
Original URL: https://aws.amazon.com/cn/blogs/machine-learning/machine-learning-best-practices-in-financial-services/
金融服务领域的机器学习最佳实践
在最近发布的白皮书《金融服务中的机器学习最佳实践(Machine Learning Best Practices in Financial Services)》中,我们概述了在构建机器学习(ML)工作流的过程中,金融机构需要关注的安全性与模型治理注意事项。这份白皮书还涵盖了常见的安全性与合规性要素,旨在配合上手演示与研习班共同为您介绍端到端的示例。虽然这份白皮书主要着眼于金融服务行业,但其中涉及的身份验证与访问管理、数据与模型安全以及 ML 实施(MLOps)最佳实践等内容,也同样适用于医疗保健等其他受到严格监管的行业。
如下图所示,典型的机器学习工作流中往往涉及多个利益相关方。为了成功管理并运营这类工作流,我们需要推动跨团队协作,将业务相关方、系统运营管理员、数据工程师以及软件/DevOps 工程师纳入这套体系中来。
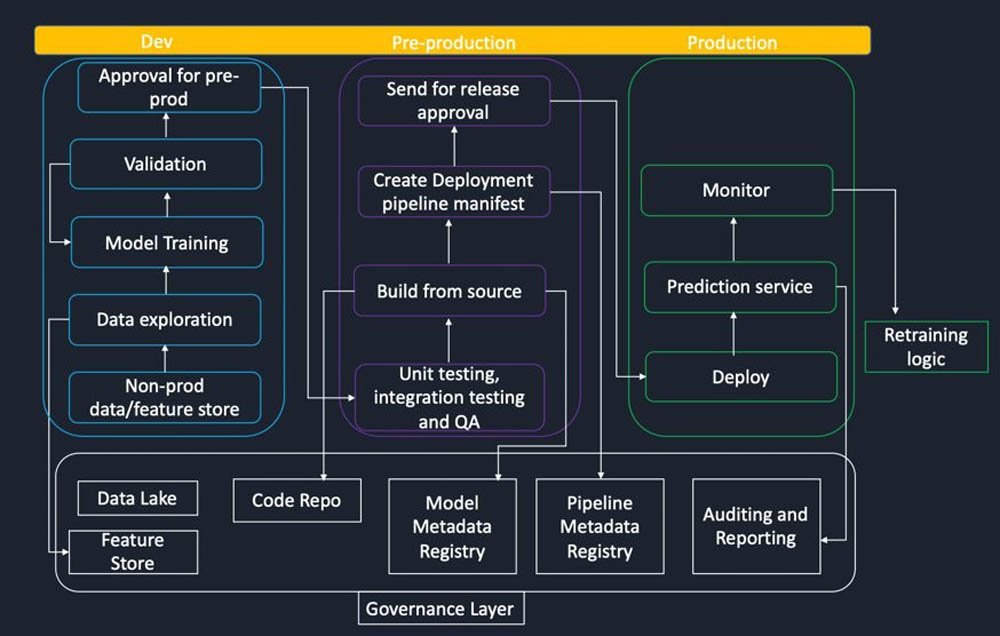
在白皮书中,我们还探讨了各个团队需要关注的核心事项,并通过示例与说明阐述如何使用Amazon SageMaker及其他 AWS 服务实现机器学习工作负载的构建、训练与部署。具体来讲,结合高监管要求背景下客户们提供的真实反馈,我们着重分析了以下主题:
置备一套安全的机器学习环境——具体包括:
* 计算与网络隔离——如何在不连接互联网的前提下,将 Amazon SageMaker 部署在客户的专用网络当中。
* 身份验证与授权——如何以可控方式对用户进行身份验证,并在非多租户场景下根据其 AWS 身份与访问管理( AWS Identity and Access Management ,简称 IAM)权限对各用户进行授权。
* 数据保护——如何使用客户提供的加密密钥对传输中的数据及静态数据进行加密。
* 可审计性——如何在给定的时间点审计、阻止并检测谁做过什么,借此帮助识别并抵御恶意行为。
建立机器学习治理机制——具体包括:
* 可追溯性——从数据准备、模型开发以及训练迭代中跟踪机器学习模型的沿袭方法,并考虑如何审计任何人在任意时间点上曾经做过什么。
* 可解释性与可理解性——有助于解释经过训练的模型如何建立起对各项特征的重要性判断与区分方法。
* 模型监控——如何对生产环境下的模型进行监控,借此防止数据漂移问题,并自动对您定义的规则做出反应。
* 可重现性——如何根据模型沿袭与存储的工件进行机器学习模型重现。
实现机器学习工作负载的可操作化——具体包括:
* 模型开发工作负载——如何在开发环境中构建起自动与手动审查流程。
* 预生产工作负载——如何使用 AWS CodeStar套件与AWS Step Functions构建起自动化 CI/CD 管道。
* 生产与持续监控工作负载——如何将持续部署与自动化模型监控结合起来。
* 跟踪与警报——如何跟踪模型指标(运营与统计指标),并在检测到异常时向相关用户发出警报。
置备一套安全机器学习环境
拥有良好治理机制的安全机器学习工作流,首先需要一套专用且隔离化的计算与网络环境。特别是在大量使用个人隐私信息(PII)进行模型构建与训练的高监管行业中,这方面需求将更为强烈。我们使用 Amazon Virtual Private Cloud (VPC) 托管 Amazon SageMaker 及其相关组件(例如 Jupyter notebook、训练实例以及托管实例等),因此必须保证将这些 VPC 部署在不接入互联网的专用网络当中。
此外,大家可以将这些 Amazon SageMaker 资源与您的 VPC 环境相关联,借此使用网络层级的控制机制(例如安全组),牢牢掌控指向 Amazon SageMaker 资源的访问以及数据进出环境。再有,您也可以使用 VPC 端点或者AWS PrivateLink在 Amazon SageMaker 与其他 AWS 服务(例如 Amazon Simple Storage Service ,简称 Amazon S3)之间建立连接。下图所示,为 Amazon SageMaker 的一套安全部署参考架构。
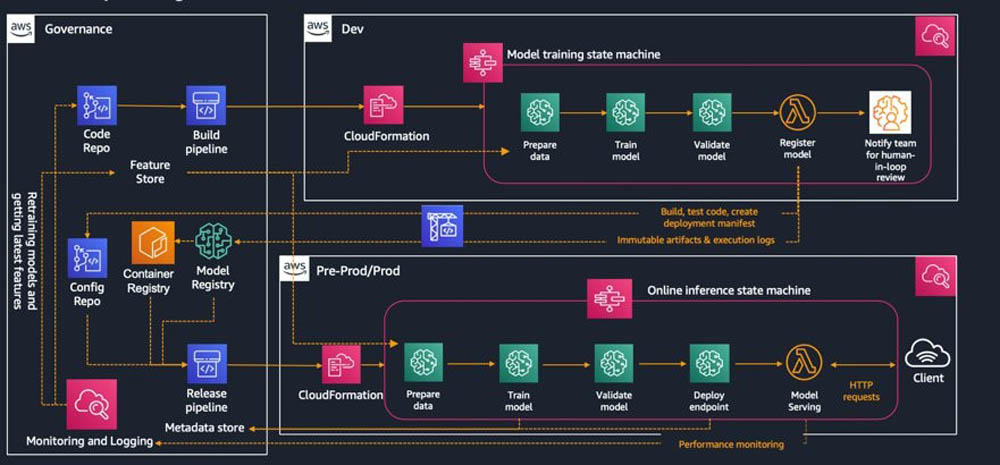
下一步工作,是确保只有授权用户才能访问到对应的 AWS 服务。IAM 能够帮助大家在机器学习环境当中建立起多种预防性控制机制,包括访问 Amazon SageMaker 资源、Amazon S3 中的数据以及 API 端点等。您可以使用 RESTful API 访问各项 AWS 服务,且每一次 API 调用都需要获得 IAM 授权。大家也可以通过 IAM 策略配置授权显式权限,由其指定获准的主体(人员)、操作(API 调用)、资源(例如 Amazon S3 对象)以及授权访问权限的条件。要深入了解如何为金融服务构建安全环境(包括实现其他良好架构支柱),请参阅本白皮书。
此外,由于机器学习环境中可能包含敏感数据与知识产权,因此安全的机器学习环境必须进行数据加密。我们建议大家使用自己的加密密钥启动静态数据与传输数据加密。最后,要建立起治理良好且安全的机器学习环境,另一项重点在于配合健壮且透明的审计跟踪机制,借此记录对于数据及模型的一切访问与变量,包括模型配置或超参数层面的更改。白皮书中就这些问题都做出了详尽阐述。
为了实现自助服务置备与自动化,管理员可以使用诸如AWS Service Catalog之类的工具以可重复方式为数据科学家创建这类安全环境。以此为基础,数据科学家能够轻松使用AWS Single Sign-On单点登录至安全门户并创建一套安全的 Jupyter notebook 环境,最终结合需求进一步安装并使用适当的安全围栏方案。
建立机器学习治理机制
在白皮书的这部分内容中,我们讨论了关于机器学习治理的注意事项,具体包括四个核心议题:可追溯性、可解释性/可理解性、实时模型监控与可重现性。金融服务行业需要承担多种合规性与监管义务,因此可能对机器学习的治理机制造成直接影响。本文建议大家与您的法律顾问、合规人员以及涉及机器学习流程的其他利益相关方沟通,共同核定并研究此类义务。
例如,如果 Jane Smith 的贷款申请被银行方面拒绝,很可能要求贷方对决策的制定过程做出解释,这也是监管要求中的固有环节。如果银行客户将机器学习引入贷款审查流程,则可能需要对机器学习模型做出的预测进行解释或说明,借此满足监管要求。通常,机器学习模型的可解释性与可理解性,是指人们理解与解释模型所执行的预测流程的能力。另外需要注意的是,相当一部分机器学习模型只是在做潜在答案本身做出预测,而并不能真正理解答案本身。因此,在实际采取行动之前,大家最好能够对机器学习模型做出的预测进行人工审核。此外,我们可能还需要监控模型,保证一旦基础数据发生更改、能够定期使用新数据对模型进行重新训练。最后,机器学习模型可能还需要保证可重现性,借此保证在对模型输出结果进行追溯时,仍能保持相同的输出内容。
实现机器学习工作负载的可操作化
在最后一节中,我们将讨论一些关于实现机器学习工作负载的最佳实践。我们首先从宏观角度出发,而后逐步深入研究使用 AWS 原生工具与服务的特定架构。除了模型部署流程之外(在传统软件部署中被称为持续集成/持续部署,即 CI/CD),从实施角度来看,在受监管行业的生产环境中部署机器学习模型还需要考虑其他一些关键因素。
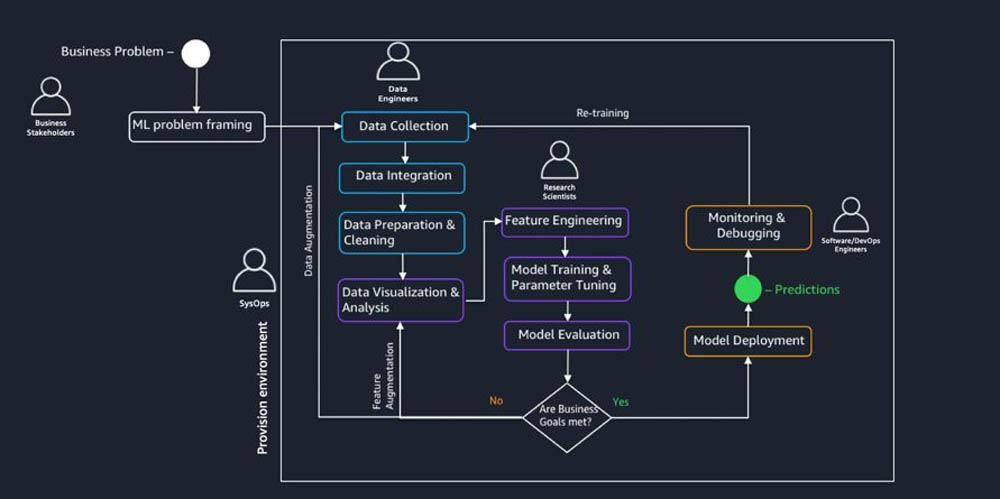
下图所示,为企业机器学习平台可能需要满足的部分高级要求,具体包括治理、审计、日志记录以及报告等相关指导规则:
一套数据湖,用于管理原始数据与相关元数据。
用于管理机器学习特征与相关元数据(从原始数据到所生成特征之间的映射,例如一键编码或缩放转换)的特征存储机制。
一套模型与容器注册表,其中包含训练后模型的工件,以及相关元数据(例如超参数、训练时间与依赖项等)。
用于维护源代码并实现版本控制的代码库(例如 Git、AWS CodeCommit或者 Artifactory)。
用于注册及维护训练与部署管道的管道注册表。
用于维护访问日志的日志记录工具。
生产监控与性能日志。
审计与报告工具。
下图所示,为使用 AWS 原生工具与服务建立的一套特定实现架构。目前市面上也存在多种可行的调度与编排工具选项,例如 Airflow 或 Jenkins 等,但为了便于理解,这里我们集中讨论使用 Step Functions 的场景。
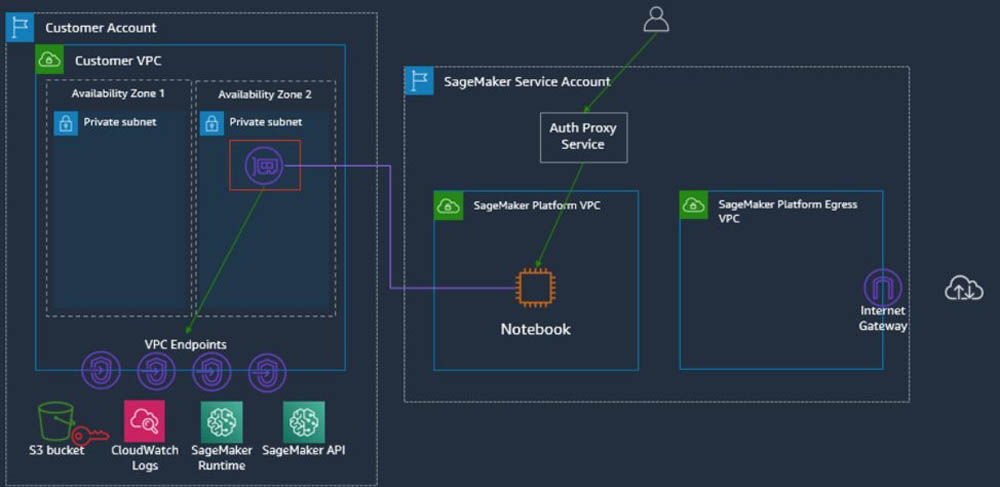
在白皮书中,我们深入探讨了上图中的各个组件,特别是以下工作负载类型:
模型开发
预生产
生产与持续监控
总结
《金融服务中的机器学习最佳实践》白皮书旨在帮助大家了解如何建立起安全且具有良好治理水平的机器学习工作流,大家也可以结合实际疑问与作者取得联系。在您的机器学习探索之旅中,不妨随时参阅另一份白皮书以了解适用于机器学习工作负载的 AWS 架构设计原则。此外,您也可以配合视频演示与以下两项研习课程进一步加深理解:
作者介绍:
Stefan Natu
Amazon Web Services 公司高级机器学习专家。他致力于帮助金融服务业客户在 AWS 上构建起端到端机器学习解决方案。在业余时间,他喜欢阅读机器学习相关技术博客、弹奏吉他以及探索纽约市本地的各种美食。
Kosti Vasilakakis
Amazon SageMaker(用于端到端机器学习的 AWS 全托管服务)高级业务开发经理。他致力于帮助金融服务与技术企业通过机器学习取得更多成就。他率先举办一系列精选研习课、上手指导活动以及预打包开源解决方案,旨在帮助客户更快、更安全地构建起更强大的机器学习模型。在工作之余,他喜欢旅行、进行哲学思考和打网球。
Alvin Huang
Amazon Web Services 公司全球金融服务业务开发资本市场专家,专注于数据湖与分析、人工智能及机器学习。Alvin 在金融服务行业拥有超过 19 年的工作经验。在加入 AWS 之前,他曾担任摩根大通公司执行董事,负责管理北美及南美洲贸易监督团队,并领导全球贸易业务发展。Alvin 还在罗格斯大学教授风险量化管理课程,同时兼任罗格斯数学金融硕士课程(MSMF)顾问委员会成员。
David Ping
Amazon Web Services 公司首席机器学习架构师兼 AI/ML 解决方案架构高级经理。他帮助企业客户在 AWS 上构建并运行各类机器学习解决方案。David 喜欢远足和关注机器学习领域的最新进展。
本文转载自亚马逊 AWS 官方博客
原文链接:




