

大数据技术自诞生之日起就一直在不断的发展,痛点推动着技术的革新。2019 年双十一当天,中通快递的日订单量超 2 亿单,平均每日产生的数据量超过 20 TB,实时计算每天处理的数据量超过 1000 亿条。面临如此体量的数据,给存储和计算带来了极大的挑战。那么,中通是如何进行海量数据的分析呢?
1 OLAP 在中通的演进
1.1 平台架构
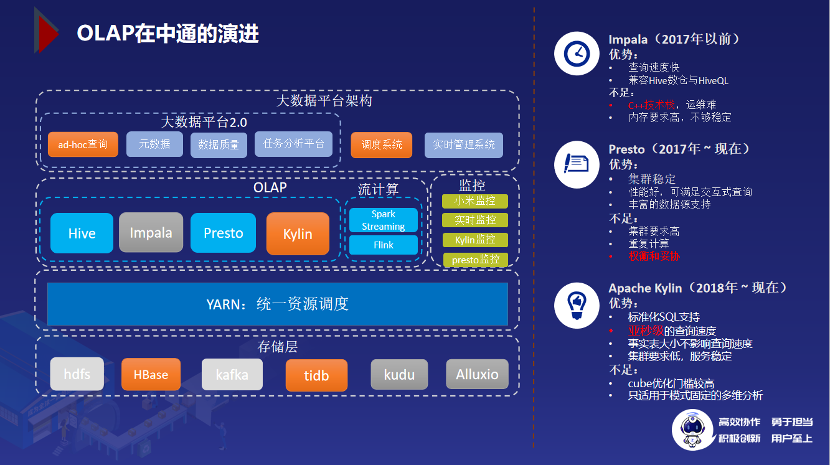
上图是中通快递的“大数据平台架构”图。OLAP 计算引擎以 Kylin 和 Presto 为主,最右侧是每个大数据组件对应的监控系统,最上层则是平台工具层,包括调度系统、Ad-hoc 查询系统等。
1.2 OLAP 在中通的发展历程
1)Impala
在 2017 年以前,是以 Impala 为主进行数据分析与报表计算。相较于 Hive,Impala 有以下几个显著优点:
查询速度快:对比 Hive 有着显著的性能提升。
兼容 Hive 数仓:可以分析 Hive 中的数据。
但随着数据量的不断增长和业务需求的不断复杂,Impala 也暴露出来了一些问题:
内存要求高且不够稳定:偶尔会出现进程挂掉的情况。
C++技术栈:带来了额外的运维成本,难以进行二次开发。
2)Presto
在这样一个背景下,中通在 2017 年引入了 Presto,并在今年上半年引入 Alluxio 对 Presto 常用 Hive 表进行加速,进一步提高 Presto 的查询速度。Presto 具有以下几个优点:
服务很稳定:很少会出现 server 挂掉的情况。
性能非常好:可满足交互式查询甚至是跑一些 ETL 任务。
丰富的数据源支持:基于插件机制可以很方便的分析 Hive、Kudu、kafka 和 Tidb 等其他组件中的数据,甚至可以进行不同数据源的关联分析,例如在一个 SQL 中关联 Hive 与 Kafka 中的数据。
Presto 虽然优点很多,却也存在几点不足:
集群要求较高:想要更快的查询速度就需要更多的机器,更好的网络带宽,更大的内存以及更强的 CPU 去支撑。
重复计算:相同的查询也要重复的拉数据进行分布式计算。这个重复计算有时会给我们带来痛苦,比如说集群繁忙,有时 namenode 负载高、网络出现抖动等都会给查询速度带来影响。为此,我们引入了 alluxio,对 Presto 常用的 hive 表进行加速,如此一来可以大幅提升 scan hive table 的速度。
需要权衡和妥协:你需要在查询速度和查询复杂度上面妥协。这一点先卖个关子,将在后面的“中通为什么选择 Apache Kylin”中重点说明。
3)Apache Kylin
为了解决这个问题,我们在 2018 年调研并引入了 Apache Kylin。Kylin 可以很好的解决海量数据的多维分析问题,并且具有亚秒级的查询响应速度。不但如此,Kylin 还具有以下几个无可比拟的优点:
具有标准化的 SQL 支持:提供了 JDBC/ODBC/Rest API 接口,便于做系统集成。
亚秒级的查询速度:这一点是难能可贵的,在大数据领域,将查询速度提高到亚秒级,凤毛麟角。这不单单是查询速度的提升,更是用户体验的巨大提升。
事实表大小不影响查询速度:随着数据量的不断增长,其他的 OLAP 引擎都会有不同程度的查询速度下降。反观 Kylin,数据的增长只会影响 cube 的构建速度,对查询速度影响很小。
集群要求低且服务稳定,中小企业也养得起 Kylin。在过去 2 年多的时间里,Kylin 集群一直很稳定,没有出现过进程异常退出的情况。
如此可见,Kylin 的优点很多很突出,但不可否认的是它也存在着不足:
cube 优化门槛较高:需要专门的学习与实践。
只适用于模式固定的多维分析:也就是说模型不能总变。
2 为什么选择 Apache Kylin
中通为什么会选择使用 Kylin 呢?只因为它能更好的解决刚刚提到的 Presto 面临的权衡问题吗?不尽然。
2.1 Apache Kylin 简介
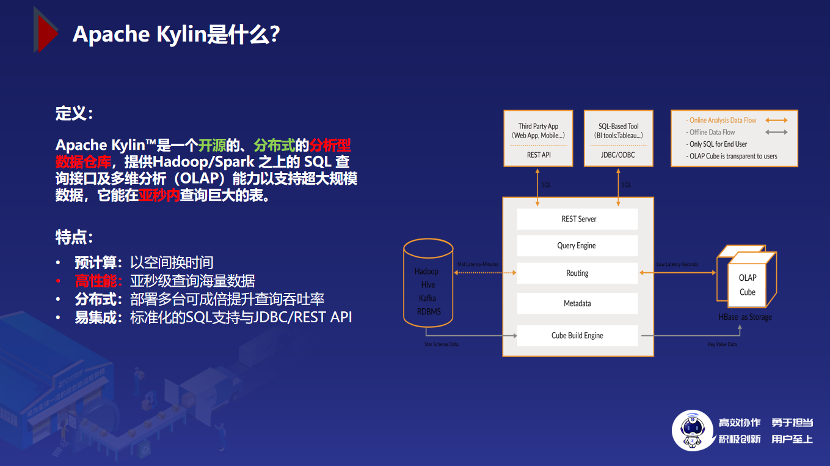
先来回顾一下官网的定义:Apache Kylin™是一个开源的、分布式的分析型数据仓库,提供 Hadoop/Spark 之上的 SQL 查询接口及多维分析(OLAP)能力以支持超大规模数据,并且能在亚秒内查询巨大的表。
从这段话中可以提炼出几个关键字,开源:意味着免费,可自由研究与修改源码。亚秒:查询性能出众。
Kylin 的特点众多,以下 4 项是比较突出的:
预计算:以空间换时间的方式事先根据模型计算出各种可能,让查询引擎做很更少的计算。
高性能:Kylin 在中通 97%以上的查询都能在 1s 内返回结果。
分布式:部署多台可成倍提升查询吞吐率。
易集成:提供 JDBC/Rest API,易于做系统集成。
2.2 基于 Presto 的经典实现
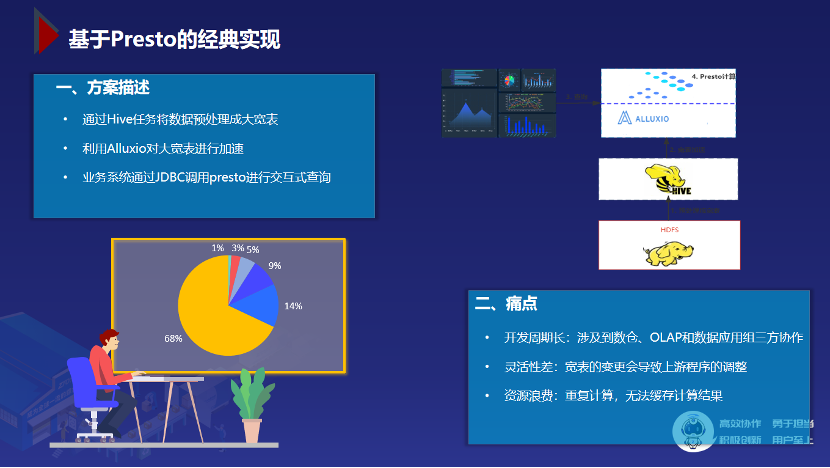
刚刚在分析 Presto 优缺点时有提到需要在查询性能和查询复杂度上面做一个权衡。如果要在 3s 内返回查询结果,查询条件就不能过于复杂,数据量也不能过大。如果想要兼得鱼和熊掌,也不是没有办法,那就是通过 ETL 任务预计算的方式先将数据打平,变成大宽表,再将这张大宽表拉到 alluxio 内存中,最后通过 Presto 做很简单的查询。虽然这种做法能解决问题,但不可避免的引入了更多问题:
开发周期长:首先需要 ETL 的同学先将数据预计算成大宽表,然后利用 alluxio 对这张宽表加速,最后应用组的同学写 sql 写代码,开发成本很高。
灵活性差:可能一个很小的改动都会导致重大的调整。
浪费集群资源:presto 会不厌其烦的重复去拉数据,重复去计算,带来了集群压力和网络带宽压力。
2.3 Apache Kylin VS Presto

1)查询耗时对比
在这样一个背景下,我们引入了 Kylin。经测试,Kylin 在查询性能方面相较于 Presto 少则十几倍多则几百倍的性能提升。某些场景下,Presto 因内存限制等原因干脆就跑不出来,查询被主动 kill 掉。反观 Kylin,表现非常好。
2)Kylin 查询耗时占比
基于内部监控系统抓取到的历史查询数据,进行了简单的统计,其中 97%以上的查询都能在 1s 以内返回结果,1s~3s 的查询有 1.35%,而 3s 以上的查询则只有 0.95%。
3)集群规模对比
以上的测试是在这样一个集群规模下测得的,Presto 50 多台,配置是 64 核,256G。而 Kylin 则是与 HBase 混布,共计 5 台,其中 4 台节点用于 query,每个节点分配了 16G 的内存。
4)小结
Kylin 对比 Presto 带来了上百倍的查询性能提升。
绝大多数的查询在亚秒内返回结果。
集群要求更低,更少的机器带来了更高的查询性能。
3 Apache Kylin 在中通的实践
引入 Kylin 以后,我们是如何使用这个瑞兽的呢?这个瑞兽又是怎样赋能中通快递的呢?带着这个疑问,先来看一个路由件量分析的案例。
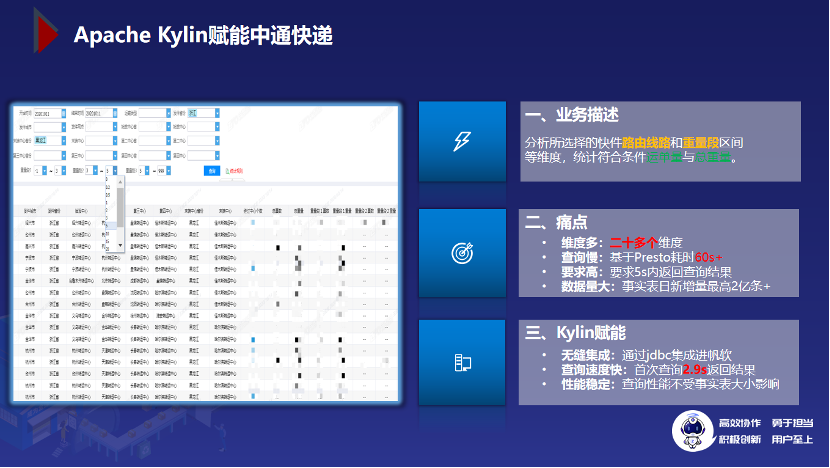
3.1 业务描述
所谓路由件量分析是指统计指定路由线路上的件量、重量以及经过的中心数。里面包含的维度很多,比如说快件的发件省份、经过的首中心、第二中心、末端中心等,这些可以看做是快件路由线路上的维度。另外还包括重量段这个维度,重量段是用来描述快件所在的重量区间,比如 1~3 公斤,3~5 公斤等。最后的指标包括件量、总重量以及经过的中心数等。
对于这个报表,我们有以下几个痛点,
维度多:大概有 20 多个维度;
查询慢:现有的技术方案不能很好的满足查询需求
要求高:要求 5s 内出结果
数据量大,日新增 2 亿多条。
我们通过 Presto 去跑,根据筛选条件的不同,查询时间从 20s 到 60s 不等,根本无法满足需求。
3.2 Kylin 如何赋能
基于 Kylin 提供的 JDBC,可以与帆软无缝集成,经过多轮的 cube 优化,最终首次查询耗时 2.9s,后续走缓存查询耗时稳定在亚秒级别,很好的满足了业务需求,解决了痛点。
3.3 Apache Kylin 在中通的规模

Kylin 共部署了 5 台节点,其中 1 台 job 节点, 4 台 query 节点;HBase 有 40 多台;当前 cube 总数 63 个;总 cube 大小是 33 TB 以上;源数据总数有 800 多亿条;每天响应查询数有 1 万以上;其中 97%以上的查询耗时小于 1s 。
3.4 Apache Kylin 与调度系统集成
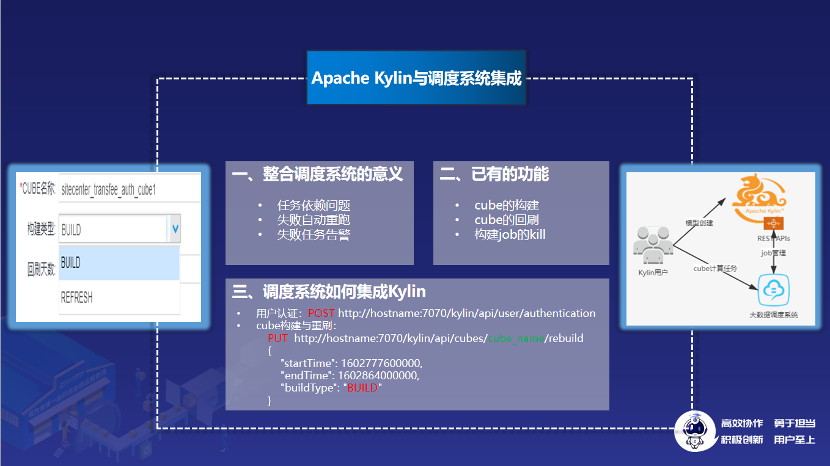
Kylin 提供了大量好用的 Rest API,通过这些 Rest API,可以很方便的与调度系统集成,进行构建任务实例的管理。
1)整合调度系统的意义
为什么要将 Kylin 计算任务集成到调度系统呢?因为通过调度系统,可以很好的解决任务间的依赖问题,任务失败也可以自动重跑,失败的任务会有电话、钉钉告警,便于第一时间发现问题。
2)已有功能
中通的调度系统目前支持指定 cube 的构建、cube 的回刷以及运行中的任务 kill 等功能,基本满足了构建任务的常规管理需要。
3)调度系统如何集成 Kylin
调度系统如何集成 Kylin 进行构建任务的管理呢?Kylin 提供了丰富的 Rest API,可用于和第三方系统做集成。整合过程大体分为两步:
首先调用认证 API 进行用户认证,然后再调用构建 API 进行 cube 的构建。如此一来,就将 Kylin 计算任务纳入到调度系统的管理,非常方便。
3.5 Apache Kylin 监控系统--分钟级监控

接下来是监控部分,监控系统是大数据平台的重要一环。我们针对 Kylin 引擎的特点自研了一套监控告警系统。由于没有找到有关 Kylin 查询相关的 Rest API,所以对源码做了二次开发,将查询请求信息主动吐到 Kafka,再由 Kylin 监控系统实时消费落库,用于更进一步的分析。
Kylin 监控主要涵盖三个方面,分别是分钟级的查询监控、天级别的监控分析以及异常监控。首先来看分钟级别的监控,这类监控的特点是粒度比较细,包含的主要功能如下:
每分钟的查询量统计:统计每分钟请求 Kylin 的查询数,可用于查看业务系统在不同时段的查询量,快速定位异常流量。
每分钟失败的查询:统计每分钟里失败的查询数,可用于判断 Kylin 是否存在问题或者是应用系统发出来的查询是否有异常。
第三个是异常 SQL 自动 kill:坏查询会给集群带来波动,异常 SQL 自动 kill 可降低这种影响,保障集群稳定。
3.6 Apache Kylin 监控系统--天级别监控
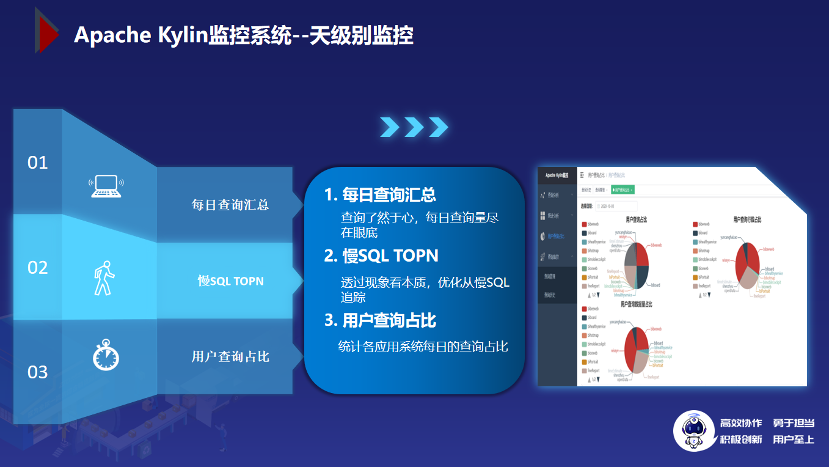
接下来是天级别的监控分析,包括以下三个功能:
每日查询统计:通过这个功能可以清晰的看到每天 Kylin 响应的查询总数,命中缓存的查询也能被统计到。
慢 SQL TOPN:很有用的一个功能,它可以对每天的查询按耗时降序排列,有哪些坏查询,对应的 cube 是否具有优化的空间,一目了然。用户查询占比:这个功能可用来统计各应用系统每日的查询量占比,辅助分析各系统的使用情况。
3.7 Apache Kylin 监控系统--异常监控

最后一个是异常监控,没有界面,只有告警推送,是 Kylin 监控中最重要的部分:
cube 膨胀率监控:根据官方的建议,当扫描到某些 cube 的膨胀率超过 1000%时会发出钉钉告警。
Segment 异常监控:我们曾经有一个线上的 cube,跑着跑着发现数据对不上,经定位发现几天前的一个构建任务没跑成功,导致了 segment 存在空洞,有了这个监控可以很好的避免此类问题的发生。
job 失败监控:当构建任务失败时,会主动推送告警信息。
TTL 未设置监控:这个监控是为了防止有些 cube 在创建过程中忘记设置 TTL 时间,避免历史数据无法得到清理。
Kylin 进程监控:7*24 小时监控 Kylin 进程,重中之重。
3.8 Apache Kylin 的优化实践

接下来是 Kylin 在中通的优化实践,优化这一块,大体分为两个方面,分别是 HBase 相关参数的优化和 MapReduce 相关参数的优化。
1)HBase 优化
Kylin 默认的 HBase 参数中没有开启表压缩,随着 segment 数的不断上涨,给存储带来了负担。通过开启 HBase 表压缩,整体节约 70% 左右的磁盘空间,效果还是很可观的。
另一个是 HBase 超时和重试次数的参数调整,由于后半夜 ETL 高峰,HBase 集群压力很大,这个时候就会出现构建任务读写 HBase 超时,为此,我们调大了超时时间,并增加了重试次数。
2)MapReduce 优化
另一方面是 MapReduce 相关参数的调整,Kylin 默认的最大 reduce 数是 500,在某些情况下会成为瓶颈,为此调大了 reduce 最大数的限制,并将用于计算 Reduce 数量的这个参数从 500 调整为 250,这样一来,reduce 数会增多。经过以上几个参数的调整,部分构建任务时间缩短近了 1/3。
3)数据管理
根据官方的建议,要定期清理元数据、cube 构建临时数据和过期的 HBase 表数据等,并定期备份元数据信息。
3.9 Apache Kylin 的源码与升级

实践的最后一部分,是关于源码和版本升级。研究 Kylin 源码好处很多,可以更深入的了解 Kylin,解决棘手的问题,甚至可以进行二次开发。到目前为止,我们对 Kylin 源码修改还比较少,以满足需求和解决问题为主。主要的改动是查询信息发 送 Kafka 和为更新数据字典时间戳添加分布式锁。之所以添加这个分布式锁是因为我们线上遇到过这个问题,右侧上图是异常的堆栈,当同时回刷一个 cube 的多个 segment 时会偶发性的报错。
最后是重要的 patch 合并和升级,在今年 7 月份完成了一次从 Kylin 2.5.1 到 3.0.2 的升级。
4 未来规划

最后是未来规划,未来,我们主要的探索方向是以下几个方面:
Kylin 智能诊断:作为监控系统的补充,智能诊断同样具有重要的作用。它可以根据预设的规则给出初步的诊断结果,辅助用户排查问题。
查询下压 Presto:Kylin 已经支持查询下压的功能,未来将探索将 Kylin 作为统一的查询入口,对于未命中 cube 的查询下压到 presto,形成优势互补。
自助分析系统:最后一个则是自助分析系统,相信 Kylin 在这个系统中会发挥更大的作用。
作者介绍:
王成龙,2016 年加入中通快递,任 OLAP 组与实时计算平台组负责人,自 2018 年起推动公司 OLAP 引擎的落地工作。
本文转载自公众号 apachekylin(ID:ApacheKylin)。
原文链接:

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论