

百度前首席科学家、斯坦福大学副教授吴恩达(Andrew Ng)曾经说过:迁移学习将是继监督学习之后的下一个促使机器学习成功商业化的驱动力。本文选自《深度学习 500 问:AI 工程师面试宝典》,将重点介绍目前最热门的深度迁移学习方法的基本思路。
随着迁移学习方法的大行其道,越来越多的研究人员开始使用深度神经网络进行迁移学习。与传统的非深度迁移学习方法相比,深度迁移学习直接提升了在不同任务上的学习效果,并且由于深度迁移学习直接对原始数据进行学习,所以它与非深度迁移学习方法相比有两个优势。
(1)能够自动化地提取更具表现力的特征。
(2)满足了实际应用中的端到端(End-to-End)需求。
近年来,以生成对抗网络(Generative Adversarial Nets,GAN)为代表的对抗学习也吸引了很多研究者的目光,基于 GAN 的各种变体网络不断涌现。对抗学习网络与传统的深度神经网络相比,极大地提升了学习效果。因此,基于对抗网络的迁移学习也是一个热门的研究点。

上图为深度迁移学习方法与非深度迁移学习方法的结果对比,展示了近几年的一些代表性方法在相同数据集上的表现。从图中的结果可以看出,与传统的非深度迁移学习方法(TCA、GFK 等)相比,深度迁移学习方法(BA、DDC、DAN)在精度上具有显著的优势。
下面我们来重点介绍深度迁移学习方法的基本思路。
首先来回答一个最基本的问题:为什么深度网络是可迁移的?然后,介绍最简单的深度网络迁移形式——微调。接着分别介绍使用深度网络和深度对抗网络进行迁移学习的基本思路和核心方法。
1、深度网络的可迁移性
随着 AlexNet 在 2012 年的 ImageNet 大赛上获得冠军,深度学习开始在机器学习的研究和应用领域大放异彩。尽管取得了很好的结果,但是神经网络本身解释性不好。神经网络具有良好的层次结构,很自然地就有人开始思考能否通过这些层次结构来很好地解释网络。于是,就有了我们熟知的例子:假设一个网络要识别一只猫,那么一开始它只能检测到一些边边角角的东西,和猫根本没有关系;然后可能会检测到一些线条和圆形;慢慢地,可以检测到猫所在的区域;接着是猫腿、猫脸等。
下图是深度神经网络进行特征提取分类的简单示例。
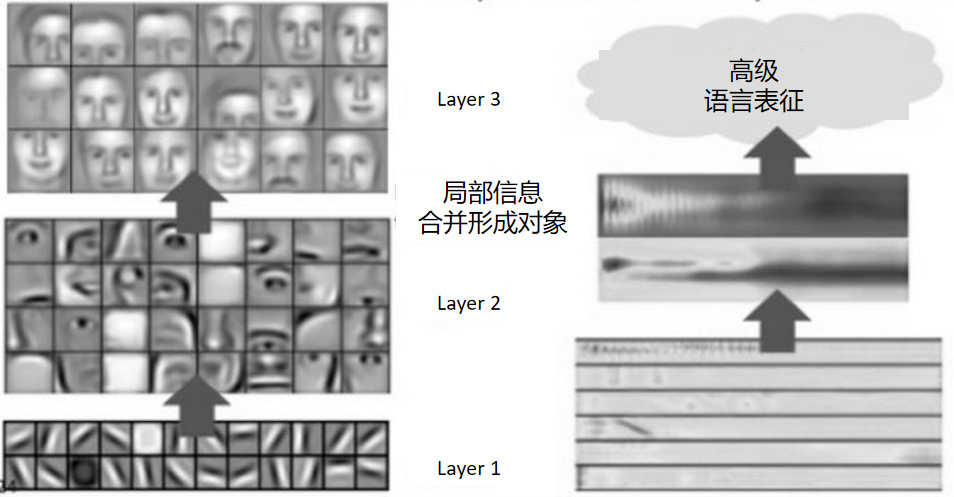
概括来说就是:前面几层学到的是通用特征(General Feature);随着网络层次的加深,后面的网络更偏重于与学习任务相关的特定特征(Specific Feature)。这非常好理解,我们也很容易接受。那么问题来了,如何得知哪些层能够学到通用特征,哪些层能够学到特定特征呢?更进一步来说,如果应用于迁移学习,如何决定该迁移哪些层、固定哪些层呢?
这个问题对于理解神经网络和深度迁移学习都有着非常重要的意义。来自康奈尔大学的 Jason Yosinski 等人率先进行了深度神经网络可迁移性的研究,该论文是一篇实验性质的文章(通篇没有一个公式)[Yosinski et al.,2014]。其目的就是要探究上面提到的几个关键性问题。因此,文章的全部贡献都来自实验及其结果。
对于 ImageNet 的 1000 个类别,作者将其分成两份(A 和 B),每份 500 个类别。然后,分别对 A 和 B 基于 Caffe 训练 AlexNet 网络。AlexNet 网络共有 8 层,除第 8 层为与类别相关的网络无法进行迁移外,作者在 1 到 7 这 7 层上逐层进行微调实验,探索网络的可迁移性。
为了更好地说明微调的结果,作者提出了两个有趣的概念:AnB 和 BnB。这里简单介绍一下 AnB 和 BnB。(所有实验都是针对数据 B 来说的。)
AnB:将 A 网络的前_n_层拿来并将其固定,剩下的层随机初始化,然后对 B 进行分类。
BnB:将 B 网络的前_n_层拿来并将其固定,剩下的随机初始化,然后对 B 进行分类。
深度网络迁移的实验结果 1 如下。
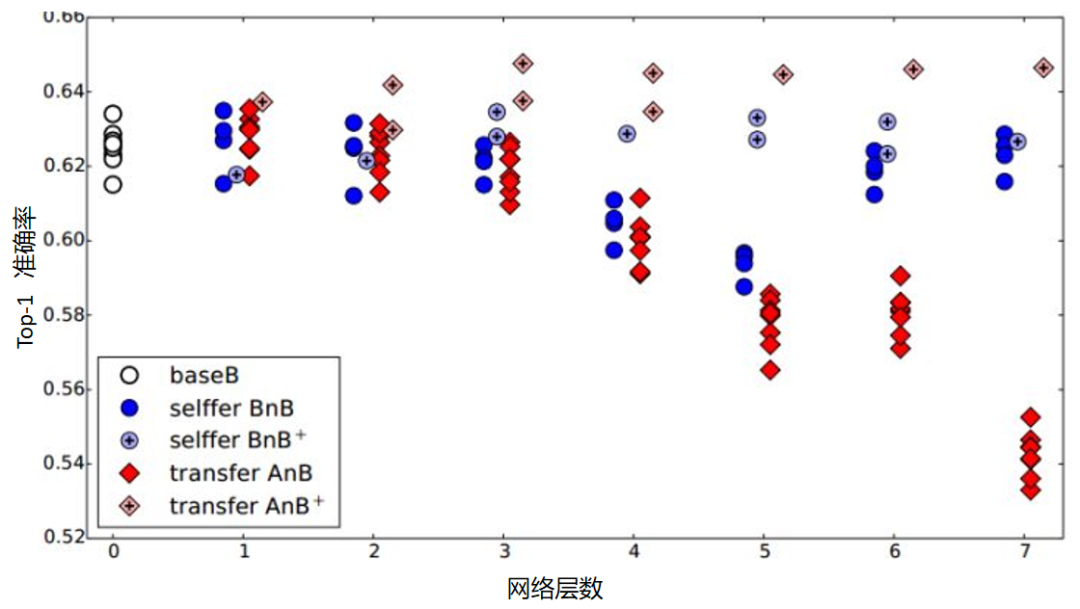
这个图说明了什么呢?我们先看 BnB 和 BnB+(即 BnB 加上微调)。对于 BnB 而言,原训练好的 B 模型的前 3 层可以直接拿来使用,而不会对模型精度有什么损失。到了第 4 层和第 5 层,精度略有下降,不过还可以接受。然而到了第 6 层、第 7 层,精度居然奇迹般地回升了,这是为什么?
原因如下:对于一开始精度下降的第 4 层、第 5 层来说,到了这两层,特征变得越来越具体,所以下降了。而对于第 6 层、第 7 层来说,由于整个网络就 8 层,我们固定了第 6 层、第 7 层,那这个网络还能学什么呢?所以很自然地,精度和原来的 B 模型几乎一致。
对 BnB+来说,结果基本上保持不变。说明微调对模型精度有着很好的促进作用。
我们重点关注 AnB 和 AnB+。对于 AnB 来说,直接将 A 网络的前 3 层迁移到 B,貌似不会有什么影响,再次说明,网络的前 3 层学到的几乎都是通用特征。往后,到了第 4 层、第 5 层时,精度开始下降,原因是这两层的特征不通用了。然而,到了第 6 层、第 7 层,精度出现了小小的提升后又下降,这又是为什么?作者在这里提出两点:互相适应(Co-Adaptation)和特征表示(Feature Representation)。也就是说,在第 4 层、第 5 层,主要是由于 A 和 B 两个数据集的差异比较大,精度才会下降的;到了第 6 层、第 7 层,由于网络几乎不再迭代,学习能力太差,此时特征学不到,所以精度下降得更厉害。
对于 AnB+,加入了微调以后,AnB+的表现对于所有的_n_几乎都非常好,甚至比 baseB(最初的 B)还要好一些。这说明,微调对深度迁移有着非常好的促进作用。
综合分析上述结果就得到了下图的深度网络迁移实验结果 2。
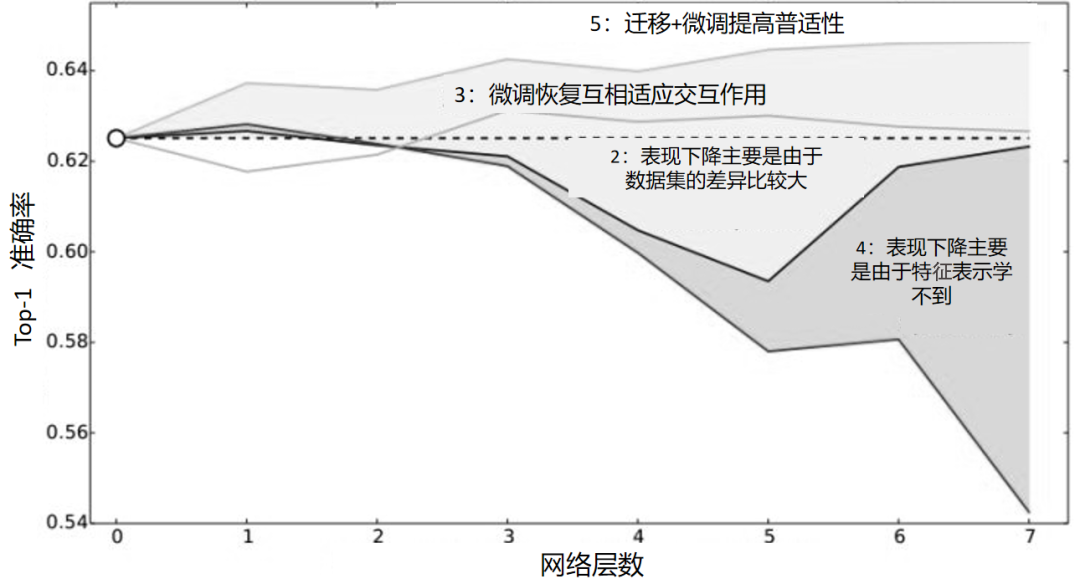
作者进一步设想,是不是在分 A、B 数据时,里面存在一些比较相似的类使结果变好了?例如,A 里有猫,B 里有狮子,所以结果会好。为了排除这些影响,作者又重新划分数据集,这次让 A 和 B 几乎没有相似的类别。在这个条件下再做 AnB,与原来精度进行比较,得到如下深度网络迁移实验结果 3。
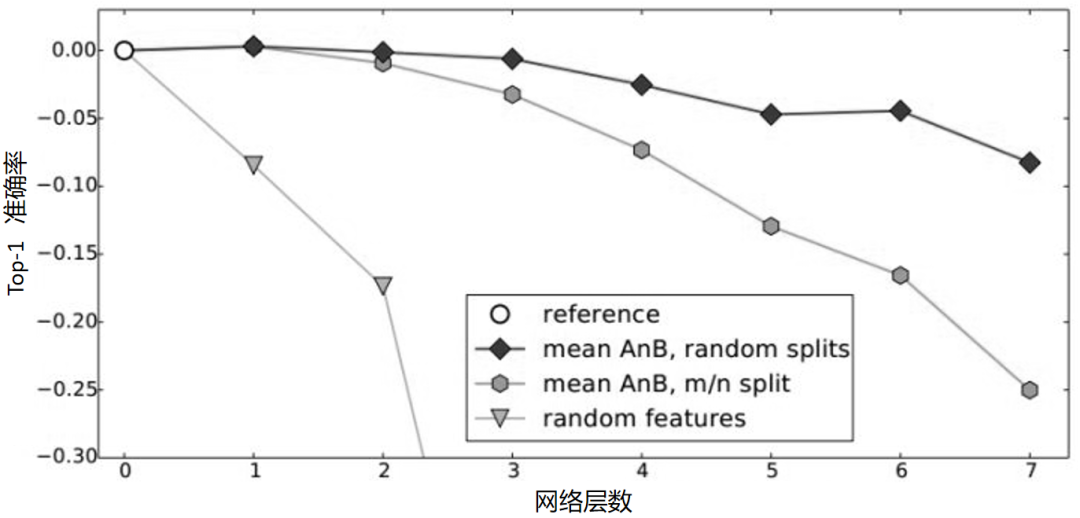
上图说明,随着可迁移层数的增加,模型性能会下降。但是,前 3 层仍然是可以迁移的。同时,与随机初始化所有权重相比,迁移学习获得的精度更高。
结论:
虽然论文[Yosinski et al.,2014]并没有提出创新的方法,但通过实验得到了以下几个结论,这对深度学习和深度迁移学习的研究都有着非常好的指导意义。
(1)神经网络的前 3 层基本都是通用特征,进行迁移的效果比较好。
(2)在深度迁移网络中加入微调,效果提升会比较大,可能会比原网络效果还好。
(3)微调可以比较好地克服数据之间的差异性。
2、微调
深度网络的微调(Fine-Tune)也许是最简单的深度网络迁移方法。简而言之,微调是利用别人已经训练好的网络,针对自己的任务再进行调整。从这个意义上看,不难理解微调是迁移学习的一部分。对于微调,有以下几个常见问题。
(1)为什么需要已经训练好的网络。
在实际应用中,我们通常不会针对一个新任务,从头开始训练一个神经网络。这样的操作显然是非常耗时的。尤其是,我们的训练数据不可能像 ImageNet 那么大,可以训练出泛化能力足够强的深度神经网络。即使我们有如此之多的训练数据,从头开始训练,其代价也是不可承受的。
那怎么办呢?迁移学习告诉我们,利用之前已经训练好的模型,将它很好地迁移到自己的任务上即可。
(2)为什么需要微调。
因为别人训练好的模型,可能并不完全适用于我们自己的任务。别人的训练数据和我们的数据可能不服从同一个分布;也可能别人的网络能做比我们的任务更多的事情;可能别人的网络比较复杂,而我们的任务比较简单。
举例子来说,假如我们想训练一个猫狗图像二分类的神经网络,那么在 CIFAR-100 上训练好的神经网络就很有参考价值。但是 CIFAR-100 有 100 个类别,我们只需要 2 个类别。此时,就需要针对我们自己的任务,固定原始网络的相关层,修改网络的输出层,以使结果更符合我们的需要,这样,会极大地加快网络训练速度,对提高我们任务上的精度表现也有很大的促进作用。
(3)微调的优势。
微调有以下几个优势。
● 针对新任务,不需要从头开始训练网络,可以节省时间。
● 预训练好的模型通常是在大数据集上进行训练的,这无形中扩充了我们的训练数据,使模型更鲁棒、泛化能力更好。
● 微调实现简单,我们只需关注自己的任务即可。
3、深度网络自适应
基本思路
深度网络的微调可以帮助我们节省训练时间,提高学习精度。但是微调有它的先天不足:它无法处理训练数据,无法测试不同数据的分布情况。因为微调的基本假设也是训练数据和测试数据服从相同的数据分布。这在迁移学习中是不成立的。因此,我们需要更进一步,针对深度网络开发出更好的方法使之更好地完成迁移学习任务。
以前面介绍过的数据分布自适应方法为参考,许多深度学习方法都设计了自适应层(Adaptation Layer)来完成源域和目标域数据的自适应。自适应能够使源域和目标域的数据分布更加接近,从而使网络的精度、稳定性更好。
从上述分析可以得出,深度网络的自适应主要完成两部分工作。
(1)决定哪些层可以自适应,这决定了网络的学习程度。
(2)决定采用什么样的自适应方法(度量准则),这决定了网络的泛化能力。
早期的研究者在 2014 年环太平洋人工智能大会(Pacific Rim International Conference on Artificial Intelligence,PRICAI)上提出了名为 DANN(Domain Adaptive Neural Networks)的神经网络[Ghifary et al.,2014]。DANN 的结构异常简单,它只由两层神经元——特征层神经元和分类器层神经元组成。作者的创新之处在于,在特征层后加入 MMD 适配层,用来计算源域和目标域的距离,并将其加入网络的损失中进行训练。但是,由于网络太浅,表征能力有限,故无法很有效地解决领域自适应问题。因此,后续的研究者大多都基于其思想进行改进,如将浅层网络改为更深层的 AlexNet、ResNet、VGG 等,将 MMD 换为多核 MMD 等。
下面将介绍几种常见的深度网络自适应方法。
基本方法
(1)DDC 方法。
加州大学伯克利分校的 Tzeng 等人首先提出了 DDC(Deep Domain Confusion)方法来解决深度网络的自适应问题[Tzeng et al.,2014]。DDC 方法遵循了上面讨论过的基本思路,采用了在 ImageNet 数据集上训练好的 AlexNet 网络进行自适应学习[Krizhevsky et al.,2012]。
下图是 DDC 方法示意图。
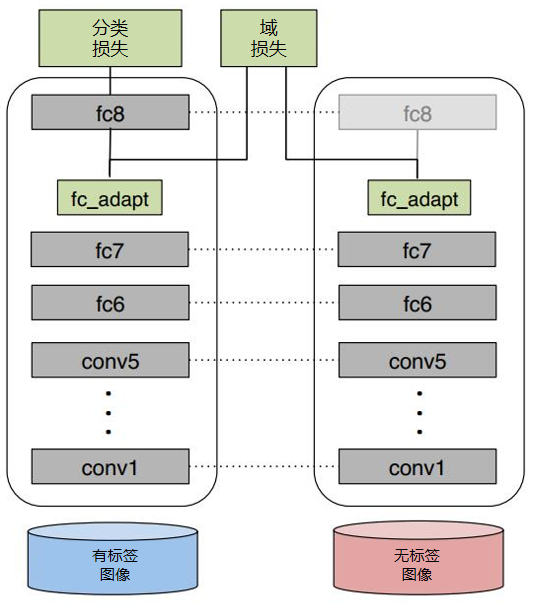
DDC 方法固定了 AlexNet 的前 7 层,在第 8 层(分类器前一层)上加入了自适应的度量。自适应度量方法采用了被广泛使用的 MMD 准则。
为什么选择倒数第 2 层?DDC 方法的作者在文章中提到,他们经过多次实验,在不同的层进行了尝试,最终发现在分类器前一层加入自适应可以达到最好的效果。这与我们的认知也是相符合的。通常来说,分类器前一层即特征,在特征上加入自适应,也正是迁移学习要完成的工作。
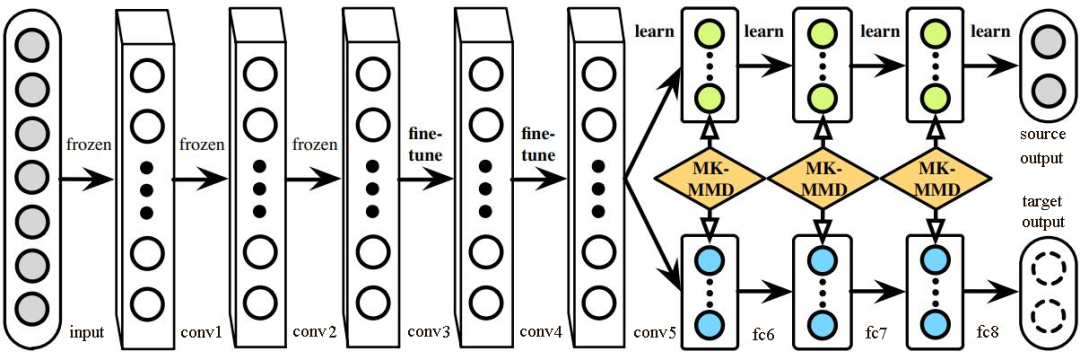
(2)DAN 方法。
清华大学的龙明盛等人于 2015 年发表在 ICML(Internation Conference on Machine Learning)上的 DAN(Deep Adaptation Networks)方法对 DDC 方法进行了几个方面的扩展[Long et al.,2015a]。首先,有别于 DDC 方法只加入一个自适应层,DAN 方法同时加入了 3 个自适应层(分类器前 3 层)。其次,DAN 方法采用表征能力更好的多核 MMD(MK-MMD)度量来代替 DDC 方法中的单核 MMD[Gretton et al.,2012]。最后,DAN 方法将多核 MMD 的参数学习融入深度网络的训练中,并且未额外增加网络的训练时间。DAN 方法在多个任务上都取得了比 DDC 方法更好的分类效果。
为什么适配 3 层?原来的 DDC 方法只适配了 1 层,现在 DAN 方法基于 AlexNet 网络,适配最后 3 层(第 6、7、8 层)。因为 Jason 在文献[Yosinski et al.,2014]中已经提出,网络的迁移能力从这 3 层开始就会有特定的任务倾向,所以要着重适配这 3 层。至于别的网络(如 GoogLeNet、VGG 等)是不是适配这 3 层就需要通过自己的实验来验证,要注意的是 DAN 方法只关注 AlexNet。DAN 方法示意图如下。
(3)同时迁移领域和任务的方法。
DDC 方法的作者 Tzeng 在 2015 年扩展了 DDC 方法,提出了领域和任务同时迁移的方法[Tzeng et al.,2015]。他提出网络要进行两部分迁移。
一是域迁移(Domain Transfer),尤其指适配边缘分布,但没有考虑类别信息。域迁移就是在传统深度网络的损失函数上,再加一个混淆损失(Confusion Loss)函数,两个损失函数一起计算。
二是任务迁移(Task Transfer),就是利用类别之间的相似度进行不同任务间的学习。举个类别之间相似度的例子:杯子与瓶子更相似,而它们与键盘不相似。
现有的深度迁移学习方法通常都只考虑域迁移,而没有考虑类别之间的信息。如何把域迁移和任务迁移结合起来,是一个需要研究的问题。
Tzeng 针对目标任务的部分类别有少量标签,剩下的类别无标签的情况,提出名为域迁移和任务迁移的联合 CNN 体系结构(Joint CNN Architecture For Domain and Task Transfer)。其最大的创新之处在于,提出现有的方法都忽略了类别之间的联系,并提出在现有损失函数的基础上还要再加一个软标签损失(Soft Label Loss)函数。意思就是在源域和目标域进行适配时,也要根据源域的类别分布情况来调整目标域。相应地,他提出的方法就是把这两个损失函数结合到一个新的 CNN 网络上,这个 CNN 是基于 AlexNet 修改而来的。总的损失函数由 3 部分组成,第 1 部分是普通训练的损失函数,第 2 部分是域自适应的损失函数,第 3 部分是目标域上的软标签损失函数。
下图为同时迁移领域和任务的方法示意图。
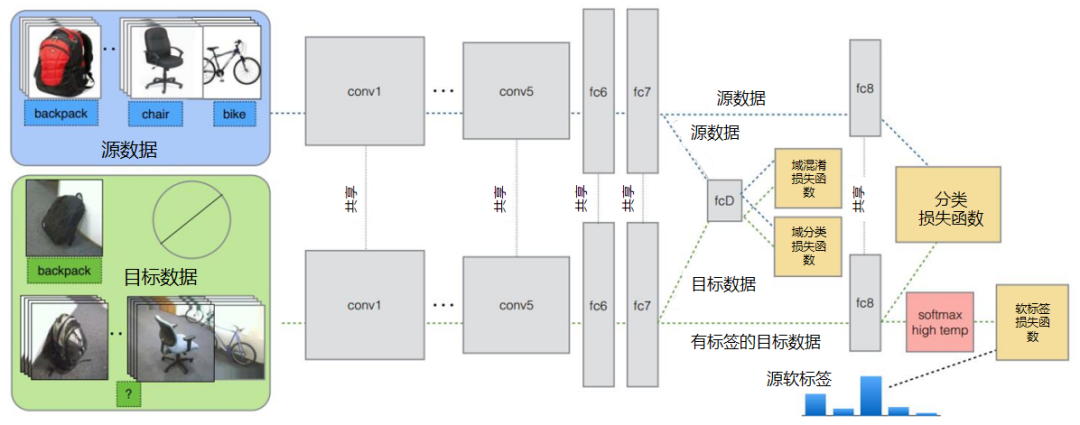
该网络由 AlexNet 修改而来,前面几层无变化,区别是在 fc7 层后面加入了一个域分类器,在该层实现域自适应,在 fc8 层后计算网络的损失函数和软标签损失函数。
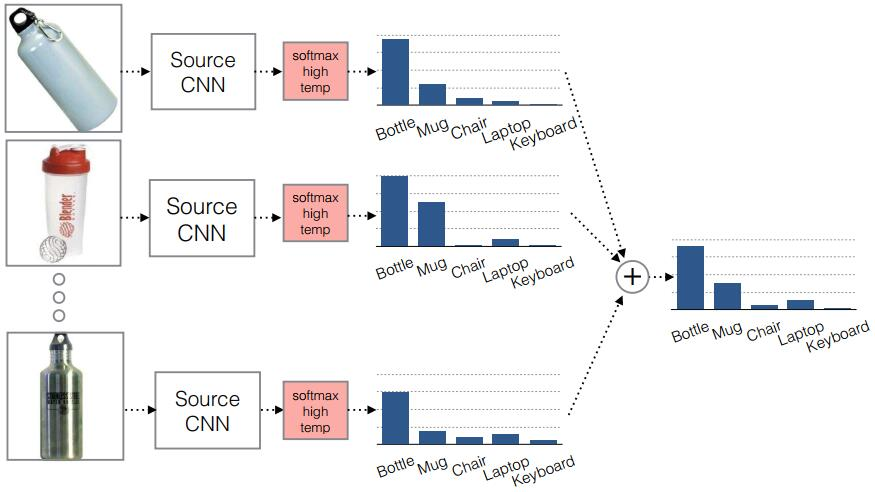
那么什么是软标签损失?
软标签损失就是不仅要适配源域和目标域的边缘分布,还要把类别信息考虑进去。具体做法如下,在网络对源域进行训练时,把源域中的每一个样本处于每一个类的概率都记下来,然后,对于所有样本,属于每一个类的概率就可以通过先求和再求平均数得到。下为软标签损失示意图。这样做的目的是,根据源域中的类别分布关系,来对目标域做相应的约束。
(4)JAN 方法。
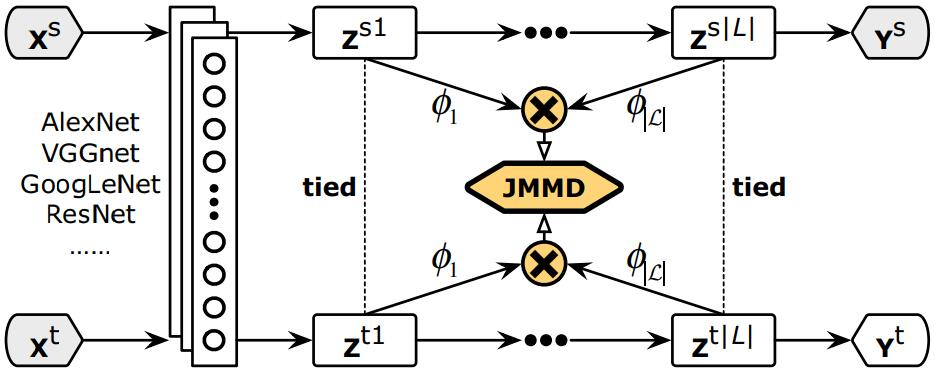
DAN 方法的作者龙明盛 2017 年在 ICML 上提出了 JAN(Joint Adaptation Networks)方法[Long et al.,2017],在深度网络中同时进行联合分布的自适应和对抗学习。JAN 方法将只对数据进行自适应的方式推广到了对类别的自适应上,提出了 JMMD 度量(Joint MMD)。下为 JAN 方法示意图。
(5)AdaBN 方法。
与上述研究选择在已有网络层中增加适配层不同,北京大学的 H Li 和图森科技的 N Wang 等人提出了 AdaBN(Adaptive Batch Normalization)方法[Li et al.,2018],其通过在归一化层加入统计特征的适配来完成迁移。下图是 AdaBN 方法示意图。
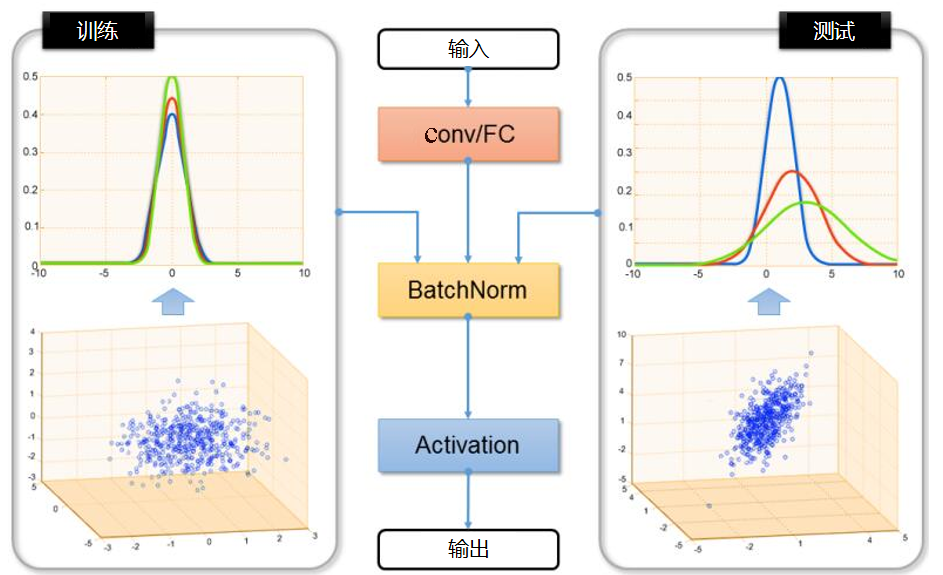
AdaBN 方法与其他方法相比,实现起来相当简单,不带有任何额外的参数,在许多公开数据集上都取得了很好的效果。
4、深度对抗网络迁移
生成对抗网络 GAN(Generative Adversarial Nets)是目前人工智能领域的研究热点之一[Goodfellow et al.,2014],它被深度学习领军人物 Yann LeCun 评为近年来最令人欣喜的成就。由此发展而来的对抗网络,也成为提升网络性能的利器。本节介绍深度对抗网络用于解决迁移学习的基本思路及其代表性研究成果。
基本思路
GAN 受博弈论中的二人零和博弈(Two-Player Game)思想的启发而提出。它包括两部分:生成网络(Generative Network),负责生成尽可能逼真的样本,被称为生成器(Generator);判别网络(Discriminative Network),负责判断样本是否真实,被称为判别器(Discriminator)。生成器和判别器互相博弈,就完成了对抗训练。
GAN 的目标很明确,就是生成训练样本,这似乎与迁移学习的大目标有些许出入。然而,由于在迁移学习中天然存在一个源域和一个目标域,因此,我们可以免去生成样本的过程,而直接将其中一个领域的数据(通常是目标域)当作生成的样本。此时,生成器的职能发生变化,不再生成新样本,而去扮演特征提取的功能——不断学习领域数据的特征,使判别器无法对两个领域进行分辨。这样,原来的生成器也可以称为特征提取器(Feature Extractor)。
通常用 来表示特征提取器,用 来表示判别器。
正是基于这样的领域对抗思想,深度对抗网络可以被很好地应用到迁移学习问题中。
与深度网络自适应迁移方法类似,深度对抗网络的损失函数也由两部分构成:网络训练损失函数 和领域判别损失函数 ,如下所示。
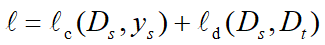
核心方法
(1)DANN 方法。
Yaroslav Ganin 等人首先在迁移学习中加入了对抗机制,并将他们的网络称为 DANN(Domain-Adversarial Neural Networks)方法[Ganin et al.,2016]。在此研究中,网络的学习目标是,生成的特征尽可能帮助区分两个领域的特征,同时使判别器无法对两个领域的差异进行判别。该方法的领域对抗损失函数表示为:
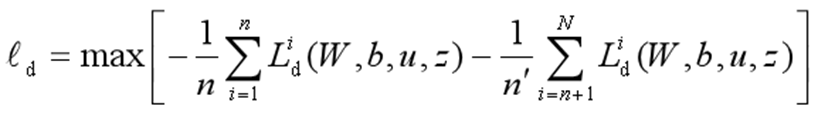
其中
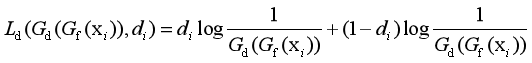
(2)DSN 方法。
来自 Google Brain 的 Bousmalis 等人提出 DSN(Domain Separation Networks)方法对 DANN 进行了扩展[Bousmalis et al.,2016]。DSN 方法认为,源域和目标域都由两部分构成:公共部分和私有部分。公共部分可以学习公共的特征,私有部分用来保持各个领域独立的特性。DSN 方法进一步对损失函数进行了定义。
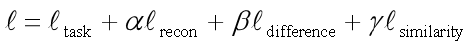
其具体含义如下。
为网络常规训练的损失函数。
为重构损失函数,确保私有部分仍然对学习目标有作用。
公共部分与私有部分的差异损失函数。
源域和目标域公共部分的相似性损失函数。
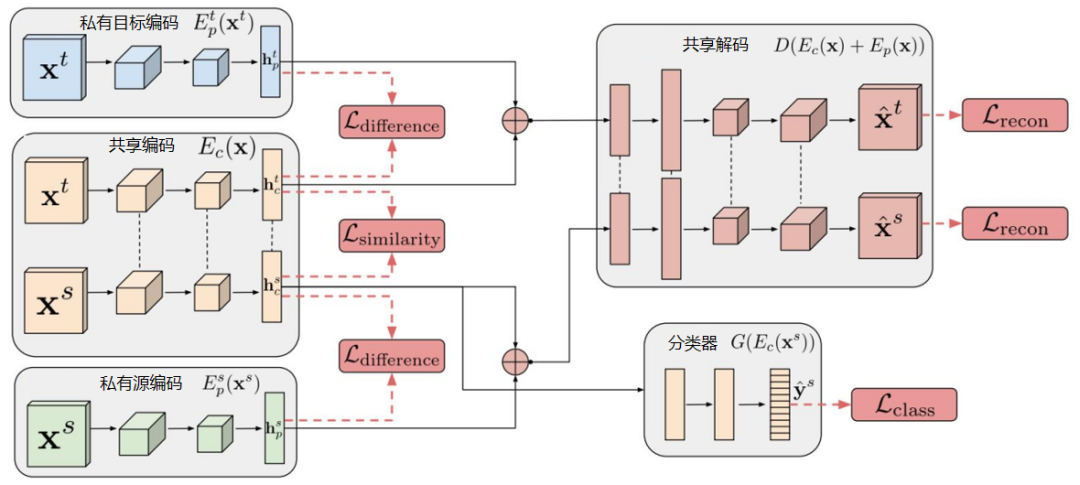
如下是 DSN 方法示意图。
(3)SAN 方法。
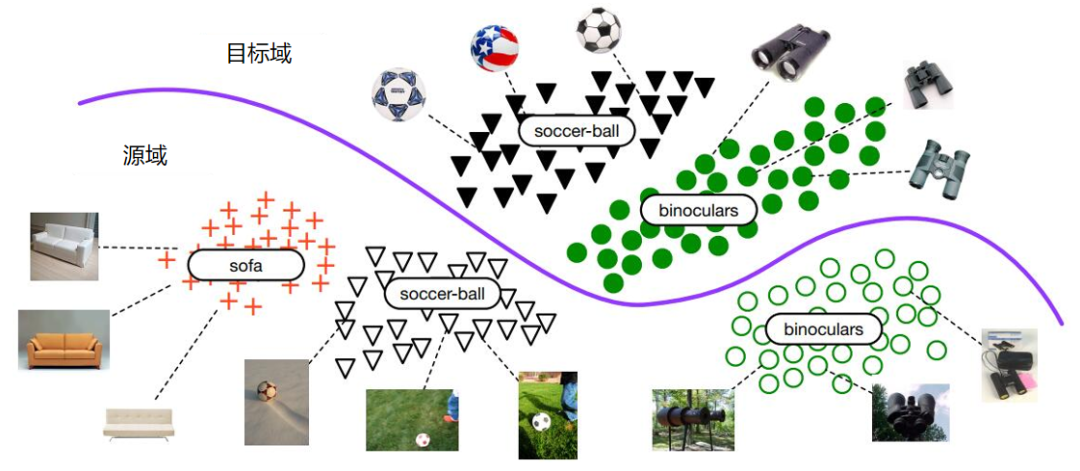
清华大学龙明盛等人 2018 年发表在 CVPR(Computer Vision and Pattern Recognition)上的文章提出了部分迁移学习(Partial Transfer Learning)。作者认为,在大数据时代,通常我们会有大量的源域数据。这些源域数据与目标域数据相比,在类别上通常更为丰富。例如,基于 ImageNet 训练的图像分类器,必然是针对几千个类别进行的分类。在实际应用时,目标域往往只是其中的一部分类别。这样就会带来一个问题:那些只存在于源域中的类别在迁移时,会对迁移结果产生负迁移影响。这种情况是非常普遍的,因此,就要求相应的迁移学习方法能够对目标域选择相似的源域样本(类别),同时也要避免负迁移。但是目标域通常是没有标签的,因此我们并不知道它和源域中哪个类别更相似。作者称这个问题为部分迁移学习(Partial Transfer Learning)。Partial 即只迁移源域中和目标域相关的那部分样本。
下图展示了部分迁移学习示意图。
作者提出了名为选择性对抗网络(Selective Adversarial Networks,SAN)的方法来处理选择性迁移问题[Cao et al.,2017]。在该问题中,传统的对抗网络不再适用。所以需要对其进行一些修改,使它能够适用于选择性迁移问题。
购买可戳该链接

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论