

手把手教你用 Python 的 Surprise 库实现一个 kNN 风格的推荐引擎,从数据准备到预测全部搞定。
*本文最初发布于 towards data science 博客,***经原作者授权由 InfoQ 中文站翻译并分享。
啊,我们的现代生活舒适却又令人痛苦:下图的纸杯蛋糕看上去都很诱人,可我们又不能全都尝一口,那么应该吃哪一个呢?无论使用哪种平台,你的选项往往都是无穷无尽的;但是作为消费者,你的资源却是有限的。不用担心,推荐系统可以助你一臂之力!

在推荐系统中,我们有一组用户和一组项目。对于给定的用户,我们希望过滤出用户可能喜欢的一个项目子集(评分高、购买过、观看过等,具体取决于问题的类型)。推荐系统无处不在,自身业务基于内容的杰出科技企业,如 Netflix、Amazon 和 Facebook 等,都非常依赖复杂的推荐系统来提升其产品的消费量。
在本文所讨论的这个项目中,我选择的是 boardgamegeek 评选出的前 100 大游戏(截至 2020 年 3 月 31 日),使用了从这家网站上收集的 230 万个人用户评分数据。我主要使用的是 Surprise(https://surprise.readthedocs.io/en/stable/index.html),这是一个专注于推荐系统的 Python scikit 库,其结构与 scikit-learn 非常相似。
在本文中我们将讨论基于记忆的模型。我们会介绍如何导入和准备数据,要使用哪些相似度指标,如何实现三个内置的 kNN 模型,如何应用模型验证,最后是如何做出预测。关于该项目的详细信息,请查看我的GitHub存储库
我们在本文中介绍的工作大致对应于文
02_modelling_neighbours.ipynb 中的代码。
推荐系统
先快速介绍一下推荐系统的各个种类,之后我们就可以探讨最近邻模型了。
你可以采用两种主要的推荐路径:
基于内容的过滤模型,它基于商品的描述和用户的历史偏好,我们不需要其他用户的意见即可做出推荐。
示例:用户喜欢 Vlaada Chvátil 设计的三款游戏,因此我们会推荐他设计的第四款游戏。
协作过滤模型,它试图通过不同用户有着类似评价/都拥有的项目来发现项目/用户之间的相似性。
示例:用户喜欢 Caverna,根据我们对人群的分析,我们知道那些喜欢 Caverna 并了解 Feast for Odin 的用户也更容易喜欢后者,因此我们会向用户推荐 FfO。
在这个项目中我们将使用协作过滤模型。在协作过滤模型中,两种最著名的独特方法分别是:
基于记忆的模型,会根据用户-项目的评分对计算用户/项目之间的相似度。
基于模型的模型(不可思议的名称),使用某种机器学习算法来估计评分。一个典型的例子是用户-项目评级矩阵的奇异值分解。
在本文中,我们将重点介绍基于记忆的模型。也就是说,在推荐系统中我们选择了协作过滤,而在协作过滤方法中我们选择了基于记忆的模型。
数据导入
首先,我们需要安装 Surprise 软件包:
完成后,你需要一个数据集,其中包含三个变量:用户 ID、项目 ID 和评分。这很重要,请勿尝试以用户-项目评分矩阵格式来传递评分。首先,数据有 3 列,且行数等于评分的总数。
如果你只是想练习一下,请随意使用我在 GitHub 上的数据集。我自己将它们放在了一个 3 列的 csv 文件中,但是你也可以使用其他数据结构,或者直接从 pandas DataFrame 加载。
为了导入数据,你需要从库中获取以下类:
然后定义 file_path(显然要更改为你的文件路径):
最后,我们创建一个具有以下属性的 Reader 对象:
line_format:确保顺序与你的文件匹配。
sep:如果我们使用的是 csv,这是一个逗号。
rating_scale:具有最低和最高可能范围的一个元组(tuple)。正确设置这个参数是很重要的,否则部分数据将被忽略。例如,如果你使用的是二进制数据,那么要表示用户喜欢/不喜欢这个项目,你可以输入(0,1)。
要导入数据,请使用 load_from_file 方法:
这样就可以了,你应该让你的数据使用 surprise 可以支持的格式!你现在可以将数据想象成一个稀疏矩阵,其中用户/项目是行/列,而各个评分是该矩阵中的元素。大多数 cell 可能为空,但这完全没问题。在我使用的数据中,我的评分有 230 万,用户约为 23 万,这意味着每位用户平均对 100 款游戏中的 10 款做出了评价,因此矩阵中有 90%的 cell 为空。
数据准备
这里 surprise 就开始派上用场了,它的工作流程与 scikit-learn 中的分类器模型是不一样的。在 scikit-learn 的模型中你有一个大的矩阵,你可以根据自己的需要将其拆分为训练/验证/测试集,做交叉验证,因为它们本质上仍是相同类型的数据。但在 surprise 中有三种不同的数据类,每种都有自己独特的用法:
Dataset:可以直接或通过交叉验证迭代器拆分为训练集和测试集。后者意味着如果你在交叉验证中将一个 Dataset 作为参数传递,它将创建许多训练-测试拆分。
Trainset:在模型的 fit 方法中用作参数。
Testset:在模型的 test 方法中用作参数。
在我看来,surprise 是一个文档相对完善的库,但它仍有一些奇怪之处。例如,一个 Dataset 对象有一个方法 construct_testset,但是除了在旧版本的文档页面中能找到这一代码外,文档并没有解释它的作用,也没说它应该用什么参数。
我坚持在项目中使用有完善文档说明的方法。我们正在为两种不同的方法做准备,在以下各节中将进一步说明这些方法的目的。
我们将使用来自 model_selection 包的以下内容:
首先,我们将数据分为 trainset 和 testset,test_size 设置为 20%:
再说一次,它与分类器/回归模型的工作机制略有不同:testset 包含随机选择的用户/项目评分,而不是完整的用户/项目。一位用户可能有 10 个评分,现在随机选择其中 3 个评分进入 testset,而不是用于拟合模型。我第一次使用时觉得这样的机制很奇怪,但是不完全删去某些用户也是有道理的。
第二种方法是使用完整的数据并交叉验证以备测试。在这种情况下,我们可以通过 build_full_trainset 方法使用所有评分来构建一个 Trainset 对象:
你可以使用 n_users 和 n_items 方法获取项目数/用户数(trainsetfull 是相同的方法,因为它们是同一类型的对象):
当 Surprise 创建一个 Trainset 或 Testset 对象时,它将获取 raw_id(你在导入的文件中使用的 id),并将它们转换为所谓的 inner_id(基本上是一系列从 0 开始的整数)。你可能需要追溯到原始名称。以这些项目为例(你可以对用户执行相同的方法,只需在代码中将 iid 换成 uid 即可),可以使用 all_items 方法来获取 inner_iid 的列表。要将原始 ID 转换为内部 ID,可以使用 to_inner_iid 方法,使用 to_raw_iid 可以转换回去。
下面是关于如何保存内部项目 ID 和原始项目 ID 的列表的示例:
到这里,我们的数据准备工作就结束了,接下来是时候了解一些模型参数了!
模型参数
当我们使用 kNN—类型推荐器算法时,可以调整两个超参数:k 参数(是的,与模型类型名称相同的 k)和相似度选项。
k 参数非常简单,机制和它在通用的 k-nearest 近邻模型中类似:它是我们希望算法考虑的相似项目的上限。例如,如果用户为 20 个游戏打分,但我们将 k 设置为 10,则当我们估计新游戏的评分时,只会考虑 20 个游戏中最接近新游戏的 10 个游戏。你也可以设置 min_k,如果用户没有足够的评分,则将使用全局平均值进行估计。默认情况下 k 为 1。
我们在上一段中提到了彼此接近的项目,但是我们如何确定这个距离呢?第二个超参数(相似度选项)定义了计算它的方式。
首先让我们看一下 sim_option配置。这个参数是一个字典,具有以下键:
shrinkage:不需要基本的 kNN 模型,只在 KNNBaseline 模型中出现。
user_based:基本上,当你要估计相似度时有两种路径。你可以计算每个项目与其他项目的相似程度,也可以计算用户间的相似程度。对于我的项目而言,考虑到我有 100 个项目和 23 万个用户,我使用 False。
min_support:最小公共点数,低于它时相似度设置为 0。示例:如果 min_support 为 10,并且有两个游戏,只有 9 个用户对它们都打了分,那么无论评分如何,两个游戏的相似度均为 0。我没有在我的项目中做这种实验,考虑到数据范围它应该没什么影响,因此我使用默认值 1。
name:公式的类型,将在后文进一步讨论。
所有相似度函数都会向特定(i,j)项目对返回 0 到 1 之间的数字。1 表示评分完全一致,0 表示两个项目之间没有任何联系。在公式中,rᵤᵢ是用户 u 对项目 i 给予的评分,μᵢ是项目 i 的平均评分,而 Uᵢⱼ是对项目 i 和 j 都打了分的用户集合。下面是 surprise 相似性模块(https://surprise.readthedocs.io/en/v1.1.0/similarities.html)中的三个相似度指标:
cosine:
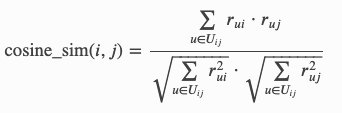
MSD:
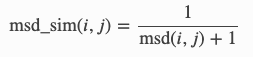
其中 msd(i,j)为:
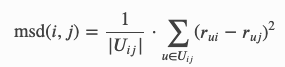
pearson:
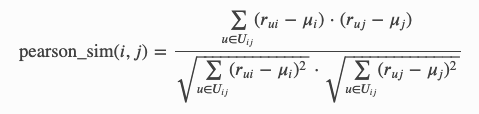
这些选项并没有优劣之分,但我很少看到有示例使用 MSD,而且在我的数据中 pearson 和 cosine 的性能确实好得多。可以看到,pearson 公式基本上是 cosine 公式的均值中心形式。
关于如何定义 sim_option 参数的示例:
现在我们做好了所有准备工作,终于可以训练一些模型了。
KNN 模型
基本的KNN模型 在 surprise 中有三种变体(我们在本文中不考虑第四种,即 KNNBaseline)。它们定义了 rᵤᵢ(也就是用户 u 对项目 i 的打分)在预测中是如何估计出来的。下面的公式主要使用我们在上一节中讨论过的符号,其中有两个是新的:σᵢ是项目 i 的标准差,Nᵤᵏ(i)是用户 u 打分的项目中,和 u 对项目 i 的打分最接近的最多 k 个项目。
公式如下:
KNNBasic:
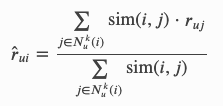
估计的评分基本上是用户对相似项目评分的加权平均值,由相似度加权。
KNNWithMeans:
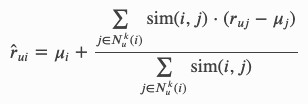
使用项目的平均评分调整 KNNBasic 公式。
KNNWithZScore:
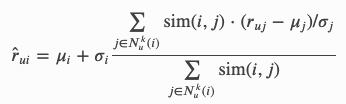
更进一步,还根据评分的标准差进行调整。
在下面的示例中,我们使用三个 my_参数拟合 KNNWithMeans 模型。根据我的经验,如果你的项目的平均评分不一样,那么几乎就不会选择使用 KNNBasic。你可以根据需要自由更改这些参数,并且所有三个模型都使用完全相同的参数。你可以在下面的代码中将 KNNWithMeans 更改为 KNNBasic 或 KNNWithZScore,运行起来都是一样的。
这样,我们的模型就拟合了。从技术上讲,这里发生的事情是模型算出了相似度矩阵,如果你需要的话还有均值/标准差。
你可以使用 sim 方法请求相似度矩阵,如下所示:
它将是一个 numpy 数组格式。除非你想自己做某种预测,否则应该不需要这个矩阵。
测试
训练模型后,就该测试了吧?性能指标保存在 surprise 的准确度模块(https://surprise.readthedocs.io/en/stable/accuracy.html)中。这里有四个指标(RMSE、FCP、MAE、MSE),但是据我所知,行业标准是均方根误差(RMSE),因此我们只使用这个指标。下面是我们最终的数学公式:
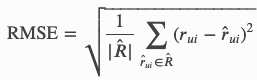
这个分数大致会告诉你估计的平均评分与实际的平均评分之间的差距。要获得测试分数,你要做的就是使用已经拟合的算法上的测试方法创建一个 predictions 对象:
假设根据我的数据,测试数据的 RMSE 得分为 1.2891。这意味着估计的平均评分是实际评分的 1.2891 倍(或相反),分数范围是 1 到 10。这个分数不算好也不算差。
交叉验证
在前两节中,我们采用了非常直接的方法:我们保留测试数据,训练模型,然后测试其性能。但是,如果你要跑很多次,则最好使用交叉验证来测试模型的性能和判断模型是否过拟合。
如前所述,surprise 中测试和验证的机制有所不同。你只能对原始 Dataset 对象进行交叉验证,而不能为最终测试留出单独的测试部分,至少我找不到相应的方法。所以我的流程基本上是这样的:
对具有不同参数的多种模型类型进行交叉验证,
选出平均测试 RMSE 得分最低的配置,
在整个 Dataset 上训练这个模型,
用它来预测。
我们讨论一下 cross_validate 方法的几个参数:
cv 定义了模型要使用的 fold 类型,类似于 scikit-learn 中的工作机制。我会输入整数来使用基本的 K-Fold,你可以在这里的文档(https://surprise.readthedocs.io/en/stable/model_selection.html?highlight=cross%20validation#module-surprise.model_selection.split)中了解不同的 K-Fold。
n_jobs:并行评估的 fold 数,如果你有充足的内存,则将其设置为-1 就意味着所有 CPU 都在并行工作。但是,当我在本地计算机上执行这个操作时它崩溃了。我最终将其保留为默认值 1。
在下一部分中,我们将交叉验证的结果保存在 result 变量中:
请注意,运行这个操作可能需要几分钟时间,测试需要一段时间,而交叉验证则需要执行 5 次。
完成后,你可以深入研究 result 变量以分析性能。例如,要获得平均测试 RMSE 分数:
自然,你会花一段时间研究,然后尝试不同的模型,并尝试尽可能降低 RMSE 得分。等你对性能感到满意,并创建了让自己满意的 algo 模型后,就可以在整个数据集上训练算法了。这个步骤是必要的,因为正如我提到的那样,你无法根据交叉验证做出预测。与上面针对非完整训练集使用的代码相同:
下一步,我们开始讨论预测!
预测
终于到这一步了,我们做整个项目就是为了这一刻,对吧?这里要注意的是,surprise 有两点可能和你期望的不一样:
只能对已经在数据集中的用户进行预测。这也是为什么我认为在流程结束时在整个数据集上训练模型才有意义的原因所在。
你不能调用一次就从模型中获得输出列表。你可以请求一个特定用户对某个特定项目的估计评分结果。但这里有一种解决方法,我们稍后会再讨论。
要做一次预测,你可以使用原始 ID,因此要获取 TestUser1(用户在数据中至少具有 min_k 个其他评分)对 ID 为 161936 的游戏的评分估计,你需要使用训练好的算法上的 predict 方法:
predict 方法将返回如下字典:
r_ui 为 None,因为用户对这个项目没有实际评分。我们感兴趣的是 est 项目,也就是估计的评分,这里估计的评分为 6.647。
到这里都很不错,但是我们如何为一位用户获取前 N 条推荐呢?你可以在这篇文档(https://surprise.readthedocs.io/en/stable/FAQ.html)中找到一个详细的解决方案,这里不会细谈,只讲一下基本步骤:
在 trainsetfull 上训练模型。
使用 build_anti_testset 方法创建一个“anti testset”。这基本上是我们原始数据集的补集。因此,如果用户对 100 款游戏中的 15 款进行了评分,我们的 testset 将包含该用户未评分的 85 款游戏。
使用 test 方法在 anti_testset 上运行预测(结果与 predict 方法有类似的结构)。通过此步骤,我们为数据中缺少的所有用户-项目评分对提供了评分估计。
对每个用户的估计评分进行排序,列出 N 个具有最高估计评分的项目。
总结
我觉得应该将我们讨论的内容放在一起总结一下。我们在下面的代码中采用的方法是交叉验证路线,因此我们使用交叉验证测试性能,然后将模型拟合到整个数据集。
请注意,你很可能不会止步于一次交叉验证,而应尝试其他模型,直到找到最佳的选项。你可能还希望简化上一节中得到的前 N 条推荐。
下一步工作
当你使用 surprise 工作时还有其他许多选项,我打算在以后的文章中具体探讨。
很容易想到的下一步工作是使用 SVD 和 SVDpp 方法探索基于模型的方法。它们使用矩阵分解来估计评分。另外你可能已经注意到,在这个场景中我没有使用 GridSearchCV 进行超参数调整。考虑到我们只有几个参数,我发现使用 cross_validate 就足够了;但是当涉及更复杂的模型时,你肯定要使用 GridSearchCV。
另一个值得探索的领域是预测。有时,你只想对某些用户评分运行模型,而无需将其集成到基础数据库中。例如,我从 boardgamegeek 收集了数据,当我只是想快速向某人展示该模型时,我不希望这些评分与“官方”评分混在一起。为一个用户重新运行整个模型也有些浪费了。现在,对于我们讨论的三种 KNN 模型而言,完全有可能仅根据相似性矩阵、均值和标准差进行预测。我将在以后的文章中专门介绍这个流程,或者你可以在 GitHub 中查看 recomm_func.py 脚本。
参考链接:
https://en.wikipedia.org/wiki/Collaborative_filtering
https://surprise.readthedocs.io/en/stable/index.html
活动推荐:
2023年9月3-5日,「QCon全球软件开发大会·北京站」 将在北京•富力万丽酒店举办。此次大会以「启航·AIGC软件工程变革」为主题,策划了大前端融合提效、大模型应用落地、面向 AI 的存储、AIGC 浪潮下的研发效能提升、LLMOps、异构算力、微服务架构治理、业务安全技术、构建未来软件的编程语言、FinOps 等近30个精彩专题。咨询购票可联系票务经理 18514549229(微信同手机号)。

InfoQ高级技术编辑

腾讯大规模云原生技术实践案例集
本案例集详细阐释了 QQ、腾讯会议、和平精英、小红书、斗鱼、微盟等十多个亿级用户产品背后的大规模云原生...













评论