

这是探索 Kafka 存储层和处理层核心基础系列文章的第二篇。在这篇文章中,我们将深入了解 Kafka 的存储层。我们将探索 Kafka 的主题,以及我认为 Kafka 最重要的概念:分区。
我们先从最基本的问题开始:Kafka 是如何存储数据的?
Kafka 的主题是什么东西?
主题属于 Kafka 的存储层,或许是 Kafka 最为人所熟知的一个概念。事件就保存在主题里,主题类似于分布式文件系统中的文件。保存和提供数据服务的机器叫作 Kafka 代理,也就是 Kafka 的服务器组件。
从概念上讲,主题是没有边界的事件序列,事件就是键值对或“消息”。在实际当中,事件将包含时间戳,不过为了简单起见,我们将忽略这些细节。主题有自己的名字,比如 payments、truck-geolocations、cloud-metrics 或 customer-registrations。
主题有各种配置参数,比如压缩(compaction)和数据保留策略。很多人把 Kafka 主题看成是临时性的,你可以强制配置存储限制(例如,配置一个主题最多存储 3TB 事件,达到这个限制之后,旧事件会被删除)或时间限制(例如,配置一个主题保留事件最多 5 年时间)。不过你也可以无限制地存储数据,就像传统的数据库一样,只需要把保留策略配置为无限制,事件就会被永久保存下来。纽约时报就是这么做的,他们的大部分关键业务数据就保存在 Kafka 中,并将其作为单一的事实来源。
存储格式:事件的序列化和反序列化
事件被写入主题时被序列化,从主题读取时被反序列化。反序列化是指将二进制数据转成人类可理解的形式,序列化则反过来。需要注意的是,这些操作是由 Kafka 客户端完成的,也就是那些应用程序,比如 ksqlDB、Kafka Streams 或者使用了 Kafka Go 语言客户端的微服务。Kafka 有多种存储格式,常见的有 Avro、Protobuf 和 JSON。
Kafka 代理不关心序列化格式或事件“类型”,它们只看到事件键值对的原始字节码(在 Java 里为<byte[],byte[]>),所以代理不知道数据里包含了什么东西,数据对代理来说就像黑盒一样。这种设计看起来很“笨”,但实际上是很聪明的,因为相比传统的消息系统,Kafka 代理具备了更好的伸缩性。
在事件流和类似的分布式数据处理系统中,很多 CPU 时间被用在数据的序列化和反序列化上。可以想象一下,如果你要粉刷一个房间,花在计划上的时间比花在粉刷上的时间还要多。所幸的是,Kafka 代理不需要做这些事情!
分区存储
Kafka 的主题由分区组成,也就是说,一个主题包含了分布在多个不同代理上的“桶”。这种分布式数据存储方式对伸缩性来说至关重要,因为客户端可以同时从不同的代理读取数据。
在创建主题时必须指定分区数量,每个分区将包含主题的部分数据。为了实现数据容错,每个分区可以有多个副本,副本可以跨区域或跨数据中心,当发生故障或执行维护任务时,总会有几个代理上的数据是可用的。常见的主题副本数量一般为 3。
在我看来,分区是 Kafka 最基本的一个概念,它是 Kafka 伸缩性、弹性和容错能力的基础,我们将多次提到分区这个概念。
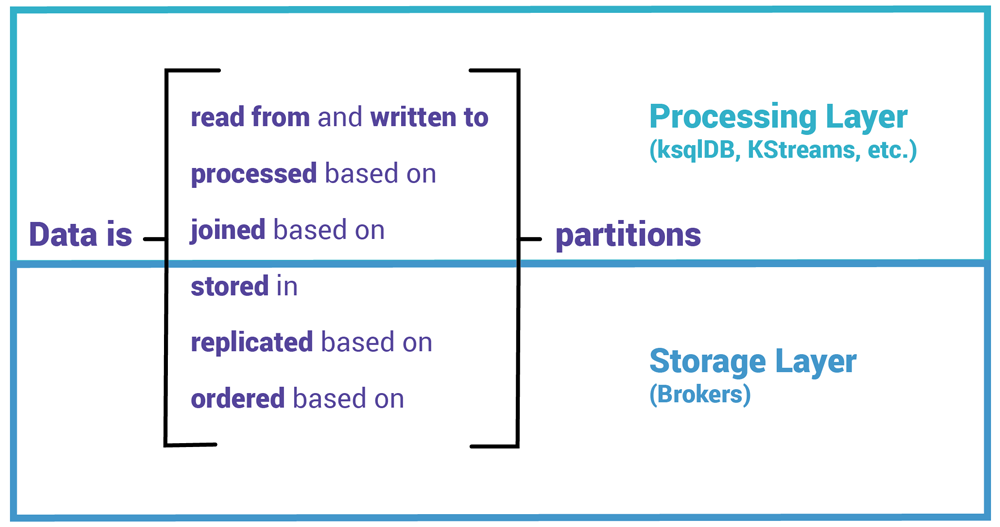
分区是最基本的构建块,它为 Kafka 带来了分布式能力、伸缩性、弹性和容错能力
事件生产者决定了事件的分区
Kafka 将事件生产者和事件消费者解耦开,这也是 Kafka 比其他消息系统更具伸缩性的原因之一。生产者并不知道哪个消费者读取了事件,读取的频率是怎样的,或者是否读取了事件。消费者可以是零个、几十个、几百个,甚至是几千个。
生产者决定了事件的分区,即事件是如何分布在同一个主题的不同分区里的。确切地说,生产者使用了分区函数 f(event.key, event.value)来决定一个事件应该被发送给主题的哪个分区。默认的分区函数是 f(event.key, event.value) = hash(event.key) % numTopicPartitions,在大多数情况下,事件会被均匀地分布在可用的分区上。分区函数实际上提供了除事件键以外的信息,比如主题的名字和集群元数据,不过这些东西不在本文的讨论范围之内。
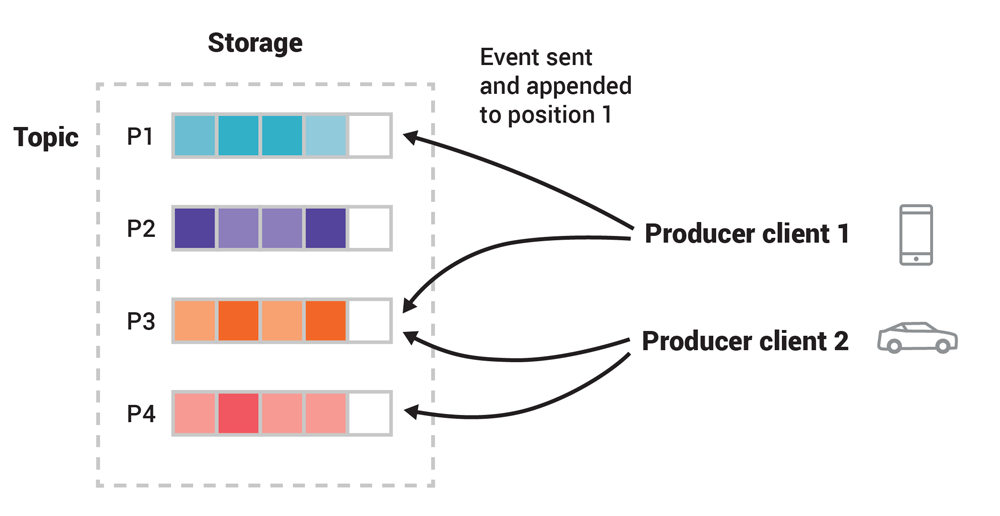
在这个例子中,主题有 4 个分区,从 P1 到 P4。两个不同的生产者客户端各自向主题发布事件,具有相关性的事件被写到同一个分区。请注意,如果有必要,两个生产者可以向同一个分区写入数据。
如何给事件分区:具有相同键的事件放在同一个分区
之前已经有篇文章介绍了如何选择正确的分区数量,所以现在我们将把注意力放在如何对事件进行分区上。分区的主要目标是保证事件的顺序:生产者应该把“相关”的事件发送给相同的分区,因为 Kafka 只保证单个分区内的事件是有序的。
为了说明如何分区,我们以更新物流公司卡车地理位置信息为例。对于这种场景,同一辆卡车的事件应该被发送给同一个分区。我们可以为每一辆卡车选择唯一的标识符作为事件的键(例如车牌或车架号),并使用默认的分区函数。
不过,除此之外,分区还有另外一个好处。流式处理应用程序通常会使用消费者群组,这些消费者同时读取同一个主题。对于这种情况,我们需要控制不同的分区分配给了同一群组里的不同消费者。
那么,在哪些情况下具有相同键的事件会被分配给不同的分区?
主题的配置发生变化:有人增加了主题的分区数量。在这种情况下,默认的分区函数 f(event.key, event.value)会为一小部分事件分配不同的分区,因为分区函数里的模数发生了变化。
生产者的配置发生变化:生产者使用了自定义的分区函数。
对于这类情况要格外小心,因为解决这些问题需要做额外的工作。为此,我们建议使用较大的分区数量,避免发生重新分区。
我个人建议一个主题使用 30 个分区,这个数字足以满足一些高吞吐量场景的需求,同时又不超过一个代理可以处理的分区数量。另外,这个数字可以被 1、2、3、5、6、10、15、30 整除,可以均匀地分布工作负载。Kafka 集群可以支持 20 万个分区,所以这种使用大分区数量的做法对于大多数人来说是安全的。
总结
这篇文章介绍了 Kafka 的存储层:主题、分区和代理,以及存储格式和分区机制。在后续的文章中,我们将深入了解 Kafka 的数据处理层。我们将从事件的存储跳到事件的处理,探索流和表以及数据契约和消费者群组,以及如何用这些东西实现分布式大规模并行处理应用程序。
原文链接:
系列文章:

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论