
1 背景
Qunar 酒店的搜索和 suggest 是基于 Lucene 构建的,在我们的使用场景中,由于召回和排序是作为两个单独的应用,当召回的文档数量比较多的时候,响应速度较慢,Young GC 也比较严重,导致并发量很难上去。经过分析我们发现,主要的问题是因为需要获取大量文档的存储字段,造成反序列化比较多,所以影响速度,GC 也比较多。
Lucene 正常的使用场景是不期望返回这么多文档的,一般是排序完成后只返回其中一页的结果,所以问题不明显,尽管也可以通过一些方法(比如粗排序)减少返回文档的数量,但问题还是存在的。所以针对这个问题,我们希望能够找到一个比较彻底的解决方案。
为什么获取存储字段会有速度和 GC 的问题呢?
我们知道,Lucene 的 Stored Fields 在存储的时候,会把文档的字段按照某种形式编码后存储,并且会按块进行压缩。所以获取存储字段的时候,先会对字段所在的块解压缩,然后将对应的字段值反序列化为 Java 对象,放到 StoredField 对象中,文档的所有字段组装成一个 Document 对象。
这里头对时间影响比较大的是解压缩和反序列化,对 GC 影响大的是两部分,一部分是反序列化会产生很多小的 Java 对象,另外是每个字段都会创建一个 StoredField Java 对象。
压缩的问题,可以通过选项禁用压缩解决,其他的在现有的实现上就不好避免了。
那么有没有其他的选项呢?Doc Values 提供了另外一种存储字段的方法,它采用列式存储,但其目的并不是为了替代 Stored Fields,Doc Values 适用于获取大量文档的少数字段的情况,而 Stored Fields 适用于获取少数文档的大量字段的情况,Doc Values 通常用于排序、算分或者 Facet 聚合计算等场景。
尽管用 Doc Values 来存储是比较接近我们的优化目标,但当字段比较多的时候不太合适,而且 String 类型的数值需要以 binary 的形式存储,编解码次数多了也比较耗时,所以我们想,能不能自己实现字段的存储,把字段 cache 到内存里头,每次访问的时候,直接根据文档 ID 去获取相应的字段,这样就基本上没有序列化的开销,也少创建很多对象,对于我们这种数据量不是特别大的情况来说,效果应该更好。基于这个想法,我们调研了一下 Lucene 提供的相关机制,证明这么做是可行的,下面我们说一下 Lucene 提供的机制,以及我们怎么利用这种机制去实现我们想要的功能。
2 Lucene 自定义 Codec 机制
Lucene 内部通过 codec API 来读写索引文件,codec 是 Lucene 的一个非常重要的抽象:它把索引数据结构的存储和上层的建索引和搜索的复杂逻辑隔离了开来,访问索引的时候都是通过 codec API 来操作,这样就允许我们实验各种不同的索引存储格式,而不会影响上层的搜索和建索引的逻辑。
Codec 针对不同类型的索引数据定义了 10 种 Format,每种类型的 Format 又定义了读写的 API,其中读的 API 在搜索时使用,写的 API 在建索引的时候使用,每个 Segment 可以设置自己单独的 Codec。
Lucene 中的抽象类 org.apache.lucene.codec.Codec 定义了 Codec 的接口:

每个 codec 必须有一个唯一的名字,比如"Lucene80",codec 通过 Java 的 SPI(Service Provider Interface)机制进行注册,所以只要知道了名字,就可以找到对应的 codec 实例,同时在建索引的过程中 codec 的名字也会写入到每个 Segment 对应的索引元数据 SegmentInfos 中,所以 Lucene 能够根据索引中的信息找到对应的 codec。
Lucene 8 中有 10 种 Format,具体每种 Format 处理什么类型的索引,我们这里就不一一详细列举了,简单说下其中几个:
PostingsFormat 支持倒排索引的读写,倒排索引我们知道,是从 Term→{docId List}的一个索引,其中 docId List 就叫做 posting list。
StoredFieldsFormat 支持存储字段的读写,Stored Fields Index 可以算作是一种正排索引(forward index)的存储方式,通过 docId 可以直接获取,Stored Fields 采用行式存储,为了节省存储,做了压缩编码。在建索引时,针对某个字段如果指定 stored=true,会存储到 StoredFields 索引文件中。
DocValuesFormat 支持 Doc Values 的读写,Doc Values 也是一种正排的存储方式,是为了解决排序、算分、Facet 聚合等场景引入的一种列式存储方式,当需要访问大量文档的同一字段时的性能提升比较明显。
我们要优化的就是 StoredFields 的访问,其他部分不做修改,所以并不需要自定义所有的 Format,Lucene 提供了 FilterCodec 类,允许我们选择性地改写某个 Format 的实现,其他则 delegate 给默认的实现:

所以我们只需要选择性地覆盖 StoredFieldsFormat 的实现,其他的使用 Lucene80 Codec 默认的实现:
Lucene 提供了完善的单元测试,可以用来验证缩写的 Codec 功能是否正常,具体可以参考:build-your-own-lucene-codec
https://dzone.com/articles/build-your-own-lucene-codec
3 自定义 StoredFieldsFormat 实现
我们希望将 Stored Fields 数据全加载到内存,尽量减少序列化和创建对象的开销。要达成这个目标,实际上我们并不需要完全从头开始定义自己的 Stored Fields 存储格式,我们可以利用原来的索引存储格式,只需要改写读索引的 StoredFieldsReader,将数据缓存到内存中,建索引时使用的 StoredFieldsWriter 和磁盘存储格式都可以保持不变,这样是最简单的。因为我们的整个架构是基于 Lucene NRT replication 构建的一个主从式的架构,所以我们在 Primary(master)建索引的时候,可以按照正常的方式建,在 Replica(slave)使用索引的时候,可以通过开关打开 cache,整个的过程大概是这样的:
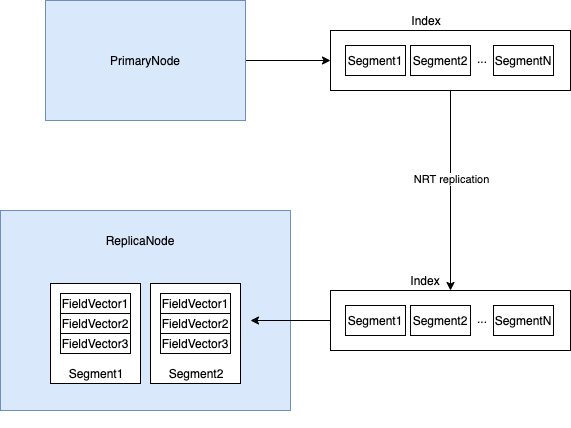
Primary 节点在建索引的时候配 IndexWriterConfig,通过 IndexWriterConfig.setCodec 设置我们自定义的 codec,codec 的信息会写入索引的元数据中。Primary 端按正常方式建索引。
Replica 节点加载 segment 数据的时候,会调用自定义的 codec,进而调用我们自定义的 StoredFieldsReader,自定义的 StoredFieldsReader 通过原有的 Lucene80Codec 的 Reader 读入数据,缓存到内存中(多个列式存储的向量),后续所有访问操作直接读取内存中的数据。
自定义的 Codec,StoredFieldsFormat 和 StoredFieldsReader 之间的关系如下图所示:
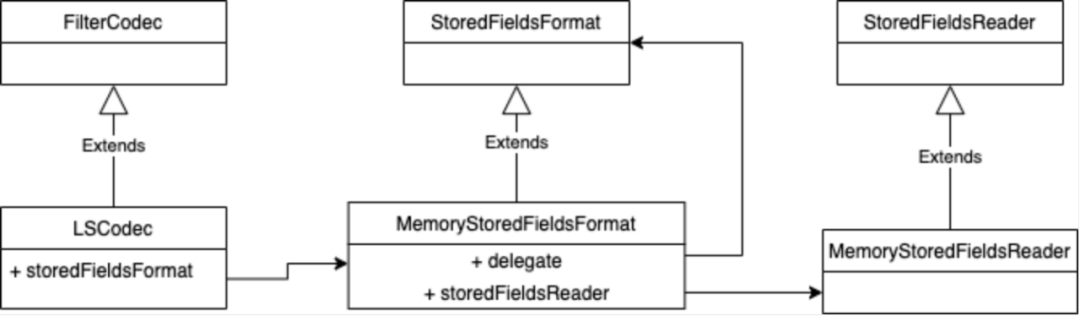
其中 StoredFieldsFormat 的接口定义如下:

我们只需要在覆盖 fieldsReader 方法,在其中初始化自定义的 MemoryStoredFieldsReader,传入的参数有 Segment 和字段相关的信息,所以可以通过 delegate 的原始 StoredFieldsReader 读取存储字段的数据(通过 visitDocument 方法访问),并存储到内存数据结构(内存数据结构我们下一节说明)中,因为 Lucene 中的 Segment 数据是不变的,所以一次性读入就可以。
数据放到内存数据结构中之后,可以通过 StoredFieldsReader 的 visitDocument 接口访问:

标准的 StoredFieldsVisitor 实现(比如 DocumentStoredFieldVisitor)有个问题,创建了太多的中间对象,比如每个字段会建一个 StoredField 对象,String 类型的字段需要先转成 byte[],然后再转成 String 等等,产生了很多不必要的中间对象,为了充分利用缓存和减少中间转化的代价,除支持标准接口外,我们自定义了 StoredFieldsVisitor,直接在内存数据结构的基础上包装了一个文档访问的接口,并通过 StoredFieldsVistor 对外提供。
伪代码示例如下:
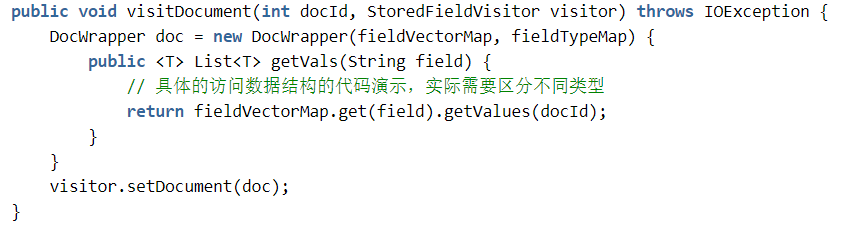
visitDocument 接口最终是被 IndexSearcher.doc(int docId, StoredFieldVisitor storedFieldsVistor)接口使用的,搜索的时候返回 docId,获取存储字段通过 Searcher 的 doc 接口。
4 内存存储结构
将数据 cache 到内存里头,一是为了解决序列化的速度问题,二是为了减少过多的中间对象,但是我们又不希望存储过度膨胀,那样我们就没法在单个机器存储所有的数据,因此,选择合适的存储结构非常重要。
一般来说,有两种存储的方法,一种是行式存储,一种是列式存储,Lucene 里头默认的 StoredFields 存储是行式存储,DocValues 是列式存储。假设我们用行式存储的方式,如果将文档序列化之后再存储,从空间、时间和产生的中间对象上来看相较原始的存储方式并没有什么优势,如果以 Java Bean 的方式来存储,速度上是最快的,产生的中间对象也比较少,但是存储空间消耗非常大,主要是因为 Java 在存储方面并不是很经济:
因为很多字段是允许多值的,所以我们需要采用数组来存储,数组在 Java 里头,64 位系统下光对象头就要占用 24 个字节(启用指针压缩的情况下也得占用 16 个字节,如果超过堆内存大小超过 32G,虽然也能对指针进行压缩,但是会有额外的对齐的开销);
空值字段也会消耗空间,比如一个 null 引用也会占用 64 位,空的原生类型字段也会占用空间;
对象对齐的开销;
复合对象引用的开销。
所以采用 Java Bean 的方式在存储上代价有点高,不太能满足要求。
而列式存储的方式,将同一个字段的放到连续的存储中,可以减少数组对象头的开销,访问的时候,也只是增加了一些偏移量计算的开销,在空间和时间上相对来说更适合。
我们通过一个例子来说明列式存储怎么实现,假设有四个文档,有一个别名字段 hotelAliases:
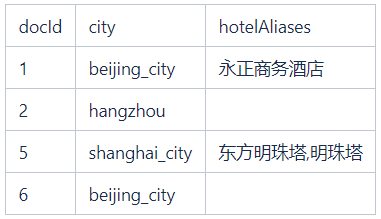
其中 ID 为 5 的文档有两个别名,ID 为 2 和 6 的文档没有别名,采用列式存储的方式可以用两个数组来表示,一个 value 数组用来存储别名,一个 offset 数组用来指示文档值的起始和结束位置:

其中 offset 的下标为文档 ID,offset[docId+1] - offset[docId]表示值的个数,如果不为 0,表示有值,值在 value 数组中的起始位置为 offset[docId]。
value 数组如果是 String 类型的对象,我们可以通过对 String 做 intern 操作来去除重复,考虑到 intern 操作本身会使用一个 Map 类型的索引来做去重,如果维护一个全局的索引的话,需要一直留着不能释放,占用内存较多,所以我们只在一个 Segment 内做 intern,因为 Segment 的数据是不变的,做完了之后,我们可以将 intern 使用的 Map 释放掉,经过测试,这样做可以节省空间,原因猜测是因为我们的数据重复的值比较集中,大都是一些低 cardinality(基数)的数据,而高 cardinality 的值则很少重复,保存去重的索引反而占用空间较多。
通过列式存储的方式,可以将存储消耗降低为 Java Bean 方式的 65%,访问速度上,损失大概百分之十几。
上面的编码方式,空值是不占 value 数组存储空间的,但是会占用 offset 数组的存储空间,虽然看起来单个文档只占用一个 int,但当存在很多不同类型的文档时,有些类型可能根本就不存在某个字段,这样就会存在大量空值,加起来浪费也比较严重,所以我们后来又在这个基础的列式存储上进一步做了优化,通过采用 succinct data structure 中的 rank/select 操作,用两个 bit 数组代替 int 数组,这个优化能够将存储空间消耗进一步减少将近 20%(12G->10G)。关于这一块,我们在将来的文章中再做介绍。
不同类型的数据,内存占用会有区别,除了提供通用的 Object 类型的实现,我们也针对 Primitive Type 提供单独的实现。
5 写在最后
本文所述的 Lucene Stored Fields 存储优化,主要是对我们的特殊应用场景:数据量不是特别大,每次查询返回文档数较多,做了针对性的优化,降低了生成的中间对象的数量,从我们的线上监控看,Young GC 频次从原来的每秒 2-3 次,变成 9-10 秒发生一次,响应时间也降低了 80%多,存储空间上面,通过采用紧凑的内存存储格式,也较好地解决了空间消耗的问题,使得我们能够将全量的存储字段数据加载到内存里头。
未来,我们还计划在这个基础上进一步做一些优化,比如:
尝试堆外存储,减少堆空间占用,更好地利用指针压缩(不过这样会有字符串编码开销,需要测试下);
实现 Per-field 的存储字段 cache,只对必要的字段做内存缓存,减少总的内存占用;
头图:Unsplash
作者:王名悠
原文:https://mp.weixin.qq.com/s/zsAjhhoOy__UlSf6i-ZMSA
原文:Lucene 中的 Stored Fields 存储优化
来源:Qunar 技术沙龙 - 微信公众号 [ID:QunarTL]
转载:著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。




