

如果你有关注与 JVM 开发相关的场景,你会发现,过去几年是 Java 垃圾回收器的“复兴”时期。先是 G1 成为 Java 9 的默认垃圾回收器,继而 Oracle 发布了 ZGC(受 Azul 无停顿回收器 C4 的启发),然后是 Red Hat 开发了 Shenandoah。从这些迹象可以看出:
垃圾回收问题还远没有得到妥善的解决。
人们越来越关注那些可以更快回收垃圾以及能够处理更大堆内存的回收器。
在这篇文章中,我将分享我在Grammarly的一个真实项目中使用 Shenandoah 的经验。写这篇文章的目的并不是为了对这项技术致敬,也绝对不是闲着蛋疼。我希望能够让读者有足够的理由去关注他们项目中使用的 GC,并解释 Shenandoah 适合用在哪些场景中,以及如何在生产环境中用好它。
Shenandoah GC 是什么东西?
Shenandoah GC 是最新的 JVM 垃圾回收器,由 Red Hat 的一个团队负责开发。垃圾回收器的并发性是指在应用程序运行的同时进行垃圾回收,而这就是 Shenandoah 的目标——最小化垃圾回收对用户代码造成的停顿。Shenandoah 的另一个设计目标是可以处理大堆和小堆。
网上已经有很多与 Shenandoah GC 相关的资料,这里就不再累述了。不过,下面还是列出了一些与 Shenandoah 和其他并发性 GC 相关的特点。
经典 GC(也叫作 STW,Stop-The-World)会在没有可用内存时暂停应用程序线程,回收垃圾,并压缩存活的对象,然后让应用程序继续执行。这种停顿有可能长达几十秒,而且会随着堆的增大而延长。
很多现代 GC(例如 G1)有分代的概念,它们根据对象在垃圾回收过程中存活下来的次数对这些对象进行分代,并针对每一个分代的对象使用不同的回收策略。
Shenandoah GC 也会造成 STW 停顿,但通常都很短暂,因为它是在应用程序运行的同时执行大量的 GC。这种停顿不会随着堆的增大而延长。
Shenandoah GC 没有分代的概念,所以它需要在每次回收周期里对存活对象进行标记(分代 GC 不需要这个操作)。不过反过来,Shenandoah 也避免了分代 GC 的一些额外的工作负载。
Shenandoah GC 的并发性是以降低应用程序的吞吐量为代价。
Shenandoah 是 JDK 12 的一部分,AdoptOpenJDK 12中就包含了 Shenandoah。不过,它也被移植到了 Java 8 和 Java 11 中,这个页面列出了一些可用的二进制版本。
为什么要使用 Shenandoah GC
开发者社区对 GC 停顿存在一个很大的误解,认为 GC 停顿只会给那些对延迟敏感的应用程序(比如高频交易应用程序)带来重大影响。实际上,如果你的应用程序可以接受任意长度的 GC 停顿,那么为什么不去选择一个侧重于吞吐量的 STW GC(比如 ParallelGC)呢?不过,如果你的应用程序是交互式的(比如一组 API 或一个网站),那么 GC 停顿所造成的影响就会更加明显了。GC 停顿会拖慢应用程序,在外界看来,它就像冻住了一样。在 GC 停顿期间发给服务器的请求会更晚收到响应,根据停顿时间的不同(传统的 GC 停顿有可能达到几十秒),客户端有可能会出现超时。如果客户端进行重试,服务器端就会有更多待处理的请求,这个时候需要使用断路器。长时间的 GC 停顿也可能造成服务的健康检测失效,并导致服务被重启。而在一个服务重启期间,其他服务需要承担更多的负载,它们所经历的停顿会更长,这就像是一个恶性循环。
不可预测的 GC 停顿给系统带来的影响远远超过了应用程序本身。客户端出现回压,请求队列溢出,监控控制台满是各种超时异常,运维人员忙得团团转。对于一个可以应对各种情况的系统来说,需要在 CPU 时间、队列长度、可接受的响应时间方面具备缓冲能力。
Shenandoah 降低了应用程序的一部分吞吐量,但相比传统 GC,它的代价要低一些。吞吐量的降低是可预测的,而且很容易做出应对计划。例如,如果你发现应用程序的运行速度慢了 10%,那就增加 10%的服务器。而 GC 停顿发生得非常迅速,你无法针对它们进行“自动伸缩”,你能做的是为它们分配额外的资源,这些资源在大部分时间是闲置的,造成了金钱的浪费。
闲扯了这么多,接下来让我来介绍一下我在真实项目中使用 Shenandoah 的经验。
初次相遇
先让我介绍一下这个应用程序,它实际上是一个反向代理,会对请求做一些预处理和后处理操作。代理对进入的请求稍作修改,把它们发给多个上游服务器,在收到来自上游的响应后,对响应进行合并,然后返回给客户端。这个看似简单的项目实际上有点复杂,因为请求和响应里会带有大量的 JSON,而且我们要求每秒处理 1 万个请求,网络带宽达到了每秒 350MB。我们使用了 AWS c5.9xlarge 实例,设置了 57GB 内存。应用程序本身不需要消耗多大内存,但它需要有足够的内存来暂存等待上游响应(最长响应时间为 5 秒钟)的请求。
刚开始我们使用的是 G1,新创建的服务在达到负载峰值之前可以正常运行,但在达到负载峰值后就变得非常脆弱。时而会出现几秒钟的 FullGC,并间接性地出现 100 毫秒到 200 毫秒的停顿。一个预期每秒可以处理 1 万个请求的服务在耗费 70%资源处理负载时伴随着 5 秒钟的停顿,这种情况你能想象吗?很多请求被积压起来,在停顿之后的数秒内,它就像抽了疯一样。停顿期间和停顿之后被挂起的请求造成了 QoS 的降级。
在一开始,调整 G1 选项似乎对我们有点帮助,但后来反而变得更加不稳定。最直接的办法是调整年轻代和老年代比例,但这么做让应用程序出现奇怪的故障。我得承认自己并不是一个 GC 专家,我的方法可能有点稚嫩,但对于一个 Java 应用程序开发人员来说,你也别指望我对 GC 有多么深入的了解。
经过一些无效的尝试之后,我们切换到了可以使用 Shenandoah 的 OpenJDK 8 镜像(shipilev/openjdk-shenandoah:8),并在命令行参数中加入-XX:+UseShenandoahGC,然后就出现了下面的这种情况:
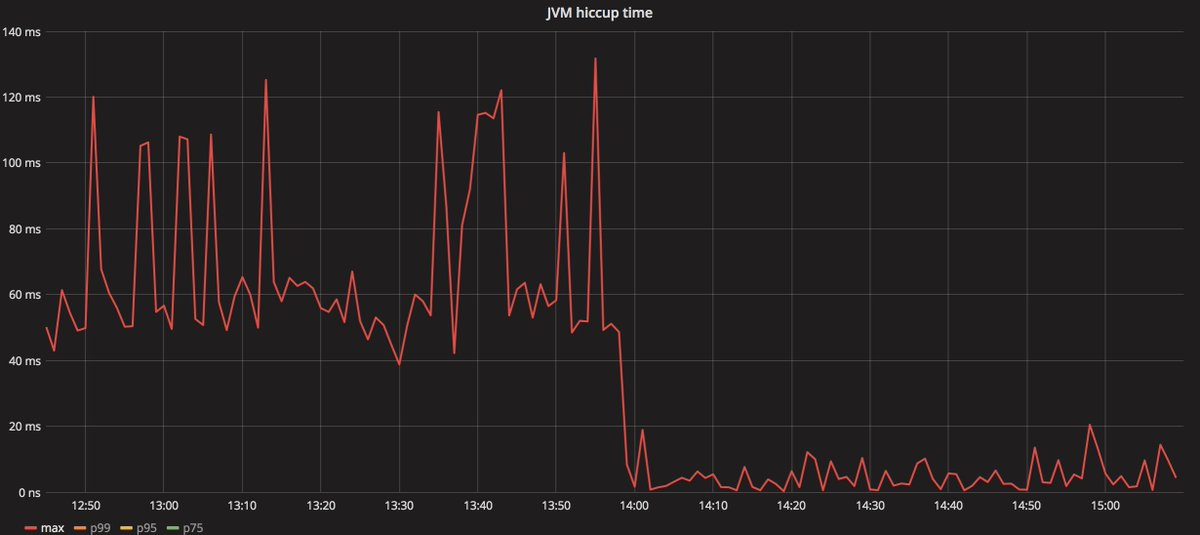
图中显示的是最大 GC 停顿的变化情况。Shenandoah 将“正常”的最大停顿从 50-150 毫秒减少到了 10-20 毫秒,而且图中并没有显示使用 G1 时常会出现的数秒钟的停顿。
突然间,服务的表现非常稳定。在解决了这些性能瓶颈之后,我们将每台机器的吞吐量又提升了一些。我们将堆大小设置到了 57GB,即使堆大了很多,但延迟并没有因此而增加。有了更大的堆缓冲区,我们就可以处理更大的流量高峰。总的 QoS 也得到了改进,并在更长的时间跨度内减少了延迟百分位。
在 Shenandoah 的日子里
新垃圾回收器给我们带来的好日子持续了一段时间。虽然只是切换了垃圾回收器,但它在应用程序运行时方面带来的改进对我们来说是个巨大的胜利。不过,如果你对服务的性能和稳定性要求很苛刻,只是简单地修改一两个参数是不够的。接下来,我将进一步介绍这个回收器以及如何更好地使用它。
jvm-hiccup-meter
jvm-hiccup-meter是一个小型的工具库,用来度量系统的停顿时间。它是jHiccup的极小化版本。jHiccup 用来累计程序运行整个过程的停顿时间,而 jvm-hiccup-meter 则通过回调持续地报告系统的停顿。
因为 Shenandoah(或者其它 Java GC 也是)已经通过 MBean 和 GC 日志告诉我们有关 GC 停顿的信息,所以这个库似乎有点多余。但是,在有些时候,它可以报告可能被 GC 漏掉的停顿,或者其他与 GC 无关的停顿(例如在进行堆转储时)。
这个所谓的库只是一个简单的 Java 类,如果你不想在项目中引入新的依赖,可以直接将这个类拷贝到项目中。
jvm-alloc-rate-meter
包括 Shenandoah 在内的大多数现代 GC 都可以轻松自如地处理大量的垃圾,但对于并发回收器来说,它们回收垃圾的速度需要比应用程序生成垃圾的速度更快。因此,如果能够知道应用程序生成对象的速度就好了。
可惜的是,JVM 并没有为我们提供这种方式。我们可以从 GC 日志中获取一些信息,但并不能用来进行实时监控。不过,我们可以使用另一个叫作jvm-alloc-rate-meter的库,用它来度量虚拟机分配内存的速率,并将这些数据发给监控系统。通过持续地观察这些指标,我们就可以直观地知道应用程序是不是分配了太多内存,这样就可以检测到可能会导致长 GC 停顿的峰值。
这个库也只是一个 Java 类,也可以直接拷贝到项目中。
内存分配分析器
知道内存分配速率固然很有用,但如果我们想知道什么时候该减少应用程序产生的垃圾,内存分析器似乎会更有用。它会告诉我们应用程序的哪些部分产生了最多的垃圾,然后我们就可以针对这些部分进行优化。
这类分析器有很多,我们最后选择的是async-profiler。async-profiler 使用了非侵入式的方式,所以可能不会非常准确,但因为开销非常小,可以被用在生产环境中。另外,async-profiler 生成的图表很容易看懂。
Shenandoah 的故障模式
即使 Shenandoah 很强大,拥有创新的设计,但它并不是一道魔法——它也只是一款运行在这个纷繁世界中的软件而已。所以,在某些特定条件下,它无法达到所宣称的停顿。因为并发型的 GC 是与应用程序一起运行的,也就是说,在 GC 运行的同时应用程序会持续地分配新对象。如果应用程序产生垃圾的速度超过了 GC 的回收速度,我们就有麻烦了。Shenandoah 开发者团队对这个回收器的故障模式也是直言不讳,并在文档中详细地描述了它们。
当垃圾回收速度赶不上垃圾生成速度时,Shenandoah 首先会尝试步调调整(pacing),即让分配对象的线程稍作停顿,降低垃圾生成的速度。这个与 STW 停顿有点像,但其实也不太像,因为它其实只影响个别线程,而不是整个应用程序。因为步调调整不作为 GC 停顿处理,所以监控工具很难看到它们,只能从 GC 日志里查找是否发生过步调调整。
如果这样还不行,Shenandoah 会进入退化模式,也就是进行老式的 STW GC,不一样的地方在于已经并发执行的 GC 工作不会重复执行。换句话说,如果 Shenandoah 能够及时进行并发回收,即使进入退化模式,停顿也较短,因为不需要在 STW 阶段完成所有的工作。与步调调整不一样的是,退化模式 GC 将被视为正常的停顿,因此监控工具可以看得到。如果你发现 Shenandoah 进入退化模式,说明创建对象的速度太快了。
最后,如果 Shenandoah 在退化模式下无法释放足够的内存,仍然会发生 STW GC。Shenandoah 的 FullGC 是并行的,所以至少会比单线程的 STW GC 快,但停顿仍然会比较长。幸运的是,我们在我们的工作负载中还没有碰到这样的 FullGC。
Shenandoah 调优
使用 Shenandoah 的默认配置就可以应对大部分场景,所以大部分情况下你不需要去修改配置。不过,其中有一个最重要的参数-Xmx,只要通过这个参数指定足够大的堆内存,剩下的事情就交给 Shenandoah 了。不过,随着你对它有了进一步的了解,可以对它做出适当的调整,让它在各种特定的工作负载下运行得更好。
Shenandoah 的一个主要调节选项是 heuristic 类型,它会根据这个参数决定什么触发 GC。这个参数的默认值是 adaptive,有就是根据程序启动前几分钟对象的分配速速来推断 GC 的阈值。你也可以把它改成 static,并指定在剩余多少可用内存时触发 GC。如果你注重延迟而不是吞吐量,也可以把它设置为 compact,这样就不会发生步调调整或进入退化模式。我们最终选择了 compact,CPU 使用率不会再像之前那么高了。
一些发现
大量的弱引用(软引用、虚幻引用、finalizer)会增加 Shenandoah 的停顿时间,因为这些引用需要在 STW 期间处理。即使应用程序中没有直接使用弱引用,但一些依赖的库或框架可能会用到。我们在项目中使用了内存泄漏检测机制,而这个机制又使用了 finalizer,所以,当我们在生产环境中禁用了内存泄漏检测机制,停顿时间就得到了大幅的改善。
一般来说,Java 垃圾回收器与同步块是不一样的,因为同步块会导致监视器膨胀并增加根对象集合。我们之前犯了一个错误,为了节省 50 字节的对象空间,使用同步类方法替代了 ReentrantLock。经过这个“优化”之后,Shenandoah 的停顿反而增加了,所以我们又回退到使用 ReentrantLock。
这个发现让我们感到很吃惊。不知道是什么原因,在运行了 7 天之后,Shenandoah 的性能逐渐下降,停顿时间也逐渐变长。经过一番调试,我们发现了一个由反射调用引起的类加载器泄漏。很显然,JVM 会在运行时通过反射的方式生成类,而这些类不会被卸载。我们目前通过设置-Dsun.reflect.inflationThreshold=2147483647 来临时规避这个问题。
确保 Shenandoah 拥有足够的线程!当然,这个是由 Shenandoah 自行决定的,它会根据机器的 CPU 核数来决定使用多少个线程。不过,如果你刚好使用的是 Amazon ECS,并且运行在 JVM 9+上,而你又忘记为容器设置 CPU 共享,那么 Java 只会看到一个 CPU 核数!这个时候 Shenandoah 只使用一个线程来回收垃圾,那么整个应用程序的运行速度可想而知了。
结论
我希望读者们在读完这篇文章后可以看看 Shenandoah 是不是可以解决你们的一些问题。如果可以,请分享你们的经验,这样就会有更多的人知道这个新垃圾回收器。
原文链接
Shenandoah GC in production: experience report

让所有人认同的文字称不上表达

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论 2 条评论