
作者|赵赛铜,OceanBase 高级开发工程师。目前在 OceanBase 存储-分析处理组,工作方向是存储结构和分析处理功能的维护与开发。
“数据是二十一世纪的石油”,这个观点正在逐渐成为现实,现在我们有各种各样的 IT 系统不断地生产着数据,这些数据累积起来为我们的生产生活带来了很多便利。但在挖掘这些数据价值的同时,大量数据的存储与计算也带来了巨大的成本,降本增效也成为了很多 IT 系统设计的重点。
历史库的需求与挑战——降本增效
在订单、交易、日志等业务场景中,数据总量会不断增加。而对于这些数据的访问往往和时间有很强的相关性,通常与当前时间越接近的数据越“热”,也就是说,这些数据可能会被频繁地修改与点查。热数据的访问更多是事务型负载和实时分析负载,其数据量在整个系统中的占比相对较低。而在系统中已经存在了一段时间的数据,被称为冷数据,这些数据的被查询次数相对没有那么频繁,也很少被修改。冷数据的访问通常是少量的事务型负载和一些 ad-hoc 或报表统计等分析型负载,而且冷数据通常是稳定运行的 IT 系统中数据量的主要部分。
由于冷热数据有着明显的区别,将它们放在一套相同规格的环境中同等处理显然会浪费系统的资源,单个数据库的容量上限还可能会限制数据的存储。但是,将冷数据定期归档到更经济的存储介质中,访问数据时采用从归档数据中还原的方法,又会对历史数据的查询性能和系统的复杂度带来负面影响。因此,将数据分为线上库和历史库,将在线数据定期同步到历史库中的做法成为了越来越多系统的解决方案,通过在存储和计算成本更低的环境上部署历史库来降低成本和满足业务需求。
历史库这种模式的出现也对数据库管理系统带来了新的需求,通常一个历史库希望数据库能够:
拥有大容量的存储空间,即能够支持大量数据的存储和在线库数据高效的持续导入;
提供更低的存储成本,即能够用更少的磁盘空间,更经济的存储介质存储更多的数据;
提供和在线库近似的查询性能,即支持高效的少量事务型查询,同时能够支持高效的分析型查询;
支持低频率的历史数据更新;
对应用和在线库保持相同的访问接口,降低应用复杂度。
面对这些需求,拥有良好的单机分布式扩展能力,支持 HTAP 混合负载处理能力的 OceanBase 数据库能够同时高效地支持业务系统的在线库和历史库场景。更为关键的是, OceanBase 可以在支持业务的同时至少降低一半的存储成本,部分客户反馈,业务历史库从其他数据库迁移至 OceanBase 后,存储成本降低 80% 左右,这也是许多用户在历史库场景选择 OceanBase 的原因之一。其中的核心技术,就是 OceanBase 的 LSM-tree 存储引擎和数据库压缩功能。本文会为大家分享 OceanBase 在降本增效的重要功能-数据库压缩上的设计与思考,来探讨存储引擎怎样通过数据压缩更好地支持历史库场景。
解决历史库需求的核心技术——数据编码与压缩
数据压缩是数据密集型应用中常用的方法,将数据处理后变换成占用更小空间的格式,来降低存储与传输数据的成本,是一种用压缩和解压的手段,以计算时间换存储空间。
在现代计算机存储的层次架构中,与 CPU Cache 和内存相比,硬盘通常有着更低的带宽与更高的查询时延。尽管现在 SSD 、 DMA 等硬件技术对 I / O 进行了优化,硬盘的访问效率仍然和内存等设备不在同一个数量级,而通过压缩可以在相同的 I / O 带宽上支持更多数据的读写。因此,对数据进行压缩不仅可以降低存储的成本,还可以降低 I / O 的压力,压缩过的数据也使得访问数据路径上的各级 cache 都能有相对更高的命中率。
而压缩数据的过程实际上就是去除数据中的冗余,更高效地表达数据信息的过程。因此,不同场景下的数据特征与访问需求也为数据压缩提供了更多的可能。例如,音视频数据都有特定的有损压缩算法,对连续的数值数据和文本数据分别有更高效的压缩方法。而对于数据库,尤其是关系型数据库,存储的数据会受到 schema 、类型、值域等限制,相似度会比较高,这些特征使数据可以被更好地编码与压缩。
不同数据库产品的数据压缩技术
目前数据库产品或多或少都提供了数据压缩功能,但由于存储引擎架构和数据库应用场景的不同,产品之间的数据库压缩设计和能力也会产生差别。通常,压缩率越高的压缩算法,压缩和解压数据的 overhead 就越大,因此各种产品在设计压缩功能时都会在成本和性能之间进行权衡, OceanBase 也根据自己的架构特点设计了数据的压缩方法。
1、事务型数据库的数据压缩技术
通常针对事务型负载设计的数据库需要在平衡压缩率和性能上做出更多的努力。面向 OLTP 场景的数据库要对频繁随机写入和更新场景支持更高的 TPS ,通常会使用基于行存和 B+ 树结构的存储引擎,因此对于数据的压缩会相对保守。这种存储引擎通常会将定长的内存数据页映射到持久化数据块来管理,而且有些情况下将更新数据同步写到数据块中,会导致对页内少量行进行 DML 操作可能需要对整个数据页进行重新压缩,在读写路径上带来更多的 overhead 。而且定长数据块在进行压缩前难以确定压缩后的数据块大小,也会带来一些空间浪费等问题。
典型的例子如 MySQL ,数据写入需要更新 redo log 和内存中的数据页,然后在触发页分裂或交换时把内存中的脏数据页刷到持久化存储中。在 MySQL 的早期版本中,一个数据页在 buffer pool 中可能同时存在压缩和未压缩两份数据,分别用于读数据和更新数据后重新压缩刷脏页,开启压缩功能的表会出现明显的性能下降。在 MySQL 5.7 版本后,通过文件系统的空洞能力实现了透明压缩( TPC ),将内存页面压缩后按照原大小刷到文件系统中,以文件系统的块大小为粒度发现并复用数据块中的空洞。这样的方法相对旧版本更灵活,压缩和解压性能相对更好,但没有解决存储空间的浪费和文件系统碎片等问题。由于存储引擎中开启压缩带来的不可避免的性能损失, MySQL 和 Oracle 都提醒开发者谨慎使用透明压缩、 OLTP 压缩等特性。
2、分析型数据库的数据压缩技术
分析型负载的数据库需要批量处理大量数据,通常对数据压缩会有更高的要求。因为面向 OLAP 场景的数据仓库等系统的数据通常是批量导入的,增量数据相对较少,所以分析型数据库通常使用列存、增量数据写日志,定期重整基线数据的存储引擎。这种存储引擎中数据压缩发生在批量导入和后台数据重整时,可以采用相对激进的压缩策略。例如,以更大的数据块为单位进行压缩,将更多数据压缩到同一个数据块中,将同一列的数据存储在相邻的数据中,并针对这一列数据的特征对数据进行压缩率更高的编码。
处理各种特定负载的数据库也会根据自己的数据结构对数据进行更高效的编码。如 ClickHouse , Redshift 等数据仓库中都对整形数据设计了特殊的编码方式;搜索引擎也对单调递增的整形序列的编码与扫描进行了深入的优化;时序数据库 Gorilla 中提出的 Gorilla 编码知名度甚至超过了这个数据库本身。很多分析型数据库还会根据自己的查询负载对数据编码进行设计,来优化自己的查询性能。传统的数据仓库能够通过列存和编码提供较好的数据压缩能力,对特定的分析型查询负载也有更好的表现,但往往难以支持高效的数据更新。
3、 OceanBase 的数据压缩技术
作为一款 HTAP 数据库产品, OceanBase 使用基于 LSM-Tree 架构的存储引擎,同时支持 OLTP 与 OLAP 负载,这种存储架构提供了优秀的数据压缩能力。在 OceanBase 中,增量数据会写入 clog 和 memtable 中, OceanBase 的 memtable 是内存中的 B+ 树索引,提供高效的事务处理能力。 memtable 会定期通过 compaction 生成硬盘持久化数据 sstable ,多层 sstable 会采用 leveled compaction 策略进行增量数据重整。sstable 中数据块的存储分为两层,其中 2M 定长的数据块(宏块)作为 sstable 写入 I / O 的最小单元,存储在宏块中的变长数据块(微块)作为数据块压缩和读 I / O 的最小单元。
在这样的存储架构下, OceanBase 的数据压缩集中发生在 compaction 过程中 sstable 的写入时,数据的在线更新与压缩得到了解耦。批量落盘的特性使其采用更激进的压缩策略。OceanBase 从 2.0 版本开始引入了行列混存的微块存储格式( PAX ),充分利用了同一列数据的局部性和类型特征,在微块内部对一组行以列存的方式存储,并针对数据特征按列进行编码。变长的数据块和连续批量压缩的数据也可以让 OceanBase 通过同一个 sstable 中已经完成压缩的数据块的先验知识,对下一个数据块的压缩进行指导,在数据块中压缩尽量多的数据行,并选择更优的编码算法。
与部分在 schema 上指定数据编码的数据库实现不同, OceanBase 选择了用户不感知的数据自适应编码,在给用户带来更小负担的同时降低了存储成本,从历史库角度而言,用户也不需要针对历史库数据做出过多压缩与编码相关的配置调整。 OceanBase 之所以能够在事务性能和压缩率之间取得更好的平衡,都得益于 LSM-Tree 的存储架构。
当然, LSM-Tree 架构不是解决数据库压缩所有问题的银弹,如何通过数据压缩降低成本、提升性能是业界一直在讨论的话题。对 B+ 树类的存储引擎进行更高效的压缩也有很多探索,比如基于可计算存储硬件的工作,利用存储硬件内部的透明压缩能力对 B+ 树类存储引擎的数据压缩进行优化,使其写放大达到了接近 LSM-Tree 架构存储引擎的效果。但 LSM-tree 中内存数据页更新与数据块落盘解耦,和 sstable 数据紧凑排布的特点,使得 LSM-tree 相对 B+ 树类存储引擎,仍然更适合在对查询/更新带来更少负面影响的前提下实现更高效的数据压缩。
OceanBase 的数据库压缩技术
OceanBase 同时支持不感知数据特征的通用压缩 ( compression ) 和感知数据特征并按列进行压缩的数据编码 ( encoding )。这两种压缩方式是正交的,也就是说,可以对一个数据块先进行编码,然后再进行通用压缩,来实现更高的压缩率。
OceanBase 中的通用压缩是在不感知微块内部数据格式的前提下,将整个微块通过通用压缩算法进行压缩,依赖通用压缩算法来检测并消除微块中的数据冗余。目前 OceanBase 支持用户选择 zlib 、 snappy 、 zstd 、 lz4 算法进行通用压缩。用户可以根据表的应用场景,通过 DDL 对指定表的通用压缩算法进行配置和变更。
由于通用压缩后的数据块在读取进行扫描前需要对整个微块进行解压,会消耗一定 CPU 并带来 overhead。为了降低解压数据块对于查询性能的影响, OceanBase 将解压数据的动作交给异步 I / O 线程来进行,并按需将解压后的数据块放在 block cache 中。这样结合查询时对预读 ( prefetching ) 技术的应用,可以为查询处理线程提供数据块的流水线,消除解压带来的额外开销。
通用压缩的优点是对被压缩的数据没有任何假设,任何数据都可能找到模式并压缩,但往往出于平衡压缩性能和压缩率的考虑,通用压缩算法会放弃对一些复杂数据冗余模式的探测和压缩。对于关系型数据库来说,系统对数据库内存储的结构化数据有着更多的先验知识,利用这些先验知识可以对数据进行更高效的压缩。
OceanBase 的数据编码算法
上文提到在关系型数据库中,由于 schema 和数据类型的限制,同一列的数据类型、精度、值域往往相同。而且在实际应用中,同一列中相邻的数据也通常会有自己的特征,如下面两个场景。
当通过一列数据存储城市、性别、产品分类等具有类型属性的值时,这些列数据块内部数据的基数( cardinality )也会比较小,这时数据库可以直接在用户数据字段上建立字典,来实现更高的压缩率;
当数据按时序插入数据库,这些插入的数据行中的时间相关字段、自增序列等数据的值域会相对较小,也会有单调递增等特性,利用这些特性,数据库可以更方便地为这些数据做 bit-packing 、差值等编码。
为了实现更高的压缩比,帮助用户大幅降低存储成本, OceanBase 设计了多种编码算法,最终在 OceanBase 的负载上实现了很好的压缩效果。 OceanBase 根据实际业务场景需求实现了单列数据的 bit-packing 编码、字符串 HEX 编码、字典编码、 RLE 编码、常量编码、数值差值编码、定长字符串差值编码,同时,创新地引入了列间等值编码和列间子串编码,能够分别对数据库中一列数据或几列数据间可能产生的不同类型数据冗余进行压缩。
1、降低存储的位宽:Bit-packing 和 HEX 编码
Bit-packing 和 HEX 编码类似,都是在压缩数据的基数较小时,通过更小位宽的编码来表示原数据。而且这两种编码可以与其他编码叠加,对于其他编码产生的数值或字符串数据,都可以再通过 bit-packing 或 HEX 编码进一步去除冗余。
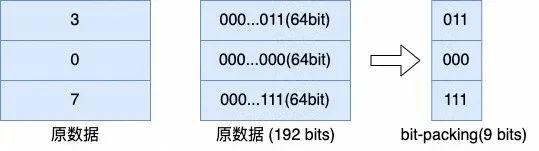
(bit-packing)
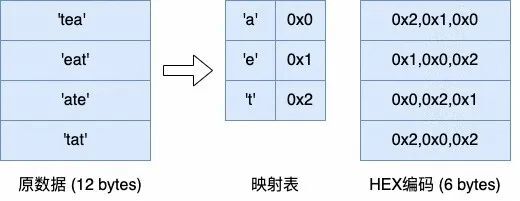
( HEX 编码)
2、单列数据去重:字典编码和 RLE 编码等
字典编码则可以通过在数据块内建立字典,来对低基数的数据进行压缩。当低基数的数据在微块内的分布符合对应的特征时,也可以使用游程编码/常量编码等方法进行进一步的压缩。
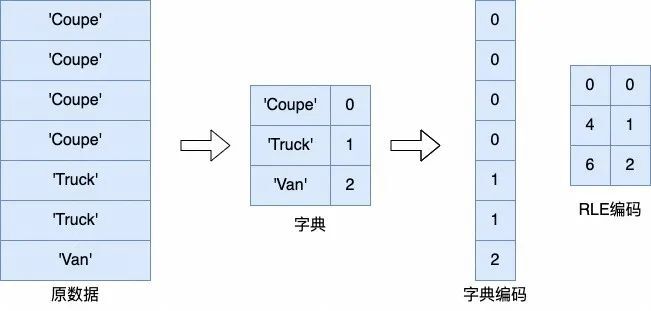
(字典编码/RLE 编码)
3、利用数据的值域压缩:差值编码等
差值编码也是常用的编码方法, OceanBase 中的差值编码分为数值差值编码和定长字符串差值编码。数值差值编码主要用来对值域较小的数值类数据类型进行压缩。对于日期、时间戳等数据,或其他临近数据差值较小的数值类数据,可以只存储最小值,每行存储原数据与最小值的差值。定长字符串编码则可以比较好地对人工生成的 ID,如订单号/身份证号、url 等有一定模式的字符串进行压缩,对一个微块的数据存储一个模式串,每行额外存储与模式串不同的子串差值,来达到更好的压缩效果。
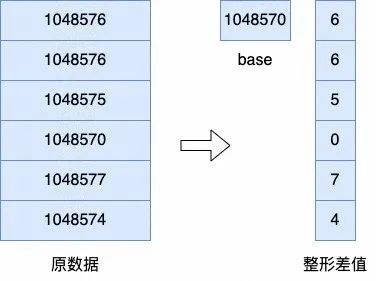
(整形差值)

(字符串差值)
4、减小多列数据冗余:列间编码
为了利用不同列间数据的相似性增强压缩效果,OceanBase 引入了列间编码。通常情况下,列存数据库只会对数据在列内部进行编码,但在实际应用中有很多表除了同一列数据之间存在相似性,不同列的数据之间也可能有一定的关系,利用这种关系可以通过一列数据表示另外一列数据的部分信息。
列间编码可以对复合列、系统生成的数据做出更好的压缩,也能够降低在数据表设计范式上的问题导致的数据冗余。
5、自适应压缩技术:让数据库选择编码算法
数据编码的压缩效果不仅与表的 schema 相关,同时还与数据的分布,微块内数据值域等数据本身的特征相关,这也就意味着比较难以在用户设计表数据模型时指定列编码来实现最好的压缩效果。为了减轻用户的使用负担,也为了实现更好的压缩效果,OceanBase 支持在合并过程中分析数据类型、值域、NDV 等特征,结合 compaction 任务中上一个微块对应列选择的编码算法和压缩率自适应地探测合适的编码,对同一列在不同数据块中支持使用不同的算法来进行编码,也保证了选择编码算法的开销在可接受的区间内。
如何降低数据编码对查询性能的影响
为了能够更好地平衡压缩效果和查询的性能,我们在设计数据编码格式时也考虑到了对查询性能带来的影响。
1、行级粒度数据随机访问
通用压缩中如果要访问一个压缩块中的一部分数据通常需要将整个数据块解压后访问,某些分析型系统的数据编码大多面向扫描的场景,点查的场景比较少,因此采用了在访问某一行数据时需要对相邻数据行或数据块内读取行之前所有行进行解码计算的数据编码的格式(如 PFor 等差值编码)。
OceanBase 需要更好地支持事务型负载,就意味着要支持相对更高效的点查,因此 OceanBase 在设计数据编码格式时保证了编码后的数据是可以以行为粒度随机访问的。也就是在对某一行进行点查时只需要对这一行相关的元数据进行访问并解码,减小了随机点查时的计算放大。同时对于编码格式的微块,解码数据所需要的所有元数据都存储在微块内,让数据微块有自解释的能力,也在解码时提供了更好的内存局部性。
2、缓存解码器
在 OceanBase 目前的数据解码实现中,每一列数据都需要初始化一个解码器对象来解析数据,构造解码器时会需要进行一些计算和内存分配,为了进一步减小访问编码数据时的 RT ,OceanBase 会将数据的解码器和数据块一起缓存在 block cache 中,访问 cache 中数据块时可以直接通过缓存的解码器解析数据。当不能命中 block cache 中缓存的解码器时,OceanBase 还会为解码器用到的元数据内存和对象构建缓存池,在不同查询间复用这些内存和对象。
通过上述细节上的优化,行列混存格式的 sstable 编码数据也可以很好地支持事务型负载。而且由于编码数据行列混存的格式,使得在分析型查询的处理上,编码数据有着和列存数据相似的特性,数据分布更紧凑,对 CPU cache 更加友好。这些特性使列存常用的优化手段也能应用于分析型查询优化中,充分利用 SIMD 等方法来提供更高效的分析型负载处理。
3、计算下推
由于编码数据中会存储有序字典、 null bitmap 、常量等可以描述数据分布的元数据,在扫描数据时可以利用这些数据对于部分过滤,聚合算子的执行过程进行优化,实现在未解码的数据上直接进行计算。 OceanBase 在 3.2 版本中对分析处理能力进行了大幅的优化,其中包括聚合与过滤计算下推到存储层执行,和在向量化引擎中利用编码数据的列存特征进行向量化的批量解码等特性。在查询时充分利用了编码元数据和编码数据列存储的局部性,在编码数据上直接进行计算,大幅提高了下推算子的执行效率和向量化引擎中的数据解码效率。基于数据编码的计算下推和向量化解码也成为了支持 OceanBase 高效处理分析型负载,在 TPC-H benchmark 中达到优秀性能指标的重要功能。
数据编码压缩的基础测试
不同的压缩方式如何影响 OceanBase 的压缩效果,以下通过一个简单的测试进行观察。
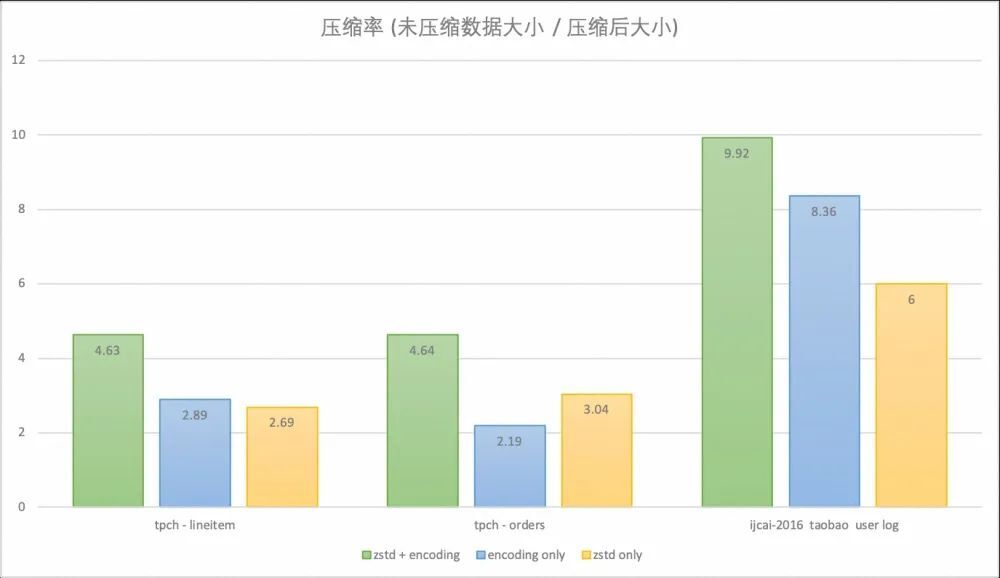
使用 OceanBase 4.0 版本分别在交易场景的 TPC-H 10g 的数据模型和用户行为日志场景的 IJCAI-16 Brick-and-Mortar Store Recommendation Dataset 数据集上对 OceanBase 的压缩率进行测试:
TPC-H 是对订单,交易场景的建模,对 TPC-H 模型中数据量比较大的两张表,即存储订单的 ORDERS 表和存储商品信息的 LINEITEM 表的压缩率进行统计。在 OceanBase 默认配置( zstd + encoding )下,这两张表的压缩率可以达到 4.6 左右,相较只开启 encoding 或 zstd 压缩时提升明显。
IJCAI-16 taobao user log 则是淘宝脱敏后的真实业务数据,存储了用户浏览商品时的行为日志。在 OceanBase 默认配置( zstd + encoding )下压缩率可以达到 9.9 ,只开启 encoding 压缩率可以达到 8.3 ,只开启 zstd 压缩率为 6.0 。
可以看到 OceanBase 在面对数据更有规律的业务数据时会有更出色的数据压缩效果,在 TPC-H 这种数据冗余相对更少的数据集上也有着优秀的数据压缩能力。
写在最后
OceanBase 存储引擎的数据库压缩功能在设计上希望能够在用户少感知、不感知存储格式的前提下,在不降低事务型负载性能的同时降低存储空间和存储成本,同时提升分析型负载的性能。这样的设计与历史库的设计不谋而合。高度压缩的数据既能够帮助历史库数据降低至少 50% 的存储成本,高效的写入查询和统一的配置接口又能够帮助业务增效。
对于历史库数据同步的需求, OceanBase 的 LSM-Tree 存储引擎天生具有高效的写入性能,既能够通过旁路导入高效处理定期的批量数据同步,又能够承载一些实时数据同步和历史库数据修改的场景。
对于历史库数据的定期跑批报表,和一些 ad-hoc 的分析型查询带来的大量数据扫描的需求,因为历史库中增量数据较少,所以绝大多数数据都存储在基线的 SSTable 中,这时计算下推可以只扫描基线数据,绕过了 LSM-Tree 架构常见的读放大问题。而且支持在压缩数据上执行下推算子和向量化解码的压缩格式可以轻松地处理大量数据查询和计算。
对于大量历史数据存储的需求, OceanBase 的 SSTable 存储格式和数据编码压缩功能可以使 OceanBase 更轻松地支持超大容量的数据存储。而且高度压缩的数据和在同等硬件下更高效的查询性能也能够大幅度降低存储和计算的成本。
此外,企业可以选择将历史库所在的集群部署在更经济的硬件上,但是对数据库进行运维基本不需要感知数据编码与压缩的相关配置,应用开发也可以做到在线库和历史库使用完全相同的访问接口,简化应用代码和架构。
这些特点让越来越多的企业开始在历史库场景使用 OceanBase 进行降本增效的实践。OceanBase 也不断在存储架构,降本增效方面做出更多的探索。




