

快手是中国领先的短视频和直播社区,拥有超过 3 亿的 DAU 和丰富的社交数据。快手秉承的价值观是真实、多元、美好、有用,致力于提高每一个用户独特的幸福感。而推荐覆盖了快手大部分流量,极大地影响整体生态,并直接作用于 DAU 和 APP 整体时长。短视频推荐需要更多地考虑生态,优化目标和约束非常多,包括消费侧指标、生产侧指标和社交侧指标。本文主要讲解多目标排序在快手短视频推荐中的实践。包括以下几个模块:
快手短视频推荐场景介绍
多目标精排:从手工融合到 Learn To Rank
复杂多目标:Ensemble Sort 和在线自动调参
重排序:Listwise、强化学习和端上重排序
总结和展望
快手短视频推荐场景介绍
1. 关于快手
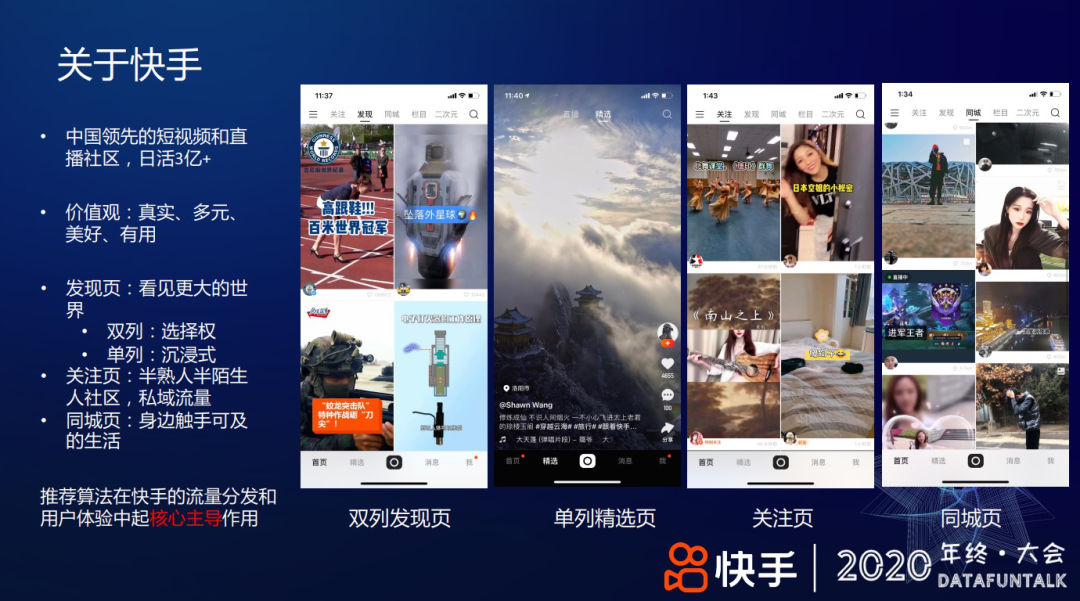
快手主要的流量形态 有 4 个页面:
① 发现页:致力于让用户看见更大的世界,分为单列和双列两种形态。
双列 点选模式,给用户提供选择的自由
单列 上下滑浏览,给用户沉浸式的浏览体验
② 关注页:一个半熟人半陌生人的社区,是私域流量的入口,比如和自己的好友互动,浏览关注订阅的生产者作品。
③ 同城页:带给用户身边触手可及的生活。
在这些流量分发的场景中,推荐算法是起着核心主导作用,直接决定了用户的体验。
2. 排序目标
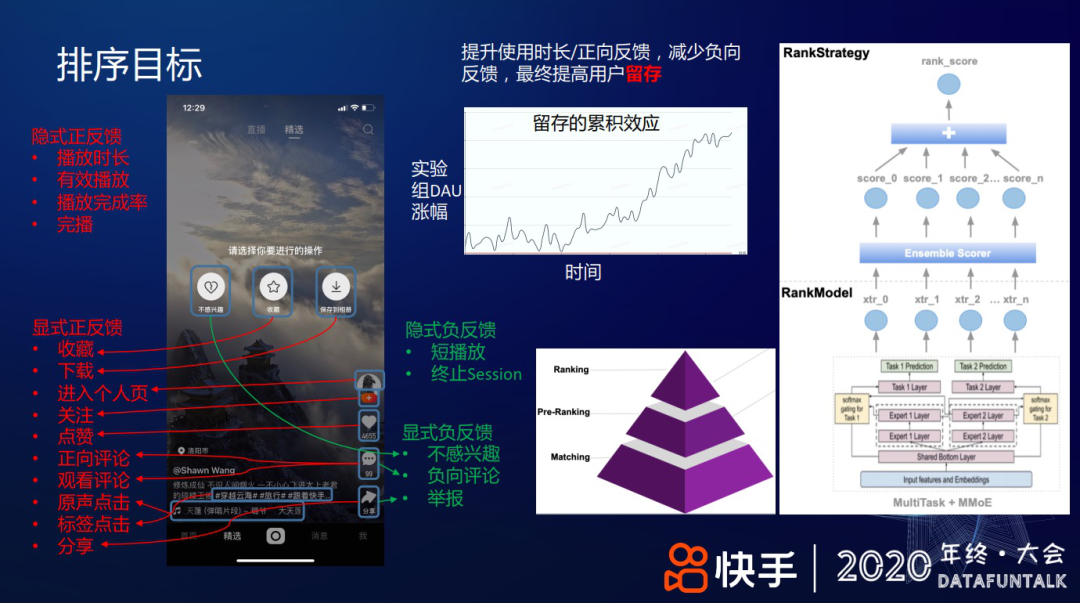
快手短视频推荐的主要优化目标是提高用户的整体的 DAU,让更多的用户持续使用快手,提升用户留存。在具体的排序建模过程,提升使用时长/正向反馈,减少负向反馈,可以提高用户留存。从上图中部曲线可见,留存提升在累计一段时间后会带来 DAU 的置信显著提升。此外,在推荐中,用户反馈分四类:
① 隐式正反馈,用户行为稠密,如用户在无意间的行为——播放时长、有效播放、播放完成率、完播、复播等;
② 显示正反馈,需要用户有意识地做出反馈,不同用户间的行为密度差异比较大,如收藏、下载、关注、点赞,发表正向评论等;
③ 隐式负反馈,用户行为稠密,如短播放、用户终止一次 session 等;
④ 显示负反馈,需要用户显式表达,如不感兴趣、负向评论、举报等。
而推荐的目标是提高正向反馈、减少负向反馈,提高用户体验。推荐分召回、粗排、精排、重排几个环节;在排序阶段,模型预估用户对内容的个性化偏好,比如,对上述各种用户反馈的预估值,然后,用机制策略将预估值融合成一个排序分,对视频排序。
多目标精排:从手工融合到 Learn To Rank
1. 手工融合和简单模型融合
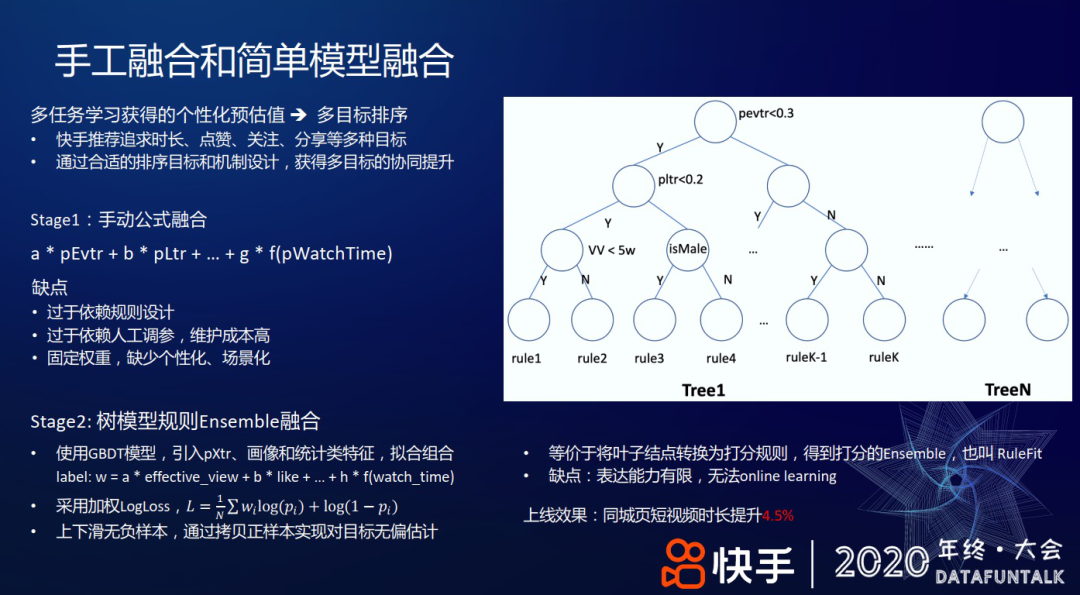
粗排/精排的个性化多任务学习模型,能预估 20 多个不同的预估值,如点击率、有效播放率、播放时长、点赞率、关注率等,那如何用它来排序呢?从多任务学习到多目标排序,中间有一个过渡,即如何把这些预估值融合成一个单一的排序分?快手推荐追求时长、点赞、关注、分享等多种目标,以及减少不感兴趣等负向反馈。通过合适的排序目标和机制设计,获得多目标的协同提升。下面,分别介绍这边 Stage1 的把不同的预估值做一个线性加权融合和 Stage2 的基于树模型的 ensemble 打分两阶段工作。
Stage1:手动公式融合
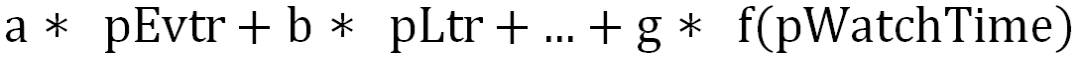
该方法的缺点是过于依赖规则设计;依赖人工调参,且维护成本高;固定权重,缺少个性化、场景化。
Stage2:树模型规则 Ensemble 融合
使用 GBDT 模型,引入 pXtr、画像和统计类特征,拟合组合 label:
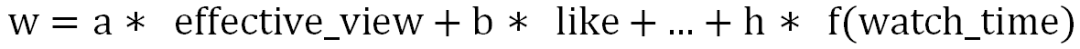
采用加权 Logloss:
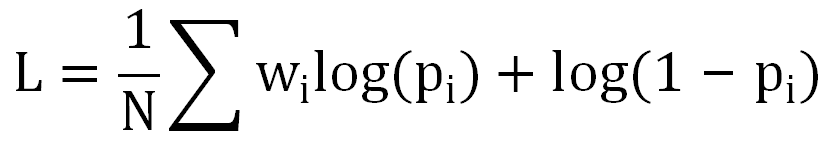
上下滑无负样本,通过拷贝正样本实现对目标无偏估计
等价于将叶子结点转换为打分规则,得到打分的 Ensemble,也叫 RuleFit
该方法的缺点是树模型表达能力有限,且无法 online learning。
上线效果:同城页短视频时长提升 4.5%
2. 超参 Learn To Rank
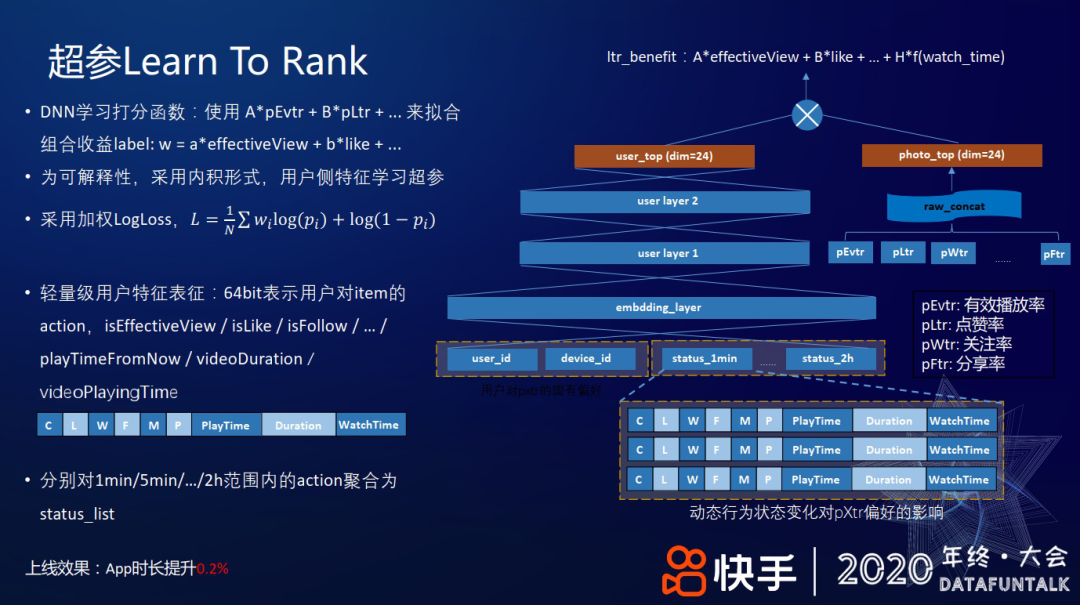
由于树模型的表达能力有限,进而考虑用 DNN 类的网络模型学习打分函数:使用
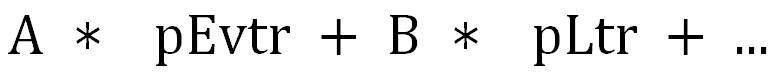
拟合组合收益 label:
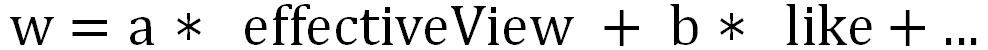
首先,介绍一个简单的双塔形式的 DNN,如上图右侧网络结构所示,视频塔直接把各种个性化预估值拼在一起,形成一个 24 维向量;用户塔的顶层向量通过网络学习,产出一个 24 维向量。最后,对视频塔和用户塔产出的向量做内积,损失函数采用加权 Logloss:
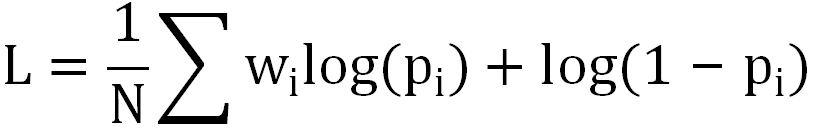
由此,相当于通过学习线性加权的超参数去拟合最终的组合收益。其次,用户特征选用了一种比较轻量级的方式,比如对用户划分不同的时间窗口:过去 1 分钟、5 分钟、15 分钟、...、2 小时,每个时间窗内,对推荐给他的视频,根据用户的反馈拼接成一个向量,这些反馈包括有效播放、点赞、关注、分享、下载、观看时长等,最后,将各时间窗口对应的反馈向量和 ID 类特征一起输入到用户侧网络。
上线效果:App 时长提升 0.2%
3. 端到端 Learn To Rank
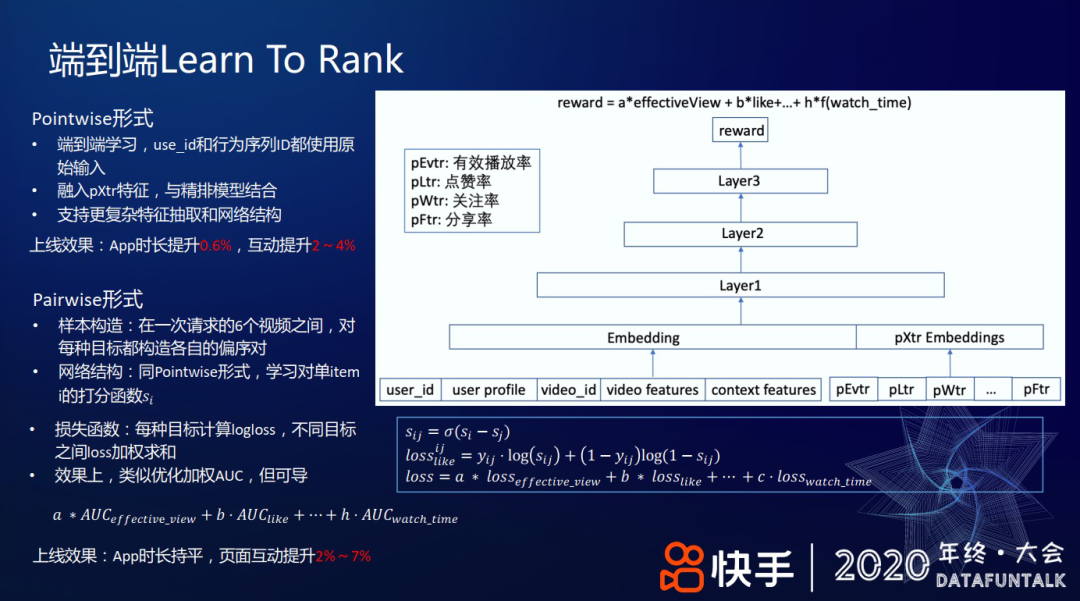
上述双塔形式的 DNN 及其轻量级的特征表达,依然限制了模型的表达能力。继而,考虑端到端学习,主要尝试了 Pointwise 和 Pairwise 两种形式。
① 对于 Pointwise 形式,把 user_id、行为序列等都作为原始输入特征,同时,融入 pXtr 特征,使用精排模型来学习最终的组合收益。因为这种方式支持更复杂的特征抽取和网络结构,如 attention 结构,所以模型的表达能力更强。
上线效果:App 时长提升 0.6%,互动提升 2~4%
② 对于 Pairwise 形式,在一次用户请求返回的 6 个视频之间,对每种目标都如下操作:先通过该目标的正样本和负样本构造偏序对,再使用 DNN 网络学习偏序对的打分,对打分做 sigmoid 变换,最后通过交叉熵损失产出 loss。下述公式表示的是 like 目标:
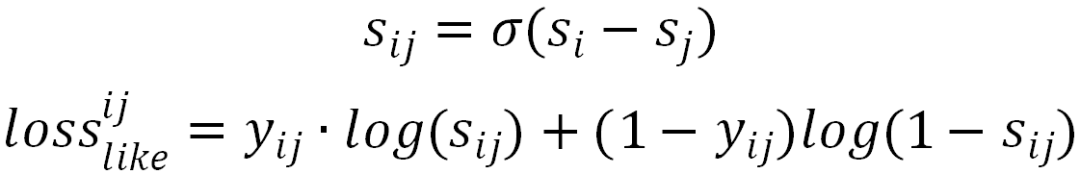
对不同目标的 loss 线性加权,从而可以兼顾多个目标间的权重:
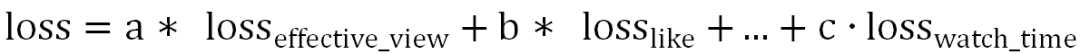
在效果上,上述做法某种意义上可以看做对不同目标的 AUC 加权求和。因为 AUC 本质上是一个偏序的关系,即正样本和负样本之间的偏序。
上线效果:App 时长持平,页面互动提升 2%~7%
复杂多目标:Ensemble Sort 和在线自动调参
前面介绍的是纯粹用模型的方式做多目标排序,但在复杂的业务场景可能不把所有优化的目标都放在模型里。纯用模型的方式做排序,成本比较高,整个线上也会比较繁重;包括一些生态上的调节、一些专项调节都不太方便。接下来,介绍下在复杂的业务场景下,快手是如何做动目标排序的。
1. Ensemble Sort

在上图左侧表格中给出了一些复杂目标,包括用户的互动和时长的多目标线性加权公式,还有分享后带来的外部效用和用户本身分享效用,其中,外部效用包括用户在外部社交网络传播对快手 DAU 的贡献等等。
对多种不同打分逻辑常规融合方法是做线性加权:
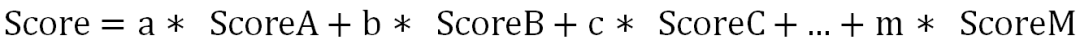
该融合方法存在的问题是不同 Score 之间含义、量级和分布差异较大;显式反馈如点赞率等在不同用户间差异巨大,难以适应统一权重;并且依赖模型预估值绝对大小,预估值分布变化时需重新调节或校准。
在此基础上,尝试在各子项分内做 Normalize 的优化,如把子项分转化为序。具体地,把用户的个性化预估点赞率从小到大排序,把每个具体的值映射成它的序,再把序折合成一个分数,不同的序映射到不同的分数,这与 GAUC 目标一致。
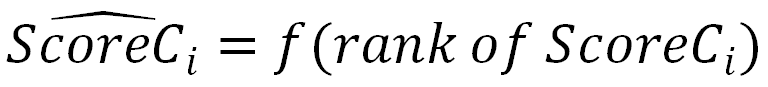
该做法把不同量纲且分布差异巨大的分数 Normalize 到同样维度,可兼容含义差异巨大的子项分,保证各子项分权重在同一量级调节,并且隐式反馈的预估分在不同用户上做到了某种自适应调节。同时,这种序和 AUC 的预估值也是一致的,能很好地和线上模型的效果保持一致性。通过以上的方式把多种不同的打分策略融合在一起,适用于快手线上复杂的业务场景。
上线效果,App 时长提升 0.6%,页面互动提升 2~3%
2. 在线自动调参
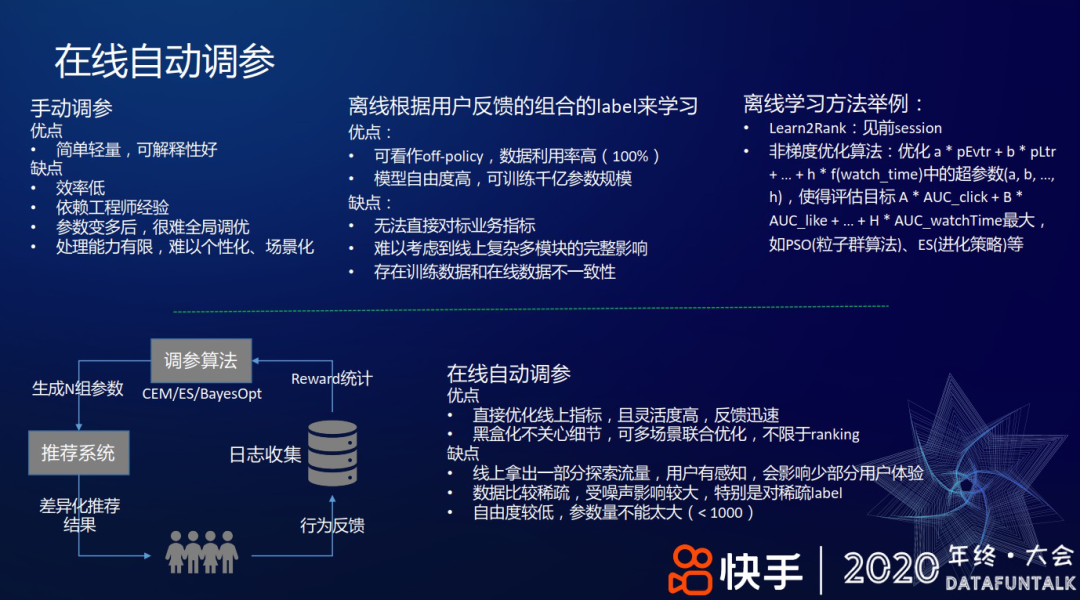
上述 Ensemble Sort 里的线性加权系数主要依赖手动调参,优点是简单轻量且可解释性好,缺点是效率低且依赖工程师经验;如果有两三个参数,可能人还能处理过来,但参数扩充到 10 个/20 个之后,很难手动判断参数之间的关联进行全局调优;并且这些固定参数很难在不同人群上做到个性化和场景化。
解决上述问题的一种方式是 Learn2Rank,即用一个模型离线学习各反馈的组合权重。
优点是这是一种 off-policy 方法;数据利用率高,100%的样本都可以被使用,模型的自由度和复杂度较高,比如 Learn2Rank 可以容纳 item embedding,并使用稀疏特征,可训练千亿规模的参数。
缺点是优化的离线 AUC 无法直接对标业务指标。因为这个过程做了很多的简化,比如从精排到最终吐给用户,中间还有重排、多样性的影响,还有后面的一些和其他如商业化/运营流量的融合等等,所以该方式难以考虑到线上复杂多模块间的完整影响。此外,线下训练数据和线上也存在不一致性。
除上述方法外,其余优化
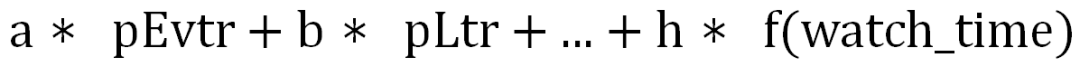
的离线学习方法,如一些非梯度优化算法:PSO(粒子群算法)、ES(进化策略)等,即每次产生一组超参数(a,b,...,h),算一下该组参数对应的评估目标:组合 AUC
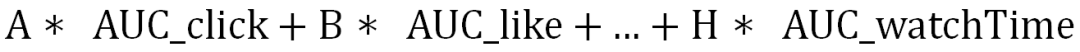
多轮迭代收敛后,选择 AUC 加权和最大的。
上述离线方法都有具有和 Learn2Rank 类似的缺陷,为了解决该问题,我们这边开发了在线自动调参框架。自动在线调参的工作机制如上图左下角所示,即在基线附近探索生成 N 组参数,传给推荐系统后获得这 N 组参数对应的展现给用户的差异化排序结果,从而获得用户不同反馈,收集这些反馈日志并做 Reward 统计,最终输给 CEM/ES/BayesOpt 等调参算法产生下一组更好的参数。经过不停迭代,参数即可逐渐向一个多目标协调最优的方向前进。
优点是直接优化线上指标,灵活性高且反馈迅速,并且算法把推荐系统当作一个黑箱,无需关心内部细节,可以做多场景联合优化,不限于 ranking,在召回等场景也可以用。
缺点是需要线上拿出一部分流量做探索,用户有感知,会影响少部分用户体验;每组几万或几十万的用户 积累几个小时的数据,只能产生一个样本点,由此数据较稀疏,受噪声的影响较大,特别是一些稀疏的 label,如分享、下载、收藏等 稀疏 label;能容纳的参数量较小,一般几十到数百,相对离线学习的参数规模小很多。
接下来,介绍下在线自动调参的具体实践。

线上给 5%流量做探索,每次探索几十组参数。在每次分发时,探索组和基线组同始同终,以基线组的样本量为准,每轮收集固定数量样本。这里,收集固定数量样本是因为白天的高峰期和夜晚的低峰期流量大小不一样,如果按时间尺度去划分,可能不同时间的样本量大小差异会产生方差噪声。
Reward 设计模块主要是衡量在每组参数下,时长和互动指标相比基线的涨跌幅度。比如,观看时长涨了 3%,而点赞跌了 5%。此外,这里区分了收益项和约束项:
收益项是主要优化目标,比如视频观看时长、个人页停留时长、评论区的时长等。
约束项包括各种互动,比如播放、点赞、关注等。约束项使用非线性约束:阈值内做线性的弱衰减,可以用一些约束轻微的去兑换时长;超出阈值的做指数强衰减,避免约束项过分被损害。
调参算法主要开发了离线优化使用的各种超参优方法,包括交叉熵算法(Cross-Entropy Method,CEM)、进化策略(Evolutionary Strategy,ES)、贝叶斯优化(Bayes Optimization)、高斯过程回归(Gaussian-Process Regression,GPR)。这里,主要介绍下实践中常用的 CEM 算法,右侧图例给出了该算法的工作流程:从参数初始的高斯分布出发,一般均值选为线上基线参数,方差手动设置,然后根据该高斯分布随机生成 N 组参数,每组参数都做在线 AB 测试、收集反馈、计算 Reward,选择 Reward 最好的 TopK 组参数,并统计着 K 组参数的均值和方差,并对方差做微小扰动(防止过早陷入局部最优)后得到新的高斯分布,根据新高斯分布继续采样获取新样本...经过若干次迭代,最终会收敛到一组较好的参数。该算法的优点是简洁、高效,超参很少;0 阶方法,TopK 选取只依赖 Reward 的序,不需要对 Reward 的数值大小进行建模,对噪声更近鲁棒;参数通过高斯分布扰动探索,偏离基线越多的参数选中的概率越小,线上指标相对平稳。
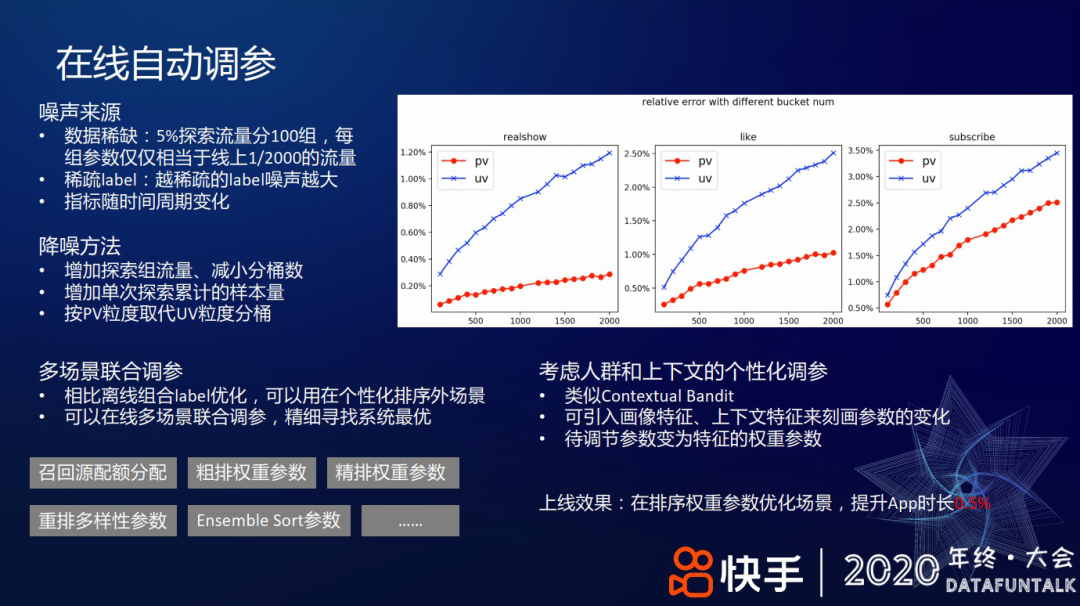
在实践中,困扰比较多的是噪声。噪声主要来源是数据稀缺和稀疏 label。比如把 5%的流量分 100 组,相当于十万量级的用户几小时的样本量只能生成一个样本点,并且每组参数只相当于线下 1/2000 的流量,这么小的流量做 AB 测试方差会比较大。上图右侧展示了“随着分组数的增加,不同互动类型的波动”,如播放量波动范围 0.4~1.2%,点赞量的波动会更大一些,因为稀数 label 的波动性可能会更大一些。
相应地,降噪方法包括:增加探索组的流量、减少分桶数;增加每次累计的样本量,如从两个小时的累计样本量增加到四个小时的累计样本量;用 PV 粒度替换 UV 粒度分桶,因为一个组 UV 可能就几百万,而每个用户每天会有几十刷,使用 PV 样本量就翻很多倍,所以使用 PV 的方差也更小,图中红线给出了按 PV 采样分桶得到的方差,可以看到,方差都更小些。
除个性化排序场景外,我们也在其余更多场景尝试了超参优化方法,比如,召回源配额分配时,主要调控召回源的数量多少、耗时及总收益的最大化;粗排和精排的排序权重参数;Ensemble Sort 的排序权重;重排的多样性权重参数等。在线多场景联合调参,精细寻找系统最优。
此外,考虑人群和上下文的个性化和场景化调参,比如通过一个广义线性模型来根据特征计算参数,类似 Contextual Bandit;引入用户画像特征,比如年龄、年龄段、性别;还有上下文特征,比如一天的上午、中午、晚上 来刻画这些参数的变化。这样,需要调节的参数 就从个性化的权重参数 变成了各个特征的权重。
上线效果:在排序权重参数优化场景,提升 App 时长 0.5%
重排序:Listwise、强化学习和端上重排序
介绍完精排,接下来介绍重排序相关部分。相比精排,重排序最大的特点是需要考虑视频之间彼此的影响,即用户可能因为看了 A 视频对 B 视频可能会促进、也可能会有损,比如看了一个风景的视频,紧接着再看一个风景的视频,它的效用就会降低,而如果看一个差异较大的互补的视频,有可能会提高它的效用。
1. Listwise Rerank
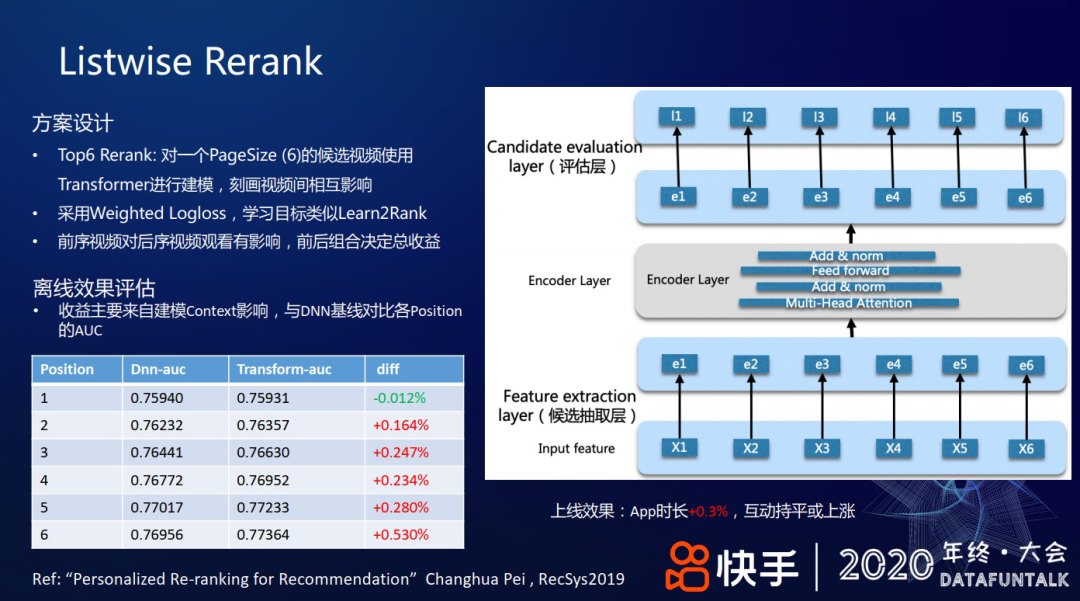
首先,采用类似 Learn2Rank 的学习方案:对精排层返回的 Top6 视频做 Rerank,使用 transformer 进行建模,刻画视频间相互影响:把 6 个视频做特征抽取后,经过 transformer 层的 encoder 得到 embedding 表示,再经过评估层得到输出,损失函数采用 Weighted Logloss。实践中,前序视频对后序视频的播放和效用有影响,比如在上下滑场景,看了前面的视频可能会对后面的视频有影响,但看了后面的视频不会对前面的视频有影响。但作为一个组合收益,需要前后组合决定总收益。比如把五个爱看的视频和五个不太爱看的视频放在一起,如果前五个全是爱看的,而后面五个全是不爱看的,可能用户翻到第七个视频时,就会退出;但如果把爱看和不爱看的夹杂着放,有可能用户能看完十个视频,可能还会从之前五个不爱看的视频里探索出一个新的兴趣,即这种组合的收益会有更大的提升空间。
对于离线效果评估,我们对比统计了“做 transformer 后推荐结果的 AUC”和“DNN 基线,即精排模型给出排序结果的 AUC”,从上图左下角表格可见:在不同位次上,从第 1 位到第 6 位,随着位次增加 AUC 逐渐提升。即考虑前序视频对后序视频的影响,能改善后序视频的推荐体验。
上线效果:App 时长+0.3%,互动持平或上涨
2. 强化学习 Rerank
上述介绍的 Learn2Rank 方式的 top6 重排序整体优化空间较少,所以我们又尝试了使用强化学习做 Rerank。
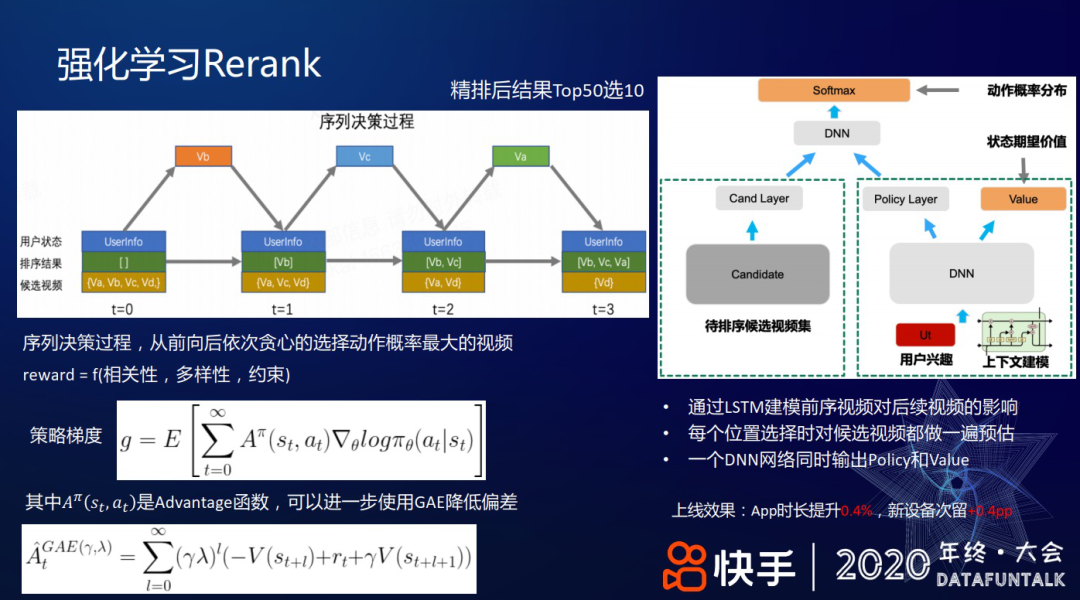
具体做法是从精排后的 Top50 里选出 Top10,通过序列决策的过程,从前向后依次贪心的选择动作概率最大的视频。比如上图左上角表示的过程:有 4 个候选集 a、b、c 和 d,先选出排序分最大的 b,把它作为一个上下文特征;然后选出第二大的 c,然后把选出的 b 和 c 作为上下文特征;再选第三个视频......选择视频时,reward 会兼容相关性、多样性及一些约束项。
根据序列决策的思想,上图右侧给了一个 LSTM 网络结构来建模前序视频对后序视频的影响。DNN 网络同时输出 Policy 和状态值函数 Value,这里 Policy 是通过 Softmax 计算选择每个候选视频(Action)的概率后,选择概率最大的视频。Policy 具体实现上,在挑选每个位置的视频时,把前序视频的作用编码成一个 embedding 向量,对候选集的每个视频做预估和 softmax 变换,最后会选择最大的。
选用策略梯度法解决该强化学习问题:对策略取 log 后求梯度,再用 Advantage 函数加权求和:
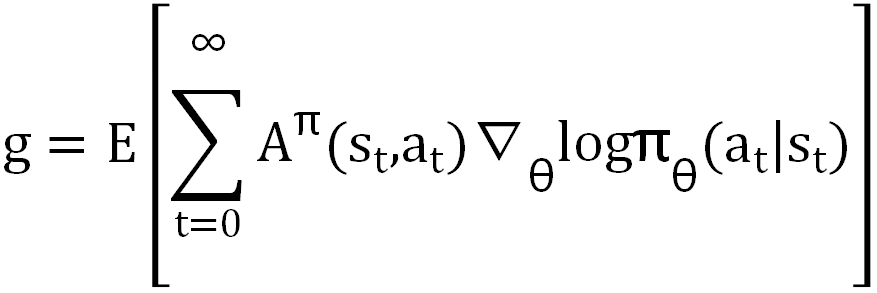
其中 Aπ(st,at)是 Advantage 函数。进一步,使用 GAE 降低偏差,通过 reward 和状态值函数组合得到 GAE:
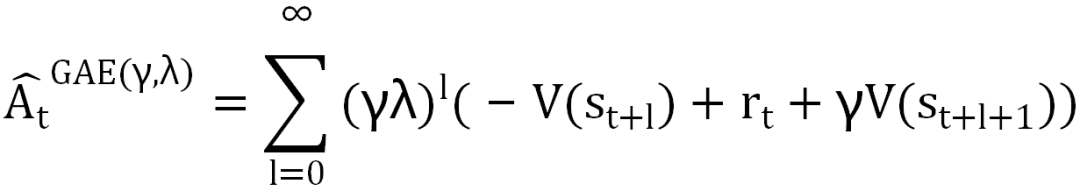
上线效果:App 时长提升 0.4%,新设备次留+0.4pp
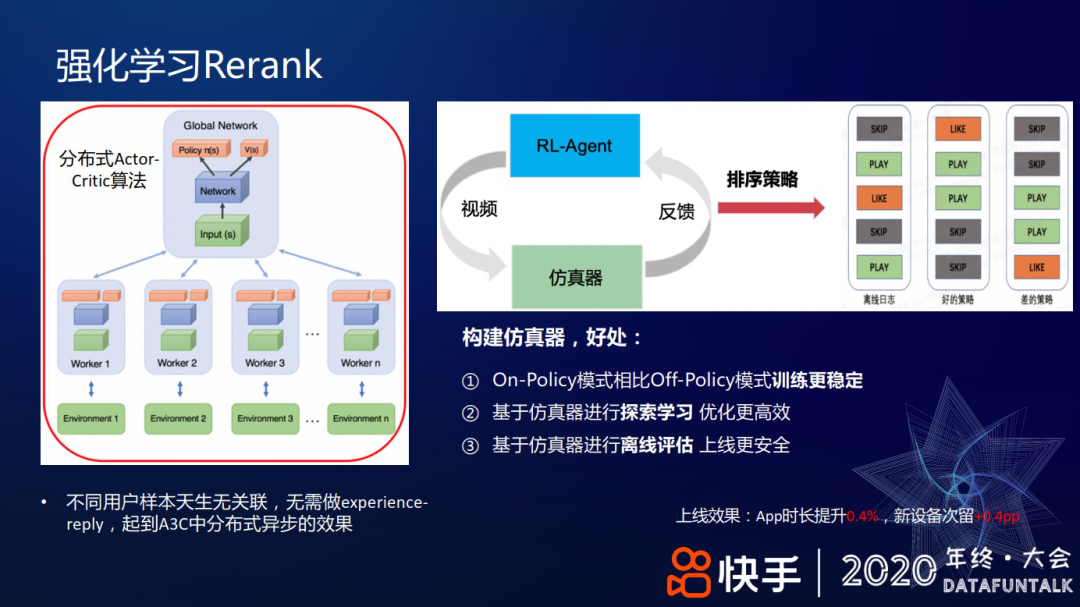
具体训练时,没做 experience-reply,因为不同用户的样本间天然没关联,所以不需要额外的去关联。而是使用一个仿真器帮助训练,好处是使用仿真器做探索学习效率更高,基于仿真器做离线学习,再上线会更安全,使用 On-Policy 相比 Off-Policy 训练会更稳定。上图右侧给出了一个排序策略作用后,不同的模式样例:离线日志有用户快速划过、播放、播放后的点赞行为,通过一个较好的策略能把好模式排在前面。
3. 端上 Rerank
上述介绍的是在云上服务器做 Rerank,同时,我们也尝试了在客户端上做 Rerank。
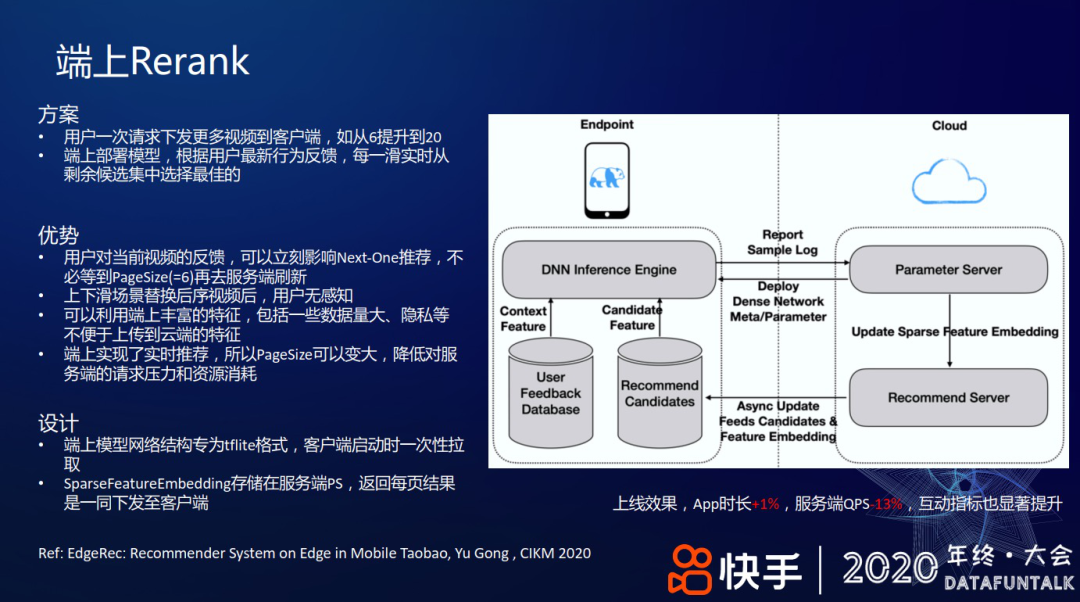
在端上做 Rerank 的具体方案是一次用户请求下发更多视频到客户端,比如从一刷下发 6 个提升到 20 个;在端上部署一个轻量的模型,根据用户对每一个视频的最新反馈实时调整,每一滑实时从候选集中选择最佳的视频。端上 Rerank 的优势有如下几方面:
用户对当前视频的反馈,可以立刻影响 Next-One 推荐,不必等到 PageSize(=6)再去服务端刷新;
上下滑场景替换后续视频后,用户无感知;
可以利用端上丰富的特征,包括一些数据量大、隐私等不便于上传到云上的特征;
端上实现了实时推荐,所以 PageSize 可以变大,降低对服务端的请求压力和资源消耗。
具体结构设计如上图右侧图例,模型用 TFLite 格式,客户端启动时一次性拉取;在每刷请求视频时,把存储在 PS 服务端的 SparseFeatureEmbedding 及其他特征一起下发至客户端。
上线效果,App 时长+1%,服务端 QPS-13%,互动指标也显著提升。
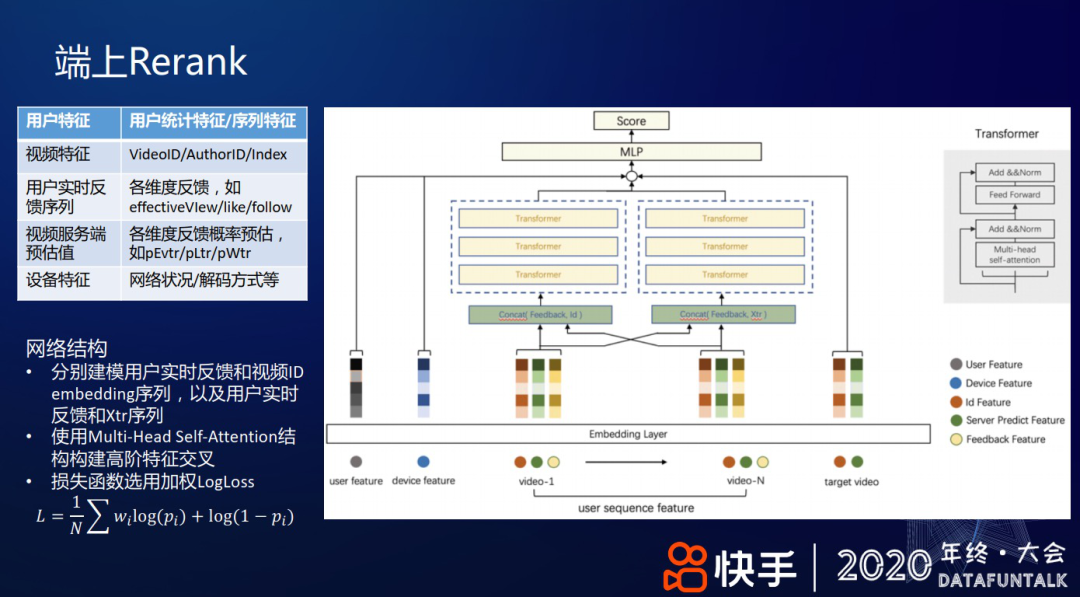
从云端下发到客户端的特征,包括用户特征、视频特征、用户实时反馈序列、视频服务端的各种静态模型预估值和设备特征等,如上图左上角表格所列。
网络结构如上图右侧所示,通过两个 transformer 结构分别建模用户实时反馈和视频 ID embedding 序列、用户实时反馈和 Xtr 序列;使用 Multi-Head Self-Attention 结构构建高阶特征交叉;损失函数选用加权 LogLoss:
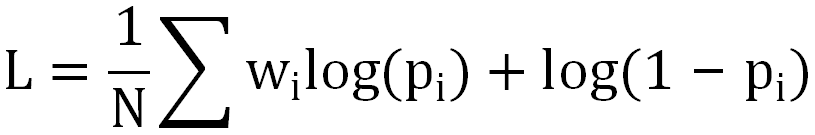
总结和展望
以上介绍了快手在多目标排序方面的部分工作,接下来给一个总结和展望,包括粗精排阶段的多目标排序、在线自动调参和重排序几方面。

在多任务学习方面,后续打算解决的问题包括:训练过程不同目标间的差异导致的梯度冲突问题;帕累托最优的权重设计,在训练过程中根据训练目标难易程度动态调节权重;对 MMoE 升级,比如用 Task-Specific Expert。
在线自动调参方面,后续打算解决的问题包括:对稀疏 reward 采用更好的处理方式,对噪声做更好的抗性处理;优化留存等更稀疏更有挑战的目标;把交叉熵这种 0 阶方法升级到 1 阶。
在重排序方面,后续的工作计划:用 Beam-Search 替代贪心搜索,控制线上耗时;在重排序过程,更好的融合相关性和多样性,端到端学习;除了上述,建模上文对下文的影响外,上下文协同的收益还有提升空间;如何在端上更好地做实时行为建模、引入丰富特征、云和端的配合等。
嘉宾介绍:
郑东 博士
快手 | 推荐算法技术总监
2012 年博士毕业于清华大学,2017 年加入快手做发现页的短视频推荐优化,完整经历了快手短视频排序模型 LR 到 DNN 再到复杂多目标学习的演进, 和排序机制从简单公式排序到多层次模型排序和自动调参的完整过程。加入快手前曾在美团做搜索广告算法的优化工作。
本文转载自:DataFunTalk(ID:dataFunTalk)
原文链接:多目标排序在快手短视频推荐中的实践

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论