
导读
随着 MySQL 8.0 的发布,MySQL 的功能和性能有了较大的增强,越来越多的企业都选择了使用成本低且部署方案灵活的 MySQL 数据库。那么,将数据从当前数据库迁移到 MySQL 时,从应用层、数据库层都需要注意哪些方面?为了顺利完成复杂的迁移工作又需要考虑和解决哪些方面的问题?
本文以 Oracle 迁移到 MySQL 为例,重点阐述 Oracle 和 MySQL 数据类型差异、业务实现差异、迁移方式以及迁移过程中的一些风险点,供大家参考,文中如有疏漏之处,望在评论区指正。
在异构数据库迁移过程中,我们从如下几个方面进行思考:
1、迁移类型
Oracle 迁移到 MySQL 主要涉及数据结构迁移、数据迁移、业务迁移这三类,我们需要考虑如下几个难点:
数据类型差异导致数据结构迁移过程中需要进行改造和处理;
数据迁移中 Oracle LOB 字段、null 值和’’值以及迁移方式为迁移难点。
业务迁移中由于 MySQL 不支持并行、不支持物化视图,会涉及到存储过程改造,同义词改造,DBlink、sequence、分区表以及复杂 sql 语句的改造。
2、迁移流程
我们需要整理一个完整的迁移流程:1、确定迁移范围;2、迁移评估;3、选择迁移方式;4、迁移验证,以此来确保迁移工作的进展和顺利完成。
1)确定迁移范围
从 Oracle 迁移到 MySQL 是一项昂贵且耗时的任务,重要的是要了解要迁移的范围,不要浪费时间来迁移不再需要的对象。另外,检查是否需要迁移所有的历史数据,不要浪费时间来复制不需要的数据,例如过去维护中的备份数据和临时表。
2)迁移评估
经过初步检查后,迁移的第一步是分析应用程序和数据库对象,找出两个数据库之间不兼容的特性,并估算迁移所需的时间和成本。例如由于 Oracle 与 MySQL 之间数据结构存在差异,且 MySQL 不支持并行、不支持物化视图、8.0 以上才支持函数索引,可能涉及到存储过程改造,同义词改造,DBlink、sequence、分区表以及复杂 sql 语句的改造等工作。
3)迁移方式
通过对迁移所需时间和成本选择不同的迁移方法或者工具进行迁移,可以分为实时复制(例如利用 GoldenGate 实时同步数据使业务影响时间最小),或者一次性加载(例如采用 Oracle 将数据表导出到 csv 文件后,通过 load 或者 mysqlsh 工具导入到 MySQL 中)。
4)验证测试
测试整个应用程序和迁移的数据库非常重要,因为两个数据库中的某些功能相同,但是实现方式和机制却是不同的。我们需要做充分的验证测试:
检查是否正确转换了所有对象;
检查所有 DML 是否正常工作;
在两个数据库中加载样本数据并检查结果,比如来自两个数据库的 SQL 结果应该相同;
检查 DML 及查询 SQL 的性能,并在必要时进行 SQL 改造。
首先,我们先从术语、元数据、表对象、索引类型、分区等方面了解一下 Oracle 和 MySQL 的差异和区别。
一、MySQL 和 Oracle 差异
1.1 MySQL 和 Oracle 术语差异
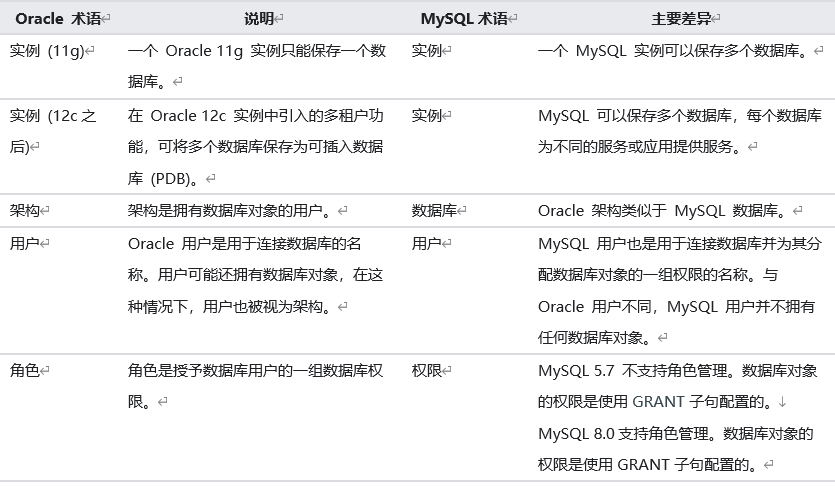
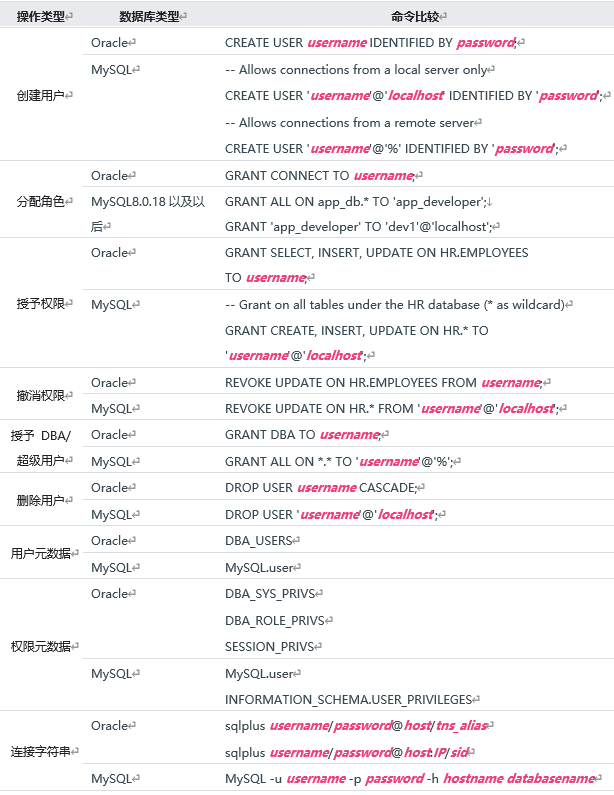
1.2 MySQL 和 Oracle 配置用户差异
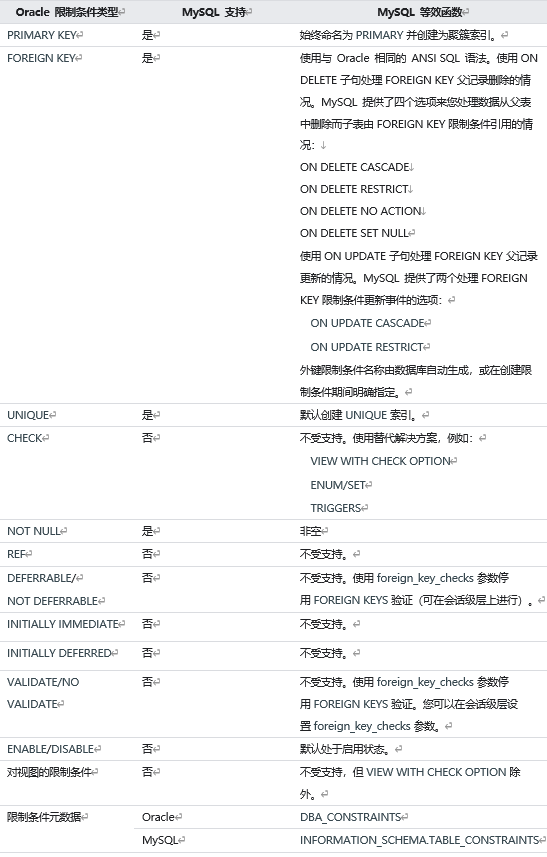
1.3 MySQL 和 Oracle 对表的限制差异
1.4 MySQL 和 Oracle 虚拟列和计算列差异
Oracle 和 MySQL 的虚拟列(在 MySQL 中也称为生成的列)基于其他列的计算结果。它们显示为常规列,但它们的值是计算所得,因此它们的值不会存储在数据库中。虚拟列可与限制条件、索引、表分区和外键一起使用,但无法通过 DML 操作操纵。
与 Oracle 的虚拟列相反 MySQL 生成的列必须指定计算列的数据类型。必须指定 GENERATED ALWAYS 值,如以下示例中所示:
Oracle 虚拟列:
SQL> CREATE TABLE PRODUCTS ( PRODUCT_ID INT PRIMARY KEY, PRODUCT_TYPE VARCHAR2(100) NOT NULL, PRODUCT_PRICE NUMBER(6,2) NOT NULL, PRICE_WITH_TAX AS (ROUND(PRODUCT_PRICE * 1.01, 2)));SQL> INSERT INTO PRODUCTS(PRODUCT_ID, PRODUCT_TYPE, PRODUCT_PRICE) VALUES(1, 'A', 99.99);SQL> SELECT * FROM PRODUCTS;PRODUCT_ID PRODUCT_TYPE PRODUCT_PRICE PRICE_WITH_TAX---------- -------------------- ------------- -------------- 1 A 99.99 100.99MySQL 虚拟列:
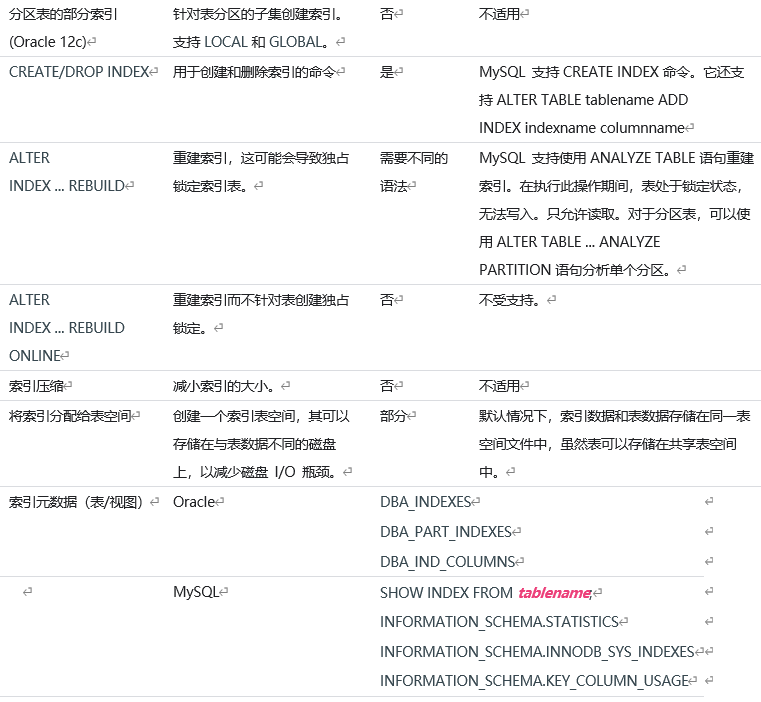
MySQL> CREATE TABLE PRODUCTS ( PRODUCT_ID INT PRIMARY KEY, PRODUCT_TYPE VARCHAR(100) NOT NULL, PRODUCT_PRICE NUMERIC(6,2) NOT NULL, PRICE_WITH_TAX NUMERIC(6,2) GENERATED ALWAYS AS (ROUND(PRODUCT_PRICE * 1.01, 2)) );MySQL> INSERT INTO PRODUCTS(PRODUCT_ID, PRODUCT_TYPE, PRODUCT_PRICE) VALUES(1, 'A', 99.99);MySQL> SELECT * FROM PRODUCTS;+------------+--------------+---------------+----------------+| PRODUCT_ID | PRODUCT_TYPE | PRODUCT_PRICE | PRICE_WITH_TAX |+------------+--------------+---------------+----------------+| 1 | A | 99.99 | 100.99 |+------------+--------------+---------------+----------------+1.5 MySQL 和 Oracle 索引类型差异

1.6 MySQL 和 Oracle 分区差异
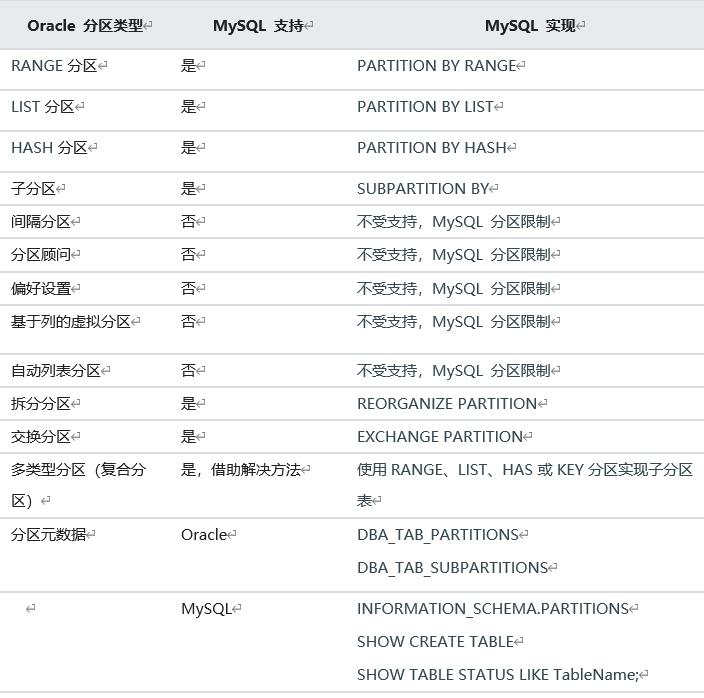
1.7 MySQL 和 Oracle 临时表差异
在 Oracle 中,临时表有全局临时表和 session 级别的临时表之分。在 MySQL 中,它们简称为临时表。在这两个平台上,临时表的基本功能是相同的。不过,两者之间存在一些显著差异:
即使在数据库重启之后,Oracle 也会存储临时表结构供重复使用,而 MySQL 仅在会话期间存储临时表。
具有相应权限的其他用户可以访问 Oracle 中的临时表。相比之下,MySQL 中的临时表只能在创建临时表的 SQL 会话期间访问。
如果在创建临时表时省略了 ON COMMIT 子句,则 Oracle 中的默认行为是 ON COMMIT DELETE ROWS,这意味着 Oracle 会在每次提交后截断临时表。相比之下,在 MySQL 中,默认行为是在每次提交后保留临时表中的行。

1.8 MySQL 和 Oracle 未使用列差异
MySQL 不支持将特定列标记为 UNUSED 的 Oracle 功能。在 MySQL 中,如需从表中删除大型列并避免执行此操作时的长等待时间,请基于原始表使用修改后的架构创建新表,然后重命名这两个表。
请注意,此过程需要停机时间。
1.9 MySQL 和 Oracle 字符集差异
Oracle 和 MySQL 都提供了多种字符集、排序规则和 Unicode 编码,包括支持单字节和多字节语言。此外,每个 MySQL 数据库都可以使用自己的字符集进行配置。MySQL 中的排序规则名称以字符集名称开头,后跟一个或多个表示其他排序规则特征的结尾。所有字符集都至少包含一个排序规则(默认排序规则),但大部分字符集都具有多个支持的排序规则。请注意,两个不同的字符集不能具有相同的排序规则。
在 Oracle 和 MySQL 中,字符集是在数据库级层指定的。与 Oracle 相比,MySQL 还支持以表级层和列级层粒度指定字符集。
1.10 MySQL 和 Oracle 视图差异
MySQL 既支持简单视图,又支持复杂视图。在对视图执行 DML 操作时,它的行为也与 Oracle 相同。对于视图创建选项,Oracle 与 MySQL 之间存在一些差异。下表着重说明了这些差异。
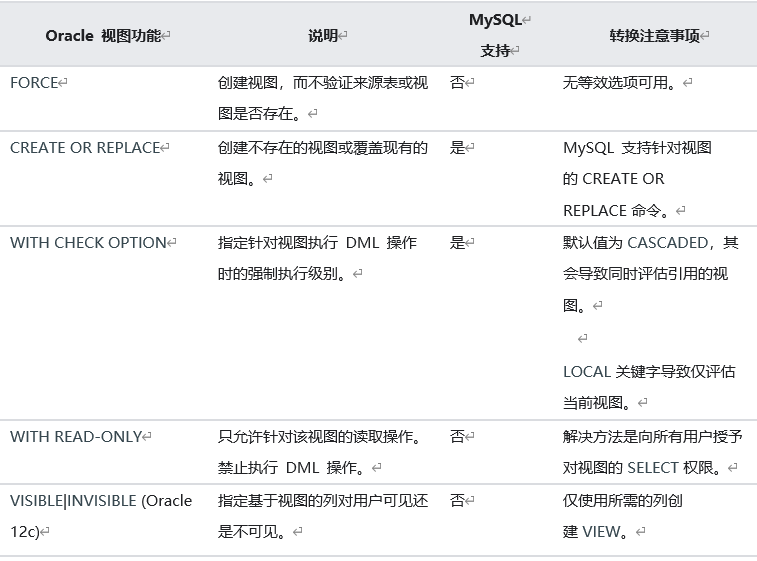
1.11 MySQL 和 Oracle 数据类型差异
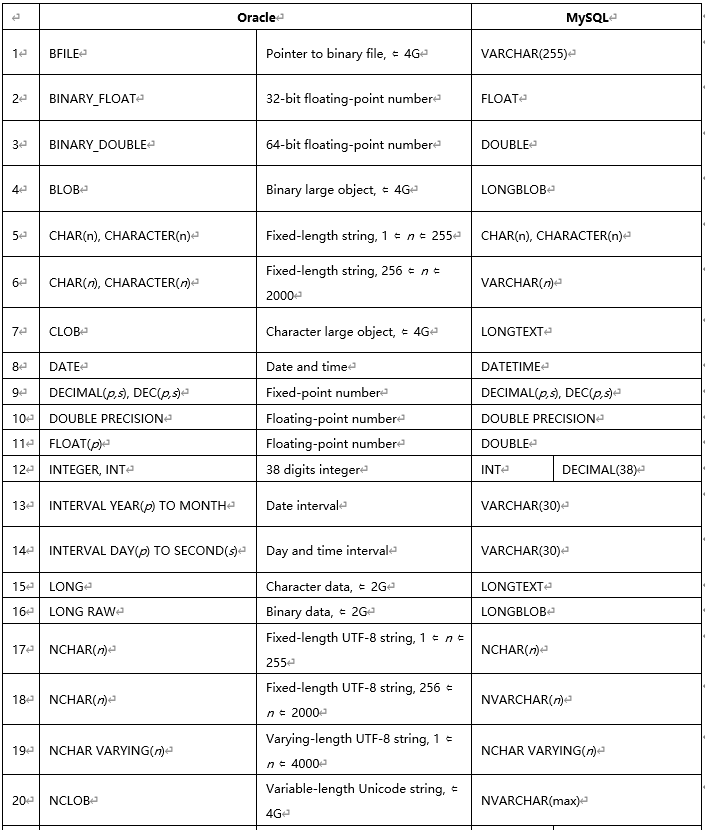
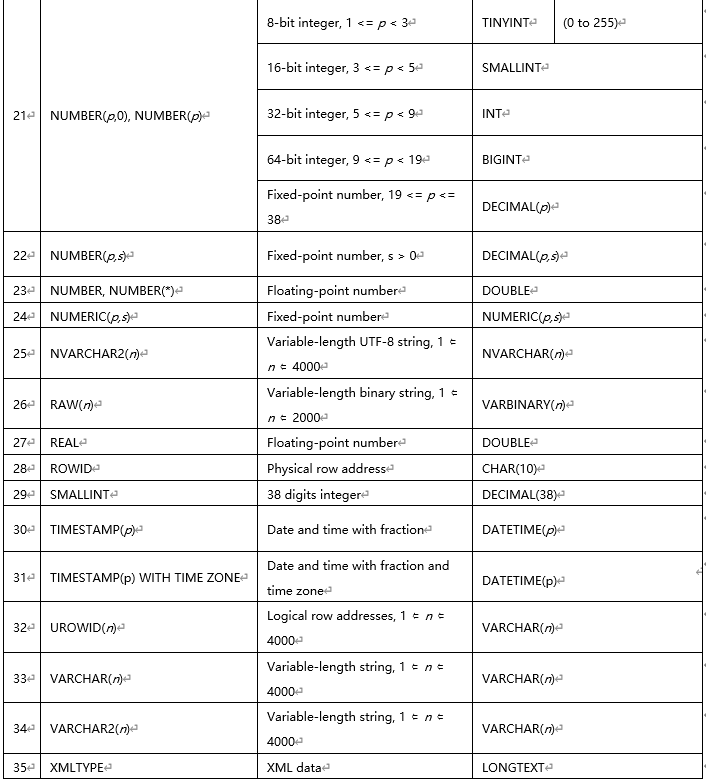
(可参考官方文档https://dev.MySQL.com/doc/refman/8.0/en/integer-types.html)
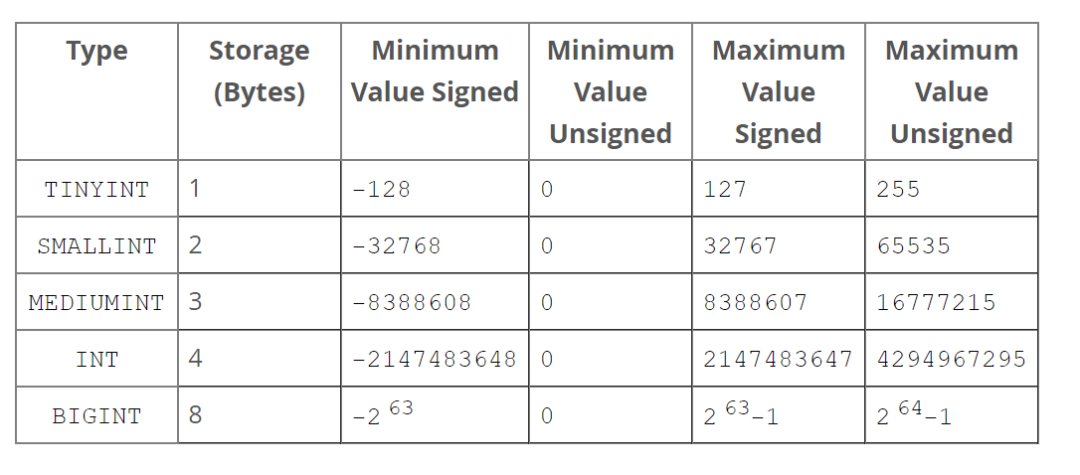
1.12 MySQL 和 Oracle 内置函数差异
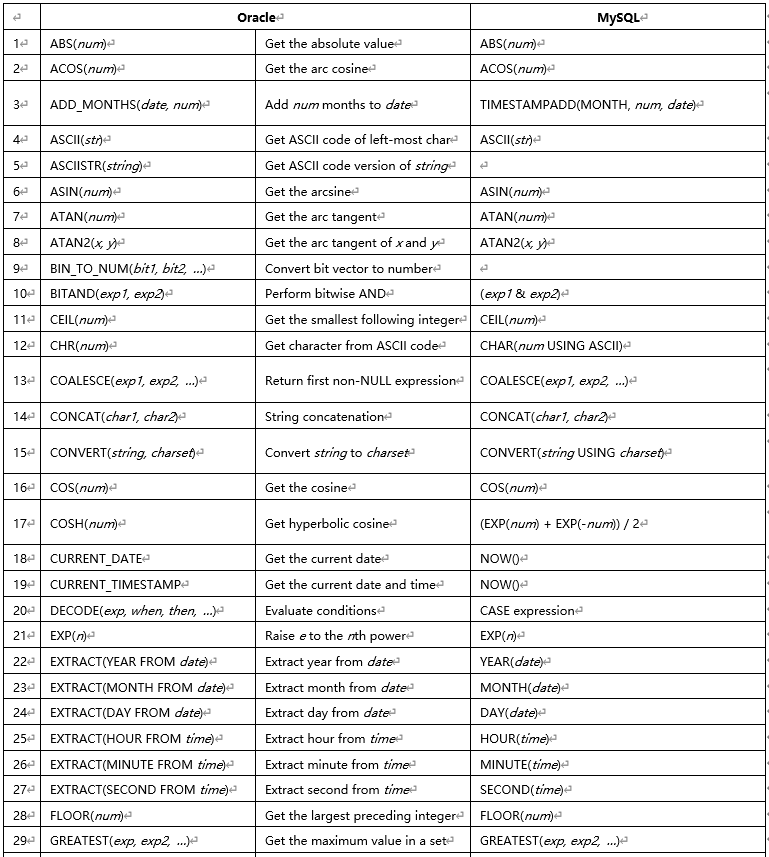
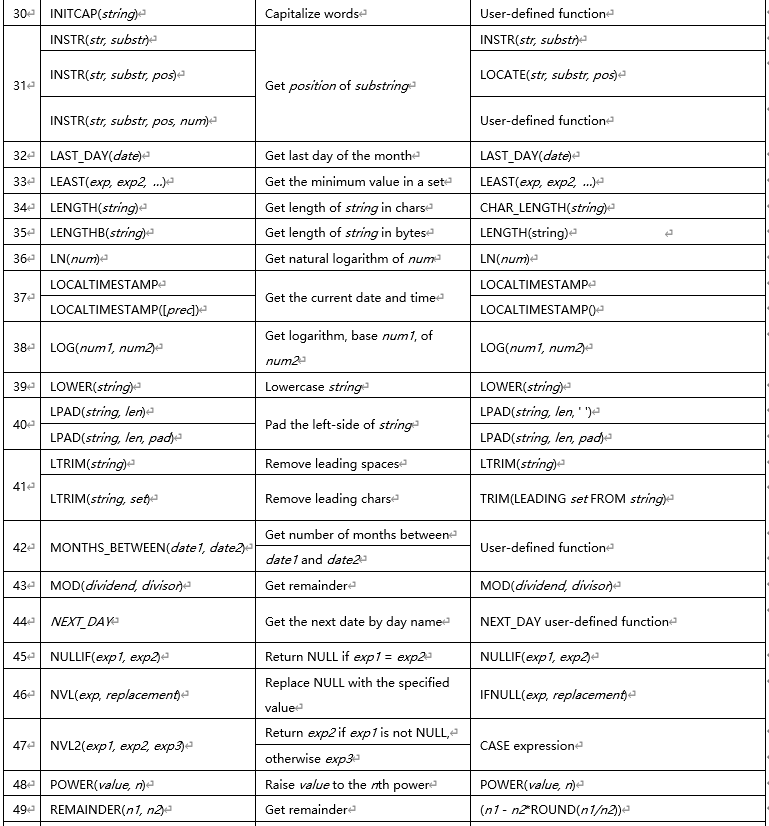
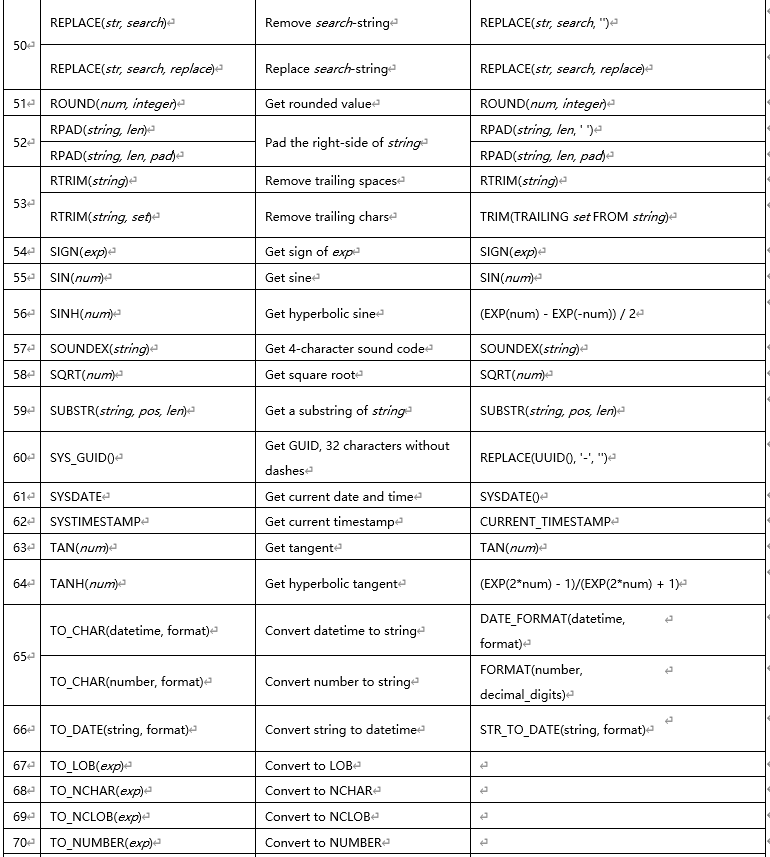
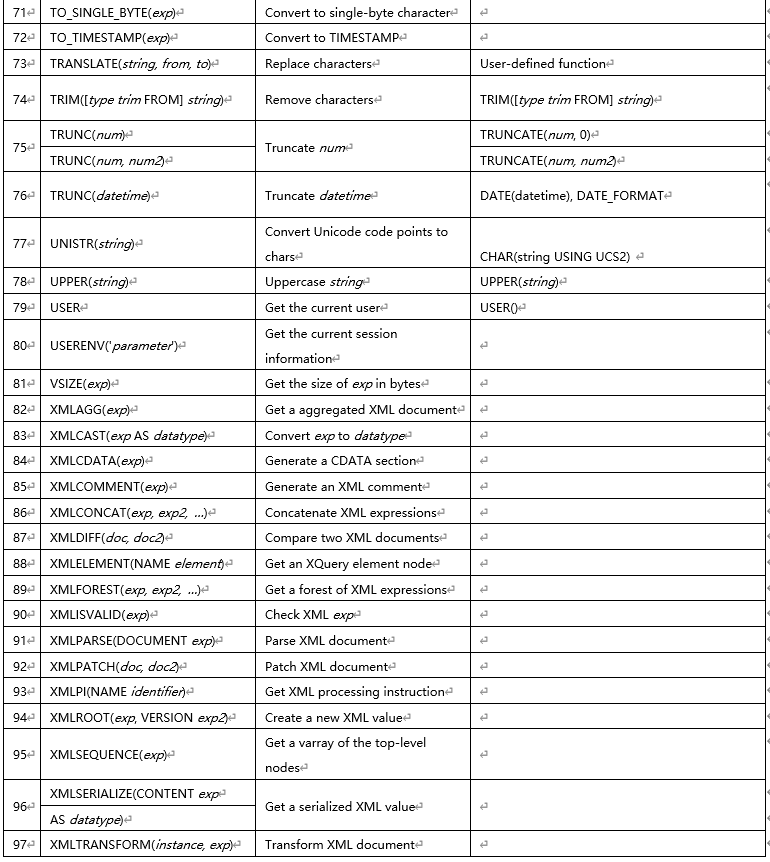
1.13 MySQL 和 Oracle 自增主键和序列的差异

Oracle 和 MySQL 除了上述数据库级别的差异外,这两种数据库在应用程序实现端也有较大的差异,比如存储过程、函数和触发器等功能的使用。在 Oracle 中,存储过程、函数和触发器归用户所有。在 MySQL 中,它们归数据库所有。在 MySQL 中,创建存储对象的数据库用户会自动获得 CREATE DEFINER 权限,并可以充当其他数据库用户的授权者。
1.14 MySQL 和 Oracle 匿名块差异
PL/SQL 可以在匿名块术语下运行,这意味着用户可以建立与 PL/SQL 引擎的连接并运行代码块,而无需创建存储对象。MySQL 没有等效的构造。在 MySQL 中,必须在存储过程或函数中创建代码块。

1.15 MySQL 和 Oracle 存储过程差异
用于创建存储过程和函数的 Oracle PL/SQL 命令包含可选的 OR REPLACE 子句,其非常适合用于更改过程。MySQL 不支持此构造。如需更改 MySQL 中的过程,请先使用 DROP PROCEDURE 再使用 CREATE PROCEDURE 语句。
创建 MySQL 存储过程或函数时,您的代码必须指定非默认分隔符“;”(分号)的其他分隔符。因为 MySQL 会将以 ";" 结尾的每一行视为一个新行,所以我们建议您使用不同的分隔符(如 $)来解析所有存储过程。END$ 关键字结束使用此分隔符。
另一个区别在于,MySQL 存储过程的变量声明部分在 BEGIN 关键字后面进行。在 Oracle 中,此部分在 BEGIN 关键字前面进行。

1.16 MySQL 和 Oracle 触发器差异
Oracle 提供三种类型的触发器:DML 触发器、instead of 触发器和 system event 触发器。其中 MySQL 原生仅支持 DML 触发器。您可以使用 FOLLOWS 或 PRECEDES 子句来修改和链接 MySQL 触发器。

1.17 MySQL 和 Oracle 默认提交方式
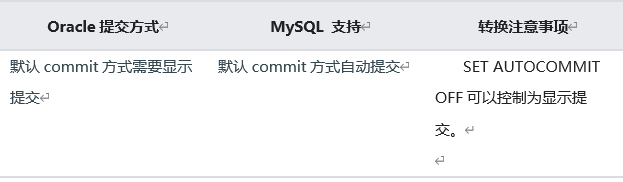
1.18 MySQL 和 Oracle 事务隔离方式
事务的隔离级别可以分为四个级别
Serializable (串行化):可避免脏读、不可重复读、幻读的发生;
Repeatable read (可重复读):可避免脏读、不可重复读的发生;
Read committed (读已提交):可避免脏读的发生;
Read uncommitted (读未提交):最低级别,任何情况都无法保证。
在 MySQL 数据库中,支持四种隔离级别,默认的为 Repeatable read (可重复读) ;而在 Oracle 数据库 中,只支持 Serializable (串行化) 级别和 Read committed (读已提交) 这两种级别,其中默认的为 Read committed(读已提交) 级别,MySQL 可以设置当前系统的隔离级别,隔离级别由低到高设置依次为
set global transaction isolation level read uncommitted;
set global transaction isolation level read committed;
set global transaction isolation level repeatable read;
set global transaction isolation level serializable;
MySQL 中使用如下语句检查系统,会话的隔离级别
select @@global.transaction_isolation, @@session.transaction_isolation, @@transaction_isolation;MySQL 为了实现可重复读的隔离级别,InnoDB 引擎使用称为“next-key locking”的算法,该算法将索引行锁定与间隙锁定结合在一起,这和隔离级别有关,只在 REPEATABLE READ 或以上的隔离级别下的特定操作才会有 gap lock 或 nextkey lock。
1.19 MySQL 不支持的功能项
MySQL 没有并行的概念,不支持并行;
MySQL 优化器较弱,复杂 SQL 建议拆分简单 SQL;
MySQL 对于子查询优化不是很好;
MySQL 不支持物化视图、存储过程改造、同义词改造、dblink 需要改造。
二、MySQL 到 Oracle 的数据迁移方式
一般我们可以通过如下两种基本方法迁移数据:一次性加载和实时复制。一次性加载方法是指从 Oracle 种导出现有数据并将其导入到 MySQL 中。实时复制方法是指数据生成之后立即从 Oracle 复制到 MySQL。
2.1 一次性加载方法
对于一次性加载方法,源数据库必须仅在该过程期间打开进行写入。因此,此方法也称为离线数据迁移。Oracle SQL DEVELOPER 是用户从 Oracle 导出数据的最常用工具之一。此工具支持从采用各种格式(包括 CSV 和 SQL 插入语句)的 Oracle 表中导出数据。或者,您可以使用 SQL*Plus 选择数据并设置其格式,然后将其假脱机到文件中。将数据从 Oracle 导出到平面文件后,您可以使用 LOAD DATA INFILE 命令将数据加载到 MySQL 中。该方法通常是一种最便宜的迁移方法,但它可能需要更多的手动输入,并且比使用迁移工具要慢。它还需要在迁移过程中将应用停机。
2.2 实时复制方法
实时复制方法(也称为更改数据捕获)是一种在线数据迁移方法。在初始数据复制期间,源数据库保持打开状态。复制产品会捕获源数据库上发生的数据更改,并将这些更改传输并应用到目标数据库。如果是迁移生产数据,您可以使用此方法以最大限度地减少所需的停机时间,并确保在进行切换之前停机时间接近零。此方法涉及使用更改数据捕获 (CDC) 产品,例如 GoldenGate、Striim 或 Informatica 的数据复制。
2.3 遵循原则
迁移数据时,请遵循以下准则,其中大部分准则同时适用于一次性加载方法和实时复制方法:
字符集:确保源 Oracle 数据库与目标 MySQL 数据库之间的字符集兼容;
外键:要提升提取速度,请暂时停用目标 MySQL 数据库上的外键限制条件。加载完成后再启用外键限制条件;
索引:与外键类似,目标 MySQL 数据库上的索引可能会显著降低初始加载的速度。确保在初始加载完成之前,在目标数据库上未创建索引;
Oracle 序列:MySQL 支持 AUTO_INCREMENT 而不是序列。确保在初始加载期间停用 AUTO_INCREMENT 特性,以避免覆盖 Oracle 的序列生成的值。在初始加载完成后,将 AUTO_INCREMENT 特性添加到主键列;
网络连接:如果您使用的是 GoldenGate TDM,请确保来源环境和目标环境都可以与 GoldenGate TDM 产品建立网络连接,以允许在 Oracle 端捕获数据并在 MySQL 端加载数据。
在迁移过程中,字符集、空间估算、NULL 值的处理、LOB 迁移等,都是迁移过程中的难点,我们需要对这些难点进行分析并设计相应的处理办法,以免在迁移过程中踩坑。
三、难点分析和处理
3.1 字符集
对于字符集,需要考虑的问题为迁移过程字段长度匹配情况,迁移后数据是否乱码,以及迁移后字符集转换后空间的问题。
3.1.1 Oracle
Oracle 创建数据库时指定字符集,一般不能修改,整个数据库都是一个字符集。还支持指定国家字符集,用于 nvarchar2 类型,常用的字符集:AL32UTF8 和 ZHS16GBK,其中 AL32UTF8 与 UTF8 几乎是等价的。一个汉字在 AL32UTF8 中占三个字节,而在 ZHS16GBK 中占用两个字节。
3.1.2 MySQL
MySQL 的字符集比较灵活,可以指定数据库、表和列的字符集,并且很容易修改数据库的字符集,不过修改字符集时已有的数据不会更新。
3.1.3 数据迁移避免乱码
客户端字符集很重要,输入数据时,包括文本输入和屏幕输入等,客户端会以这个字符集来解析输入的文本,如果实际输入的字符集与客户端字符集不一致,那么就可能导致录入数据库的数据出现乱码;输出数据时,如果客户端字符集设置的不合适,就会导致展示或导出的数据是乱码。
Oracle 通过环境变量 NLS_LANG 配置客户端字符集。
Linux 下会话级设置方法:export NLS_LANG=AMERICAN_AMERICA.AL32UTF8
Windows 下会话级设置方法:set NLS_LANG=AMERICAN_AMERICA.AL32UTF8
特别要注意一点,用 SQLPLUS 执行脚本时,NLS_LANG 需要跟脚本文件的字符集保持一致。如果是 UTF8,脚本需要保存为 UTF8 无 BOM 格式。
查询 oracle server 端的字符集: select userenv('language') from dual;
查询 oracle client 端的字符集:
MySQL 刻意通过如下字符集参数来确认字符集设置:
character_set_client:客户端来源数据使用的字符集;
character_set_connection:连接层字符集;
character_set_results:查询结果字符集。
如果检查的结果发现 server 端与 client 端字符集不一致,请统一修改为同 server 端相同的字符集。
3.2 迁移过程中字段长度匹配和空间估算
MySQL 中 char(n)和 varchar(n)代表的是字符串长度,而 Oracle 中 char(n)和 varchar(n)代表的是字节长度,所以迁移过程中可以适当减少字段长度减少储存空间。
3.3 空串和 Null 值的处理
Oracle 和 MySQL 中‘’和 null 的区别:
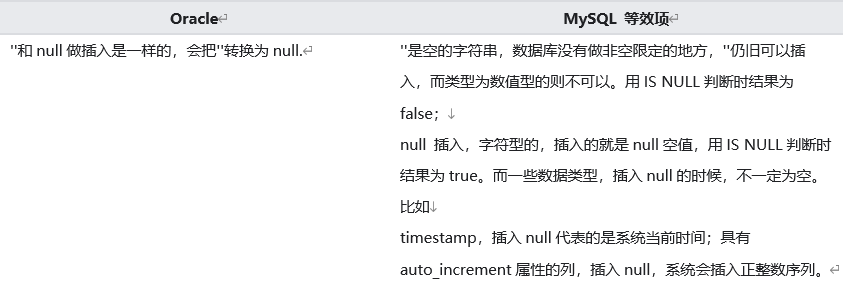
从 Oracle 中导出到文件中是的有 null 值会被成‘’,这样插入到 MySQL 后 null 和‘’就会混乱,且插入到 MySQL 的‘’会根据不同的字段类型转换成不同的方式。
使用文件导入到 MySQL 时字段中的空值 null 需要使用\N 表示,如果用空字符串表示,那么根据不同的数据类型,MySQL 处理也各异。
Oracle 导出到文本文件,null 会变为空字符串,插入到 MySQL 后会被认为是空字符串插入,破坏了数据一致性,以下提供了三种方式进行规避:
1、可以在 Oracle 迁移之前将所有业务表的 null 值变更为无意义的值,等到迁移到 MySQL 后统一数据修复调整回来,例如:
UPDATE SUPPLIERS_TBL SET SUPPLIER_ID=NVL(null,‘N/A’) where SUPPLIER_ID is null;2、使用 spool 导出的时候对 null 值进行转换,需要针对表和列进行修改
SelectNVL(TO_CHAR(id),'N/A')||','||NVL(name,'N/A')||','||NVL(SEX,'N/A')||','||NVL(ADDRESS,'N/A')||','||NVL(TO_CHAR(BIRTHDAY),'N/A') from user1;3、使用 python 脚本进行抽取加载,避免了导出到文本文件的问题,需要进行对脚本进行开发,大数据量效率需要进行测试。
3.4 日期类型处理
Oracle 缺省的时间数据的显示形式,与所使用的字符集有关。一般显示年月日,而不显示时分秒。例如,使用 us7ascii 字符集(或者是其他的英语字符集)时,缺省的时间格式显示为:28-Jan-2003,使用 zhs16gbk 字符集(或其他中文字符集)的时间格式缺省显示为:2003-1 月-28。
MySQL 数据库默认时间字段格式
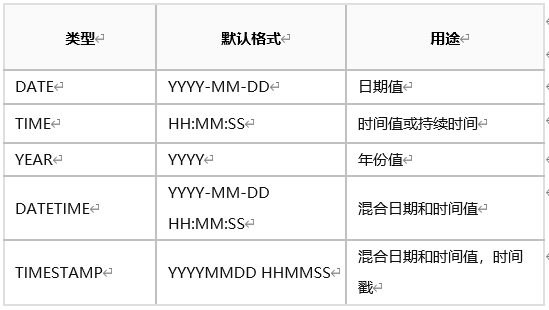
所以在导出到文本文件时需要注意,调整 Oracle 的默认时间格式,最好在配置文件中直接设置
export NLS_DATE_FORMAT='YYYY-MM-DD HH24:MI:SS'需要注意的点:
字段类型如果是 datetime,应该严格把控相应文本数据的格式,建议采用类似这种 yyyy-MM-dd HH:mm:ss 同时有日期、时间的格式,否则难以保证数据导入的正确性。
字段类型如果是 timestamp 且 explicit_defaults_for_timestamp=on,数据行更新时,timestamp 类型字段不更新为当前时间。
3.5 LOB 字段迁移
Lob 字段可以分为 clob 和 blob。含 clob 字段的表可以采用 UTL_FILE 导出到 csv 中,再导入 MySQL 中。
参考:How to Export The Table with a CLOB Column Into a CSV File using UTL_FILE ? (Doc ID 1967617.1)
3.6 大小写敏感差异
Oracle 里会默认统一按照大写来处理,MySQL 里面默认是大小写敏感的。
我们较为了解的是表结构大小写敏感参数 lower_case_table_names,但是数据内容区分大小写敏感参数(collate)参数使用可能较少,由于 Oracle 默认是区分数据大小写的,为达到迁移前后一致性,所以我们需要对这个参数做显式修改。
3.7 外部表处理方式
MySQL 中提供 CSV 引擎,可以实现 Oracle 中外部表的功能,创建 CSV 表时,服务器将创建一个纯文本数据文件,该文件的名称以表名开头并具有.CSV 扩展名。将数据存储到表中时,存储引擎会将其以逗号分隔的值格式保存到数据文件中。可以将外部文件替换.CSV 后 flush table 实现 Oracle 外部表功能。
CSV 引擎限制:
CSV 存储引擎不支持索引;
CSV 存储引擎不支持分区。
使用 CSV 存储引擎创建的所有表必须在所有列上具有 NOT NULL 属性。
3.8 MySQL sql_mode
MySQL 服务器能够工作在不同的 SQL 模式下,针对不同的客户端,以不同的方式应用这些模式。这样应用程序就能对服务器操作进行量身定制,以满足自己的需求。这类模式定义了 MySQL 应支持的 SQL 语法,以及应该在数据上执行何种确认检查。MySQL 8.0 默认为严格模式的 sql_mode
建议:在导入过程中对于不匹配的格式,可以先关闭严格模式进行导入 set global sql_mode='',导入之后再打开严格模式。
四、迁移性能的考虑
当数据量比较大时,我们需要着重考虑迁移的性能和速度,从而减少数据库迁移时的时间窗口。
4.1 数据导出阶段
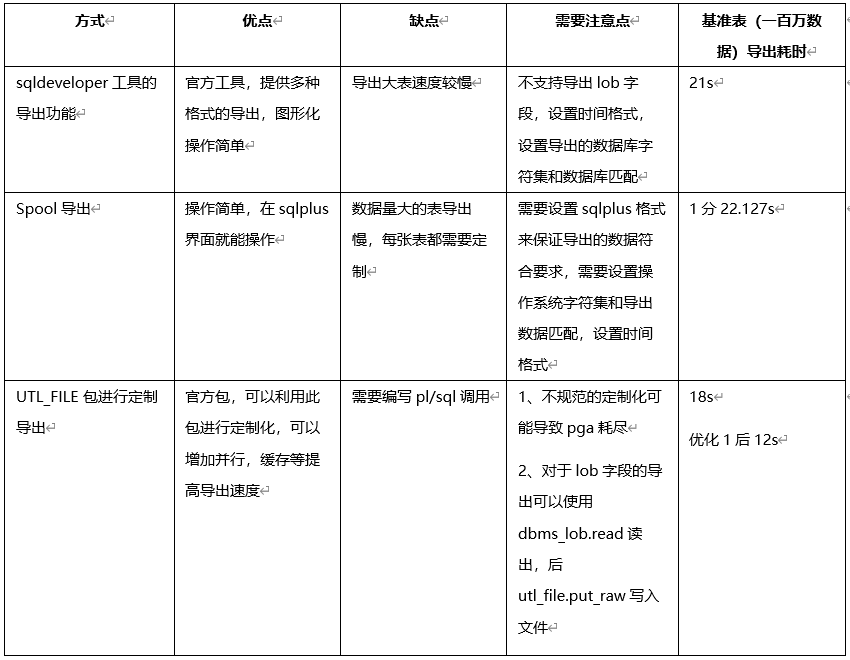
数据库自带一次性加载方式中卸载数据方式:
使用 sql developer 进行导出,应用程序只有 windows 版,导出数量大的表容易 hang;
Utl_file 卸载方式 处理的表的数据量较少时较快;
Sqlplus spool 卸载方式 处理的表的数据量较少时较快 可以增加并行提高导出速度。
一次性加载的方式需要进行测试才能确定停机时间
测试案例和导出时间对比:
或者,使用 Orato8a 工具将 Oracle 数据库的表导出成 CSV 文件,然后使用 load 命令将数据导入 MySQL 数据库,该工具需要预先安装好 Oracle 客户端,并配置好连接串。
Orato8a 是一个可以快速、高效地从 Oracle 数据库系统中抽取数据,并将数据保存到指定文件中的专用工具。并且 Orato8a 还提供查询语句导出和全表导出两种方式,其中全表导出的登录用户需要对 dba_extents、dba_objects 和 dba_tables 这三张表有 select 权限,使用步骤如下:
或者可以使用 python 利用已有的包进行迁移普通表,测试参考,性能需要进行测试。
#Import librariesimport cx_Oracleimport mysql.connectorimport pandas as pdfrom sqlalchemy import create_engine#Set Oralce Connectionconn = cx_Oracle.connect('test/test@192.168.19.111/orcl')#Open cursorcursor = conn.cursor()#buidling sql statement to select records from Oraclesql = "SELECT * FROM T"#read data into dataframe directlydata=pd.read_sql(sql,conn)print("Total records form Oracle : ", data.shape[0])#Create sqlalchemy engineengine = create_engine("mysql+mysqlconnector://test:root@192.168.19.111:3312/test")data.to_sql("t", con = engine, if_exists = 'append', index = False, chunksize =10000)print("Data pushed success")#close connectionconn.close()4.2 数据导入阶段
数据导入我们可以采用 mysqlsh 或者 load data 进行导入,在导入数据的时候预先的修改一些参数,来获取最大性能的处理,比如可以把自适应 hash 关掉,Doublewrite 关掉,然后调整缓存区,log 文件的大小,把能变大的都变大,把能关的都关掉来获取最大的性能,我们接下来说几个常用的:
4.3 迁移后验证数据的完整性
在数据迁移完毕后,我们需要找出目标 MySQL 库存在的问题和数据不一致的地方,以便快速解决数据之间的所有差异。可以考虑从如下几个方面进行验证:
比较源数据库表与目标数据库表的行数以找出所有差距,除了运行 count 之外,还要对同一组表运行 sum、avg、min 和 max;
针对目标 MySQL 环境运行常用的 SQL 语句,以确保数据与源 Oracle 数据库匹配;
将应用连接到源数据库和目标数据库,并验证结果是否匹配。
五、迁移总结
1、明确数据结构差异,应用实现的差异并正确调整是保障迁移后准确性的关键。
2、合适的迁移方式需要再多次测试演练中进行摸索才能在相对准确的时间内完成迁移,一定要选择较合适的迁移方法。
3、比较推荐使用 mysqlsh 将 csv 导入到 MySQL 库中,该方法可以并行导入且可以将大的数据文件进行切片。
4、数据库迁移完毕后,数据完整准确的检验非常重要,迁移前需要制定合理的完整性校验步骤和方法。
作者介绍
吴海存,10g / 11g / 12c OCM,Oracle Exadata / Golden Gate 专家,曾于 Amazon 和 Oracle 公司担任全球业务资深 DBA,目前供职于中国农业银行,负责数据库前沿技术研究和支持。
本文转载自:dbaplus 社群(ID:dbaplus)




