

最近,在语言预训练方面的进展使自然语言处理领域取得了巨大进展,这得益于 BERT、RoBERTa、XLNet、ALBERT 和 T5 等最先进的模型。尽管这些方法在设计上有所不同,但它们都有一个共同的理念,即在对特定的 NLP 任务(如情感分析和问答系统)进行调优之前,利用大量未标记的文本来构建语言理解的通用模型。
本文最初发布于谷歌 AI 博客,经原作者授权由 InfoQ 中文站翻译并分享。
最近,在语言预训练方面的进展使自然语言处理领域取得了巨大进展,这得益于BERT、RoBERTa、XLNet、ALBERT和T5等最先进的模型。尽管这些方法在设计上有所不同,但它们都有一个共同的理念,即在对特定的 NLP 任务(如情感分析和问答系统)进行调优之前,利用大量未标记的文本来构建语言理解的通用模型。
现有的预训练方法通常归为两类:语言模型(LM),如GPT(从左到右处理输入文本,根据前面的上下文预测下一个单词)和遮蔽语言模型(MLM),如 BERT、RoBERTa、ALBERT(它可以预测输入中被遮蔽的一小部分单词的特征。)。MLM 具有双向的优点,它不是单向的,因为它们可以“看到”被预测 Token 左右两侧的文本,而不是只看到一侧的文本。然而,MLM 方法(和相关方法,如 XLNet)也有一个缺点。与预测每个输入 Token 不同,这些模型只预测了一个很小的子集,被遮蔽的那 15%,减少了从每个句子中获得的信息量。
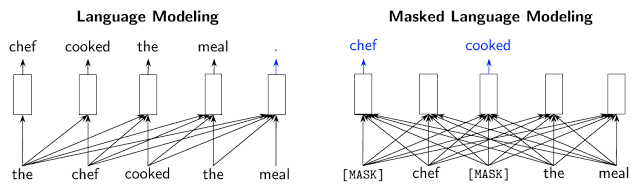
现有的预训练方法及其不足。箭头表示使用哪些 Token 来生成给定的输出表示(矩形)。左:传统的语言模型(如 GPT)只使用当前单词左边的上下文。右:遮蔽语言模型(例如 BERT)使用来自左右两边的上下文,但是只预测每个输入的一小部分单词
在“ELECTRA:将预训练文本编码器作为鉴别器而不是生成器”一文中,我们采用了一种不同的方法来进行语言预训练,它提供了 BERT 的好处,但学习效率要高得多。ELECTRA(Efficiently Learning an Encoder that Classifies Token Replacements Accurately )是一种新的预训练方法,在计算预算相同的情况下,它的性能要优于现有的技术。例如,在GLUE自然语言理解基准下,仅使用不到¼的算力,ELECTRA 的性能就堪比 RoBERTa 和 XLNet,并且在SQuAD问答基准上成果领先。ELECTRA 出色的效率意味着它即使在小规模下也能工作得很好——它在一个 GPU 上进行几天的训练,就可以获得比 GPT 更高的精度,而 GPT 使用的算力是前者的 30 倍。ELECTRA 是 TensorFlow 上的一个开源模型,包含了一些现成的预先训练好的语言表示模型。
加速预训练
ELECTRA 使用一种新的预训练任务,称为替换 Token 检测(RTD),它训练一个双向模型(类似 MLM),同时学习所有输入位置(类似 LM)。受生成对抗网络(GANs)的启发,ELECTRA 训练模型来区分“真实”和“虚假”输入数据。与在 BERT 中使用“[MASK]”替换 Token 来变换(corrupt)输入不同,我们的方法通过使用不准确(但有些可信的)的伪 Token 替换一些输入 Token 来变换输入。
例如,在下图中,单词“cooked”可以替换为“ate”。虽然这有一定的道理,但它并不能很好地契合整个上下文。预训练任务需要模型(即鉴别器)判断原始输入中的哪些 Token 已被替换或保持不变。至关重要的是,这个二元分类任务应用于每个输入 Token,而不是只有少数被遮蔽的 Token(在 BERT 类模型中是 15%),这使得 RTD 比 MLM 更高效——ELECTRA 只需要更少的样本就可以达到同样的性能,因为它可以从单个样本中获取更多的训练信号。同时,RTD 也带来了强大的表示学习,因为模型必须准确地学习数据分布的表示才能解决问题。
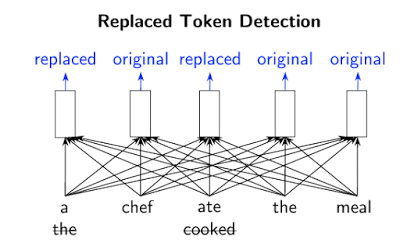
替换 Token 检测训练了一个双向模型,同时从所有的输入位置学习
替换 Token 来自另一个称为生成器的神经网络。虽然生成器可以是任何生成 Token 输出分布的模型,但是我们使用的是一个小型的遮蔽语言模型(即与鉴别器联合训练的 BERT 模型,其 hidden size 较小)。尽管输入鉴别器的生成器的结构类似于 GAN,但由于将 GAN 应用于文本比较困难,我们尽最大可能地训练生成器来预测遮蔽词,而不是相反。生成器和鉴别器共享相同的输入词嵌入。在预训练之后,生成器被丢弃,鉴别器(ELECTRA 模型)会针对下游任务微调。我们的模型都是用的transformer神经结构。
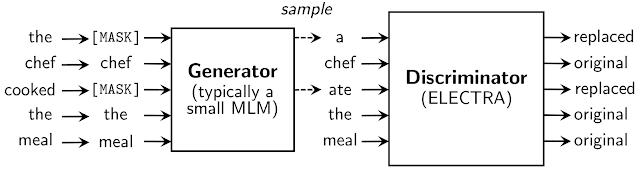
关于替换 Token 检测(RTD)任务的详细信息。伪 Token 是从与 ELECTRA 联合训练的小型遮蔽语言模型中抽取的
ELECTRA 试验结果
我们将 ELECTRA 与其他最先进的 NLP 模型进行了比较,发现在相同的计算预算下,它比以前的方法有了很大的改进,在使用的计算量不到 25%的情况下,其性能就与 RoBERTa 和 XLNet 相当。
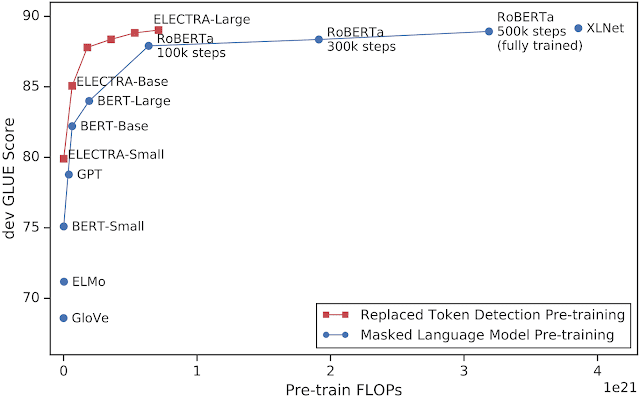
X 轴表示用于训练模型的计算量(以FLOPs为单位),y 轴表示 dev GLUE 得分。ELECTRA 比现有的预训练 NLP 模型学习效率更高。请注意,GLUE 上当前最好的模型如T5(11B)并不适合放到这副图上,因为它们比其他模型使用了更多的计算(大约是 RoBERTa 的 10 倍)。
为了进一步提高效率,我们试验了一个小型的 ELECTRA 模型,它可以在 4 天内在单 GPU 上训练得到良好的精度。虽然没有达到需要许多 TPU 来训练的大型模型的精度,但 ELECTRA-Small 仍然表现得很好,甚至超过了 GPT,而只需要 1/30 的计算。最后,为了看下这令人鼓舞的结果在大规模时是否能够保持,我们使用更多的计算来训练一个大型的 ELECTRA 模型(与 RoBERTa 的计算量大致相同,约为 T5 的 10%)。该模型在SQuAD 2.0问答数据集(见下表)上达到了一个新的高度,并且在 GLUE 排行榜上超过了 RoBERTa、XLNet 和 ALBERT。大型的T5-11b模型在 GLUE 上的得分更高,但 ELECTRA 的大小只有 T5-11b 的 1/30,并且只使用 10%的算力来训练。
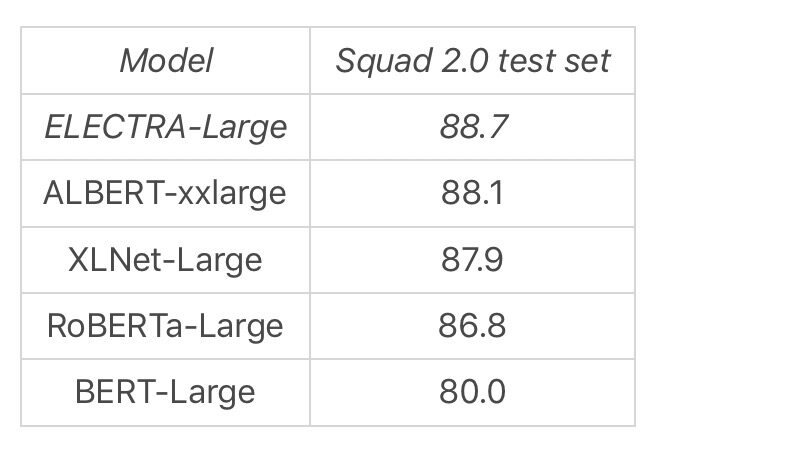
ELECTRA-Large 和其他先进模型的 SQuAD 2.0 分值(仅显示非集成模型)
ELECTRA 发布
我们发布了对 ELECTRA 进行预训练和对下游任务进行调优的代码,目前支持的任务包括文本分类、问答系统和序列标记。该代码支持在一个 GPU 上快速训练一个小型的 ELECTRA 模型。我们还发布了 ELECTRA-Large、ELECTRA-Base 和 ELECTRA-Small 的预训练权重。ELECTRA 模型目前只适用于英语,但我们希望将来能发布许多其他语言的预训练模型。
英文原文:More Efficient NLP Model Pre-training with ELECTRA

极客邦科技 总编辑

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论