

监控的重要性不言而喻,它让我们能充分了解到应用程序的状况。Kubernetes 有很多内置工具可供用户们选择,让大家更好地对基础架构层(node)和逻辑层(pod)有充分的了解。
在本系列文章的第一篇中,我们关注了专为用户提供监控和指标的工具 Dashboard 和 cAdvisor。在本文中,我们将继续分享关注工作负载扩缩容和生命周期管理的监控工具:Probe(探针)和 Horizontal Pod Autoscaler(HPA)。同样的,一切介绍都将以 demo 形式进行。
Demo 的前期准备
在本系列文章的上一篇中,我们已经演示了如何启动 Rancher 实例以及 Kubernetes 集群。在上篇文章中我们提到过,Kubernetes 附带了一些内置的监控工具,包括:
Kubernetes dashboard: 为集群上运行的资源提供一个概览。它还提供了一种非常基本的部署以及与这些资源进行交互的方法。
cAdvisor: 一种用于监控资源使用情况并分析容器性能的开源代理。
Liveness 和 Readiness Probe: 主动监控容器的健康情况。
Horizontal Pod Autoscaler: 基于通过分析不同指标所收集的信息,根据需要增加 pod 的数量。
在上篇文章了,我们深度分析了前两个组件 Kubernetes Dashboard 和 cAdvisor,在本文中,我们将继续探讨后两个工具:探针及 HPA。
Probe(探针)
健康检查有两种:liveness 和 readiness。
readiness 探针让 Kubernetes 知道应用程序是否已准备好,来为流量提供服务。只有探针允许通过时,Kubernetes 才会允许服务将流量发送到 pod。如果探针没有通过,Kubernetes 将停止向该 Pod 发送流量,直到再次通过为止。
当你的应用程序需要花费相当长的时间来启动时,readiness 探针非常有用。即使进程已经启动,在探针成功通过之前,该服务也无法工作。默认情况下,Kubernetes 将在容器内的进程启动后立即开始发送流量,但是在有 readiness 探针的情况下,Kubernetes 将在应用程序完全启动后再允许服务路由流量。
liveness 探针让 Kubernetes 知道应用程序是否处于运行状态。如果处于运行状态,则不采取任何行动。如果该应用程序未处于运行状态,Kubernetes 将删除该 pod 并启动一个新的 pod 替换之前的 pod。当你的应用程序停止提供请求时,liveness 探针非常有用。由于进程仍在运行,因此默认情况下,Kubernetes 将继续向 pod 发送请求。凭借 liveness 探针,Kubernetes 将检测到应用程序不再提供请求并将重新启动 pod。
对于 liveness 和 readiness 检查,可以使用以下类型的探针:
http: 自定义探针中最常见的一种。Kubernetes ping 一条路径,如果它在 200-300 的范围内获得 http 响应,则将该 pod 标记为健康。
command: 使用此探针时,Kubernetes 将在其中一个 pod 容器内运行命令。如果该命令返回退出代码 0,则容器将标记为健康。
tcp: Kubernetes 将尝试在指定端口上建立 TCP 连接。如果能够建立连接,则容器标记为健康。
配置探针时,可提供以下参数:
initialDelaySeconds: 首次启动容器时,发送 readiness/liveness 探针之前等待的时间。对于 liveness 检查,请确保仅在应用程序准备就绪后启动探针,否则你的应用程序将会继续重新启动。
periodSeconds: 执行探针的频率(默认值为 10)。
timeoutSeconds: 探针超时的时间,以秒为单位(默认值为 1)。
successThreshold: 探针成功的最小连续成功检查次数。
failureThreshold: 放弃之前探针失败的次数。放弃 liveness 探针会导致 Kubernetes 重新启动 pod。对于 liveness 探针,pod 将被标记为未准备好。
Readiness 探针的演示
在本节中,我们将使用命令检查来配置 readiness 探针。我们将使用默认的 nginx 容器部署两个副本。在容器中找到名为/tmp/healthy 的文件之前,不会有任何流量发送到 pod。
首先,输入以下命令创建一个 readiness.yaml 文件:

接下来,应用 YAML 文件:

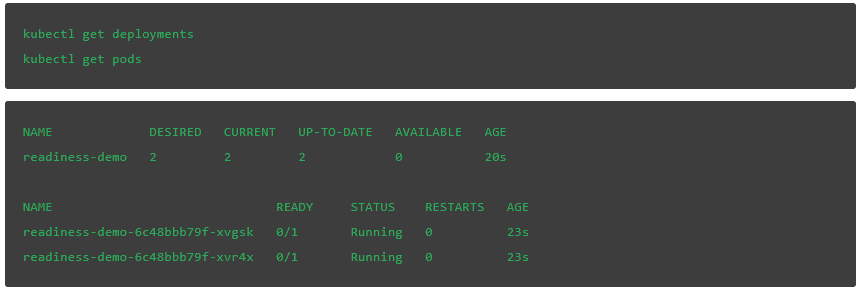
我们将看到正在创建的部署和服务:

除非 readiness 探针通过,否则 pod 将不会进入 READY 状态。在这种情况下,由于没有名为/tmp/healthy 的文件,因此将被标记为失败,服务将不会发送任何流量。
为了更好地理解,我们将修改两个 pod 的默认 nginx 索引页面。当被请求时,第一个将显示 1 作为响应,第二个将显示 2 作为响应。
下面将特定 pod 名称替换为计算机上部署创建的 pod 名称:

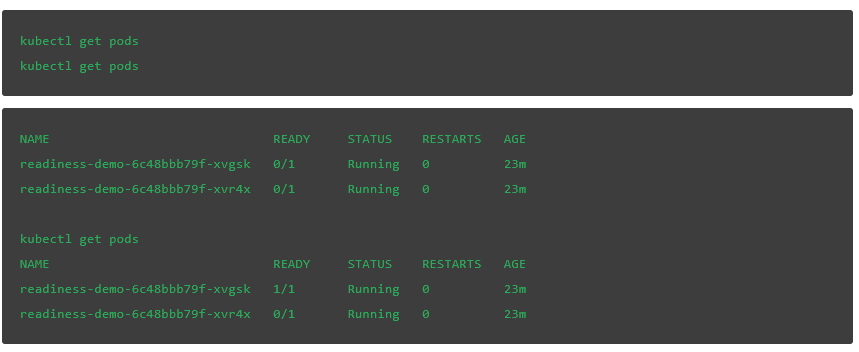
在第一个 pod 中创建所需的文件,以便转换到 READY 状态并可以在那里路由流量:

探针每 5 秒运行一次,因此我们可能需要稍等一会儿才能看到结果:
一旦状态发生变化,我们就可以开始点击负载均衡器的外部 IP:

下面我们应该能看到我们修改过的 Nginx 页面了,它由一个数字标识符组成:

为第二个 pod 创建文件也会导致该 pod 进入 READY 状态。此处的流量也会被重定向:
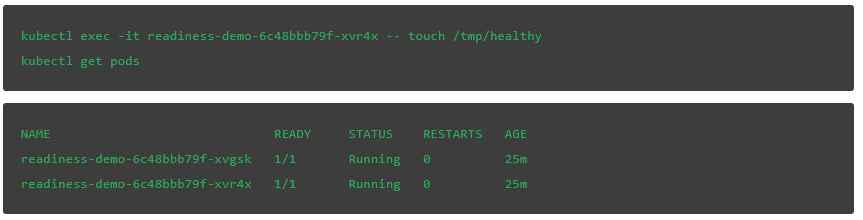
当第二个 pod 标记为 READY 时,该服务将向两个 pod 发送流量:

此时的输出应该已经指明了,流量正在两个 pod 之间分配:

Liveness 探针的演示
在本节中,我们将演示使用 tcp 检查配置的 liveness 探针。如上所述,我们将使用默认的 nginx 容器部署两个副本。如果容器内的端口 80 没有正处于监听状态,则不会将流量发送到容器,并且将重新启动容器。
首先,我们来看看 liveness 探针演示文件:

我们可以用一个命令来应用 YAML:

然后,我们可以检查 pod,并像上面一样修改默认的 Nginx 页面以使用简单的 1 或 2 来表示响应。
首先,找到 Nginx 部署给 pod 的名称:
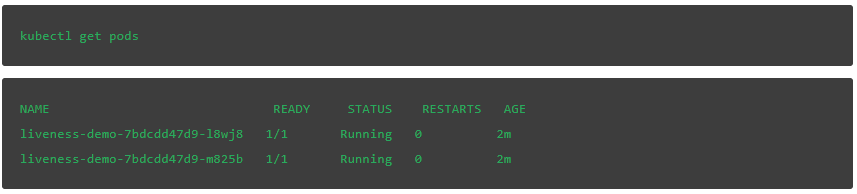
接下来,使用数字标识符替换每个 pod 中的默认索引页:

流量已被服务重定向,因此可立即从两个 pod 获取响应:

同样,响应应该表明流量正在两个 pod 之间分配:

现在我们已经准备好在第一个 pod 中停止 Nginx 进程,以查看处于运行状态的 liveness 探针。一旦 Kubernetes 注意到容器不再监听端口 80,pod 的状态将会改变并重新启动。我们可以观察其转换的一些状态,直到再次正常运行。
首先,停止其中一个 pod 中的 Web 服务器进程:

现在,当 Kubernetes 注意到探针失败并采取措施重启 pod 时,审核 pod 的状态:

你可能会看到 pod 在再次处于健康状况之前进行了多种状态的转换:
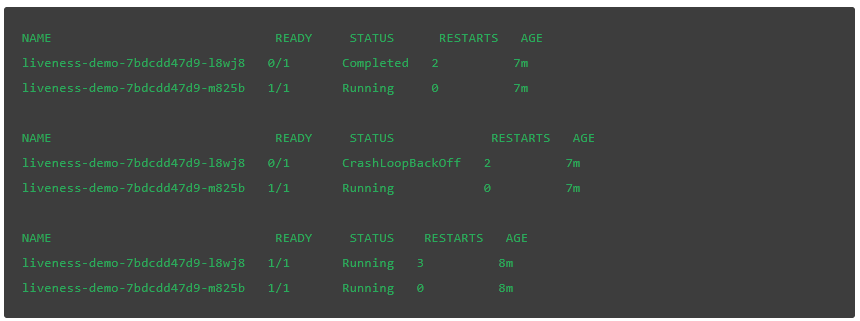
如果我们通过我们的服务请求页面,我们将从第二个 pod 中看到正确的响应,即修改后的标识符“2”。然而,刚创建的 pod 将从容器镜像返回了默认的 Nginx 页面:

这表明 Kubernetes 已经部署了一个全新的 pod 来替换之前失败的 pod。
Horizontal Pod Autoscaler
Horizontal Pod Autoscaler(HPA)是 Kubernetes 的一项功能,使我们能够根据观察到的指标对部署、复制控制器、或副本集所需的 pod 数量进行自动扩缩容。在实际使用中,CPU 指标通常是最主要的触发因素,但自定义指标也可以是触发因素。
基于测量到的资源使用情况,该过程的每个部分都是自动完成的,不需要人工干预。相关指标可以从 metrics.k8s.io、custom.metrics.k8s.io 或 external.metrics.k8s.io 等 API 获取。
在下文的示例中,我们将基于 CPU 指标进行演示。我们可以在这种情况下使用的命令是 kubectl top pods,它将显示 pod 的 CPU 和内存使用情况。
首先,创建一个 YAML 文件,该文件将使用单个副本创建部署:
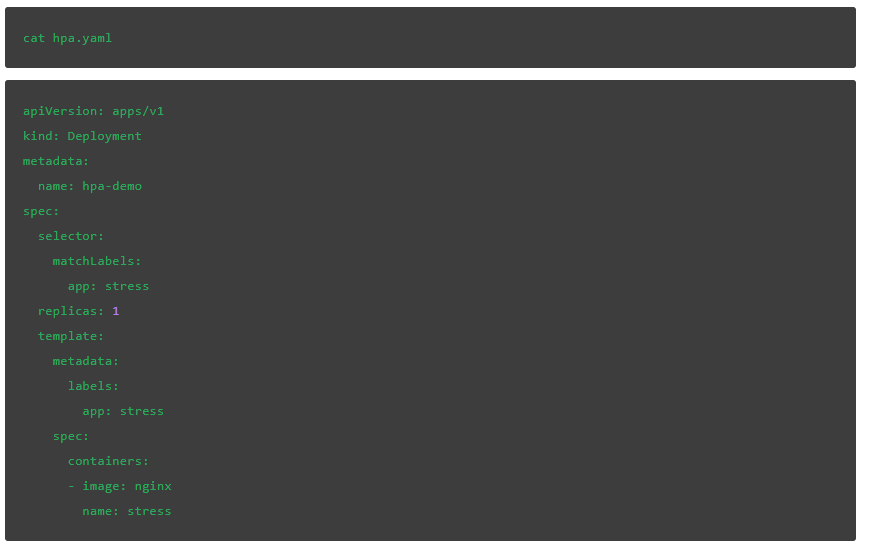
输入以下内容来应用部署:

这是一个很简单的 deployment,具有相同的 Nginx 镜像和单个副本:

接下来,让我们了解如何实现自动缩放机制。使用 kubectl get / describe hpa 命令,可以查看当前已定义的 autoscaler。要定义新的 autoscaler,我们可以使用 kubectl create 命令。但是,创建 autoscaler 的最简单方法是以现有部署为目标,如下所示:

这将为我们之前创建的 hpa-demo 部署创建一个 autoscaler,而且预计 CPU 利用率为 50%。副本号在此处设为 1 到 10 之间的数字,因此当高负载时 autoscaler 将创建的最大 pod 数为 10。
你可以通过输入以下内容来确认 autoscaler 的配置:

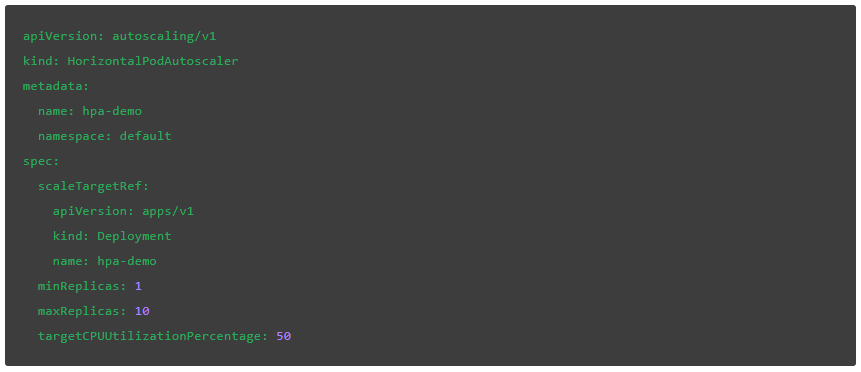
我们也可以用 YAML 格式定义它,从而更容易地进行审查和变更管理:
为了查看 HPA 的运行情况,我们需要运行一个在 CPU 上创建负载的命令。这里有很多种方法,但一个非常简单的例子如下:

首先,检查唯一 pod 上的负载。因为它目前处于空闲状态,所以没有太多负载:

现在,让我们在当前 pod 上生成一些负载。一旦负载增加,我们应该就能看到 HPA 开始自动创建一些额外的 pod 来处理所增加的负载。让以下命令运行几秒钟,然后停止命令:

检查当前 pod 上的当前负载:

HPA 开始发挥作用,并开始创建额外的 pod。Kubernetes 显示部署已自动缩放,现在有三个副本:
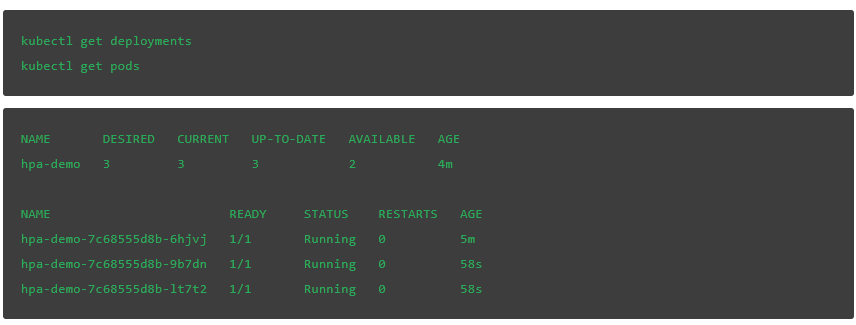
我们可以看到 HPA 的详细信息以及将其扩展到三个副本的原因:

由于我们停止了生成负载的命令,所以如果我们等待几分钟,HPA 应该注意到负载减少并缩小副本的数量。没有高负载,就不需要创建额外的两个 pod。
autoscaler 在 Kubernetes 中执行缩减操作之前等待的默认时间是 5 分钟。您可以通过调整–horizontal-pod-autoscaler-downscale-delay 设置来修改该时间,更多信息可以参考官方文档:
https://kubernetes.io/docs/tasks/run-application/horizontal-pod-autoscale/
等待时间结束后,我们会发现,在高负载的标记处,部署的 pod 数量减少了:
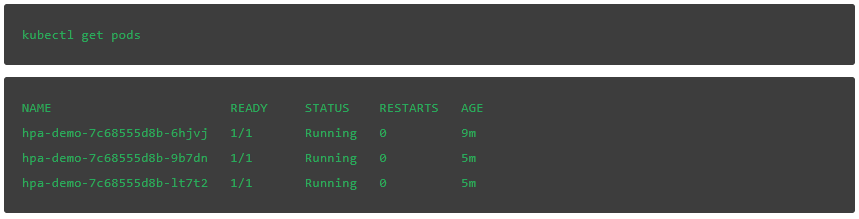
pod 数量会变回到基数:

如果再次检查 HPA 的描述,我们将能看到减少副本数量的原因:

结语
相信通过这两篇系列文章,我们能够深入地理解了 Kubernetes 是如何使用内置工具为集群设置监控的。我们知道了 Kubernetes 在幕后如何通过不间断的工作来保证应用程序的运行,同时可以的话也应该更进一步去了解其背后的原理。
从 Dashboard 和探针收集所有数据,再通过 cAdvisor 公开所有容器资源,可以帮助我们了解到资源限制或容量规划。良好地监控 Kubernetes 是至关重要的,因为它可以帮助我们了解到集群、以及在集群上运行着的应用程序的运行状况和性能。

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论