

背景
截止今年 8 月,知乎注册用户量已突破 2 亿。对于垃圾信息的治理,我们面临着更大的挑战和考验。过去我们通过不断升级「悟空」的策略引擎,通过在行为、环境、资源、文本等多维度组合应用,已经取得了非常不错的效果。近期我们尝试引入深度学习识别垃圾文本,「悟空」对 Spam 的治理能力又迈上了一个新的台阶。
问题分析
我们对当前站内垃圾文本进行了梳理,发现目前主要包括四种形式:
导流内容:这类内容大概能占到社区中垃圾文本的 70%-80%,比较典型的包括培训机构, 美容,保险,代购相关的。导流内容会涉及到 QQ,手机号,微信,url 甚至座机,在一些特殊时间节点还会出现各类的专项垃圾文本,比如说世界杯,双十一,双十二,都是黑产大赚一笔的好时机。
品牌内容:这类内容会具有比较典型的 SEO 特色,一般内容中不会有明显的导流标识,作弊形式以一问一答的方式出现,比如提问中问什么牌子怎么样?哪里的培训学校怎么样?然后在对应的回答里面进行推荐。
诈骗内容:这类内容一般以冒充名人,机构的方式出现,比如单车退款类,在内容中提供虚假的客服电话进行诈骗。
骚扰内容:比如一些诱导类,调查类的批量内容, 非常严重影响知友体验。

这些垃圾文本的核心获益点一方面是面向站内的传播,另一方面,面向搜索引擎,达到 SEO 的目的。
算法介绍
从算法角度可以把这个问题看作是一个文本分类问题,把站内的内容分为垃圾文本和正常文本两个类别。常用文本分类算法有很多,我们不打算详细介绍每一个分类算法,只是分享我们在处理实际问题中遇到的一些问题。
我们遇到的第一个问题是使用 RNN 还是 CNN。一般来说,CNN 是分层架构,RNN 是连续结构。CNN 适合由一些关键词来决定的任务;RNN 适合顺序建模任务 ,例如语言建模任务,要求在了解上下文的基础上灵活建模。这一结论非常明显,但是目前的 NLP 文献中并没有支持性的文章。另外一般来说,CNN 训练速度和预测速度都快于 RNN。考虑到上述站内垃圾文本的主要形式,导流和品牌内容中都会出现关键词,同时对于垃圾文本检测的速度要求比较高,我们最终使用 CNN。一个典型的 CNN 文本分类模型如下图所示。
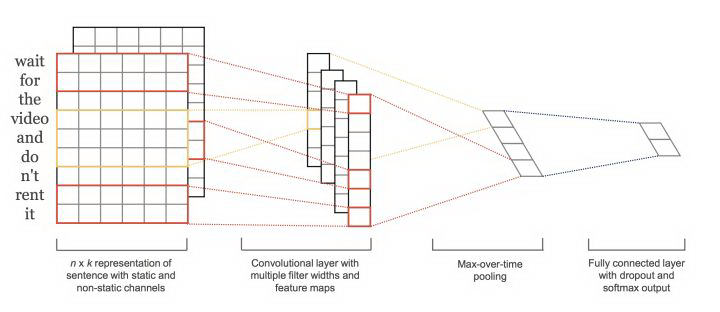
接下来,我们遇到的一个问题是,使用字还是词语作为输入。词语具有比字更高的抽象等级,更丰富的含义。但是导流内容中的 QQ、手机号、微信、url、座机等,通常不会出现在已有词库中,品牌词也具有类似的特点,一般是未登录词。而且,导流内容通常会出现变体词,使用词语作为输入,不能很好地捕捉类似特征。所以,我们最终使用的是字作为输入。
在决定使用字作为输入之后,需要考虑使用在知乎站内语料上预训练的字向量初始化模型的 Embedding 层,还是直接在分类模型中随机生成初始字向量。这里的考虑是垃圾文本的数据分布和知乎站内文本的数据分布具有比较大的区别,垃圾文本相对于站内正常文本是一个比较特定的领域。因此我们使用随机初始化字向量。
在决定使用字向量之后,我们观察到“有意者加我咨询:2839825539”、“找北京·合·合·天·下”等关键信息,按字来计算通常都很长。因此,CNN 需要更大的感受域来提取相关文本特征,如果简单增加卷积核大小,会增加参数数量。我们考虑使用空洞卷积(dilated convolution),来增加卷积的感受域,同时不增加网络参数数量。一个典型的空洞卷积如下图所示。
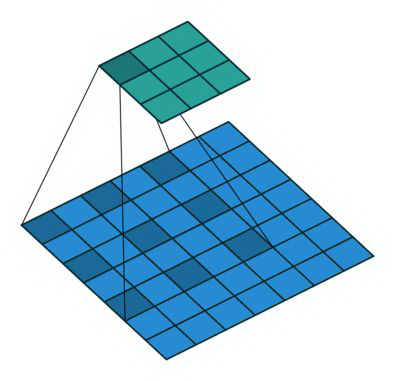
另外我们观察到需要识别的垃圾文本并不都是短文本,还有一部分是长文本。由于文本长度的关系,如果简单将卷积层的输出取平均,输出到全连接层,那么文本能决定是否是垃圾文本的关键特征很可能被其他特征所淹没,导致模型精度难以提升。因此,我们加入了一个 Attention 层,通过它给予关键特征更大的权重。Attention 计算方法如下图所示。

通过上述分析,我们最终采用的模型结构如下图所示。
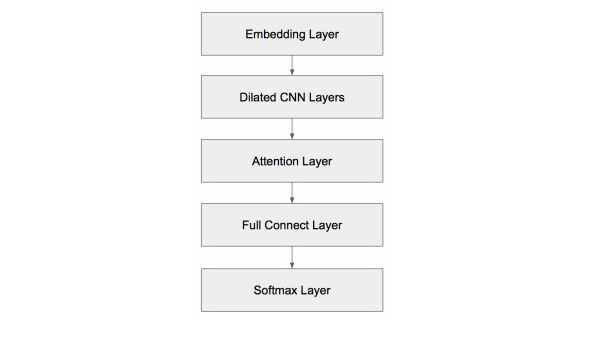
垃圾文本分类算法结构
模型效果
目前,垃圾文本模型会对知乎站内的所有内容进行评分,输出 0-1 之间的分数,系统会对高分内容进行处理。
模型分数在知乎部分业务线上的表现
当前情况下,模型结合其他反作弊维度,可实现对垃圾评分 0.5 分以上的内容进行删除,同时准确率达到 97% 以上。上线以来,每天删除垃圾内容数千条。

模型实时处理
另外值得一提的是端午期间,知乎站内涌现了一波违法违规的 spam,垃圾文本模型覆盖了 98% 以上内容,使得这波攻击大概持续了 1000 条左右就停了。

端午 spam 攻击
后续计划
垃圾文本识别是一个长期攻防的过程,站内垃圾文本会随着时间不断演变,现有模型的效果也会随之变化。为了应对站内垃圾文本的挑战,我们将一直收集 badcase,进一步优化模型的效果。
最后
由于本人的水平有限,如有错误和疏漏,欢迎各位同学指正。
本文转载自知乎。
原文链接:
https://zhuanlan.zhihu.com/p/46877662

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论