

本文是 InfoQ“解读 2019”年终技术盘点系列文章之一。
自 Google 在 2018 年推出预训练语言模型 BERT,在 11 项 NLP 任务上达到最高水平,预训练语言模型的研究与应用成为学术界和工业界广泛关注的重点,被认为开启了自然语言处理的新篇章。在 2019 年各大公司和高校陆续发布了自己的预训练语言模型,如:Facebook 发布的 RoBERTa,CMU 发布的 XLNet,Stanford 发布的 ELECTRA,还有百度的 ERNIE 模型等,不断刷新自然语言理解任务的最高表现,并且在细粒度舆情分析,序列化推荐等不同场景下展现了巨大的应用价值。本文着重对预训练语言模型的重要意义,当前的发展,包括模型,训练方法等进行了总结、回顾与探讨,也欢迎同行业的学者,专家交流指正。
预训练语言模型简介
语言模型的任务是根据一个句子里的已知词预测句子里的未知词,在自动填充(如:在电子邮件书写过程中的自动补全),机器翻译,语音识别等方向有着广泛的应用,传统的语言模型包括 n-gram,HMM 等。在 2003 年 Joshua Bengio 首次提出使用神经网络来建模语言模型,由于近期一系列有影响力的预训练语言模型的工作都是基于神经网络的,本章节将重点关注神经语言模型。
神经语言模型不仅提供了强大的建模语言模型的工具,同时,也提供了词,句子以及文本的向量表示。2013 年诞生了被大家广泛使用的 Word2Vec,利用语言模型作为训练任务,得到词的向量表示,这里每个词的向量表示是固定的,与上下文无关,例如:“bank”的词向量表示在“bank of China”和“river bank”这两个不同的上下文里面都是一样的。2017 年 ELMo 利用双向 LSTM 获取了一个基于上下文的词向量表示(contextualized word embedding),使得每个词的向量表示包含了上下文的语义信息,例如前面的例子里面,“bank”一词在使用 ELMo 得到的 embedding 在不同的上下文是不一样的。此后的一系列工作都采用了基于上下文的词向量表示。
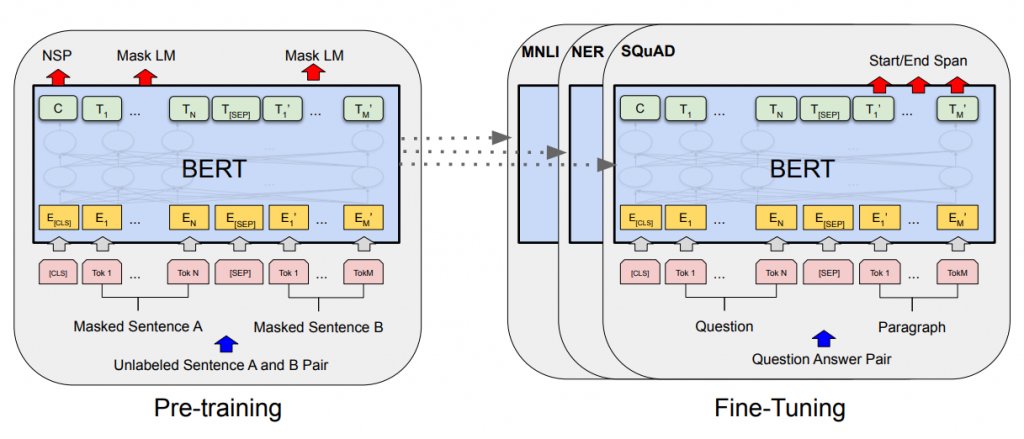
一个革命性的工作是 2018 年诞生的 BERT,该工作将 Transformer 的架构引入了预训练语言模型,并开启了 Pretraining-Finetuning 的框架。该框架在预训练阶段基于大规模无监督语料进行两个预训练任务,分别是词级别和句子级别的,一个是 MLM(Masked Language Modeling),另外一个是 NSP(Next Sentence Prediction),MLM 是从一个部分被 Mask 的句子恢复这些被 Mask 掉的确实词,NSP 是判断一个句对是不是上下句,从而获取基于上下文的词和句子的表示。在 Finetune 阶段,针对具体的下游任务,BERT 会微调中间层参数以调整词的 Embedding 以及调整预测层的参数,成功的将预训练学到的词和句子的表示迁移到下游任务中,实现了对低资源任务的有效支撑。
预训练语言模型的发展现状
由于 BERT 取得的巨大成功,2019 年在预训练语言模型方面涌现了一大批有效,实用并且带给人来启发的工作。由于篇幅有限,本文未能列举所有工作,只会挑选一些来阐述。下面在模型,预训练任务和算法三个维度进行总结。
模型方面
模型方面主要有以下几个方面的改进。
位置信息编码方式。BERT 的网络架构是一个多层的 Transformer 网络,由于 Transformer 并没有直接考虑输入的 token 的位置信息,原始的 Transformer 模型和 BERT 分别采用了函数式和参数式的绝对位置编码方式,即每一个位置上输入的 token 会叠加一个与位置信息相关的一个 embedding(这个 embedding 称为绝对位置编码:absolute position embedding,APE),前者的位置编码是一个与位置相关的函数,后者则是模型参数的一部分,在预训练过程中学到的。此后,CMU 和 Google 提出的 Transformer-XL 和 XLNet 提出了相对位置编码方式,即在每一层计算隐状态的相互依赖的时候考虑它们之间的相对位置关系,这个相对位置信息表示为一个相对位置编码(relative position embedding,RPE),这两个工作均在相对位置编码中加入了可学习的参数。此后,华为发布的 NEZHA 模型使用了完全函数式的相对位置编码(相对位置编码没有任何需要学习的参数),实验结果表明该位置编码方式使得模型在各个下游任务上的效果均得到明显提升。
词表 embedding 矩阵的分解与中间层的层共享。 Google 发布的 ALBERT 针对词表 embedding 矩阵进行了矩阵分解,将原先的大小为 VH 的词表 embedding 矩阵分解为两个大小分别为 VE 和 E*H 的 low-rank 矩阵相乘的形式,其中 V,H 分别为词表大小以及模型隐状态维度,E 则是远小于 V 和 H 的值,因而这个方法有效的减少了词表 embedding 的参数。同时,该模型采用了层共享技术,并尝试了共享中间层多头注意力或者是 Feed Forward Network 的参数。实验证明该方法在显著少于原始 BERT 参数量的前提下在多个下游任务上大大超越了 BERT。
预训练任务方面
在词级别的训练任务方面,一个为大家广泛使用且证明有效的方法是全词 Mask 技术。不同于原始的 BERT 模型 Mask 单个 Token,该技术在 MLM 预训练任务中 Mask 整个词而不是单个 Token(如下图全词 Mask 方法 Mask 了一整个词“大兴”),进而提升了任务难度使得 BERT 学到更多语义信息。此任务在 Google 发布的英文 BERT 的训练以及哈工大和科大讯飞联合发布的中文 BERT 模型以及华为发布的 NEZHA 模型中得到了应用。

百度发布的 ERNIE 模型在词法,句法以及语义方面分别引入了若干任务。词法方面,百度 ERNIE 采用了 Knowledge Masking 的方法,即 MLM 预训练任务中 Mask 若干实体。句法方面,其采用了句子重排序以及句子距离计算的任务。语义方面,百度 ERNIE 使用了大量来自搜索引擎的数据,采取了信息检索相关的任务。
CMU 和 Google 联合发布的 XLNet 框架统一了预训练语言模型的 Autoencoder 和 Auto-regressive 两种框架。预训练阶段,一改原始 BERT 通过引入[MASK]字符来恢复缺失词,XLNet 则是通过 Auto-regressive 的方式,逐个生成一个句子中的缺失词。这样的方式使得预训练和 Finetune 阶段都不需要引入[MASK]字符,解决了原始 BERT 的预训练和 Finetune 不一致(discrepancy)的问题(原始 BERT 的预训练语料中包含[MASK]字符而 Finetune 则不包含)。与此同时,Auto-regressive 的生成方式也使得生成词之间具有一定的依赖,后生成的词会依赖之前生成的词,解决了原始 BERT 中各个缺失词互相之间独立生成的问题。此外,训练过程中,XLNet 还将一个句子的缺失词进行了多次不同顺序的生成,充分利用了语料的语义信息。
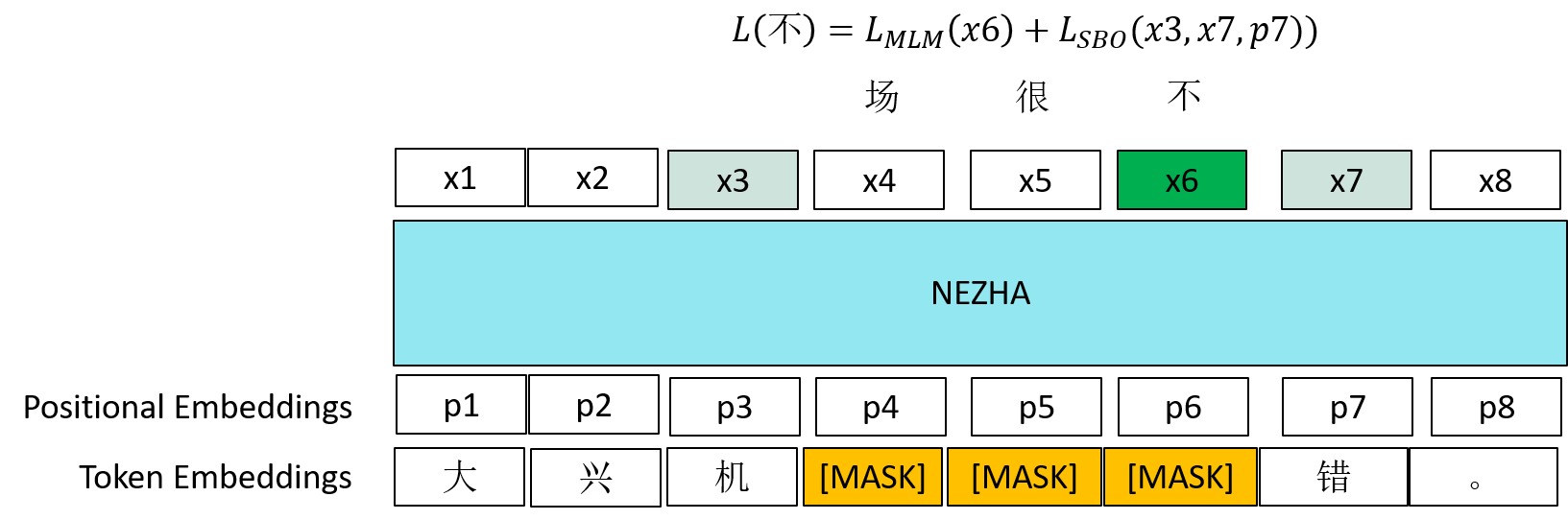
华盛顿大学和 Facebook 联合发布的 SpanBERT 模型还引入了 Span 预测任务,该任务 Mask 一个连续的 Span(例如下图中“场”,“很”,“不”三个字),利用 Span 前后的两个字的最上层表示(下图中的 x3 和 x7)以及待预测字的位置信息来预测该字,如下图中,待预测字为“不”,Span 预测任务会使用 x3,x7 和“不”这个字的位置信息(就是 x3 和 x6 还有 p7,即“不”这个字的绝对位置编码)来预测该字,“场”和“很”的预测也是同样的方法。该方法使得 Span 前后的字的表示会包含 Span 中字的语义信息,由于在训练过程中,一个句子会被随机 Mask 很多次,所以句子中每个字都有机会成为 Span 的前后字,进而使得各个字学到的表示都会包含周围 Span 的信息,Span 预测任务能够有效提高模型在下游的 Span 抽取任务(此任务的目标是获取一段文字中目标片段的开始和结束位置)的效果。
斯坦福大学提出的 ELECTRA 模型采用了生成对抗式的方法训练模型。生成器采用了 BERT 模型,即一个 Denoising Autoencoder,恢复一个句子中被 Mask 的词,由于 BERT 不可能达到 100%的复原,被恢复的词有一些是原句中的原词,有一些则被替换成了别的词。辨别器也是一个多层的 Transformer 网络,其训练任务是辨别生成器输出的句子中哪些词是原词,哪些是被替换的。在 ELECTRA 中,最终保留的是辨别器,由于预训练阶段,在生成器中,各个句子中的每一个词的表示都被使用来进行一个二分类任务(即是否是原词),相比原始的 BERT(只有 15%不到的词的表示被拿来做预测),ELECTRA 的 sample 的利用率非常之高,进而收敛很快,在相同的 FLOPS 的情况下,性能优于 BERT,ROBERTa 等同样规模的预训练语言模型。
训练算法
在训练算法方面,当前有两个广泛使用的方法。
第一个在训练过程中变量的精度方面做了优化,此方法被称为混合精度训练(Mixed Precision Training),在传统的深度学习训练过程中,所有的变量包括 weight,activation 和 gradient 都是用 FP32(单精度浮点数)来表示。而在混合精度训练过程中,每一个 step 会为模型的所有 weight 维护一个 FP32 的 copy,称为 Master Weights,在做前向和后向传播过程中,Master Weights 会转换成 FP16(半精度浮点数)格式,权重,激活函数和梯度都是用 FP16 进行表示,最后梯度会转换成 FP32 格式去更新 Master Weights。
第二个主要是优化算法方面的,此优化算法被称为 LAMB 优化器,通常在深度神经网络训练的 Batch Size 很大的情况下(超过一定阈值)会给模型的泛化能力带来负面影响。而 LAMB 优化器通过一个自适应式的方式为每个参数调整 learning rate,能够在 Batch Size 很大的情况下不损失模型的效果,使得模型训练能够采用很大的 Batch Size,进而极大提高训练速度。在训练 BERT 的研究中,使用 LAMB 优化器在不损失模型效果的前提下,Batch Size 达到了超过 30k,使得 BERT 的训练时间从 3 天降到了 76 分钟。
总结与展望
预训练语言模型在大规模无监督文本上进行预训练,将得到的词和句子的表示成功迁移到广泛的下游任务上,并取得了巨大成功,尤其对于低资源场景。2019 年涌现出的一大批在预训练语言模型的探索工作主要围绕在预训练任务方面,通过设计任务使模型学到更加丰富有效的语义信息。
在未来,笔者认为预训练语言模型还有着巨大的发展空间。
笔者认为模型方面的发展方向有两条线:1,模型效果方面,根据 XLNet 的实验,我们看到当前即使 large 量级的模型还只能 underfit 海量的数据,因此,模型方面就效果而言还有很大的改进空间;2,训练效率方面,当前的训练各个预训练语言模型在几十块 GPU 的算力下还是需要若干天,算力和资金消耗巨大,如何巧妙设计模型,降低冗余的计算也是一个重要问题。
此外,2019 年的大部分工作是基于 BERT 做了很多尝试性的工作,比如:函数式相对位置编码方面,经过尝试发现效果好,但似乎缺少针对性,笔者认为这是在模型的理论方面可解释性不够造成的,我们很难理解 Transformer 架构到底有什么欠缺,到底哪里学不好,每一部分到底起到什么作用,因而很难有针对性的改进方案。现有的解释性工作大多集中在解释预训练语言模型的功能,如:学到的词表示是否能够做词法和句法分析等,原理性的解释比较少,北京大学提出的 MacaronNET 是一个很好的原理方面的解释性工作,用偏微分方程解释 Transformer 的工作原理,从数学的角度准确定量地阐释了 Transformer 的机制,不过确实需要很强的数学功底才能吃透,2020 期待更多这方面的工作。
作者介绍
魏俊秋博士,华为高级技术专家,华为诺亚方舟实验室语音语义组的研究员,博士毕业于香港科技大学计算机系,本科毕业于南京大学。长期从事时空数据分析、主题模型、预训练语言模型的研究,在国际顶级会议和期刊,如:SIGMOD、TKDE、ICDM、TKDD 发表论文数篇,并曾在国际知名会议,如:COLING、BIG DATA、BiGComp、PAKDD 担任程序委员会委员。

InfoQ高级技术编辑

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论