

在上一篇文章《获得更好用户体验的必杀器——A/B实验统计学秘籍(上)》中,我们介绍了利用 Apollo 进行 A/B 实验涉及到的术语名词和置信区间与基本误差的相关概念,在下篇中,我们将继续为大家介绍假设检验以及一二类错误,并总结 A/B 实验结果的注意事项。
如何理解假设检验
假设检验是依据反证法思想,首先对总体参数提出某种假设(原假设),然后利用样本信息去判断这个假设是否成立的过程。在 A/B 实验中一般有两种假设:
原假设 (H0):反对的假设。
备择假设 (H1, or Ha):支持的假设。
假设检验的目标是拒绝原假设,它的核心是证伪。一般来说我们在多个备选项中选出其中的某一个有两种思考过程,一种是基于满意法的思考,也就是找到那个看上去最可信的假设;另一种是证伪法,即剔除掉那些无法证实的假设。满意法的严重问题是,当人们在没有对其他假设进行透彻分析的情况下就坚持其中一个假设,当反面证据如山时往往也视而不见。而证伪法能克服人们专注于某一个答案而忽视其他答案,减少犯错误的可能性。证伪法的思考过程类似于陪审团审判,首先假定一个人无罪,然后收集证据证明他有罪,如果有足够证据说明他有罪,就拒绝他无罪的假设。
在上篇文章我们提到的吃橘子的案例里,世界上有 50%的人爱吃橘子是我们的原假设。由于一次实验得出的置信区间 [80%±1.96*0.04] 不包含 0.5,并且我们 95%确信这个区间包含真值,只有 5%的概率出错,而 5%概率非常小,小到我们可以接受,所以拒绝原假设。
在 A/B 实验中,我们的目标与橘子案例不同的是,我们不是要估算全部用户的转化率,而是在实验组和对照组之中选出更优的方案。因此 A/B 实验的估计量不再是 p,而是 p2-p1 (实验组和对照组的转化率之差)。原假设是 p2-p1=0 (即两者没有差异),因为只有当我们怀疑实验组和对照组的结果不一样, 才有实验的动机,而我们支持的备择假设是 p2-p1≠0(两者有差异)。如果 p2-p1≠0,在此基础上我们还需要确定这种差异是否具有统计上的显著性以支撑我们全量上线实验组方案。
由于抽样误差的存在,A/B 实验可能出现四种结果,而这四种结果中存在两种假设检验错误:当原假设 H0 为真,却拒绝原假设;和当 H0 为假,却没有拒绝原假设 H0。这两种错误分别用 α (alpha) 和 β (beta) 表示,相应的,做出正确假设检验判断的概率分别是 1-α 和 1-β。
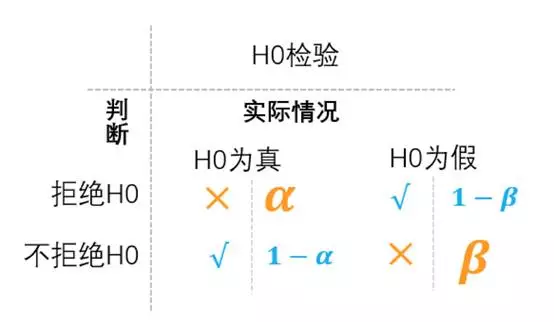
一类错误和统计显著性
一类错误(Type I Error)指错误的拒绝原假设。对于 A/B 实验来说就是实验组相比对照组有提升,然而实际却没有差别。这里所说的有提升,是相对于样本而言的,在总体上实验组是否相比对照组有提升,这是我们关心却无从知晓的。也许对于样本用户,实验组存在提升,但对于总体用户而言,这样的提升并不存在。当我们想知道这次实验的提升,是否适用于总体,是否能使假设检验犯一类错误的概率保持在非常低的水平(例如 5%以下)时,我们就需要特别关注实验是否具有统计显著性 (Statistical Significance)。要想判断实验是否具有统计显著性,p-value 至关重要。
p-value 是什么?
以万能的扔硬币为例。我们的原假设是硬币是均匀的,备择假设是硬币不均匀。下表为扔硬币的次数和出现正面朝上的概率。
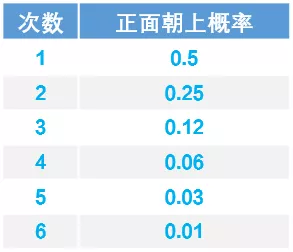
当扔硬币 1 次,正面朝上了,如果硬币是均匀的,那么发生这件事的概率是 0.5;
当扔硬币 2 次,两次正面都朝上,如果是均匀的硬币,那么发生这件事的概率是 0.5*0.5=0.25;
接着你扔了 3 次,4 次,每次都正面朝上。当扔硬币 5 次的时候,仍然是正面朝上,如果硬币是均匀的,那么发生这件事的概率只有 0.5^5=0.03。这是一个非常小的概率,因为如果硬币是均匀的,是不太可能发生这样极端的事情的。但是这样极端的事情却发生了,这使你怀疑原假设的正确性,因为一枚不均匀的硬币极有可能投出这样的结果,因此你拒绝了原假设,接受了备择假设,认为这是一枚不均匀的硬币。
我们回到什么是 p-value 的问题,在这个例子里,假设一枚硬币是均匀的,扔了 n 次,n 次都正面朝上的概率就是 p-value。对于 A/B 实验而言,p-value 是在实验组和对照组没有差别这个前提条件成立的情况下,实验仍然检测到差异以及更极端情况出现的概率。如果 p-value 非常小,就拒绝原假设,认为实验组和对照组没有差别这个前提是错误的。那么怎么定义非常小这个概念?这时需要用到显著性水平 (significance level) 来做标尺。显著性水平是人为给定的假设检验中犯一类错误的可接受上限,用α表示,在工业届它的取值一般是 5%,这说明我们寻求 95%可能性正确的结果。当 p-value 超过这个值时(即 p-value>0.05),我们会认为这个实验犯一类错误的概率太高,因此用这个实验估计总体是不可信的。当 p-value 小于显著性水平时(p-value< 0.05), 实验达到统计上的显著性,认为这个实验犯一类错误的概率比较小,因此适用于总体。
这里需要注意的是,统计显著性并非实际显著性 (Practical Significance)。p-value 只能告诉你两个版本是否存在差异,并不能说明实验组到底比对照组好了多少。举个例子,在某个 A/B 实验中,实验组相比对照组只有 0.1%的提升,p-value=0.001,这说明这次实验是达到统计显著的,但是实验效果却只提升了 0.1%。是否会为了这 0.1%的提升而全量上线实验组方案,还需要从成本等角度全面衡量实验的商业效果。因此做决策不能仅凭借统计显著性。
另外,对于很多实验,在实验前段时期的显著性是在显著和不显著之间上下波动的,我们需要足够多的样本量和更长的实验周期来涵盖前期的波动直到显著性趋于平稳。
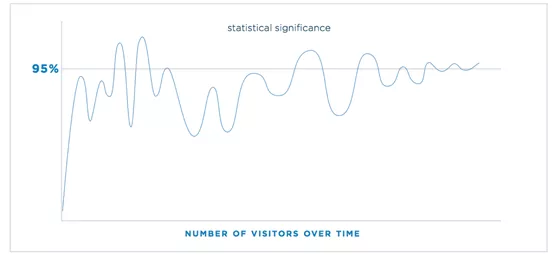
(Source: Statistics for Online Experiments)
上图为统计显著性的波动随样本量增大的变化情况。在实验刚开始时,统计显著性的波动是非常明显的,这可能受到新奇效应 (Novelty Effect) 的影响。对于用户存在感知的 A/B 实验,如 UI 的改版、运营方案的更新、新功能的上线等,实验组所做的任何改变都可能引起用户的注意,好奇心会驱使他们先体验一番,从而导致 A/B 实验中实验组效果一开始优于对照组,p-value 极小,实验效果非常显著。但是一段时间过去后,用户对于新的改变不再敏感,实验组效果回落,显著性可能会下降,最后趋于稳定。足够的样本量能保证一个合理的实验周期,从而避免这种新奇效应的影响。
统计显著性还可以通过置信区间来判断。A/B 实验的原假设是实验组与对照组没有差异,即 p2-p1=0, 那么在刚才的例子里,在样本量达标的前提下,如果实验求得的置信区间不包含 0,也可以说明我们 95%确信实验组相比对照组存在提升。
二类错误和统计功效
在 A/B 实验中,我们还需要注意二类错误 (Type II Error)。二类错误指没有正确的拒绝原假设,即当原假设为假时没有拒绝原假设, 犯这种错误的概率为 β。对于 A/B 实验来说就是实验组和对照组没有差异,但实际实验组和对照组有差异。
一类错误和统计显著性有关;二类错误则和统计功效 (Power) 有关。统计功效是正确的拒绝原假设的概率, 即 1-β。为了让实验结果更准确,实验需要提高统计功效, 一般来说提升到 80%以上,犯二类错误的概率控制到 20%一下,实验结果就比较可信了。
更大的样本量和更长的实验周期能获得更高的统计功效和更准确的测试。为什么这么说?因为对于很多 A/B 实验来说,实验组相比对照组的实际提升值非常小,对于这样微小的提升值,需要更多的样本使其被检测到。通过给定的统计功效值(如 80%)和预期提升幅度, 可以推导出一个实验需要的最小样本量值。比较实验实际进入的样本量和最小样本量值,如果实际样本量能达到这个值,并且达到预期提升幅度,说明统计功效足够,此时就可以下结论了。
总结 A/B 实验结果的注意事项
1:样本量达标
根据给定的统计功效预估实验最小样本量,根据历史数据表现推测未来每日进入样本量。通过最小样本量/每日进入样本量估算实验时长。这可以保证实验达到统计功效,减小犯二类错误的概率。
2:观察实际提升
对比实验组相比对照组的指标在实验周期内的累积提升值。比如我希望实验组相比对照组在某核心指标上有正向提升,实验累积结果确实出现了正向提升。
3:观察统计显著性
若实验周期结束后的累积 p-value<0.05, 或置信区间不包含 0, 则拒绝原假设,说明实验组和对照组有差异,实验具有统计显著性。反之,则不拒绝原假设,说明实验组和对照组没有统计上的显著差异。特别的,观察 p-value 在实验周期的波动,是否在实验后期趋于稳定。
4:结合 2 和 3 和心理预期判断是否应该采纳实验组方案
如果实验累积结果有符合预期的提升,并且实验检测出统计显著性。这时需要结合其他因素(如全量上线实验组方案的成本)衡量该提升幅度是否值得我们采纳实验组方案。一般来说实验组的提升幅度越大,实验效果越明显。在 A/B 实验前,你需要建立一个心理预期,比如实验组相比比对照组至少实际提升 2%,才认为实验组的版本有实际价值。这个最小预期提升幅度 (MDE) 需要在做实验前就具备大致意识,根据具体优化需求确定。如果实验组相比对照组有提升,且检测到统计显著性,却没有达到你心理预期的最小提升,实验组方案就不值得被采纳。
本系列文章介绍了 A/B 实验的统计原理,从抽样和中心极限定理,到统计显著性和统计功效,再到如何将这些理论知识与实际的测试相结合来解读实验结果,希望能帮助大家做出正确的数据驱动决策。
备注:在上一篇文章获得更好用户体验的必杀器——A/B实验统计学秘籍(上)中,关于标准差的计算介绍出现了笔误:
原文内容:
反过来思考,以一次抽样的观测值 p̂ 为中心,往前和往后推大约 1.96 σ 的区间,就有可能抓住那个真实的的 p 。如果重复抽样无数次,构成无数个这样的区间,有 95%个区间会包含真实的 p , 只有 5%个区间不包含。在这个例子里,如果一次随机抽样的结果是 80%的人喜欢吃橘子,标准差为 0.20.8=0.16 (伯努利分布),那么可以说我们 95%肯定这个世界上爱吃橘子的人的比率在 [80%±1.960.16] 这个区间内。通过上面的例子,我们知道置信区间的上界是样本均值+抽样误差,下界是样本均值-抽样误差,95%置信度下的抽样误差是 1.96*样本标准差。
文中的标准差应为 sqrt(0.20.8/100)=0.04,抽样误差为 1.960.04,对应的,我们 95%肯定这个世界上爱吃橘子的人的比率所在[80%±1.960.04]区间内,由于[80%±1.960.04]区间不包含 0.5,并且我们已经 95%肯定这个区间包含真实值,那么先前假设的 0.5 是非常值得怀疑的,是我们应该拒绝的。
本文转载自公众号滴滴技术(ID:didi_tech)。
原文链接:
https://mp.weixin.qq.com/s/SdMx50ZB9dZRBRW7c3NI4Q

Java 避坑指南:Java 高手笔记代码篇
本迷你书包括 86 个业务开发中常见踩坑点。每一个知识点都相当的实用,是程序员业务开发中的必备避坑指南...











评论