

理解层次聚类
与 K-均值聚类算法(K-means)不同,不需要指定聚类的数量。
结果汇总在树状图,树状图可以方便地解释数据和选择任何数量的聚类。
基本思路
专注 :自下而上(又称凝聚聚类(Agglomerative clustering))
从单个观察开始(又称 叶子 )开始,作为聚类。
通过将叶子合并成 树枝 向上移动。
将树枝与其他叶子或树枝合并。
最终,当所有的东西都合并到一个聚类时,到达顶端。
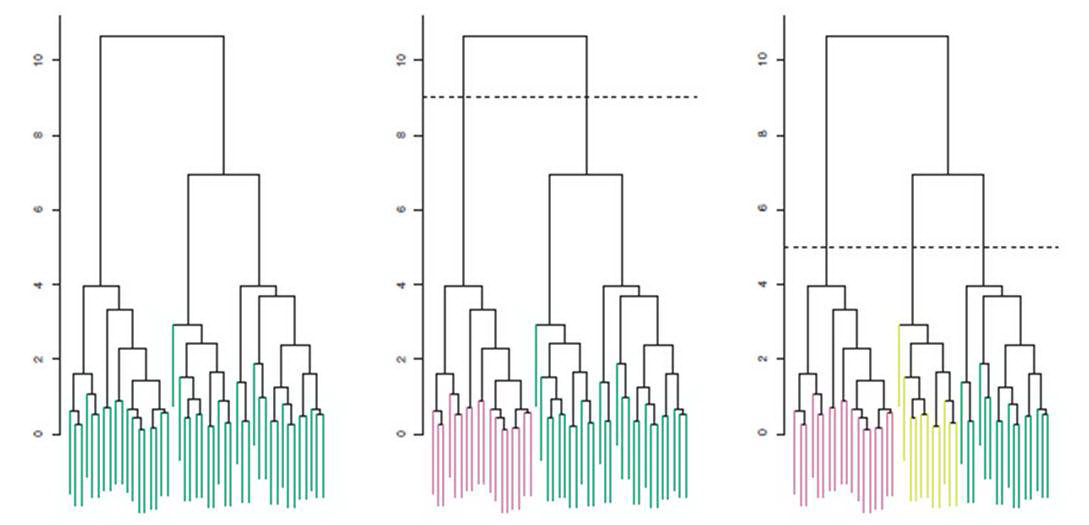
树状图示例。
解释树状图
在适当的高度上进行切割,以获得所需聚类的 #。
垂直轴:相异度度量(或距离)——两个聚类合并的高度。
高度表示聚类的相似性。
较低的高度 → 更相似 。
水平轴并不表示相似性。
交换左右分支并不影响树状图的意义。
它如何衡量聚类之间的差异?
基于度量(最常见的是曼哈顿距离(Manhattan distance)或欧几里得距离(Euclidean distance,亦称欧氏距离))。
最长距离法(Complete linkage)(即最远邻法(furthest-neighbor))
最短距离法(Single linkage)(即最近邻法(nearest-neighbor))
平均距离法(Average linkage)
质心距离法(Centroid linkage)
2, 基于相关性的距离
查找观测值之间的相关性。
层次聚类的缺点
计算成本高——不适用于大数据集。
,而表示 K-均值。
对噪声和离群值敏感。
使用层次聚类对 FIFA20 的球员进行分组
数据清理/预处理(第一部分中的代码)
标准化数据
基于平均距离法的层次聚类
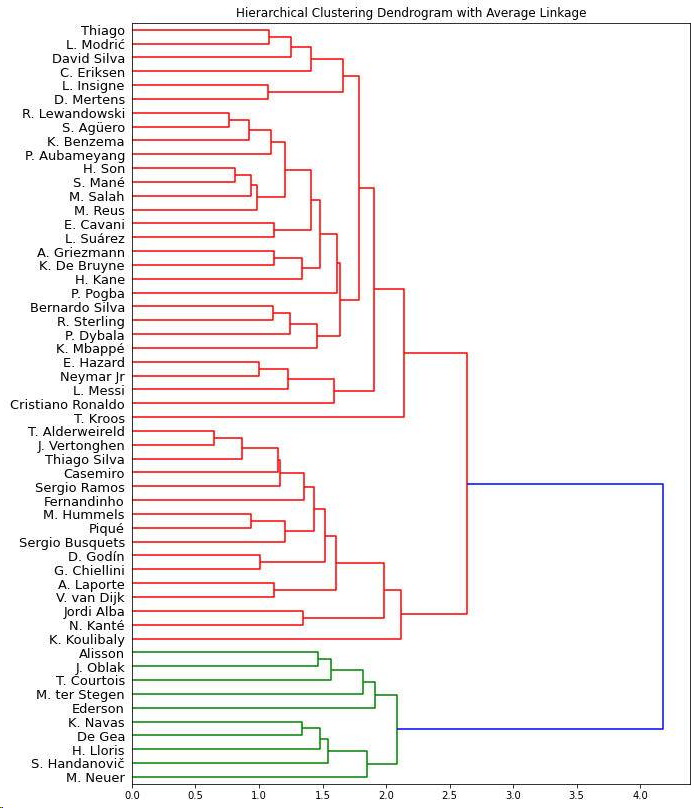
分成两组:守门员和其他人
最短距离法
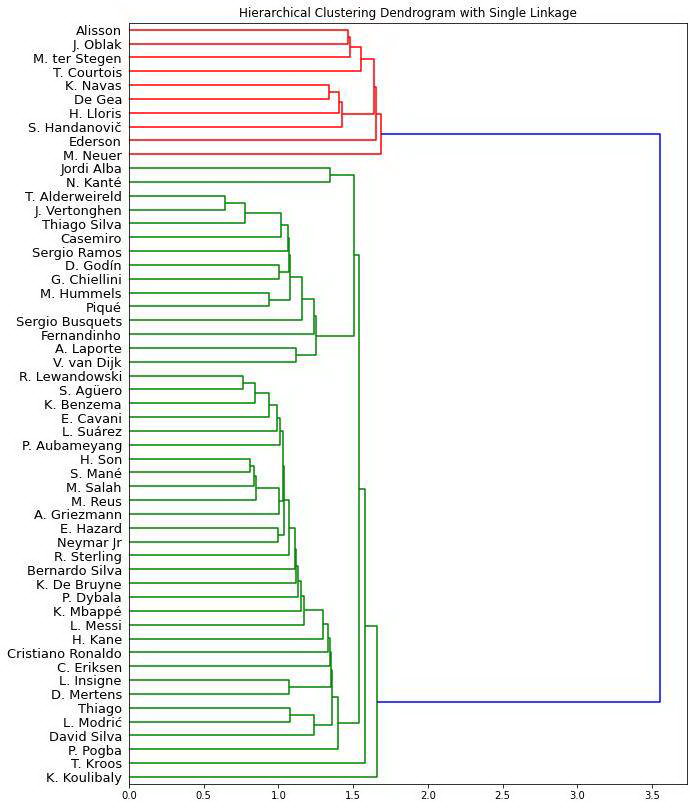
分为守门员和其他人
质心距离法
再次分成守门员和其他人。
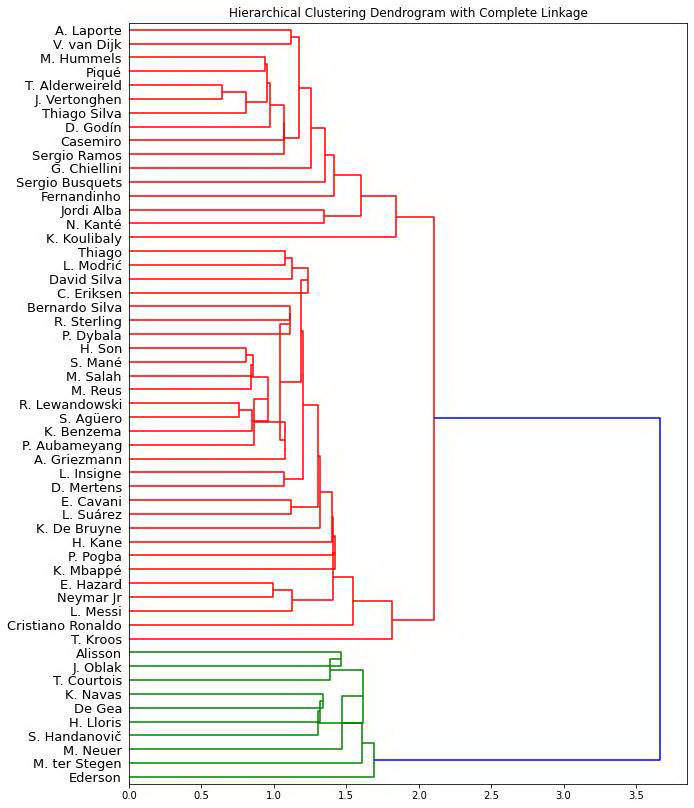
最长距离法
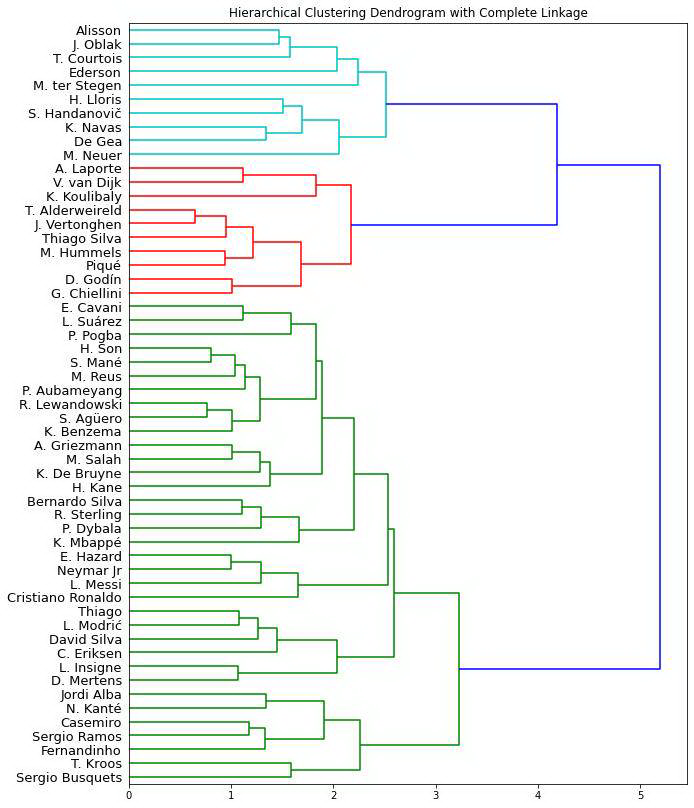
结论
最长距离法似乎是将球员进行最准确地分组的方法!
感谢阅读本文,希望对你有所启迪。
本文的 GitHub 仓库:https://github.com/importdata/Clustering-FIFA-20-Players
作者介绍:
Jaemin Lee,Jaemin Lee,专攻数据分析与数据科学,数据科学应届毕业生。
原文链接:

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论