

在计算机视觉中,尺度始终是一个大问题,小物体与超大尺度物体往往都会严重影响性能。
什么是多尺度
1.1 什么是多尺度
所谓多尺度,实际上就是对信号的不同粒度的采样,通常在不同的尺度下我们可以观察到不同的特征,从而完成不同的任务。
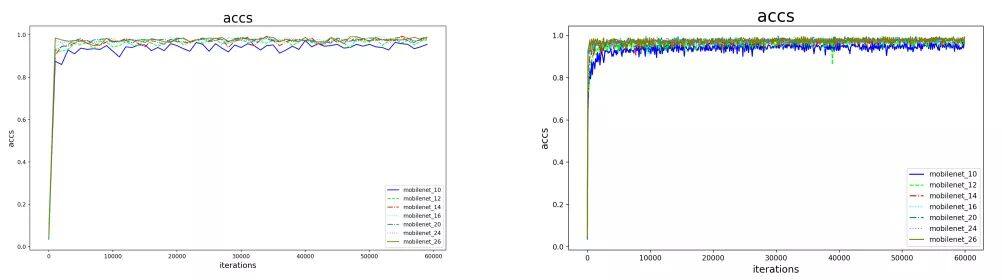
如上两个图是同样的一维信号在不同采样频率下的结果,这是一条精度曲线。通常来说粒度更小/更密集的采样可以看到更多的细节,粒度更大/更稀疏的采样可以看到整体的趋势,不过此处由于使用了不同的颜色,曲线本身也存在较大的波动,所以粒度更小的右图反而能更直观的看到各个曲线的整体性能比较结果。

如上展示了 3 个尺度的图像,如果要完成的任务只是判断图中是否有前景,那么 12×8 的图像尺度就足够了。如果要完成的任务是识别图中的水果种类,那么 64×48 的尺度也能勉强完成。如果要完成的任务是后期合成该图像的景深,则需要更高分辨率的图像,比如 640×480。
1.2 图像金字塔
很多时候多尺度的信号实际上已经包含了不同的特征,为了获取更加强大的特征表达,在传统图像处理算法中,有一个很重要的概念,即图像金字塔和高斯金字塔。
图像金字塔,即一组不同分辨率的图像,如下图:
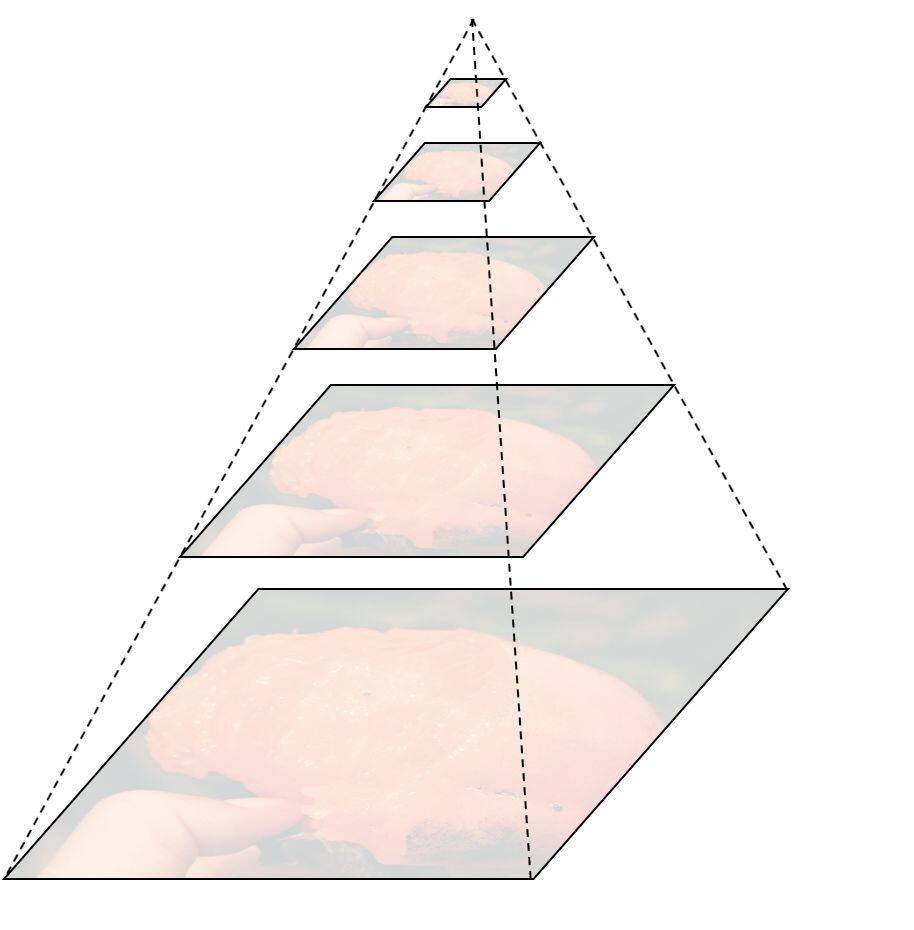
采样的方式可以是不重叠或者重叠的,如果是不重叠的,采样尺度因子为 2,那就是每增加一层,行列分辨率为原来的 1/2。
当然,为了满足采样定理,每一个采样层还需要配合平滑滤波器,因此更常用的就是高斯金字塔,每一层内用了不同的平滑参数,在经典的图像算子 SIFT 中被使用。
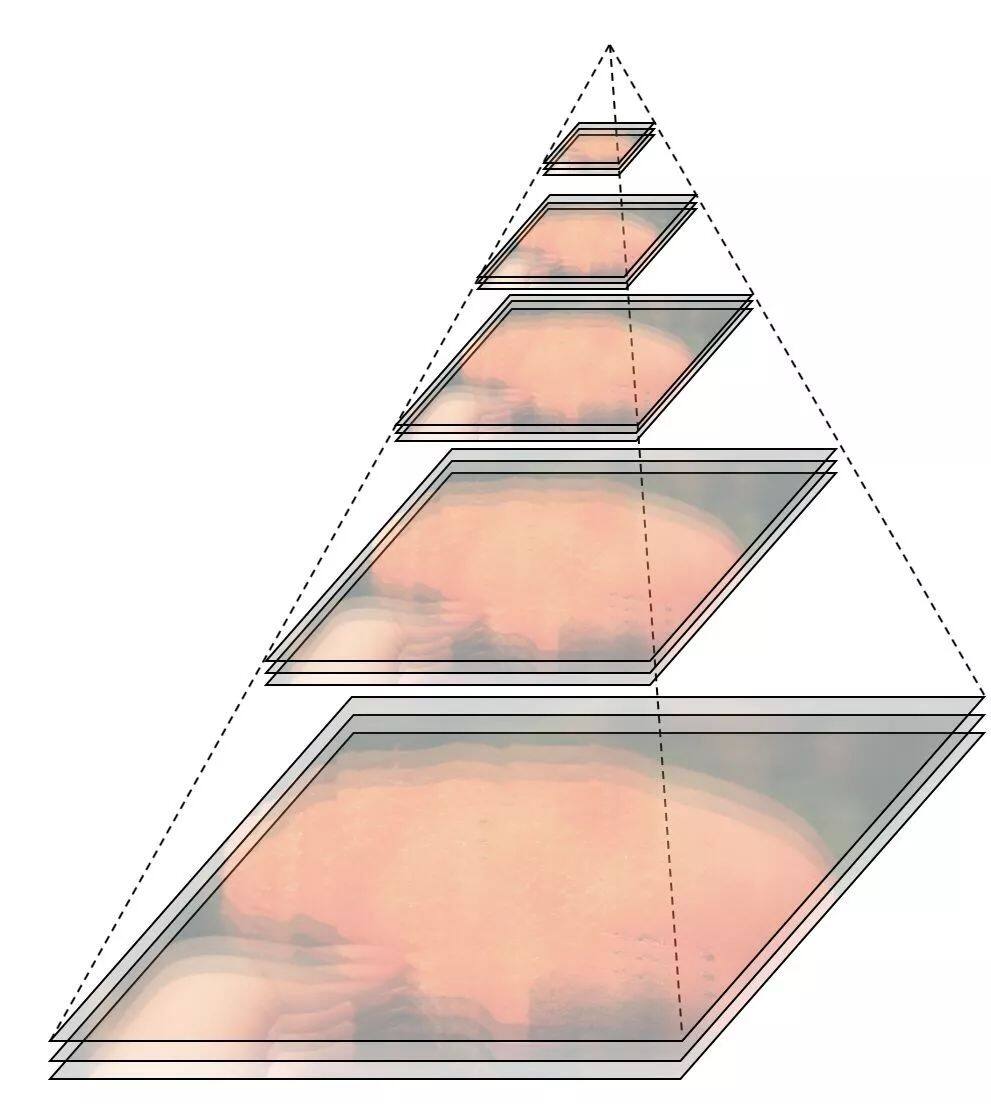
不过这不是本文要聚焦的内容,请大家去自行了解尺度空间理论,接下来聚焦深度学习中的多尺度模型设计。
计算机视觉中的多尺度模型架构
卷积神经网络通过逐层抽象的方式来提取目标的特征,其中一个重要的概念就是感受野。如果感受野太小,则只能观察到局部的特征,如果感受野太大,则获取了过多的无效信息,因此研究人员一直都在设计各种各样的多尺度模型架构,主要是图像金字塔和特征金字塔两种方案,但是具体的网络结构可以分为以下几种:(1) 多尺度输入。(2) 多尺度特征融合。(3) 多尺度特征预测融合。(4) 以上方法的组合。
2.1 多尺度输入网络
顾名思义,就是使用多个尺度的图像输入(图像金字塔),然后将其结果进行融合,传统的人脸检测算法 V-J 框架就采用了这样的思路。
深度学习中模型以 MTCNN[1]人脸检测算法为代表,其流程如下,在第一步检测 PNet 中就使用了多个分辨率的输入,各个分辨率的预测结果(检测框)一起作为 RNet 的输入。
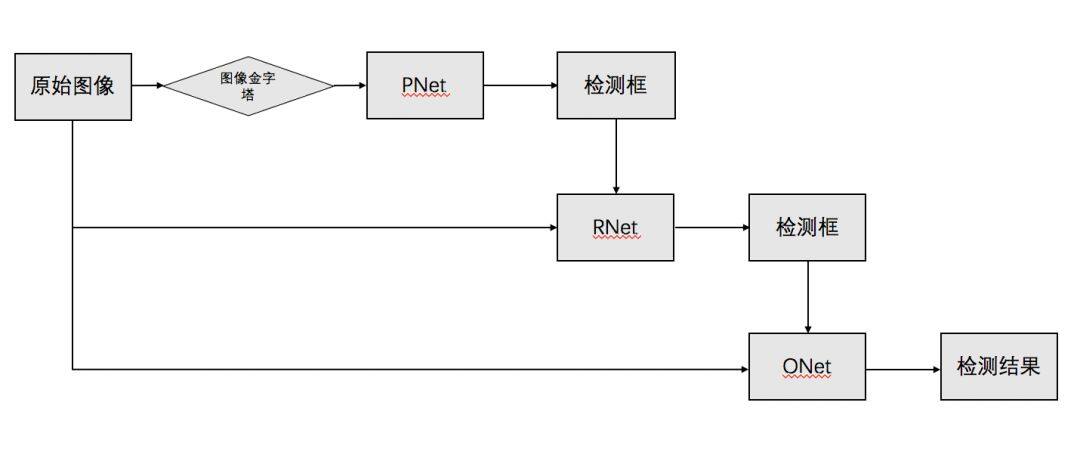
值得一提的是,多尺度模型集成的方案在提高分类任务模型性能方面是不可或缺的,许多的模型仅仅采用多个尺度的预测结果进行平均值融合,就能在 ImageNet 等任务中提升 2%以上的性能。
2.2 多尺度特征融合网络
多尺度特征融合网络常见的有两种,第一种是并行多分支网络,第二种是串行的跳层连接结构,都是在不同的感受野下进行特征提取。
(1) 并行多分支结构
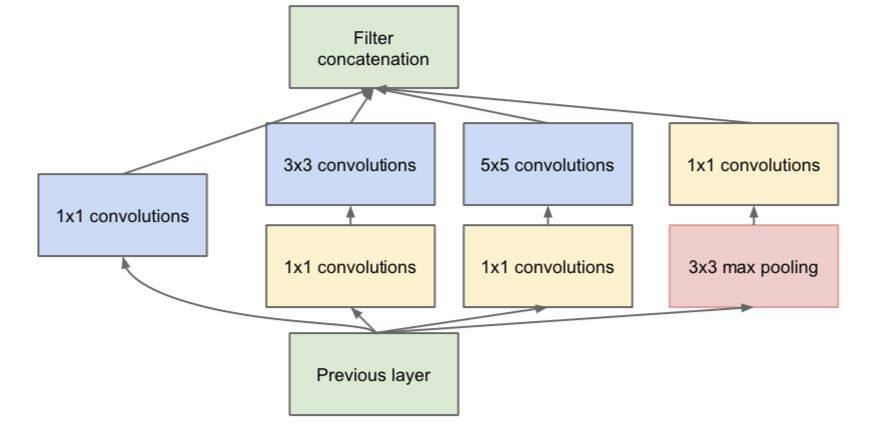
比如 Inception 网络中的 Inception 基本模块,包括有四个并行的分支结构,分别是 1×1 卷积,3×3 卷积,5×5 卷积,3×3 最大池化,最后对四个通道进行组合。
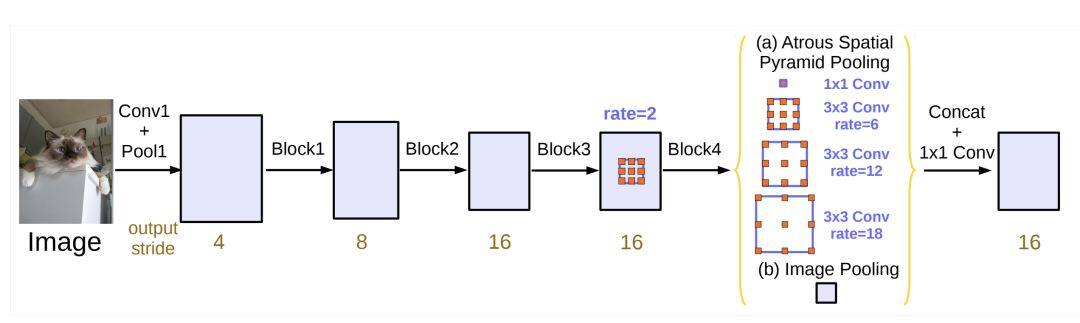
除了更高卷积核大小,还可以使用带孔卷积来控制感受野。在图像分割网络 Deeplab V3[2]和目标检测网络 trident networks[3]中都使用了这样的策略,网络结构如下图:
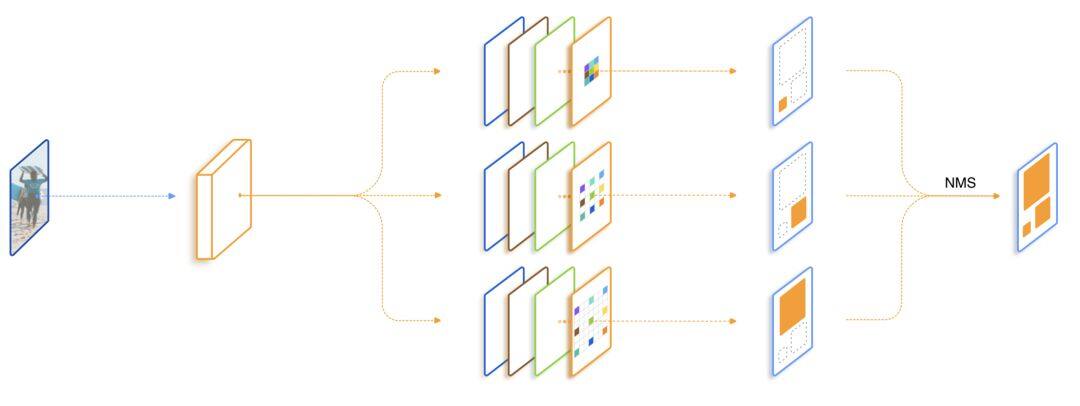
还有一种比不同大小的卷积核和带孔卷积计算代价更低的控制感受野的方法,即直接使用不同大小的池化操作,被 PSPNet[4]采用。
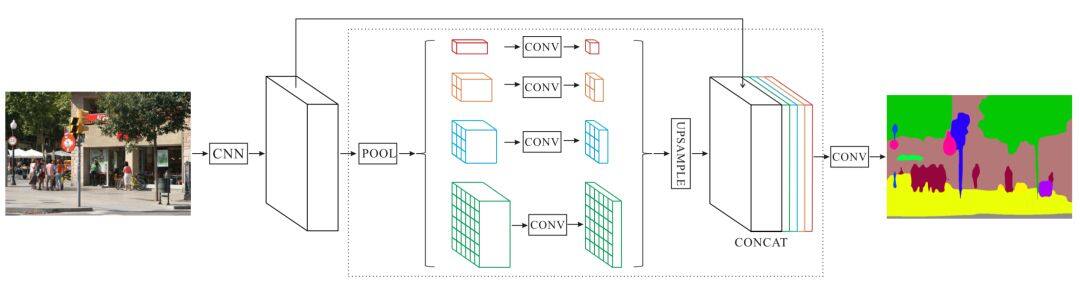
值得注意的是,这样的多分支结构对于模型压缩也是有益处的,以 Big-little Net[5]为代表,它采用不同的尺度对信息进行处理。
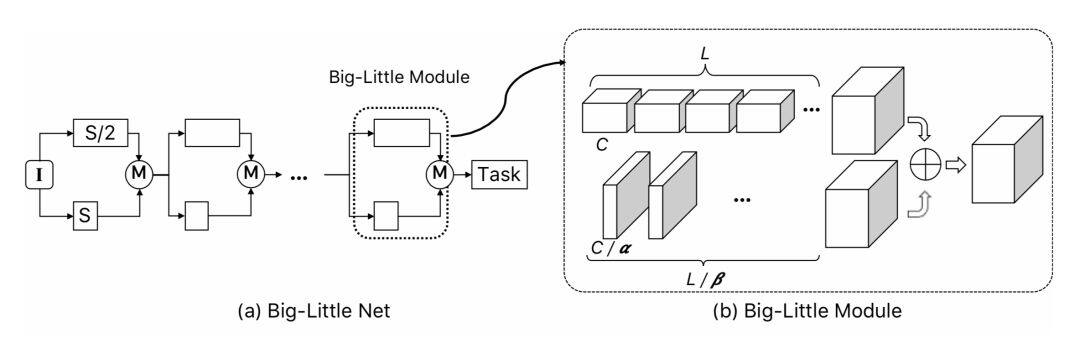
对于分辨率大的分支,使用更少的卷积通道,对于分辨率小的分支,使用更多的卷积通道,这样的方案能够更加充分地使用通道信息。
(2) 串行多分支结构
串行的多尺度特征结构以 FCN[6],U-Net 为代表,需要通过跳层连接来实现特征组合,这样的结构在图像分割/目标检测任务中是非常常见的。
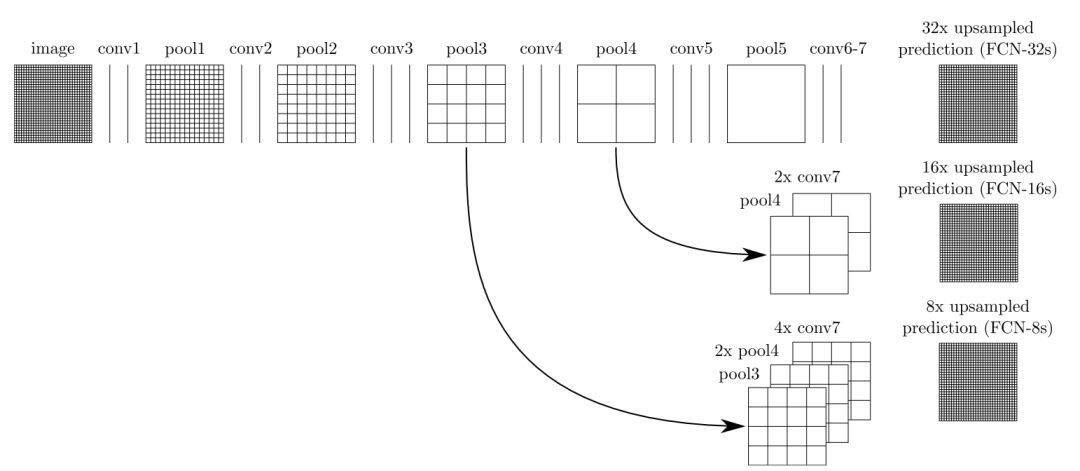
从上面这些模型可以看出,并行的结构能够在同一层级获取不同感受野的特征,经过融合后传递到下一层,可以更加灵活地平衡计算量和模型能力。串行的结构将不同抽象层级的特征进行融合,对于边界敏感的图像分割任务是不可缺少的。
2.3 多尺度特征预测融合
即在不同的特征尺度进行预测,最后将结果进行融合,以目标检测中的 SSD[7]为代表。
SSD 在不同 stride 不同大小的特征图上进行预测。低层特征图 stride 较小,尺寸较大,感受野较小,期望能检测到小目标。高层特征图 stride 较大,尺寸较小,感受野较大,期望能检测到大目标。

类似的思想还有 SSH[8],从分辨率较大的特征图开始分为多个分支,然后各个分支单独预测不同尺度大小的目标。
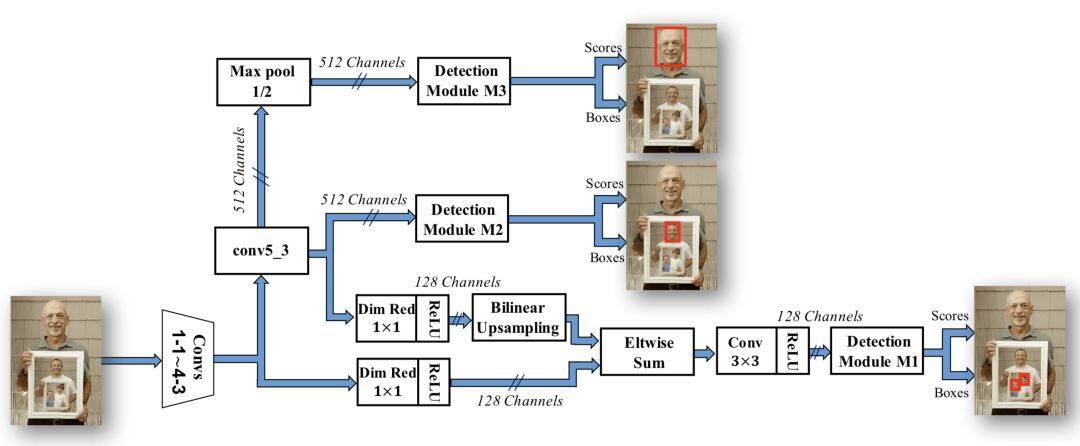
在多个特征通道进行预测的思想与多个输入的方案其实是异曲同工的,但是它的计算效率更高。
2.4 多尺度特征和预测融合
既然可以将不同尺度的特征进行融合,也可以在不同的尺度进行预测,为何不同时将这两种机制一起使用呢?这样的结构以目标检测中的 FPN[9]为代表。
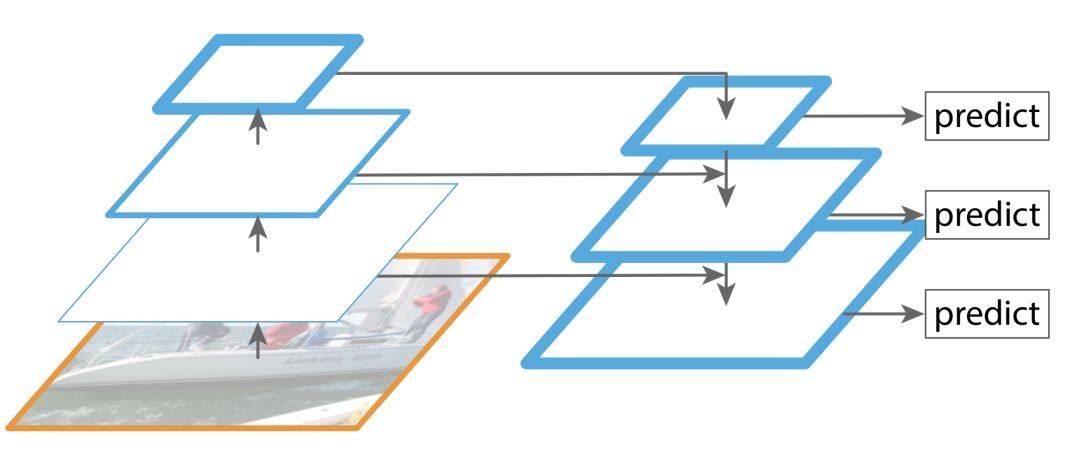
即将高层的特征添加到相邻的低层组合成新的特征,每一层单独进行预测。当然,也可以反过来将低层的特征也添加到高层,比如 PAN[10]。
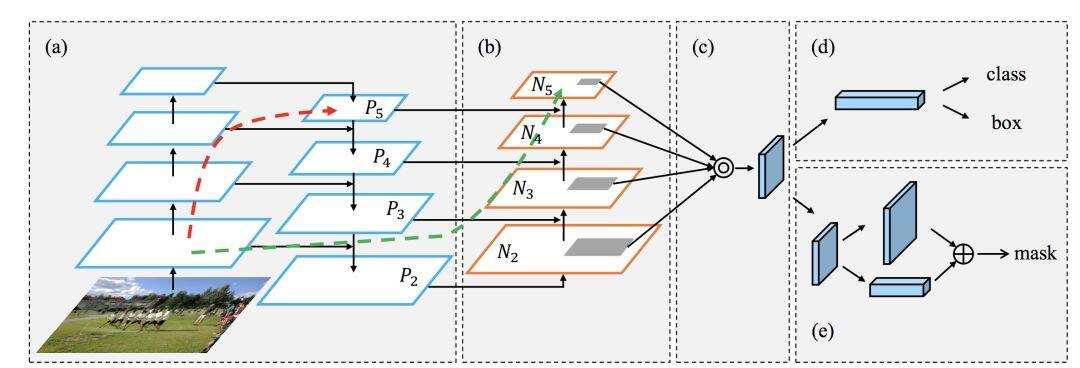
当然,对于不同尺度的特征图的融合,还可以基于学习的融合方案。
写在最后:
上面说了这么多的方法,相信动手能力强的同学一定可以基于这些方法进行排列组合和拓展。另外,对于某些领域中的专用技巧,比如目标检测中的不同尺度的 Anchor 设计,不同尺度的训练技巧,在这里没有讲述。
以上就是多尺度的常用设计方法,从图像分辨率的控制,到卷积核,池化的大小和不同的方案,到不同特征的融合,现在有很多相关的研究,本文不一一详述,作为计算机视觉中的老大难问题,我们会持续关注,相关自动架构搜索的研究也已经出现。
参考文献
[1] Zhang K, Zhang Z, Li Z, et al. Joint face detection and alignment using multitask cascaded convolutional networks[J]. IEEE Signal Processing Letters, 2016, 23(10): 1499-1503.
[2] Chen L C, Papandreou G, Schroff F, et al. Rethinking atrous convolution for semantic image segmentation[J]. arXiv preprint arXiv:1706.05587, 2017.
[3] Li Y, Chen Y, Wang N, et al. Scale-aware trident networks for object detection[J]. arXiv preprint arXiv:1901.01892, 2019.
[4] Zhao H, Shi J, Qi X, et al. Pyramid scene parsing network[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2017: 2881-2890.
[5] Chen C F, Fan Q, Mallinar N, et al. Big-little net: An efficient multi-scale feature representation for visual and speech recognition[J]. arXiv preprint arXiv:1807.03848, 2018.
[6]Long J, Shelhamer E, Darrell T. Fully convolutional networks for semantic segmentation[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2015: 3431-3440.
[7] Liu W, Anguelov D, Erhan D, et al. Ssd: Single shot multibox detector[C]//European conference on computer vision. Springer, Cham, 2016: 21-37.
[8] Najibi M, Samangouei P, Chellappa R, et al. Ssh: Single stage headless face detector[C]//Proceedings of the IEEE International Conference on Computer Vision. 2017: 4875-4884.
[9] Lin T Y, Dollár P, Girshick R, et al. Feature pyramid networks for object detection[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2017: 2117-2125.
[10] Liu S, Qi L, Qin H, et al. Path aggregation network for instance segmentation[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2018: 8759-8768.
[11] Ghiasi G, Lin T Y, Le Q V. Nas-fpn: Learning scalable feature pyramid architecture for object detection[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2019: 7036-7045.
作者介绍
言有三,公众号《有三 AI》作者,致力于为读者提供 AI 各个领域所需的系统性的专业知识。
原文链接
本文源自言有三的知乎,https://zhuanlan.zhihu.com/p/74710464

Java 避坑指南:Java 高手笔记代码篇
本迷你书包括 86 个业务开发中常见踩坑点。每一个知识点都相当的实用,是程序员业务开发中的必备避坑指南...











评论