
作者 | Tina
采访嘉宾 | 韩欣、王国璋
“我对该版本感到非常兴奋,但我们的业务特性决定了我们不能停机升级...”
3 月 30 日,Kafka 背后的企业 Confluent 发布博客表示,在即将发布的 2.8 版本里,用户可在完全不需要 ZooKeeper 的情况下运行 Kafka,该版本将依赖于 ZooKeeper 的控制器改造成了基于 Kafka Raft 的 Quorm 控制器。
在之前的版本中,如果没有 ZooKeeper,Kafka 将无法运行。但管理部署两个不同的系统不仅让运维复杂度翻倍,还让 Kafka 变得沉重,进而限制了 Kafka 在轻量环境下的应用,同时 ZooKeeper 的分区特性也限制了 Kafka 的承载能力。
从 2019 年起,Confluent 就开始策划更换掉 ZooKeeper。这是一项相当大的工程,经过九个多月的开发,KIP-500 代码的早期访问已经提交到 trunk 中。
第一次,用户可以在没有 ZooKeeper 的情况下运行 Kafka。
这是一次架构上的重大升级,让一向“重量级”的 Kafka 从此变得简单了起来。轻量级的单进程部署可以作为 ActiveMQ 或 RabbitMQ 等的替代方案,同时也适合于边缘场景和使用轻量级硬件的场景。
为什么要抛弃使用了十年的 ZooKeeper
ZooKeeper 是 Hadoop 的一个子项目,一般用来管理较大规模、结构复杂的服务器集群,具有自己的配置文件语法、管理工具和部署模式。Kafka 最初由 LinkedIn 开发,随后于 2011 年初开源,2014 年由主创人员组建企业 Confluent。
Broker 是 Kafka 集群的骨干,负责从生产者(producer)到消费者(consumer)的接收、存储和发送消息。在当前架构下,Kafka 进程在启动的时候需要往 ZooKeeper 集群中注册一些信息,比如 BrokerId,并组建集群。ZooKeeper 为 Kafka 提供了可靠的元数据存储,比如 Topic/分区的元数据、Broker 数据、ACL 信息等等。
同时 ZooKeeper 充当 Kafka 的领导者,以更新集群中的拓扑更改;根据 ZooKeeper 提供的通知,生产者和消费者发现整个 Kafka 集群中是否存在任何新 Broker 或 Broker 失败。大多数的运维操作,比如说扩容、分区迁移等等,都需要和 ZooKeeper 交互。
也就是说,Kafka 代码库中有很大一部分是负责实现在集群中多个 Broker 之间分配分区(即日志)、分配领导权、处理故障等分布式系统的功能。而早已经过业界广泛使用和验证过的 ZooKeeper 是分布式代码工作的关键部分。
假设没有 ZooKeeper 的话,Kafka 甚至无法启动进程。腾讯云中间件-微服务产品中心技术总监韩欣对 InfoQ 说,“在以前的版本中,ZooKeeper 可以说是 Kafka 集群的灵魂。”
但严重依赖 ZooKeeper,也给 Kafka 带来了掣肘。Kafka 一路发展过来,绕不开的两个话题就是集群运维的复杂度以及单集群可承载的分区规模,韩欣表示,比如腾讯云 Kafka 维护了上万节点的 Kafka 集群,主要遇到的问题也还是这两个。
首先从集群运维的角度来看,Kafka 本身就是一个分布式系统。但它又依赖另一个开源的分布式系统,而这个系统又是 Kafka 系统本身的核心。这就要求集群的研发和维护人员需要同时了解这两个开源系统,需要对其运行原理以及日常的运维(比如参数配置、扩缩容、监控告警等)都有足够的了解和运营经验。否则在集群出现问题的时候无法恢复,是不可接受的。所以,ZooKeeper 的存在增加了运维的成本。
其次从集群规模的角度来看,限制 Kafka 集群规模的一个核心指标就是集群可承载的分区数。集群的分区数对集群的影响主要有两点:ZooKeeper 上存储的元数据量和控制器变动效率。
Kafka 集群依赖于一个单一的 Controller 节点来处理绝大多数的 ZooKeeper 读写和运维操作,并在本地缓存所有 ZooKeeper 上的元数据。分区数增加,ZooKeeper 上需要存储的元数据就会增加,从而加大 ZooKeeper 的负载,给 ZooKeeper 集群带来压力,可能导致 Watch 的延时或丢失。
当 Controller 节点出现变动时,需要进行 Leader 切换、Controller 节点重新选举等行为,分区数越多需要进行越多的 ZooKeeper 操作:比如当一个 Kafka 节点关闭的时候,Controller 需要通过写 ZooKeeper 将这个节点的所有 Leader 分区迁移到其他节点;新的 Controller 节点启动时,首先需要将所有 ZooKeeper 上的元数据读进本地缓存,分区越多,数据量越多,故障恢复耗时也就越长。
Kafka 单集群可承载的分区数量对于一些业务来说,又特别重要。韩欣举例补充道,“腾讯云 Kafka 主要为公有云用户以及公司内部业务提供服务。我们遇到了很多需要支持百万分区的用户,比如腾讯云 Serverless、腾讯云的 CLS 日志服务、云上的一些客户等,他们面临的场景是一个客户需要一个 topic 来进行业务逻辑处理,当用户量达到百万千万量级的情况下,topic 带来的膨胀是非常恐怖的。在当前架构下,Kafka 单集群无法稳定承载百万分区稳定运行。这也是我对新的 KIP-500 版本感到非常兴奋的原因。”
去除 ZooKeeper 后的 Kafka
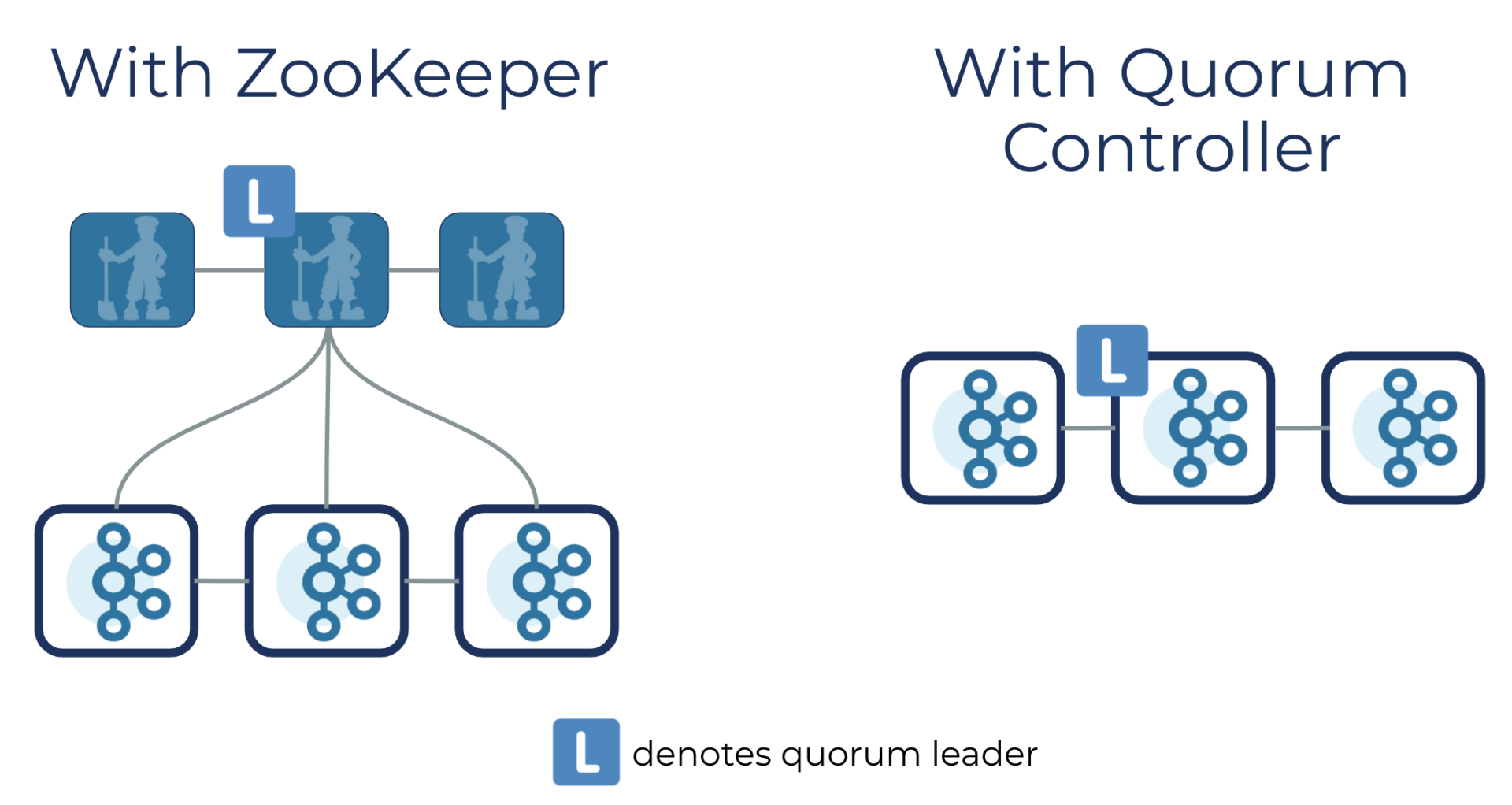
为了改善 Kafka,去年起 Confluent 就开始重写 ZooKeeper 功能,将这部分代码集成到了 Kafka 内部。他们将新版本称为“ Kafka on Kafka”,意思是将元数据存储在 Kafka 本身,而不是存储 ZooKeeper 这样的外部系统中。Quorum 控制器使用新的 KRaft 协议来确保元数据在仲裁中被精确地复制。这个协议在很多方面与 ZooKeeper 的 ZAB 协议和 Raft 相似。这意味着,仲裁控制器在成为活动状态之前不需要从 ZooKeeper 加载状态。当领导权发生变化时,新的活动控制器已经在内存中拥有所有提交的元数据记录。
去除 ZooKeeper 后,Kafka 集群的运维复杂性直接减半。
在架构改进之前,一个最小的分布式 Kafka 集群也需要六个异构的节点:三个 ZooKeeper 节点,三个 Kafka 节点。而一个最简单的 Quickstart 演示也需要先启动一个 ZooKeeper 进程,然后再启动一个 Kafka 进程。在新的 KIP-500 版本中,一个分布式 Kafka 集群只需要三个节点,而 Quickstart 演示只需要一个 Kafka 进程就可以。
改进后同时提高了集群的延展性(scalability),大大增加了 Kafka 单集群可承载的分区数量。
在此之前,元数据管理一直是集群范围限制的主要瓶颈。特别是在集群规模比较大的时候,如果出现 Controller 节点失败涉及到的选举、Leader 分区迁移,以及将所有 ZooKeeper 的元数据读进本地缓存的操作,所有这些操作都会受限于单个 Controller 的读写带宽。因此一个 Kafka 集群可以管理的分区总数也会受限于这单个 Controller 的效率。
Confluent 流数据部门首席工程师王国璋解释道:“在 KIP-500 中,我们用一个 Quorum Controller 来代替和 ZooKeeper 交互的单个 Controller,这个 Quorum 里面的每个 Controller 节点都会通过 Raft 机制来备份所有元数据,而其中的 Leader 在写入新的元数据时,也可以借由批量写入(batch writes)Raft 日志来提高效率。我们的实验表明,在一个可以管理两百万个分区的集群中,Quorum Controller 的迁移过程可以从几分钟缩小至三十秒。”
升级是否需要停机?
减少依赖、扩大单集群承载能力,这肯定是一个很积极的改变方向。虽然目前的版本还未经过大流量检验,可能存在稳定性问题,这也是让广大开发者担心的一个方面。但从长期意义上来讲,KIP-500 对社区和用户都是一个很大的福音。
当版本稳定之后,最终大家就会涉及到“升级”的工作。但如何升级,却成了一个新的问题,在很多 Kafka 的使用场景中,是不允许业务停机的。韩欣拿腾讯云的业务举例说,“微信安全业务的消息管道就使用了腾讯云的 Kafka,假设发生停机,那么一些自动化的安全业务就会受到影响,从而严重影响客户体验。”
“就我们的经验而言,停机升级,在腾讯云上是一个非常敏感的词。腾讯云 Kafka 至今为止已经运营了六七年,服务了内外部几百家大客户,还未发生过一次停机升级的情况。如果需要停机才能升级,那么对客户的业务肯定会有影响的,影响的范围取决于客户业务的重要性。从云服务的角度来看,任何客户的业务的可持续性都是非常重要的、不可以被影响的。”
对于 Confluent 来讲,提供不需要停机的平滑升级方案是一件非常有必要的事情。
据王国璋介绍,“目前的设计方案是,在 2.8 版本之后的 3.0 版本会是一个特殊的搭桥版本(bridge release),在这个版本中,Quorum Controller 会和老版本的基于 ZooKeeper 的 Controller 共存,而在之后的版本我们才会去掉旧的 Controller 模块。”
对于用户而言,这意味着如果想要从 2.8 版本以下升级到 3.0 以后的某一个版本,比如说 3.1,则需要借由 3.0 版本实现两次“跳跃”,也就是说先在线平滑升级到 3.0,然后再一次在线平滑升级到 3.1。并且在整个过程中,Kafka 服务器端都可以和各种低版本的客户端进行交互,而不需要强制客户端的升级。
而像腾讯这样的企业,也会持续采用灰度的方式来进行业务的升级验证,韩欣说,“一般不会在存量集群上做大规模升级操作,而是会采用新建集群的方式,让一些有迫切诉求的业务先切量进行灰度验证,在保证线上业务稳定运行的情况下,逐步扩展新集群的规模,这样逐步将业务升级和迁移到新的架构上去。”
消息系统掀起二次革命?
Apache Kafka 出现之后,很快击败其它的消息系统,成为最主流的应用。从 2011 年启动,经过十年发展,得到大规模应用之后,为什么现在又决定用“Raft 协议”替换 ZooKeeper 呢?对此,王国璋回复 InfoQ 说,Raft 是近年来很火的共识算法,但在 Kafka 设计之初(2011 年),不仅仅是 Raft 方案,就连一个成熟通用的共识机制(consensus)代码库也不存在。当时最直接的设计方案就是基于 ZooKeeper 这样一个高可用的同步服务项目。
在这十年里,Hadoop 生态中的不少软件都在被逐渐抛弃。如今,作为 Hadoop 生态中的一员,ZooKeeper 也开始过时了?韩欣给予了否认意见,“每一种架构或者软件都有其适合的应用场景,我不认可过时这个词。”
从技术的角度来看,历史的车轮在不断向前滚动,学术界和工业界的理论基础一直在不断进化,技术也要适应不断革新的业务不停去演进。不否认有一些软件会被一些新的软件所替代,或者说一些新的软件会更适合某些场景。比如流计算领域,Storm、Spark、Filnk 的演进。但是合适的组件总会出现在合适的地方,这就是架构师和研发人员的工作和责任。
Kafka 发展至今,虽然其体系结构不断被改进,比如引入自动缩放、多租户等功能,来满足用户发展的需求,但针对这次大的改进,且还存在需要验证的现状,网友在 HackerNews 上提出了一个灵魂发问:“如果现在还要设计一个新系统,那么是什么理由选择 Kafka 而不是 Pulsar?”
Confluent 的科林·麦凯布(Colin McCabe)回应这个争议说,起码去掉 ZooKeeper 对 Pulsar 来说是一个艰巨的挑战。Kafka 去除 ZooKeeper 依赖是个很大的卖点,意味着 Kafka 只有一个组件 Broker,而 Pulsar 则需要 ZooKeeper、Bookie、Broker(或者 proxy)等多个组件。但也正因为 抽离出一层存储层(Bookie),使得后起之秀的 Pulsar 在架构上天然具有了“计算存储分离”的优势。
总的来说,在企业加速上云的背景下,无论是 Kafka 还是 Pulsar,消息系统必须是要适应云原生的大趋势的,实现计算和存储分离的功能也是 Kafka 下一步的策略。Confluent 在另一个 KIP-405 版本中,实现了一个分层式的存储模式,利用在云架构下多种存储介质的实际情况,将计算层和存储层分离,将“冷数据”和“热数据”分离,使得 Kafka 的分区扩容、缩容、迁移等等操作更加高效和低耗,同时也使 Kafka 可以在理论上长时间保留数据流。
在发展趋势上,云原生的出现对消息系统的影响是比较大的,比如容器化和大规模云盘,为原本在单集群性能和堆积限制方面存在上限问题的 Kafka,在突破资源瓶颈这里带来了新的思路。Broker 的容器化,堆积的消息用大规模的云盘,再加上 KRaft 去掉了 ZooKeeper 给 Kafka 带来的元数据管理方面的限制,是否是给 Kafka 带来了二次的消息系统革命?容器化的消息系统是否会带来运营运维方面更多的自动化的能力?Serverless 是否是消息系统的未来趋势?云和云原生的发展,给传统的消息系统安上了新的翅膀,带来了新的想象空间。
采访嘉宾:
韩欣,腾讯云中间件-微服务产品中心技术总监,微服务平台 TSF、消息队列 CKafka / TDMQ、微服务观测平台 TSW 等中间件产品的负责人。负责中间件相关产品的规划,架构和落地实施,有超过十三年的研发架构经验。目前关注在云计算中间件相关领域,致力于整合 PaaS 技术资源,构建基于微服务的技术中台,为企业的数字化转型提供基础支持。
王国璋,现就职于 Confluent,任流数据部门首席工程师。Apache Kafka 项目管理委员会成员(PMC),Kafka Streams 作者。分别于复旦大学计算机系和美国康奈尔大学计算机系取得学士和博士学位,主要研究方向为数据库管理和分布式数据系统。此前曾就职于 LinkedIn 数据架构组任高级工程师,主要负责实时数据处理平台,包括 Apache Kafka 和 Apache Samza 系统的开发与维护。




