

迁移学习是什么?前百度首席科学家、斯坦福的教授吴恩达(Andrew Ng)曾经说过:迁移学习将会是继监督学习之后的下一个机器学习商业成功的驱动力。不可否认,机器学习在产业界的应用和成功主要是受监督学习、深度学习及大量标签数据集的推动。但是,当我们没有足够的来自于任务域的标注数据来训练可靠模型时,应该怎么办?在AICon大会现场,InfoQ 采访了百分点首席算法科学家苏海波,聊聊深度迁移学习在 NLP 中的应用实践以及被评效果逆天的 GPT 2.0 到底咋样?
为什么需要迁移学习?
过去几年,我们已经具备了将模型训练得越来越准确的能力,现今比较先进的模型在很多任务上已经达到了不错的效果,大幅降低了使用者的门槛。但这些模型的共同特点都是极其重视数据,依靠大量的标注数据才能实现理想的效果。
但是,在真实的业务环境中,标注数据往往是不足的,而且标注的代价比较高,迁移学习可以帮助处理这些场景,使机器学习在没有大量标注数据的任务域中规模化应用。那么,什么是迁移学习?迁移学习是指利用数据、任务或模型之间的相似性,将在旧领域学习过的模型,应用于新领域的一种学习过程。
概括来说,之所以需要迁移学习,是因为要解决以下四个问题:
深度学习和少标注之间的矛盾:目前深度学习只有在拥有充足标注数据的场景下,才能发挥它的威力。但是在实际的很多问题中,我们没有足够的标注数据,这时就需要迁移学习;
强算力与弱资源之间的矛盾:某些海量数据的模型训练任务,需要非常大的算力,大公司才能烧得起这个钱,而普通人的机器资源是很有限的,需要让他们也能利用这些数据和模型;
通用模型与个性化需求之间的矛盾:通用的模型可以解决绝大多数的公共问题,但是具体到个性化的需求,都存在其独特性,通用模型根本无法满足。因此,需要将这个通用的模型加以改造和适配,使其更好地服务于各种个性化需求;
特定应用的需求:现实世界的某些特定应用,例如个性化推荐,存在用户数据的冷启动问题,那么通过迁移学习则可以将相似领域的知识迁移过来。
迁移学习方法可以分为四类,包括基于样本的迁移学习方法、基于特征的迁移学习方法、基于模型的迁移学习方法和基于关系的迁移学习方法。在这四种方法中,苏海波表示,基于模型的迁移方法在深度神经网络里面应用的特别多,因为神经网络的结构可以直接进行迁移,这称之为深度迁移学习。
模型选择:BERT 还是 GPT 2.0?
在模型选择上,一边是被评效果逆天的通用语言模型 GPT 2.0,一边是结构与 GPT 1.0 类似,但突然爆红的 BERT,百分点是如何决策的呢?苏海波表示,在 2018 年 Google BERT 出现后,百分点就开始在各种 NLP 任务中广泛使用预训练模型技术,并进行持续的优化和改进,包括采用 Google TPU 解决算力的瓶颈、采用 BERT 和上层神经网络进行联合参数调优、采用 BERT 的各种优化模型和数据增强进行效果提升等方面进行探索和实践。
苏海波表示,百分点使用过 BERT 的很多改进版本,包括 XLNet、RoBERTa、ERNIE 等。从整体框架上来说,BERT 和 GPT 1.0 的结构非常类似,它们都包含预训练+Fine-tuning 两个阶段,但在预训练阶段,BERT 采取的是“双向语言模型”,GPT 1.0 采取的是“单向语言模型”,除此之外,二者在其它方面没有本质差异。
GPT 2.0 针对 1.0 做了改进,针对预训练的第一阶段,2.0 采取了更多的高质量训练数据及更大规模的 Transformer 模型,模型参数扩大到了 15 亿;针对第二阶段的 Fine-tuning,1.0 是进行有监督的下游任务,2.0 换成了无监督的下游任务。
GPT 2.0 相比 BERT 而言,因在第一个预训练阶段学到了非常多的通用知识和领域知识,自然语言生成的能力特别强,所以 GPT 2.0 刚推出来的时候,被网上盛传能续写小说或者红楼梦。苏海波补充道,GPT 2.0 的成功,对我们也带来一些启发:如果持续增加高质量的文本数据,就能够不断地让预训练模型学习到更多知识,从而进一步持续提升下游 NLP 任务的效果。这种技术思路是简单有效的,只要有足够的算力就可以实现。
在苏海波看来,BERT 是 NLP 世界的历史性突破,也是 NLP 未来的技术主流。BERT 优势非常明显,不仅在所有 NLP 测试任务都通用,均达到了 state of the art,效果显著提升,而且,BERT 结合了迁移学习的思想,相比传统的深度学习,大大减小了所需要的数据标注量。因在很多传统企业的实际应用场景中,往往标注数据量很少,因此 BERT 对 NLP 的实际应用落地起着非常显著的推动作用。
对于 BERT 的短板,一方面在于模型参数量上亿,需要消费的算力是比较大的,尤其是预训练模型的重新训练,对于一般的开发者而言,硬件资源成本和开发效率如何兼顾是需要考虑的问题。另一方面,BERT 根据上下文单词来预测被 MASK 掉的单词,但是在应用阶段是没有 MASK 标记的,因此在实际的 NLP 任务中,就面临训练过程和应用过程不一致的问题,导致 BERT 在生成类任务方面做的不太好。
此外,BERT 也面临线上服务预测性能问题,线上服务对性能的要求是比较高的,而 BERT 模型比较慢,百分点在实践中就遇到了这样的问题,尤其是在客户没有 GPU 的情况下,这个问题会更加严重。不过目前业界已经有一些 BERT 模型的轻量化解决方案,例如 Google 发布的 ALBERT 模型,百分点也正在开展这方面的研发工作。
深度迁移学习实践
踩坑:硬件成本高昂
早期,百分点通过购买 GPU 用于模型训练,后来发现这种模式根本不够用,这也是百分点实践过程中踩的第一个坑:算力不够。苏海波表示,由于 base 版本的 BERT 模型有 110M 参数,这样的模型即使仅仅根据任务 Fine-tuning 也需要比较长的时间,而重新训练则更是需要以天为单位计算。如果有多个 NLP 任务需要并行开发,完全依靠 GPU 硬件资源就会产生很大的开销成本。
另外,在基于预训练模型进行实际 NLP 开发时,会同时有多个任务进行,如果串行来做,需要花费大量时间等待;如果并行来做,消耗算力太大,硬件成本负担不起。因此,如何探索出一种高效省钱的研发模式是 NLP 算法研究员和工程师面临的普遍问题。百分点使用的方案是租用云上的 GPU 和 TPU 资源,既能控制好成本,又能提高模型的研发效率。
第二点是根据领域数据进行重新预训练。由于 Google 发布的中文 BERT 模型是基于维基百科数据训练得到,属于通用领域的预训练语言模型,对此,百分点加入领域数据进行重新训练,使模型更好地对该领域的语义进行建模。在情感分类和媒体审校等任务的实践中,百分点证明这种方法能进一步提升效果。
BERT:解决标注数据量较少问题
百分点最早在 2018 年就发现,预训练模型 BERT 的效果非常好,在效果验证后决定逐渐将所有算法功能模块全部基于 BERT 进行修改。
以短文本情感分类为例,苏海波表示,百分点原来应用的是卷积神经网络 CNN 模型。CNN 最早被应用于图像,后来也可以应用到文本的情感分析。CNN 主要由输入层、卷积层、池化层和全连接层构成,卷积的计算方式是相邻区域内元素的加权求和,与位置无关,实现了权值参数共享,池化层实现了空间采样,这些方式大大减小了神经网络的参数,避免模型过拟合。
在 BERT 出现之前,团队已经意识到 CNN 模型存在的问题。苏海波补充道,这种模式对标注数据的依赖太大,一个简单的情感分类需要上万条,甚至十几万条标注数据,工作量太大,且实验过程中发现很多场景下根本无法提供这么多标注数据。对比之下,深度迁移学习可以大大降低标注数据量,通过预训练模型和大规模通用性语料,在不需要大量标注数据的情况下就可以得到不错的效果,这是一个革命性创新。
如今,百分点已经在很多 NLP 技术模块中广泛应用 BERT,包括命名实体识别、情感分类、智能问答、NL2SQL 和自动纠错等,并且,这些功能也集成到了百分点的认知智能应用产品中,包括智能消费者洞察分析系统、智能检务问答系统、智能商业分析系统、智能媒体审核系统等等。苏海波表示,通过实践证明,相比传统的深度学习模型,BERT 确实大大减少了需要的标注数据量,带来了显著的效果提升。
比如,对于短文本的情感分类任务,BERT 模型在文本前插入一个[CLS]符号,并将该符号对应的输出向量作为这段文本的语义表示,用于情感分类,因为与文本中已有的其它字相比,这个无语义信息的符号会更“公平”地融合文本中各个字的语义信息,最终效果如下所示:
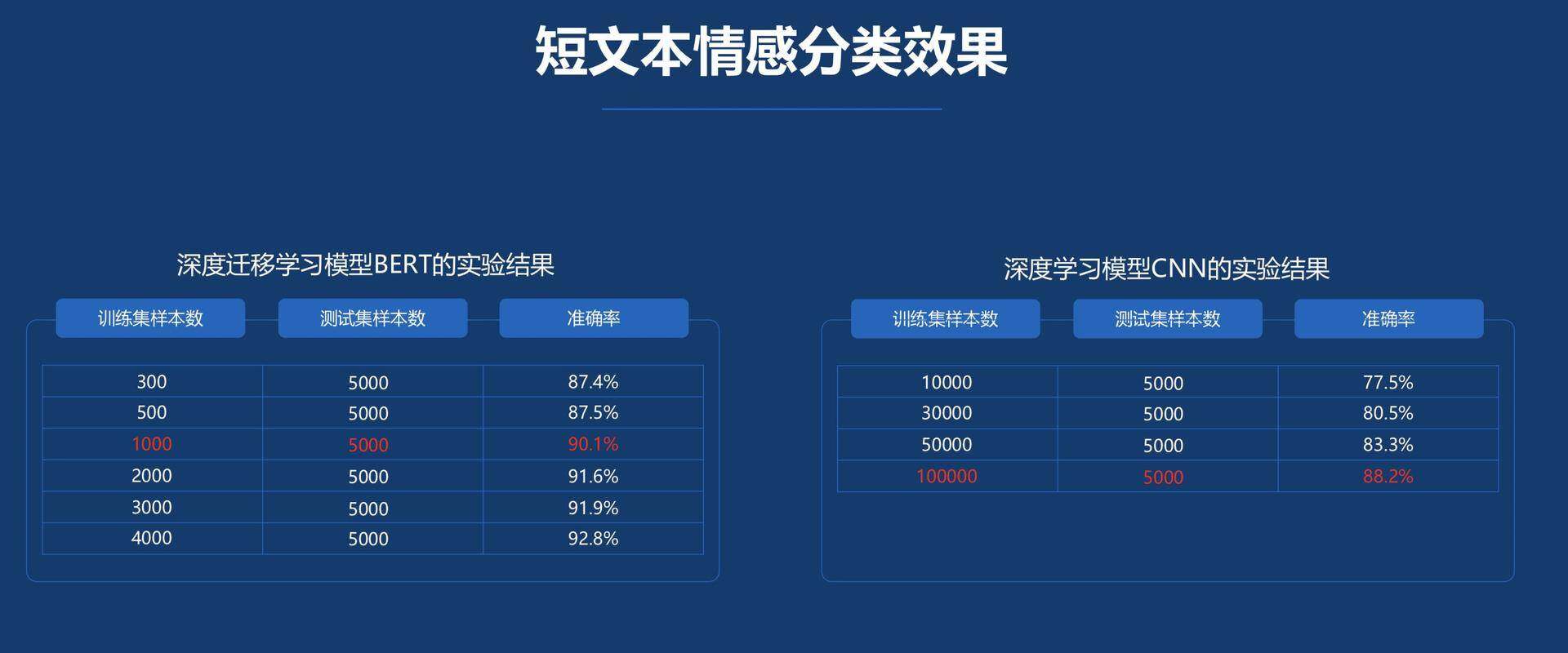
从上图可以看到两个模型随着训练数据的增加,情感分类的准确率都在不断提升。不过二者的对比差异也很明显,BERT 模型在训练集只有 1000 时,预测的准确率就达到了 90%;而 CNN 模型在训练集样本数到 100000 时,预测的准确率才只有 88.2%。这说明,深度迁移学习模型需要的标注样本数远远小于以往的深度学习模型,就能达到更好的效果。
由于 BERT 模型输入文本有 512 个字的限制,短文本分类比较直接,直接输入 BERT 模型即可。但针对长文本,如果直接截取前面的 512 个字,会有信息损失,那么该如何使用 BERT 模型呢?百分点的方案是将长文本进行平均截断,例如按照平均 6 段进行截断,划分为若干个短文本,然后输入对应的 BERT 模型或者各种变种,例如 RoBERTa、XLNet 等,然后再将输出的增强语义向量进行拼接,后面再接上 GRU 模型。
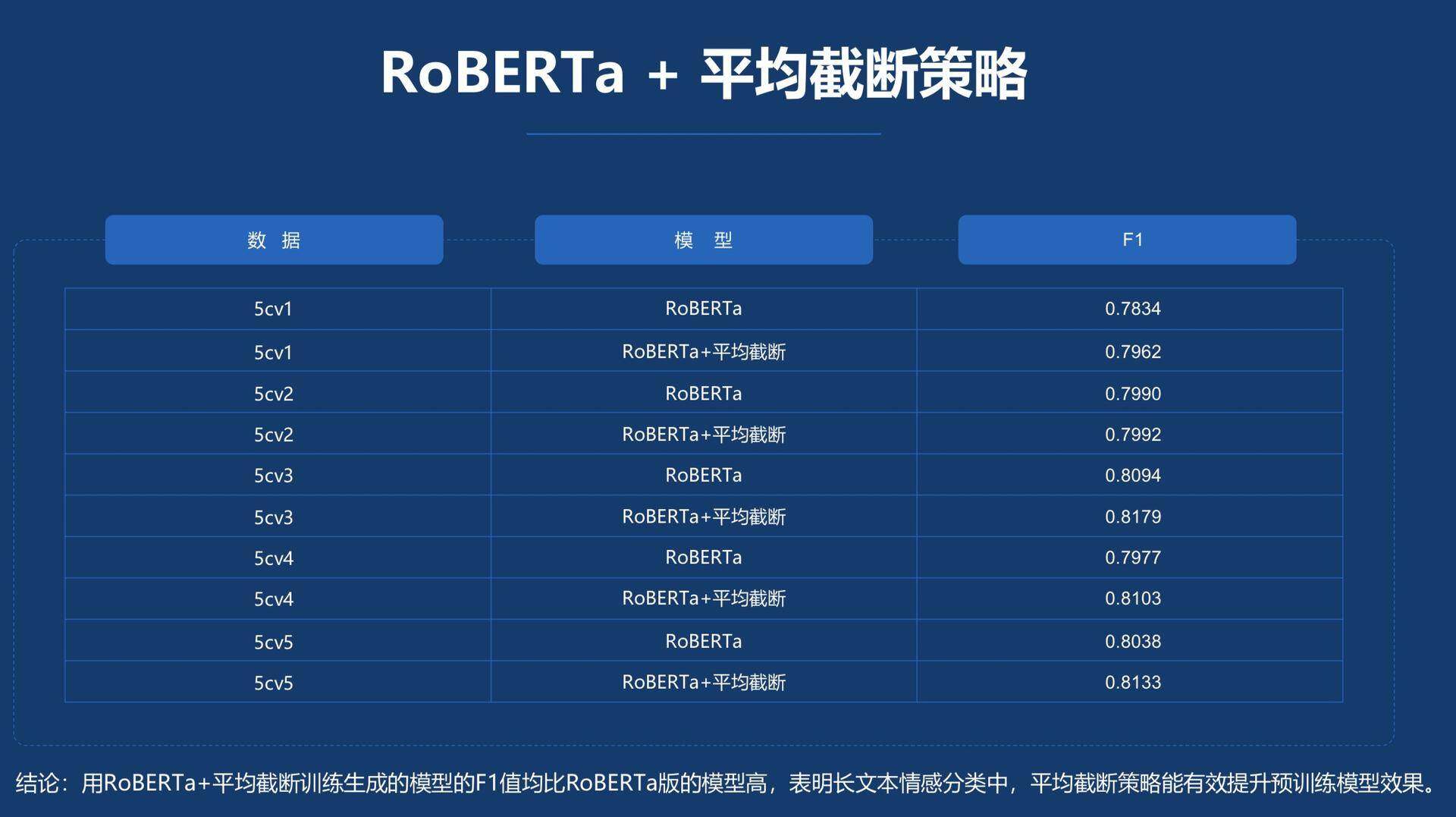
上图是百分点对标注数据集进行 5 折划分,通过交叉验证平均截断策略的效果。实验结果表明,用 RoBERTa+平均截断训练生成的模型的 F1 值均比 RoBERTa 版的模型高,表明长文本情感分类中,平均截断策略能有效提升预训练模型效果。
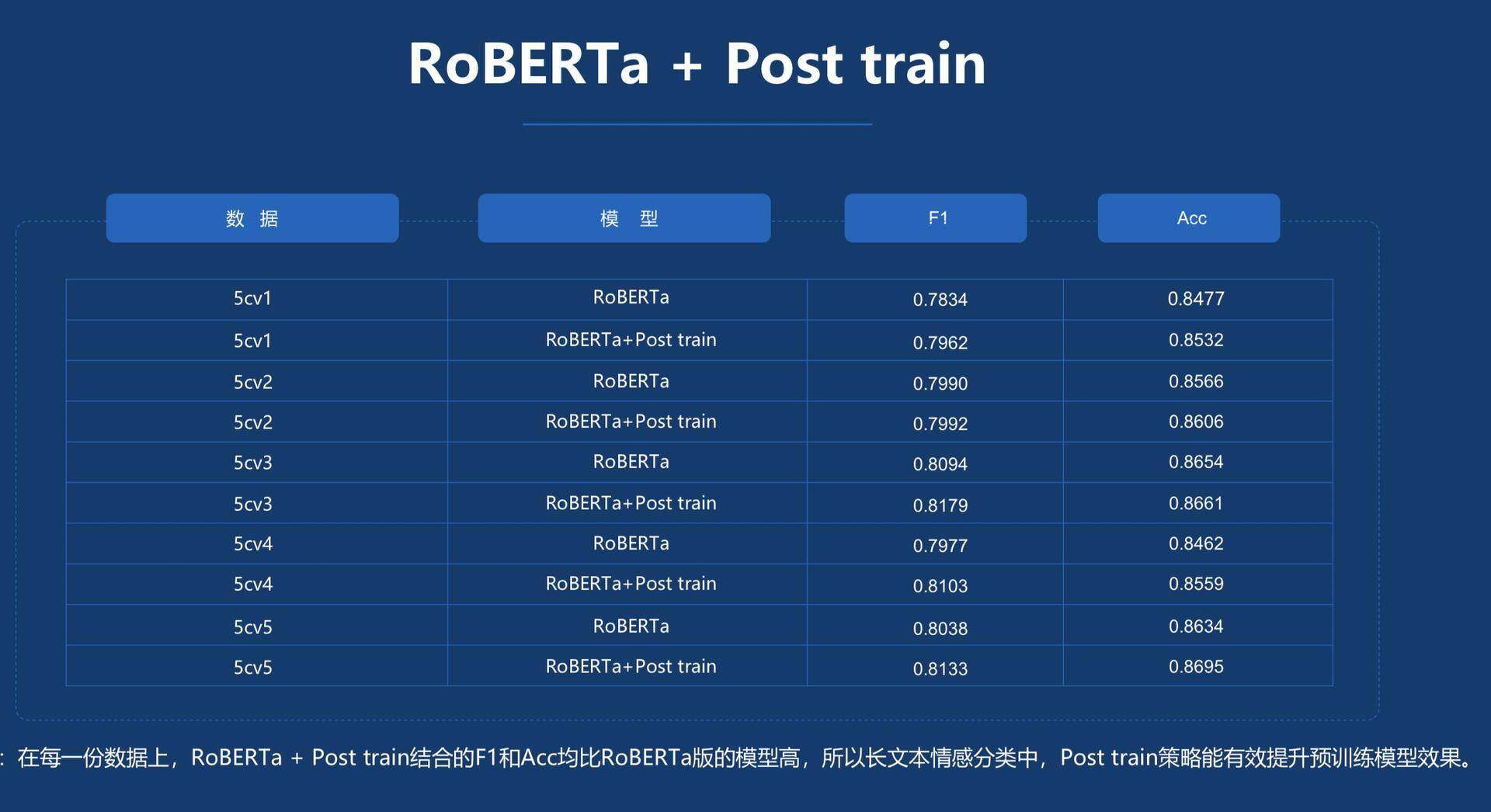
另外,百分点还采用了 post train 的方法提升模型的效果,实验结果证明,在每一份数据上,RoBERTa+ Post train 结合的 F1 和 Acc 均比 RoBERTa 版的模型高,所以在长文本情感分类中,Post train 策略能有效提升预训练模型效果。
实践总结:对 NLP 开发者的三点建议
经过一番前沿探索,苏海波对开发者提出了一些建议:一是注意硬件成本,可以考虑云上租用资源的方式;二是如果对性能要求特别高,需要对 BERT 做一些改进和方案上的优化;三是 BERT 本身采用双向语言模型,可能会出现训练和预测不一致的现象。
RoBERTa 是 Facebook 推出的 BERT 改进方案,采用更多的数据、改进的训练技巧及更长的训练时间。ERNIE 是百度推出的预训练模型,扩展了中文训练语料,而且针对中文的词和实体等语义单元进行建模。百分点在中文情感分类等任务上均用过 RoBERTa 和 ERNIE,效果比 BERT 要好一些。
针对第三个问题,现在也有很多变种在解决这些问题,比如 XLNet。苏海波介绍道,XLNet 是 CMU 和 Google 大脑推出的 BERT 改进方案,进行了 Permutation Language Model 的理论创新,增加预训练数据的规模,采用 Transformer-XL 编码器。因此,在长文档任务(例如阅读理解)和生成类任务的效果比 BERT 表现得更出色。
对于暴力堆数据问题,苏海波认为,它只是目前 NLP 领域突破的一种解法而已,但并不是唯一的解法,模型算法本身也有很多需要突破的地方,包括深度学习、迁移学习、强化学习等。就拿 BERT 模型来举例,其本质也是 NLP 算法技术的突破,是深度迁移学习技术在 NLP 上的突破成果,并不是暴力堆数据的结果。
另外,目前业界如 XLNet、RoBERTa 等各种 BERT 的改进预训练模型,虽然是通过增加预训练的数据进一步提升效果,但除了增加数据,还做了许多模型方面的优化,这些突破都不是仅仅是依靠堆数据就能带来的成果。
未来趋势:三大流派技术融合
采访最后,苏海波表示,准确地说,预训练模型是 NLP 领域新的 baseline,如果要在完全不依赖 BERT 的基础上,提出一个与 BERT 效果相当或者更好的新模型,目前来看可能性非常低。目前业界大部分 NLP 成果均是基于 BERT 的各种改进或者在对应业务场景上进行应用的,而且 BERT 的改进方向比较多,包括针对其在长文本处理、文本生成任务上的不足,与知识图谱进行融合,探索轻量级的在线服务模型等。在 NLP 领域,除了不断提升预训练模型的效果,未来如何更好地与领域的知识图谱融合,弥补预训练模型中知识的不足,也是新的技术突破方向。扩展到整个人工智能领域,未来最可能的趋势就是各流派技术的融合,这将是值得关注的 AI 技术风向。
采访嘉宾:
苏海波,清华大学电子工程系博士,百分点首席算法科学家,擅长人工智能领域的自然语言理解、动态知识图谱、深度学习、个性化推荐以及计算广告学技术;多篇论文发表于 GLOBECOM、ICC、IEICE Transactions 等国外顶尖学术会议和期刊;曾就职于新浪微博,负责广告系统的算法效果优化,以及信息流产品整体算法策略的设计及研发;现负责百分点自然语言处理、知识图谱及智能问答等认知智能方面的算法研发,带领团队成功开发了智能问答、智能校对、智能翻译、智能消费者洞察分析、AI 李白等多款 NLP 应用产品,并在多个行业的客户中成功落地使用。
延展阅读:

极客邦科技 总编辑

中国开发者画像洞察研究报告 2024
分析开发者的行为模式、工作价值、职业发展等内容,帮助整个行业生态更深入地理解开发者,为他们提供更精准...













评论