

本文是王喆在 AI 前线 开设的原创技术专栏“深度学习 CTR 预估模型实践”第六篇文章(以下“深度学习 CTR 预估模型实践”简称“深度 CTR 模型”)。回顾王喆老师过往精彩文章:《谷歌、阿里等 10 大深度学习 CTR 模型最全演化图谱》、《重读 Youtube 深度学习推荐系统论文,字字珠玑,惊为神文》、《YouTube 深度学习推荐系统的十大工程问题》《推荐系统工程师必看!Embedding技术在深度学习CTR模型中的应用》。
之前的专栏文章更多从技术的角度讲解了 CTR 模型的主要结构,以及 Embedding 等 CTR 模型的主要技术点。今天这篇文章我们希望讨论的是,“除了 CTR 模型结构等技术要点,有没有其他更重要的影响 CTR 预估效果的要素?”
有解决 CTR 预估问题的“银弹”吗?
在很多同行发给我的咨询问题中,经常会被问及哪种 CTR 模型的效果会更好。诚然,CTR 模型结构对于最终的效果来说是重要的,但真的存在一种模型结构是 CTR 预估问题的“银弹”吗?
要回答这个问题,我们可以先分析一个模型的例子——阿里最新的 CTR 模型 DIEN(Deep Interest Evolution Network 深度兴趣进化网络)。图 1 是阿里 DIEN 的模型架构图。
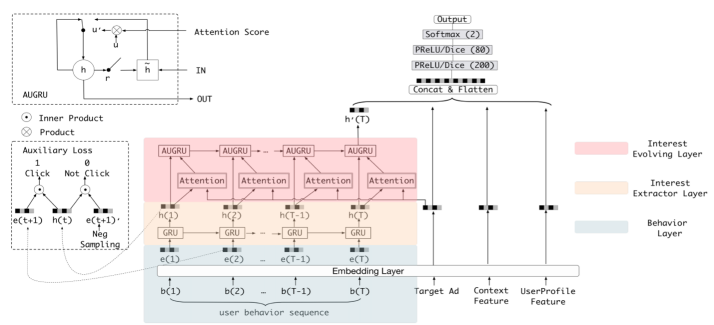
图 1 阿里的 CTR 预估模型 DIEN
如果去掉架构图中彩色的部分,模型其实是一个加入 Attention 机制的经典深度学习网络。而彩色的部分就是所谓的兴趣进化的过程。首先基于行为层(Behavior Layer)的用户行为序列,在兴趣抽取层(Interest Extractor Layer)抽取出抽象的用户兴趣,再在兴趣进化层(Interest Evolving Layer)利用 AUGRU 序列模型模拟兴趣演化的过程。
模型提出以来,有不少同学向我提出过类似问题说“王老师,我们应用了阿里的 DIEN 模型,但效果不好,你觉得会是什么原因?是不是 Embedding 层的维度不够,是不是应该再增加兴趣演化层的状态数量?”
所有问类似问题的同学都默认了一个前提假设,就是在阿里应用场景下 work 的 DIEN 模型理应在你的应用场景下同样 work。然而,这个假设真的合理吗?DIEN 模型是 CTR 预估领域的“银弹”吗?
答案必然是否定的。做一个简单的分析,既然 DIEN 的要点是模拟并表达用户兴趣进化的过程,那模型应用的前提必然是你的应用场景存在“兴趣的进化”。阿里的场景非常好理解,用户的购买兴趣的确在不同时间点有变化。比如用户在购买电脑后一定概率会购买电脑周边产品,用户在购买某类型的服装时会一定概率选择搭配的其他服装,这些都是兴趣进化的直观例子。
DIEN 在阿里场景能够 work 的另一个原因是用户的兴趣进化路径能够被阿里的数据近乎完整的保留。因为作为中国最大的电商集团,阿里巴巴各产品线组成的产品矩阵能够几乎完整的抓住用户购买兴趣迁移的过程。当然,用户是有可能去京东、拼多多购物从而打断阿里的兴趣进化过程,但统计意义上,大量用户的兴趣进化过程还是可以被阿里的数据体系捕获。
所以 DIEN 有效的前提应是你的应用场景满足两个条件:
1、 应用场景存在“兴趣的进化”;
2、 用户兴趣的进化过程能够被你的数据完整捕获到。
如果二者中有一个条件是你不具备的。那么 DIEN 大概率在这样的场景下不会带来较大的收益。
举个例子来说,笔者是做流媒体平台的推荐系统的,用户既可以选择我们自己的内容,也可以选择看 Netflix、YouTube 或者其他流媒体的内容(图 2 是流媒体平台不同的频道列表)。而一旦用户进入 Netflix 或者其他第三方应用,我们是无法得到应用中的具体数据的。在这样的场景下,我们仅能够获取到很少一部分的用户观看、点击数据,抽取出用户的兴趣点都是不容易的,谈何构建用户的整个兴趣链条呢?即使勉强构建出兴趣链条,也是错误的兴趣链条。

图 2 流媒体平台的不同频道
那么在这样的应用场景下,DIEN 适合成为我们 CTR 模型的主要架构吗?答案是否定的。我们通过实验也证明了 DIEN 在此场景下容易产生过拟合。如果在此场景下仍把模型效果不佳的主要原因归咎于参数没调好、数据量不够大,无疑有舍本逐末的嫌疑。相比这些技术原因,首先理解你的用户场景,熟悉你的数据特点才是最重要的。
什么才是比 CTR 模型结构更重要的东西?
到这里,我们也基本可以给出开头问题的答案了——在构建 CTR 模型的过程中,从应用场景出发,基于用户行为和数据的特点,提出合理的改进模型的动机才是最重要的。
换句话说,CTR 模型的结构不是构建一个好的 CTR 模型的“银弹”,真正的“银弹”是你对用户行为和应用场景的观察,基于这些观察,改进出最能够表达这些观察的模型结构。
去年我参加 Netflix 的 RPS workshop,Netflix 在做一项 CTR 模型的改进,就能够很好的体现 Netflix 对用户行为的观察。
众所周知,Netflix 是美国最大的流媒体公司,其推荐系统会根据用户的喜好生成影片的推荐列表。除了影片的排序外,最能够影响点击率的元素其实是影片的海报预览图。举例来说,一位喜欢马特达蒙的用户,当看到影片的海报上有马特达蒙的头像时,他点击该影片的概率会大幅增加。Netflix 的数据科学家在通过 AB Test 验证这一点后,着手开始对影片预览图的生成进行优化(如图 3),以提高推荐结果整体的点击率。

图 3 Netflix 不同预览图的模版
在具体的优化过程中,模型会根据不同用户的喜好,使用不同的影片预览图模版,填充以不同的背景、字体。通过使用简单的线性 contextual bandits 探索与利用模型来验证那种组合才是最适合某类用户的个性化海报。
在这个问题中,Netflix 并没有使用复杂的模型,但 CTR 提升的效果是 10%量级的。远远超过改进 CTR 模型结构带来的收益。这才是从用户和场景出发解决问题。
再举一个例子,图 4 是某 Smart TV 的主页,每一行是一个类型的影片。但对于一个新用户来说,是非常缺少点击和播放这类正样本的。我们能否找到一些其他的有价值的信息来解决数据稀疏问题呢?
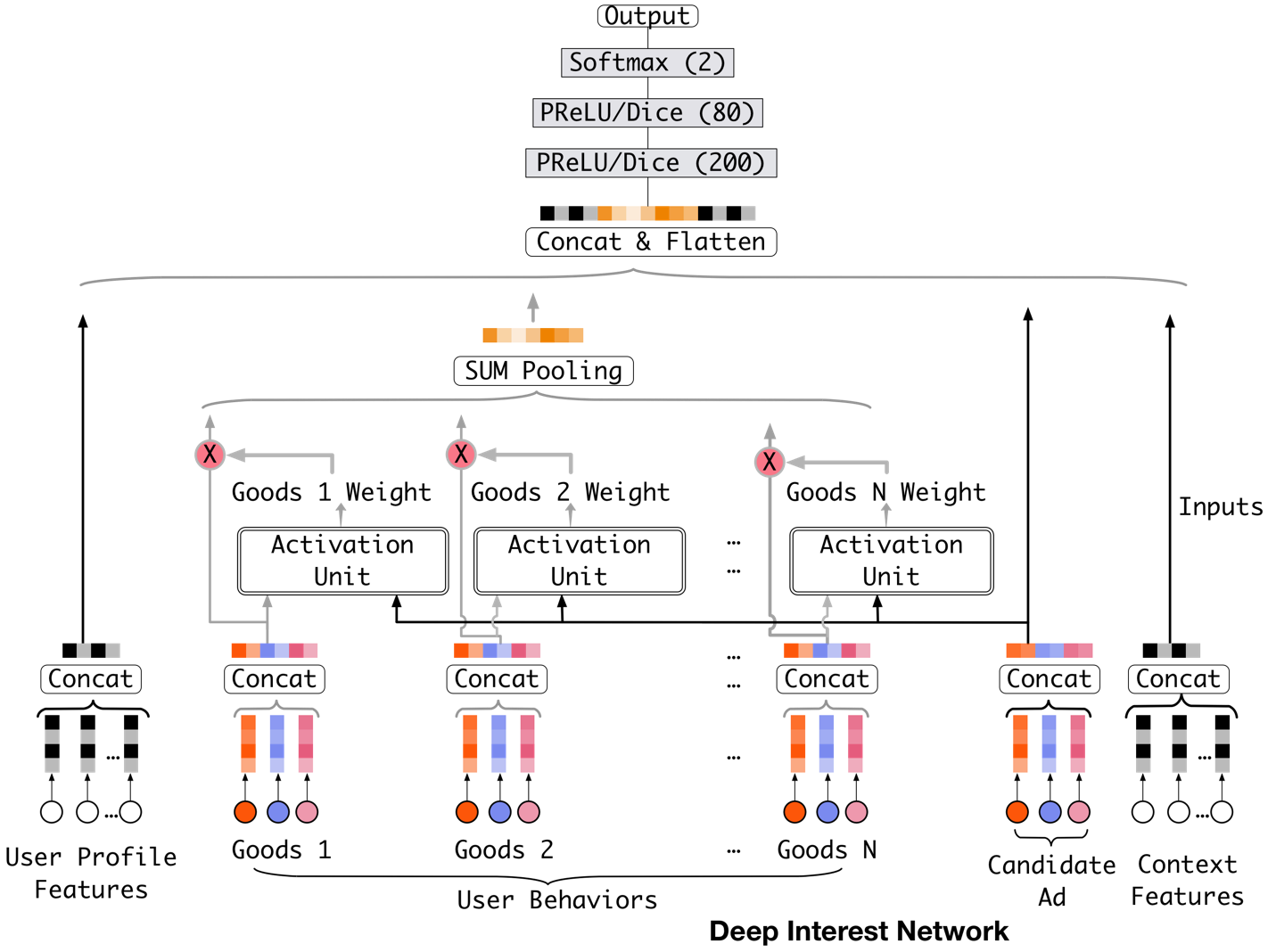
图 4 捕捉包含关键信息的用户行为
这就要求我们回到产品中,把自己置身于用户的角度去理解这个问题。这时你不难发现一个非常有价值的信号。针对这个用户界面来说,如果你对某个类型片感兴趣,必然会向右滑动鼠标或者遥控器(如图 4 中红色箭头所指),去找这个类型下面更多的影片,这个滑动的动作很好的反应了用户对于某类型影片的兴趣。
引入这个动作,无疑对构建用户兴趣向量,解决数据稀疏问题,进而提高 CTR 模型的效果有正向的作用。而引入更多有价值信息带来的收益也远远高于改进模型结构。
最后一个例子我们回到阿里的 CTR 预估模型,大家知道 DIEN 的前身是 DIN(深度兴趣网络)。DIN 的基本思想是将 attention 机制跟深度神经网络结合起来。
图 5 阿里的 DIN 模型
简单直观的来说,DIN 在经典的深度 CTR 模型的基础上,在构建特征向量的过程中,对每一类特征加入了一个激活单元(Activation Unit),这个激活单元的作用类似一个开关,控制了这类特征是否放入特征向量以及放入时权重的大小。那这个开关由谁控制呢?它是由被预测 item 跟这类特征的关系决定的。也就是说,在预测用户 u 是否喜欢商品 i 这件事上,DIN 只把跟商品 i 有关的特征考虑进来,其他特征的门会被关上,完全不考虑或者权重很小。
举例来解释 DIN 的工作原理,比如模型希望预测一个用户喜不喜欢看“复仇者联盟”,在构建用户的特征向量的时候,我们希望参考一下用户有没有看过“美国队长”的历史记录,但我们完全不关心用户看过没有“动物世界”,因为加入“动物世界”这类跟“复仇者联盟”不相关的特征,可能会让用户的特征向量丧失特殊性。
那么阿里妈妈的工程师能够提出将 attention 机制应用于深度神经网路的想法是单纯的技术考虑吗?
在跟论文作者交流之后,我发现他们的出发点仍然是用户的行为特点,因为天猫、淘宝作为综合性的电商网站,只有跟候选商品相关的用户历史行为记录才是有价值的。基于这个出发点,最终发现 attention 机制恰巧是能够表达这个动机的最合适的技术结构。
如果算法工程师们真的把自己当作一个“调参师”,“炼金术士”,仅仅专注于是否加 dropout,要不要更改 activation function,需不需要增加正则化项,修改网络深度和宽度。是不可能做出真正符合应用场景的针对性改进的。
结语
很多业内的朋友都说做 CTR 模型、做推荐系统就是“揣摩人心”,这句话我不能说完全赞同,但却也一定程度上反应了这篇文章的主题——从用户的角度思考问题,构建模型。
当你已经有了几年工作经验,对机器学习的相关技术已经驾轻就熟了的时候,反而应该从技术中跳出来,站在用户的角度,去深度体验他们的想法,去发现他们想法中的偏好和习惯,再用你的机器学习工具去验证它, 模拟它,我想你会得到意想不到的效果。
《深度学习 CTR 预估模型实践》专栏内容回顾:
前深度学习时代 CTR 预估模型的演化之路——从 LR 到 FFM
盘点前深度学习时代阿里、谷歌、Facebook 的 CTR 预估模型
推荐系统工程师必看!Embedding技术在深度学习CTR模型中的应用
作者介绍
王喆,毕业于清华大学计算机系,现在美国最大的 smartTV 公司 Roku 任 senior machine learning engineer,曾任 hulu senior research SDE,7 年计算广告、推荐系统领域业界经验,相关专利 3 项,论文 7 篇,《机器学习实践指南》、《百面机器学习》作者之一。知乎专栏 / 微信公众号:王喆的机器学习笔记。

腾讯大规模云原生技术实践案例集
本案例集详细阐释了 QQ、腾讯会议、和平精英、小红书、斗鱼、微盟等十多个亿级用户产品背后的大规模云原生...










评论