
背景
数据流量增长到我们在十多年前从未想到的水平,而且没有放缓的迹象。数据流量的指数级增长引领我们进入了大数据时代,数据从四面八方汹涌而出——移动应用程序、社交网络、客户数据库或物联网设备。
大数据的出现意味着对新技术、新挑战和新技能的关注,以跟上数据库新技术的发展步伐。
与此同时,现在我们称之为“传统数据库”的东西正在输给创新的数据库解决方案。作为大数据首选存储解决方案的数据湖,它的出现意味着建立在关系型数据库(传统数据库)之上、只能存储结构化数据的传统数据仓库正陷入挣扎的泥潭。相比之下,数据湖通常建立在 Hadoop 集群或 NoSQL 数据库之上。
本文从介绍自互联网成为主流以来出现的挑战开始,然后展示一些想法和解决其中一些问题(特别是数据分布和安全)的实践指南。
因为这两个问题与大数据的不同领域相关,所以你可能会想到很多可用的数据库。为了让事情简单明了,本文只考虑如何用分布式和安全特性来升级传统的数据库,如 MySQL、PostgreSQL 或 SQLServer。这种解决方案将你的数据库集群转换成分片的分布式系统,并加入数据加密和流量管理等有用的特性。这些优势可不是小打小闹,除此之外还有更多——如果你关注成本效益,你会看到升级和迁移数据库集群将为你带来净效益。
大数据带来的数据库挑战
在深入实际的层面之前,我们先来看看大数据的 5V 特征及其挑战。
容量(Volume)——数据量太大,无法进行有效的管理和使用。
多样性(Variety)——数据类型非常广泛,如结构化数据、非结构化数据和混合数据。
速度(Velocity)——蓬勃发展的互联网流量导致数据的生成速度不断增长。
准确性(Veracity)——数据的准确性决定了高管们对商业决策和前景的信心。
价值(Value)——数据积累和分析为企业发现新的潜在市场/产品创造了新的机会,并帮助他们作出更明智的决策。
因为“准确性”和“价值”与数据分析更为相关,所以不是本文的讨论重点。至于容量、多样性和速度,很多行业的企业正在为以下这些问题寻找解决方案。
如何有效存储和管理空前数量的数据?
如何按需灵活伸缩数据库实例?
在某些情况下,我们从多个数据源收集数据,然后组合成一个结果,那么如何同时管理结构化和非结构化的数据?
如何在最小化重构数量的情况下保护在线系统用户的隐私?
这些问题有多种可能的解决方案,例如寻找新的数据库供应商,或者开发中间件或插件。
但是,如果你正在使用或考虑使用开源的传统 DBMS,那么你可以参考本文后面的部分,并将其作为一种建议来改进或构建一种以传统 DBMS 为基础的安全分布式数据库系统。你可以选择 PostgreSQL、MySQL 或 RDS,下面的这些步骤都可以应用到你的系统中。
架构介绍
Apache ShardingSphere
Apache ShardingSphere是一个开源生态系统,它可以将任意数据库转换成分布式数据库系统,并加入分片、弹性伸缩、加密等特性。
关于这个项目的介绍已经在告诉我们——它可以帮助我们将现有的数据库转换成分布式数据库系统,并通过有用的特性来改进新系统。
这个过程相当简单。为了实现这个效果,你所要做的就是将项目导入到数据库系统中(也就是创建了一个分片数据库系统),然后按需进行伸缩,还可以对数据进行加密。下图是这种架构的概览。
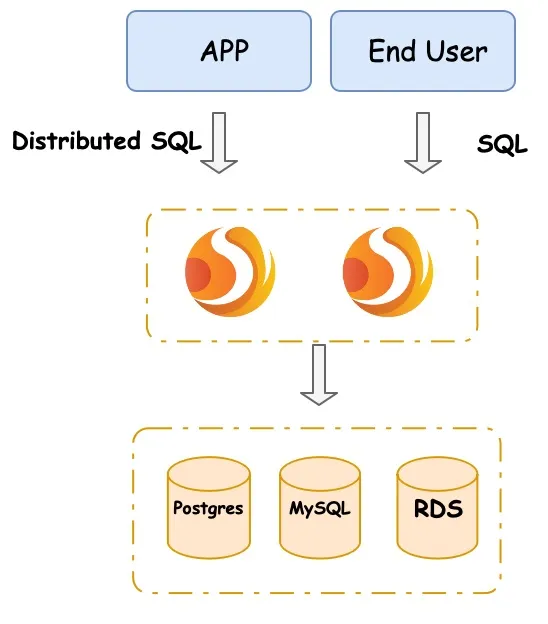
如上图所示,分布式数据库系统由 ShardingSphere(本例为 ShardingSphere-Proxy)和各种数据库(MySQL、PostgreSQL、Aurora 或其他 SQL92 数据库)组成,ShardingSphere 位于应用程序和数据库之间。
在这个系统中,ShardingSphere 作为接收用户请求的计算节点,数据库作为保存数据和进行一些本地计算的存储节点。应用程序将查询发送到 ShardingSphere,就像它们将查询发送到 DBMS 一样。
传统的 SQL 用于查询数据库。然而,因为在分布式数据库系统中添加了多个新特性(比如自动伸缩、加密、SQL 审计),所以我们需要一种类似 SQL 的语言来操作这些新特性。
为了满足这一需求,并且不给用户造成新的障碍或学习曲线,ShardingSphere 使用了分布式 SQL (DistSQL)来实现无缝的转换。这意味着你可以登录到 ShardingSphere,然后输入 SQL 和 DistSQL 来创建分片表、加密表,或者启动伸缩作业。在下面的小节中,我将展示它的魔力和多功能性。
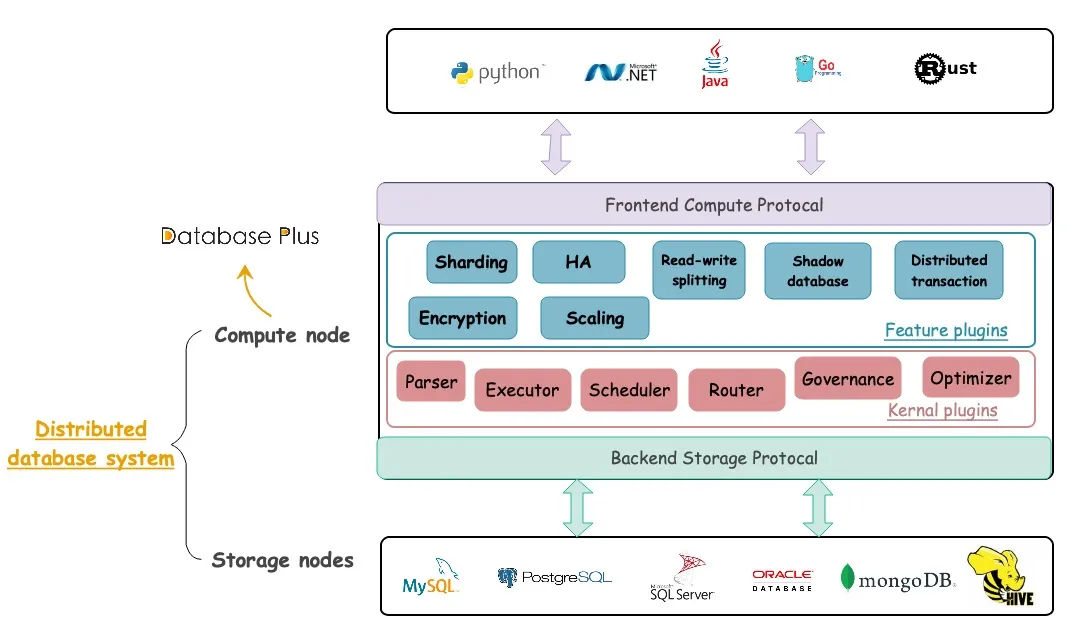
在继续其他内容之前,我们先来进一步分析前面的那张架构图。架构图对包括 ShardingSphere 在内的部署架构进行了概览,下面将对其进行“放大”,让你更深入地了解它。
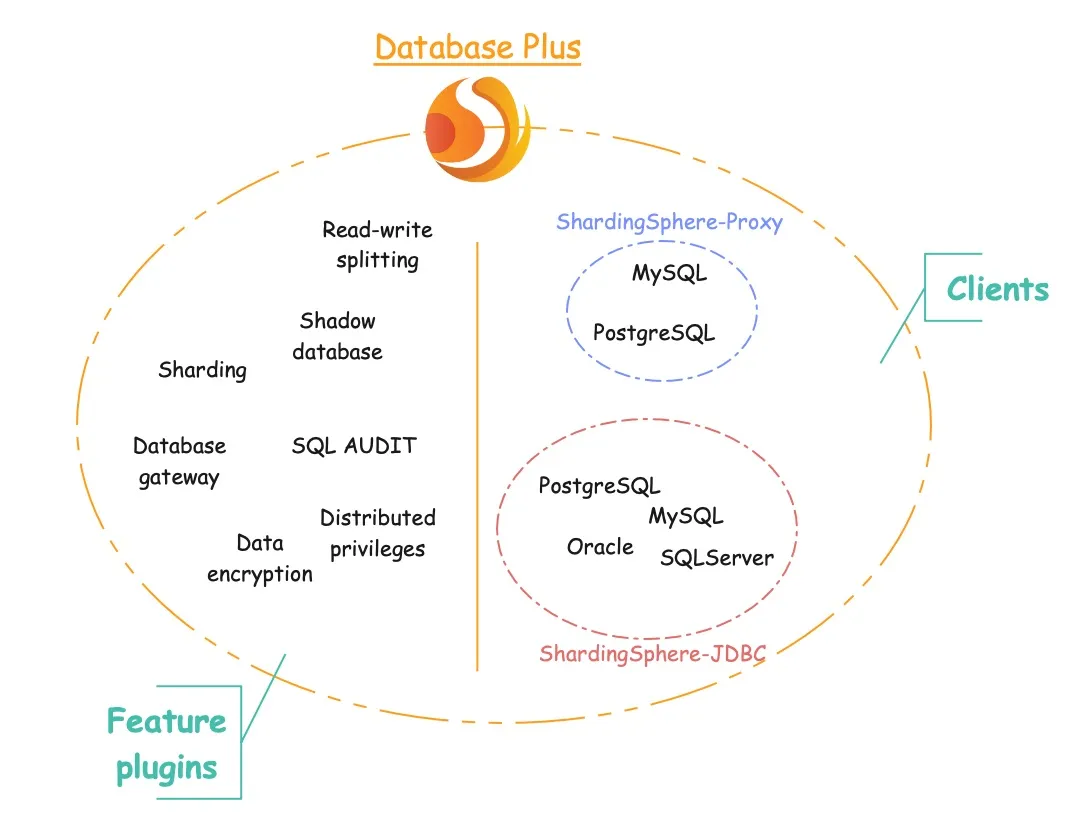
从图中可以看出,ShardingSphere 不仅是分布式数据库系统的计算节点,还提供了很多有用的特性。其中 ShardingSphere-Proxy 和 ShardingSphere-JDBC 是两个客户端。
Database Plus
Database Plus 是 ShardingSphere 项目遵循的指导性开发概念。它是分布式数据库系统的一个概念,超越了简单的数据分片。
最初的设想是在现有的碎片化数据库之上建立一个标准化的层和生态系统,提供统一的 SQL 操作服务,最大限度地减少数据库差异。应用程序可以直接与标准化服务通信,不需要费劲匹配每一个不同的数据库。ShardingSphere 利用了传统 DBMS 和 NoSQL 数据库(在规划中),并成为最终用户的标准数据库服务器。
功能插件
Database Plus 术语中的“功能插件”是指所有这些特性既可以独立运行,也可以同时运行。
这意味着基于 Database Plus 的数据库系统是可调节和“可插拔”的,为最终用户简化了组合多种功能插件的复杂性。ShardingSphere 目前支持分片、读写分离、数据库网关、数据加密、分布式权限、影子数据库等功能。
客户端
生态系统中包含了两个客户端,可以单独或同时部署。
ShardingSphere-Proxy 是透明的数据库代理,也作为数据库服务器。因此,它应该独立部署在服务器上。目前,PostgreSQL 和 MySQL 与 ShardingSphere 配合得很顺畅。
ShardingSphere-JDBC 是一个扩展了 Java JDBC 层的轻量级 Java 框架,可以集成到 JDBC 应用程序中。
我们可以同时部署这两个客户端,ShardingSphere-JDBC 作为高性能的驱动程序,ShardingSphere-Proxy 作为管理客户端。
利用 DBMS 创建安全的分布式数据库集群
在了解了架构之后,现在让我们来一步一步地创建分片和安全的 Aurora 数据库系统(步骤指南在后面)。我们将使用 ShardingSphere 的分片插件、数据加密插件以及 ShardingSphereProxy 来构建一个分布式数据库系统,如下图所示。
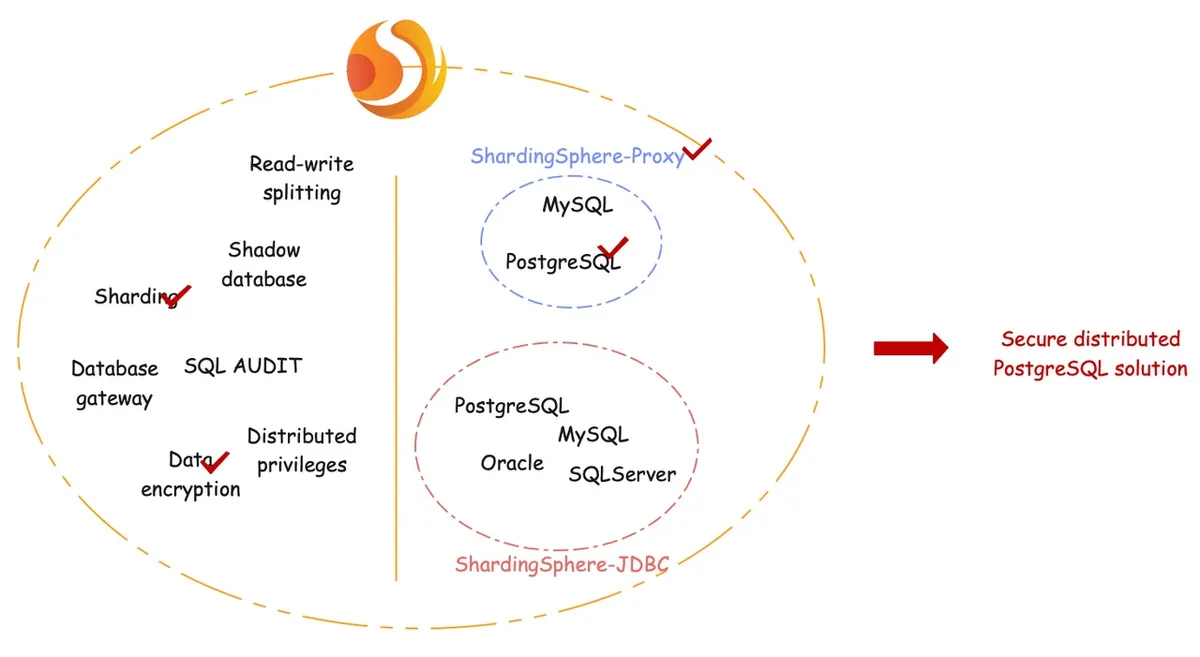
完成指南中的步骤后,你将得到的最终解决方案将如下图所示。
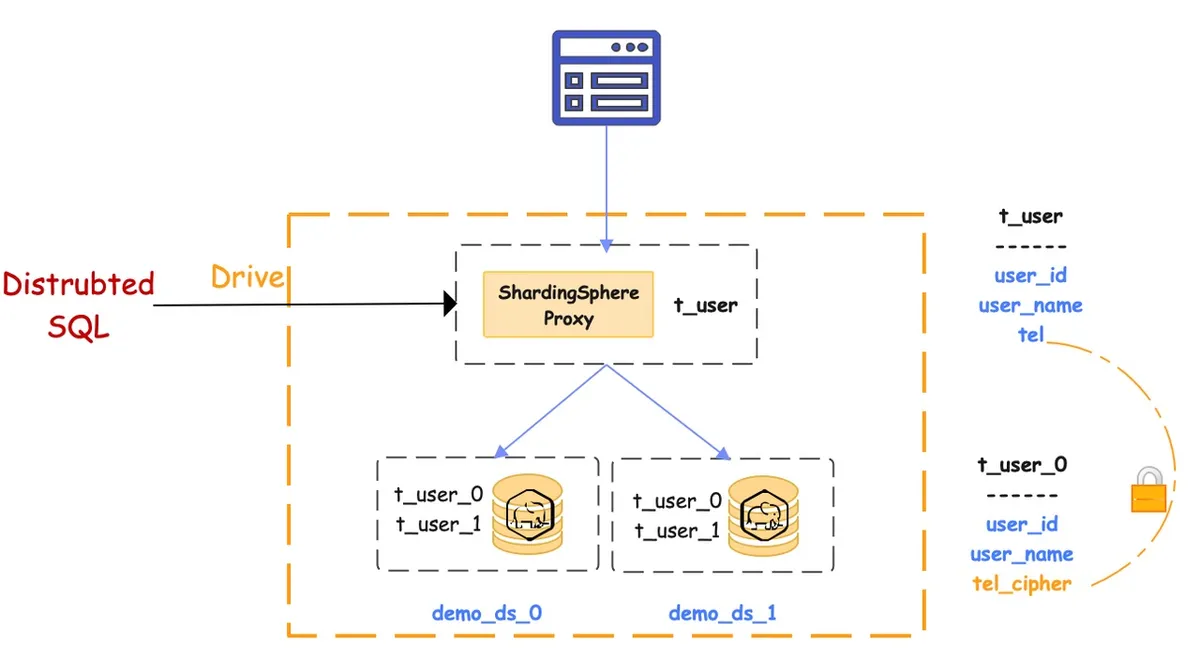
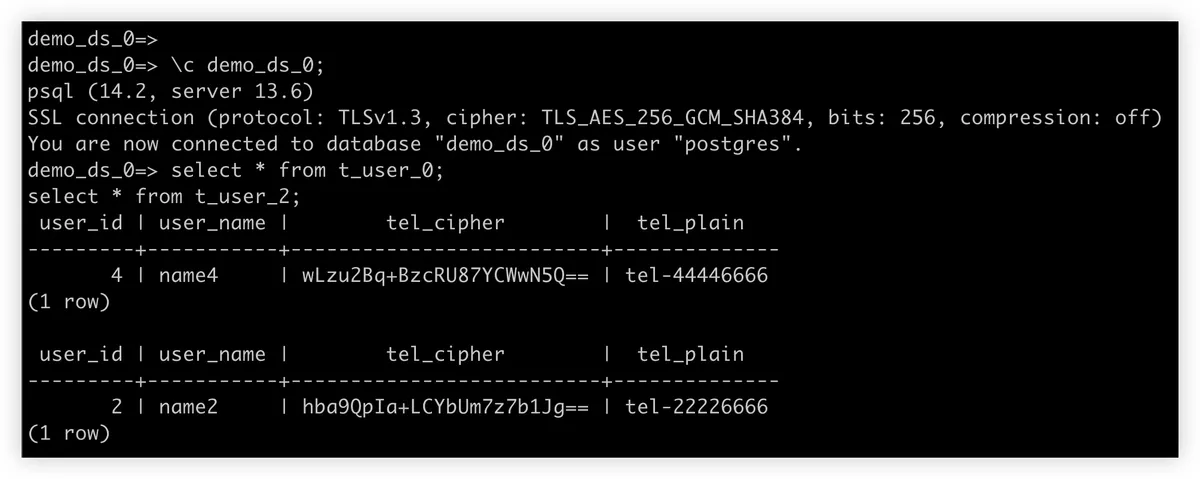
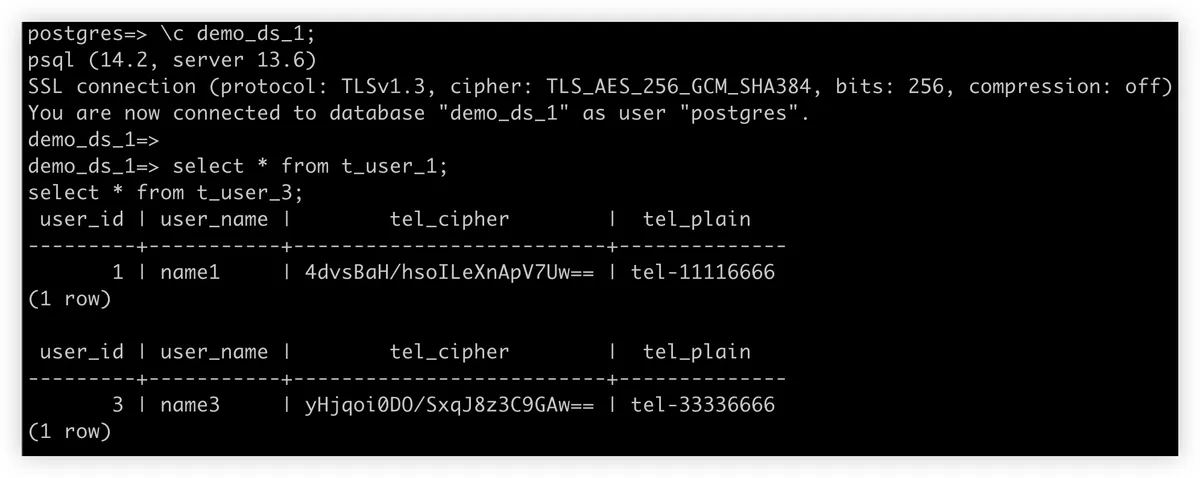
应用程序将 ShardingSphere + PostgreSQL 实例看成是一个分布式数据库,并像对待 PostgreSQL 那样对待 ShardingSphere。从用户的角度来看只有一个逻辑表 t_user。但实际上,这个逻辑表是由四个实际表组成的,从 t_user_0 到 t_user_3,它们位于两个不同的 PostgreSQL 实例中。
逻辑表 t_user 有一个 tel 列,用于存储用户的电话号码。由于电话号码是敏感数据,所以在存储到数据库中时必须进行加密。为此,在实际表中创建了 tel_cipher 和 tel_plain 两个列,用于保存相应的密文和明文(可选,这里仅为演示目的)。
生态系统的用户友好性体现在最终用户不需要关心实际表中的列,也不需要关心如何将逻辑列映射到实际列。他们只需使用逻辑列和明文数据构造 SQL 语句,ShardingSphere 会完成数据分片的整个过程,并自动对数据进行加密和解密。
ShardingSphere-Proxy 在后台处理这些过程,大大简化了用户的工作,用户只需要处理逻辑表 t_user 的逻辑列 tel。但是,在运行 SQL 查询之前,用户需要告诉 ShardingSphere 如何分片和加密数据。
步骤指南
下面的演示是在 AWS 上进行的,将 Aurora 数据库作为存储节点,运行在 EC2 上的 ShardingSphere 作为计算节点。
1. 创建 ShardingSphere-Proxy EC2 实例

2. 创建 Aurora 数据库
3. 部署 ShardingSphere-Proxy
4. 登录 ShardingSphere-Proxy

5. 初始化 Aurora 数据库
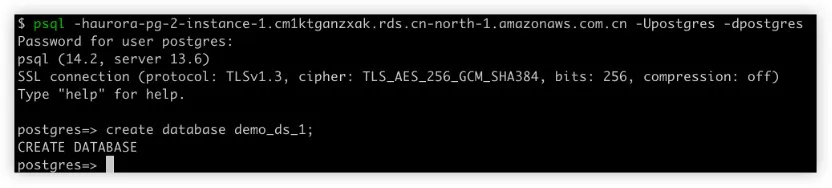
6. 通过 SQL 和分布式 SQL 使用加密规则和分片规则初始化 ShardingSphere
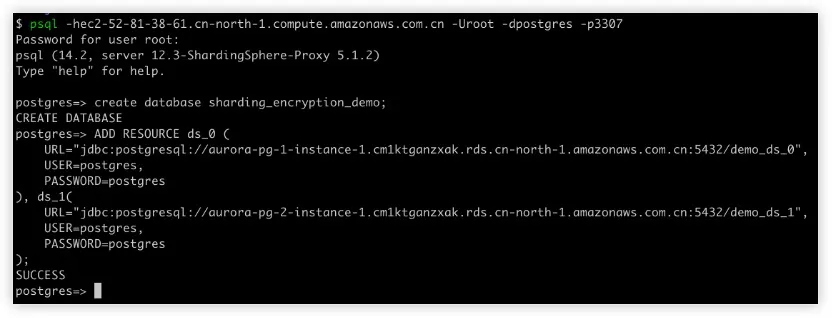
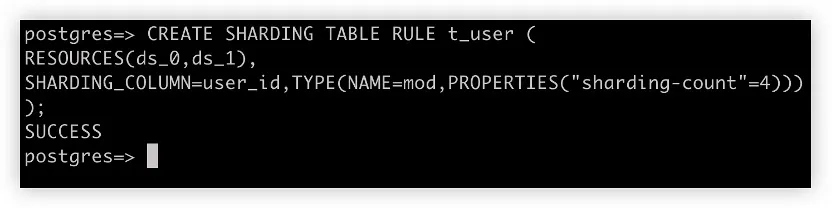

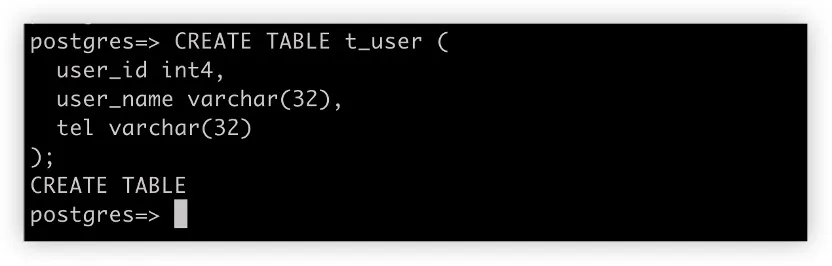
7. 在 ShardingSphere-Proxy 上插入测试数据行
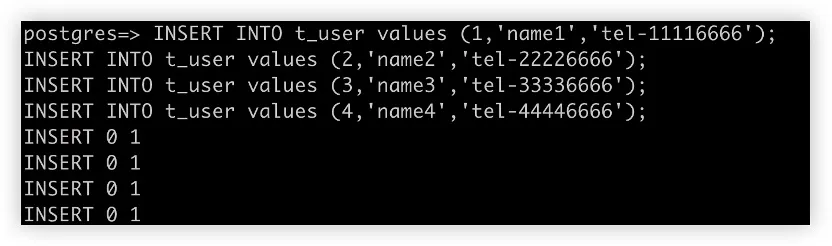
8. 运行查询 SQL
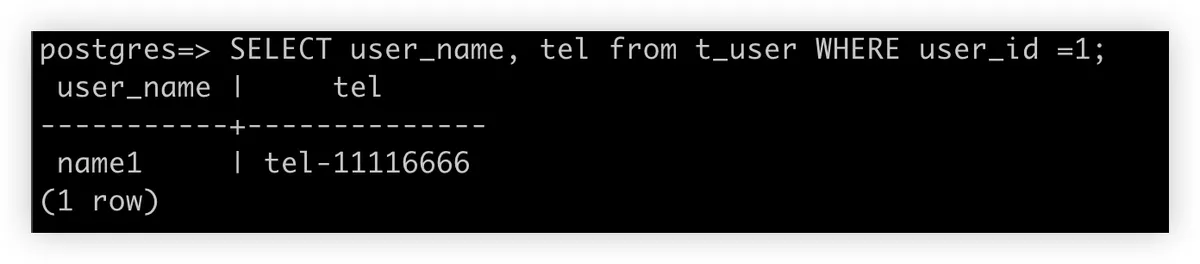
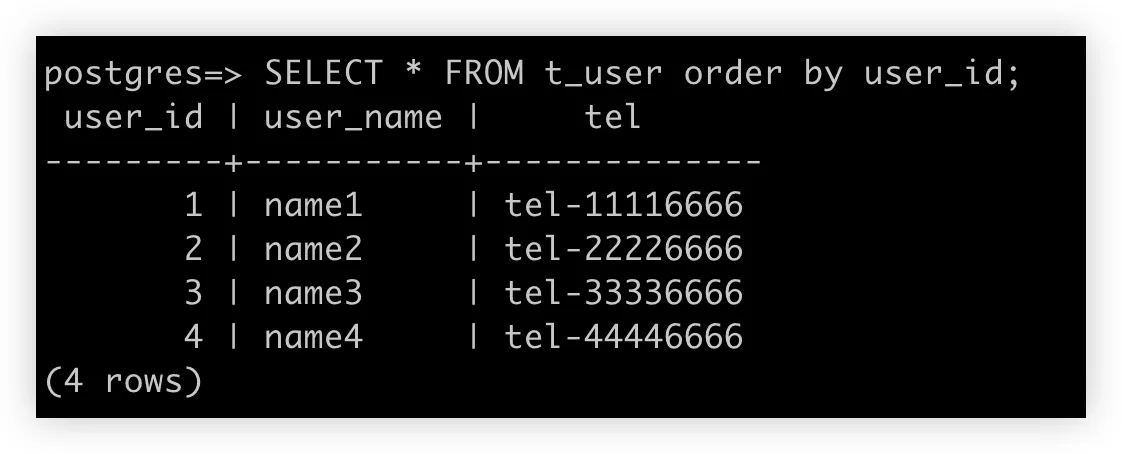
9. 检查 Aurora 数据库中的数据
总结
这篇文章的重点是介绍如何使用 ShardingSphere 在 Aurora 上创建安全的分布式数据库,同时也提供了添加新特性的可能性。
本文提供的指南也可用于将其他各种受支持的数据库作为这种分布式数据库的存储节点。由于开源的强大力量,可能也有许多其他的解决方案可以解决类似的问题,我希望本文的读者能够找到最适合他们的解决方案。
作者简介:
Trista Pan 是 SphereEx 联合创始人兼 CTO、Apache 成员和孵化器导师、Apache ShardingSphere PMC、AWS Data Hero、腾讯云 TVP。曾负责京东数科智能数据库平台的设计与开发。
原文链接:
Creating a Secure Distributed Database Cluster Leveraging Your Existing Database Management System




