

#导读
在之前的eBay云计算“网”事|网络超时篇和eBay云计算“网”事|网络丢包篇里,我们针对 Linux 主机网络中常见的延时和丢包问题进行了分析。本篇将关注网络中另外一个常见的问题: 重传 。在网络环境中,重传率的高低往往直接影响到数据的传输效率,因此也是用户应用比较关心的一个指标。
一、问题描述
某个部署到 Kubernetes 集群的应用,会有多个 SLB(Softare Load Balancer)节点来对接收的数据流量进行分发。这些 SLB 节点原本部署在物理机上,在将某个业务节点部署到 Kubernetes 集群后,发现每 10 秒的重传包个数,相对于运行在物理机上时更高, 如图 1 所示。于是我们着手进行排查。
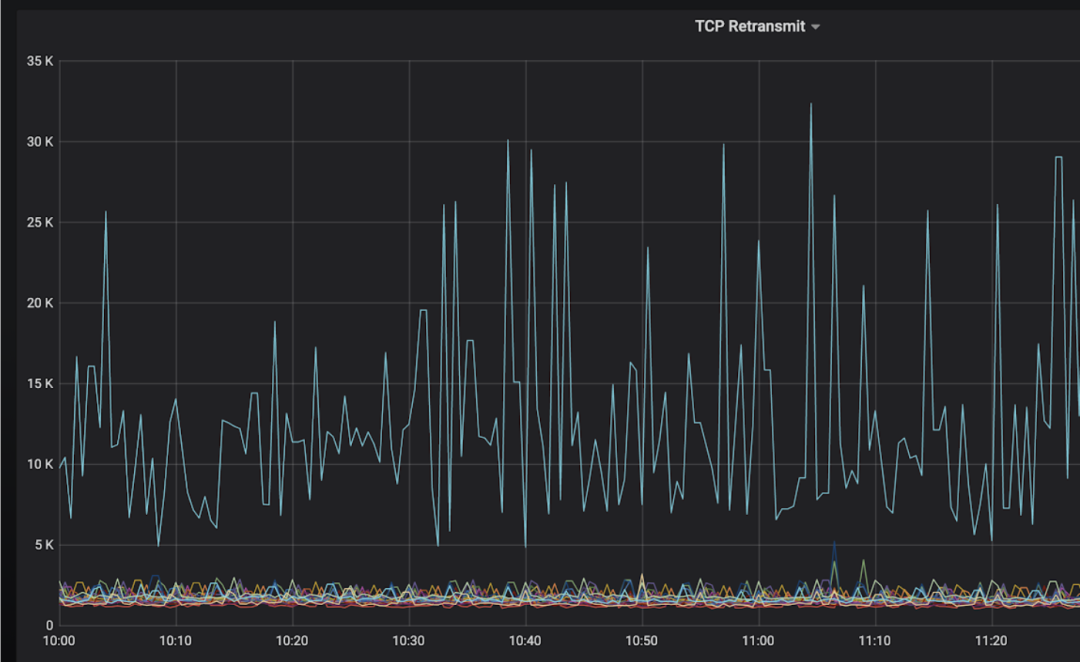
图 1 不同节点的 TCP 每 10 秒的重传个数
经过和应用方沟通并进入容器查看后,我们了解到相关信息:
每个SLB节点,同时会有 25k 左右的TCP链接。这些链接的客户端节点,不一定相同,每个客户端节点可能会跟SLB创建多个链接,链接的维持时间一般都比较短。
运行在物理机上的SLB节点,每10秒的重传包是 10k 左右,而运行在物理机上的SLB节点,每10秒的重传包在 2k 以下。
重传包个数从netstat -s|grep “segments retransmitted”得出,取10秒前后的差值,就得出每10秒的重传包数。
每个SLB节点的业务量差别不大。运行在Kubernetes集群中的SLB,业务量会比运行在物理机中的SLB流量多些,但是不至于造成重传统计上这么大的差别。
TCP数据包的重传和网络链接客户端、网络路径强相关。在客户端和网络路径不同的情况下,节点的重传率可能会不同。因此两方的重传数据对比,很难说明重传率高就是因为业务容器化引起的。但我们仍旧需要对重传着手进行分析,并给出合理的解释。
二、问题分析
1. 是否有数据丢包的情况发生
因为涉及到重传,第一反应就是查看是否有丢包的情况发生。从netstat -s的情况来看,并没有明显的丢包情况发生。
2. TCP协议栈配置参数是否一致
然后,我们对比下双边TCP配置参数,对比容器Pod network namespace和物理机下的/proc/sys/net的配置参数。两边的参数一致,除了TCP的拥塞(congestion)算法,前者是BBR,后者是CUBIC。于是修改了下容器内tcp_congestion_control的算法,一段时间后,当老的链接都关闭,新的链接拥塞算法都变为BBR后,重传包减少了一半左右,到了 6k/10秒 ,如图2所示。尽管指标有了很大的改善,但是重传率还是比较高。
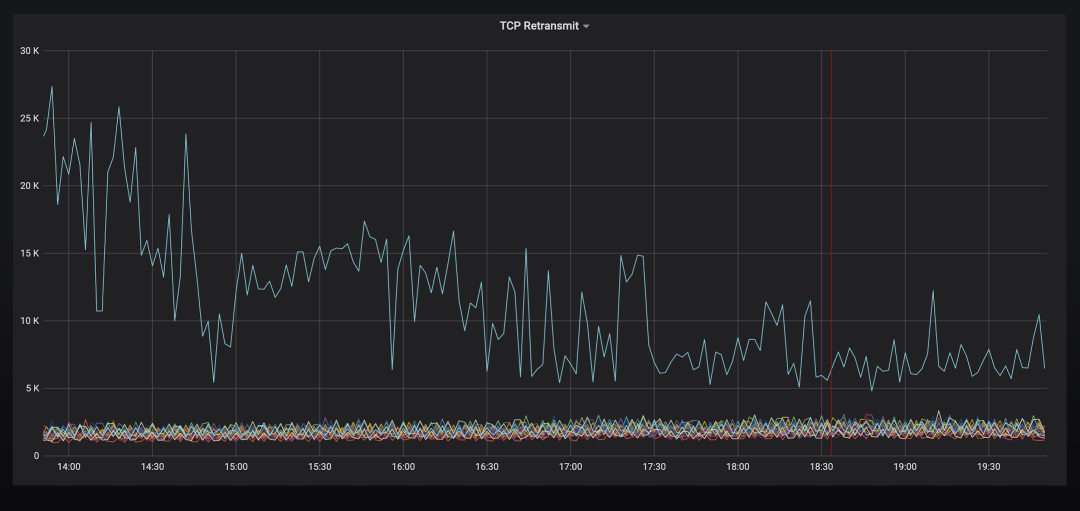
图2 修改TCP congestion算法为CUBIC
3. 重传的链接
因为链接比较多,我们需要查看具体是哪些链接的重传导致的问题。于是运行BCC的tcpretrans.py 工具,来查看具体重传的链接信息。 结果发现,重传比较多的,都属于四个固定的虚拟机客户端。
于是在这些节点上通过tcpdump进行抓包,发现了如下现象:
不管数据是来自于Pod还是来自于物理机的SLB,在虚拟机上一直能看到有包乱序的情况。
当接收到乱序包后,VM会发送SACK数据包,而在Pod接收到SACK数据包后,Pod会立刻进行重传,但物理机的SLB并没有。
4. 为何数据包会乱序
我们先来定位数据包乱序的原因。
在虚拟机所在的物理机上,对网卡和给虚拟机分配的tap端口上做tcpdump,数据包并没有乱序,因此可以判断, 乱序应该是发生在虚拟机内部了。
在虚拟机上kprobe了函数napi_gro_receive(),将接收的数据包进行打印,发现在数据包被该函数处理的时候,也并没有乱序,但是tcpdump上看到的数据包是乱序的,因此我们怀疑是gro引起的乱序问题。
通过ethtool -K eth0 gro off将虚拟机网卡的gro特性关闭。在gro关闭后,从tcpdump抓到的数据就不存在乱序情况了。因此将有包乱序的节点的gro都关闭,在gro关闭后,可以看到TCP的重传从 6k/10秒 降到了 4k/10秒 。
这些虚拟机使用的都是ubuntu 16.04的系统,且为4.4的kernel版本,所以网卡驱动的gro有bug,导致包乱序,而如果使用的是4.15 kernel版本,就不会有乱序的情况发生。
既然了解了包乱序的问题,那么遗留的问题就是,Pod和物理机对接收到SACK后的行为为何会不一致?
5. 为何收到SACK数据包的行为不一致
从netstat -s的命令输出来看,可以看出双方重传的差别,如图3所示:

图3 重传的原因
Pod容器的TCPSackRecovery和TCPLossProbes导致重传的次数差别不大,而物理机上,绝大部分的重传都是由TCPLossProbes引起的,TCPSackRecovery只是TCPLossProbes的 1/20 左右。如果我们可以减少Pod容器的TCPSackRecovery比例,那么就能大大降低数据的重传。
在TCP协议栈中,通过FACK,SACK,RACK等算法来决定是否对TCP数据进行重传,这些算法在众多的RFC文档中都有详细定义,而对于开发人员来说,相对便捷的途径,是从TCP协议栈的实现来更快地了解TCP重传的多种原因。
从TCP协议栈的实现来看,它会调用tcp_retransmit_skb()函数来进行TCP数据包的重传,于是大概浏览了协议栈代码,整理出函数的调用关系图,如图4所示:
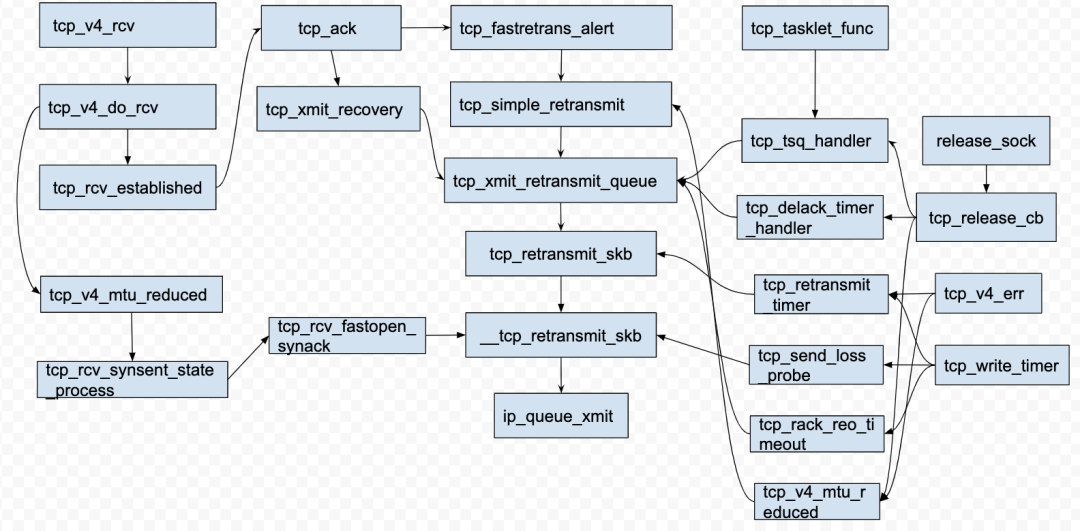
图4 TCP重传函数调用路径
如果在调用函数tcp_retransmit_skb()的地方,打印出函数调用的协议栈,那么可以很清楚地看到是因哪个路径而引起的重传。这类数据如果将函数调用栈打印出来,就是图5显示的情况:

图5 重传的函数调用栈
在tcp_ack()中调用tcp_xmit_recovery来进行重传,期间需要调用多个函数进行TCP链接是否要进入recovery状态的判断。直接的栈调用关系,体现不出这种判断的具体细节,也不知道TCP链接进入recovery状态的具体原因。因此需要继续查看代码,进行更深入的分析。
在tcp_xmit_recovery()中,会根据rexmit的值来判断是否会调用tcp_xmit_retransmit_queue()。而决定rexmit值的地方,就在函数tcp_fastretrans_alert()中。该函数也会有多个路径来决定是否给rexmit赋值。 因此,基于以下的逻辑及eBPF,我们设计了一个重传的定位工具:
如果数据重传,打印出重传的栈,就可以判断出数据包的重传究竟是由于输入的数据引起的,还是timer超时引起的。
针对输入数据引起的重传,我们需要知道输入数据的具体信息,以及重传数据的具体信息。这些信息包含数据的源IP,目的IP,tcp sequence,ack sequence,长度,tcp flag字段等。
在此基础上,我们需要知道输入数据包在协议栈中被哪些函数处理。因此利用kprobe,探查了tcp_ack(),tcp_fastretrans_alert()里面的多个函数。如果某个函数不能被kprobe,那么就需要kprobe函数调用的子程序。这些kprobe的函数通过tcp的socket和当前的PID为key的eBPF map进行关联,将调用到的函数存储到map中。在函数重传的时候,将该信息通过event发送给用户态。
针对tcp_fastretrans_alert(),将函数的输入参数以及当前tcp socket的一些字段信息进行打印,例如prior_snd_una, is_dupack ack_flag, tp->packets_out,tp->sacked_out,icsk->icsk_ca_state,tp->snd_una, tp->reordering , tp->mss_cache等信息也一并计入到map中。
运行工具后,当数据发生重传时,我们可以获取到以下三类信息,详情如图6所示:
输入数据包的信息和重传数据包的信息。
数据包的函数处理函数。
数据包的处理协议栈。

图6 抓取的数据包重传信息
根据tcp_fastretrans_alert ()的函数调用信息,以及该数据包调用到的函数,不难推测出该数据因为触发了tcp_force_fast_retransmit()而引起了重传。在tcp_force_fast_retransmit()中,会进行图7的判断:
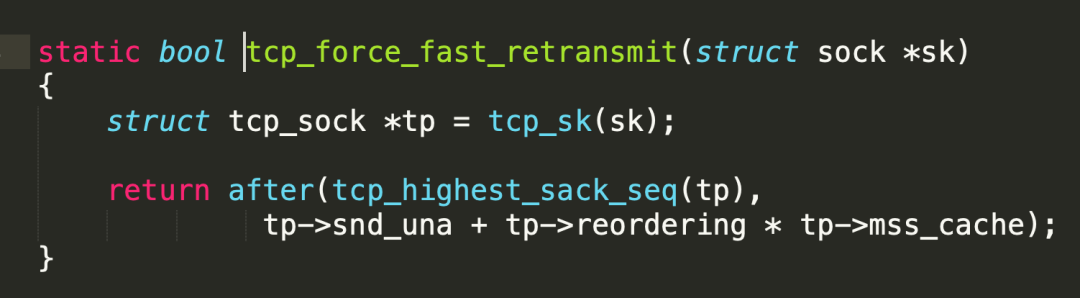
图7 tcp_force_fast_retransmit() 函数
该处判断此TCP链接的Highest sacked seq - unacknowledged seq >= reordering * MSS 是否满足条件,如果满足条件的话,则会进行重传操作。可以很明显看到,tp->reordering就是决定是否进行重传的关键因素。因此通过ss -i,查看了下所有链接的tp->reordering值,如图8所示:

图8 TCP重传的统计
在ss -i命令的输出结果中,如果tp->reordering等于默认值3,那么就不会有值打印出来,而如果tp->reordering不等于3,则会打印出来具体的值。从结果可以看出,因为链接的客户端和网络环境不同,容器环境内SLB和物理机器环境内SLB的TCP链接,相互之间的tp->reordering值差别很大。
从tcp_force_fast_retransmit的判断条件来看,tp->reordering值越高,越不容易发生重传,这也是在抓包的时候,为什么同时收到SACK数据,容器发生重传,而物理机节点不发生重传的原因。至于tcp->reodering如何更新,网络上已经有很多的分析文章,这里不再赘述。
三、解决方案
在TCP链接建立的时候,tp->reordering默认值是从/proc/sys/net/ipv4/tcp_reordering(默认值为3)获取的。之后根据网络的乱序情况,进行动态调整,最大可以增长到/proc/sys/net/ipv4/tcp_max_reordering (默认值为300)的大小。
在网卡TSO开启的情况下,会发送超过3个MSS的数据包,如果采用reordering值为3,稍微的乱序都可能导致重传,而很多的重传都是没有必要的。 因此尝试修改 /proc/sys/net/ipv4/tcp_reordering的默认值为6,以修复因为乱序而导致无谓重传的问题。 经修改后,从netstat -s的结果来看,TCPSackRecovery的统计明显降低了,因此重传率也降低了,如图9所示。
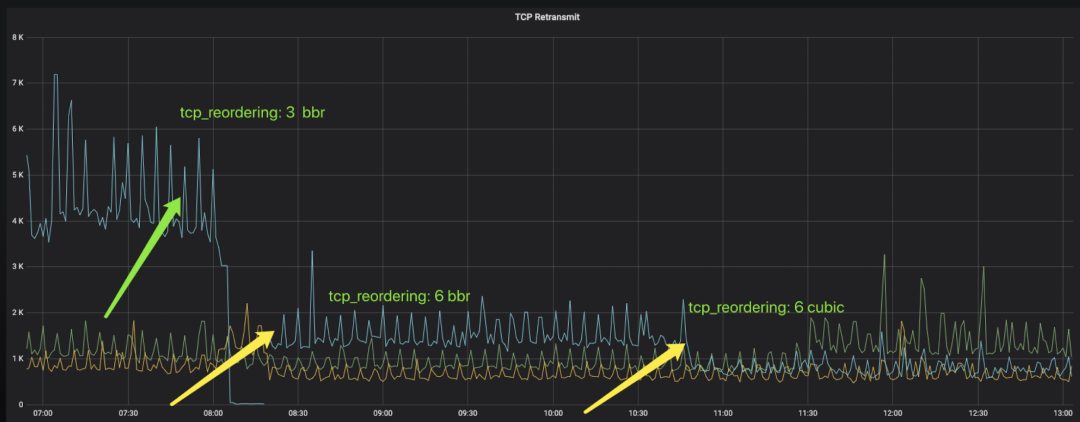
图9 tcp重传率在增大reordering值后下降
需要注意的是:
新建的network namespace的 /proc/sys/net/ipv4/tcp_reordering默认值是3,不会和host network namespace设置的值保持一致。
监听端口的socket创建后,该socket上的后续链接,都会默认使用该socket的tp->reordering作为初始值,而不会动态从/proc/sys/net/ipv4/tcp_reordering里读取,因此,该值需要在监听端口的socket创建之前进行设置。
四、网络重传篇小结
通过netstat -s显示的MIB统计是该network namespace下所有链接统计的总和。在类似SLB这种具有几万个TCP链接的场景下,还是需要像BCC这样的tcpretrans.py 工具来寻找重传率比较高的客户端,这样可以将问题收敛到某些链路上。
与丢包问题不同,重传原因在TCP内核协议栈中的MIB记录点明显偏少,因此也不容易直接通过netstat -s 显示的MIB信息来获取,而这可以通过eBPF工具来抓取内核中对数据包的处理路径进行针对性分析。除了像本案例场景的参数调优以外,内核处理路径的抓取还可以输出数据包在协议栈内的信息,也能进一步帮助我们后续定位协议栈方面的代码问题。
eBay云计算“网”事三部曲总结
网络环境作为云计算里面的重要一环,经常会发生各种各样的问题,也是用户反馈较多的问题点。本系列的三篇文章,从 网络延迟,网络丢包,网络重传 三个方面,针对网络的常见问题进行分析,均为线上真实案例。这些案例并不是我们处理过的最困难的问题,却是在网络环境中最典型的问题,因此拿来作为例子详细讲述。现在回头来看,当初定位问题的思路或方式还有很多可以改进的地方,但是认知和经验的积累从来不是一步到位的,因此定位的方法也会不断地修正和改进。
Linux内核相关的问题定位一直都是云环境中的痛点之一,需要定位人员有丰富的知识积累以及相关经验。在关于Linux内核的问题定位上,一般都是根据经验和现场猜测怀疑点,不断修改参数重试或者借助搜索引擎来解决。该方式费时费力,并且解决问题的方法方式往往不可重复和扩展。下次碰到同一模块的问题,往往还是需要重来一遍。
在意识到这样的问题后,我们希望能够借助eBPF等手段,力求将内核白盒化,尽量能够从对代码的跟踪上找出问题的原因。 该方式在刚开始的时候,可能会比较痛苦,因为需要详细了解相关问题涉及到的Linux模块实现,并针对性形成该模块问题定位的方式以及工具集合,比较耗时耗力,但是只要定位该模块的方式形成后,就会达到磨刀不误砍柴工的效果。有时候,最难走的路,往往才是捷径。
本文转载自公众号eBay技术荟(ID:eBayTechRecruiting)。
原文链接:

Java 避坑指南:Java 高手笔记代码篇
本迷你书包括 86 个业务开发中常见踩坑点。每一个知识点都相当的实用,是程序员业务开发中的必备避坑指南...











评论