

今天介绍自然语言处理中经典的隐马尔科夫模型(HMM)。HMM 早期在语音识别、分词等序列标注问题中有着广泛的应用。
了解 HMM 的基础原理以及应用,对于了解 NLP 处理问题的基本思想和技术发展脉络有很大的好处。本文会详细讲述 HMM 的基本概念和原理,并详细介绍其在分词中的实际应用。
马尔科夫随机过程
设随机变量 X(t)随时间 t(t=t1,t2,t3…tn)而变化,E 为其状态空间,若随机变量 x 满足马尔科夫性,如下:
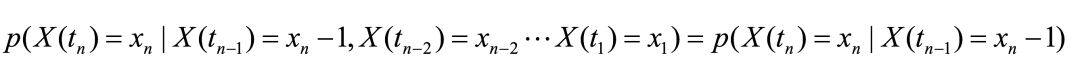
即 X 在 tn 时刻的状态只与其前一时刻时状态的值有关,则称该随机变量的变化过程是马尔科夫随机过程,随机变量满足马尔科夫性。
隐马尔科夫模型(HMM)
如图所示为马尔科夫模型的图结构
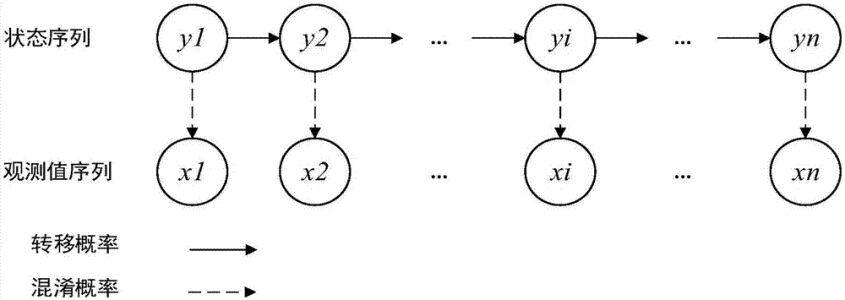
基于此图结构可知,HMM 模型满足如下的性质:
(1) 它基于观测变量来推测未知变量;
(2) 状态序列满足马尔科夫性;
(3) 观测序列变量 X 在 t 时刻的状态仅由 t 时刻隐藏状态 yt 决定。
同时,隐马尔科夫模型是一种概率图模型,它将学习任务归结于计算变量的概率分布。通过考虑联合概率 P(Y,X)来推断 Y 的分布。
考虑马尔科夫性质以及随机变量 Y 在 t 时刻的状态仅由 y(t-1)决定,观测序列变量 X 在 t 时刻的状态仅由 yt 决定,有:
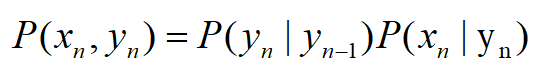
从而可以推出联合概率:
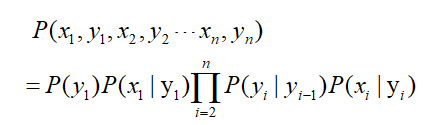
总的来说,马尔科夫模型式利用已知的观测序列来推断未知变量序列的模型。
例如在分词任务中,中文的句子“请问今天的天气怎么样?”就是可以被观测到的序列,而其分词的标记序列就是未知的状态序列“请问/今天/深圳/的/天气/怎么样/?” 这种分词方式对应的标记序列为“BEBEBESBEBME”
标记序列:标签方案中通常都使用一些简短的英文字符[串]来编码。
标签列表如下,在分词任务中,通常用 BMES 标记。
B,即 Begin,表示开始
M,即 Mediate,表示中间
E,即 End,表示结尾
S,即 Single,表示单个字符
HMM 模型的几个重要概率矩阵
仔细分析此联合概率表达式,可知其分为三个部分:
(1) 初始状态概率 P(y1)
初始概率矩阵是指序列头的状态分布,以分词为例,就是每个句子开头,标记分别为 BMES 的概率。
(2) 状态转移概率 P(yi|yi-1)
状态转移概率是指状态序列内,两个时刻内不同状态之间转移的状态分布。以分词为例,标记状态总共有 BMES 四种,因此状态转移概率构成了一个 4*4 的状态转移矩阵。这个矩阵描述了 4 种标记之间转化的概率。例如,P(yi=”E”|yi-1=”M”)描述的 i-1 时刻标为“M”时,i 时刻标记为“E”的概率。
(3) 输出观测概率 P(xi|yi)
输出观测概率是指由某个隐藏状态输出为某个观测状态的概率。以分词为例,标记状态总共有 BMES 四种,词表中有 N 个字,则输出观测概率构成了一个 4*N 的输出观测概率矩阵。这个矩阵描述了 4 种标记输出为某个字的概率。例如,P(Xi=”深”|yi=”B”)描述的是 i 时刻标记为“B”时,i 时刻观测到到字为“深”的概率。
HMM 在分词应用中的实战
经过上面的讲述,各位读者可能还是会对 HMM 有一种似懂非懂的感觉。所以这一节中介绍其在分词应用中的实践,通过完整实际的思路介绍和代码讲解,相信各位读者能够对 HMM 模型有一个准确的认识。
假设有词序列 Y = y1y2…yn,HMM 分词的任务就是根据序列 Y 进行推断,得到其标记序列 X= x1x2…xn,也就是计算这一个概率:
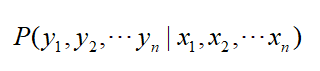
根据贝叶斯公式:
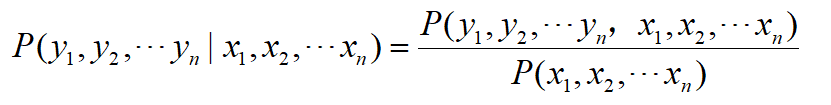
当语料确定时
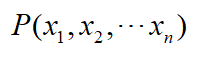
可以认为是常数,所以只需计算
这样的话,就是要计算 3 小节的那三个概率矩阵,当获得上述三个矩阵之后,便可以根据维特比算法计算出一个词序列对应概率最大的分词标记序列,就此也就完成了分词的任务。那我们就还剩下 2 个任务:
根据语料计算三个概率矩阵
当获得了分好词的语料之后,三个概率可以通过如下方式获得:
(1) 初始状态概率 P(y1)
统计每个句子开头,序列标记分别为 B,S 的个数,最后除以总句子的个数,即得到了初始概率矩阵。
(2) 状态转移概率 P(yi|yi-1)
根据语料,统计不同序列状态之间转化的个数,例如 count(yi=”E”|yi-1=”M”)为语料中 i-1 时刻标为“M”时,i 时刻标记为“E”出现的次数。得到一个 4*4 的矩阵,再将矩阵的每个元素除以语料中该标记字的个数,得到状态转移概率矩阵。
(3) 输出观测概率 P(xi|yi)
根据语料,统计由某个隐藏状态输出为某个观测状态的个数,例如 count(xi=”深”|yi=”B”)为 i 时刻标记为“B”时,i 时刻观测到字为“深”的次数。得到一个 4*N 的矩阵,再将矩阵的每个元素除以语料中该标记的个数,得到输出观测概率矩阵。
我们看一下该部分的代码:
Pi = {k: v*1.0/line_num for k,v in Pi_dict.items()}
A = {k: { k1: v1/ Count_dict[k] for k1, v1 in v.items()}
for k, v in A_dict.items()
}
B= {k: { k1: v1/ Count_dict[k] for k1, v1 in v.items()}
for k,v in B_dict.items()
}
line_num 为预料中句子的个数;
Pi_dic 记录了语料中句子中开头标记的个数。
Count_dict 记录了预料中“BMES”四个标记的个数;
A_dict 记录了不同序列状态之间转化的个数;
B_dict 记录了不同隐藏状态输出为某个观测状态的个数。
维特比算法
训练结束之后,便可获得三个概率矩阵,那么该如何利用上述矩阵,获得一个句子的最大概率分词标记序列,即完成分词任务呢?下面就是我们要介绍的维特比算法。
设 Q 是所有可能状态的集合 Q={q1,q2,…qN},V={v1,v2,…vM}是所有可能的观测集的集合。其中 N 是可能的状态数(例如标记个数 4:“BMES”),M 是可能的观测状态数(例如字典中字的个数)。
一个隐马尔可夫模型由一个三元组(Pi,A,B)确定,I 是长度为 T 的状态序列,O 是对应的观测序列,先用数学符号表示上述的三个概率矩阵:
初始概率矩阵,表示序列开头,序列状态为 yi 的概率
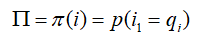
状态转移矩阵,表示序列状态由 yi 转为 yj 的概率
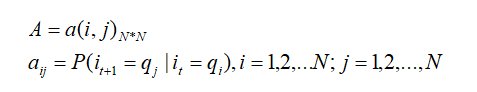
输出状态矩阵,表示序列状态为 yi 时,输出字为 xj 的概率
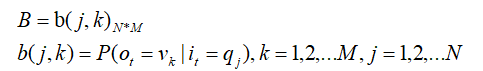
进而,为了叙述方便,引入两个变量:
定义时刻 t 状态为 i 的所有单个路径(i1,i2,i3,…,it)中概率最大值为,简单记为 delta(i):
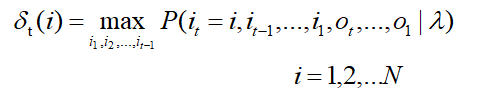
由其定义可得其递推公式:
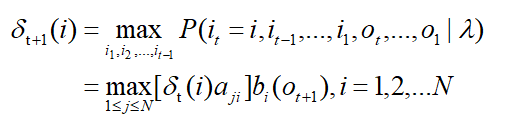
下为时刻 t 状态为 i 的所有单个路径中,概率最大的路径的第 t-1 个节点,简单记为 kethe(i):
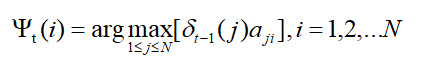
先阐述一下维特比算法的基本流程:
(1) 计算初始转态概率
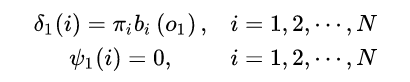
通过上述公式,得到 t=1 时刻,隐藏状态取各个值(BMES)时的概率。
(2) 逐渐递推到 t=2,3,4…T
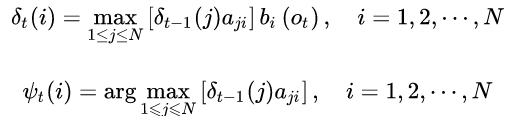
通过上述公式,分别得到各个时刻,隐藏状态取各个值时的概率最大的路径以及其前一时刻节点状态
(3) 终止
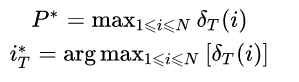
选取 T 时刻中,取值最大的那个状态为 T 时刻的状态。
(4) 回溯最优路径
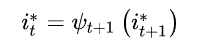
根据前面计算的结果,反推得到各个时刻隐藏状态的取值
可能还有同学对这个过程不是很理解,我们举分词的例子,详细介绍一下这个过程。
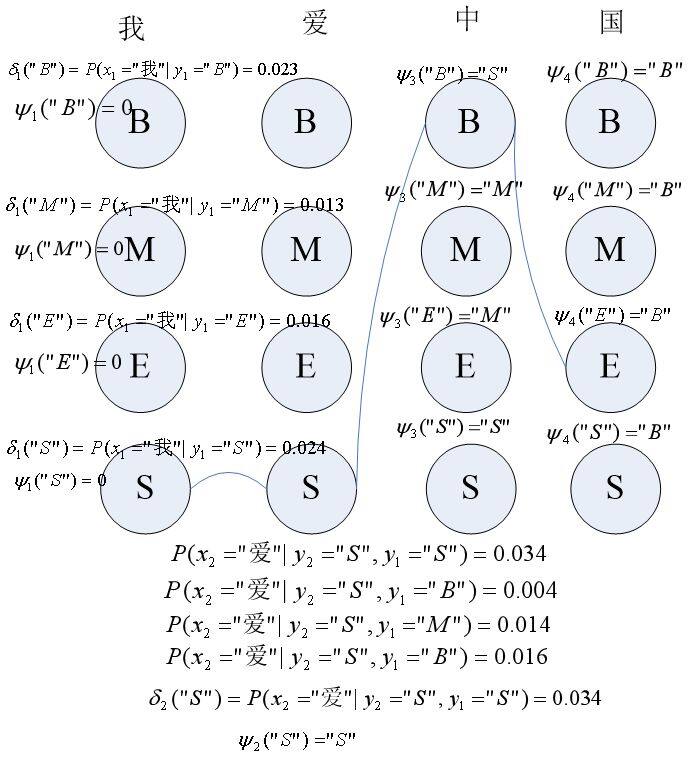
维特比算法是计算一个概率最大的路径,如图要计算“我爱中国”的分词序列:
第一个词为“我”,通过初始概率矩阵和输出观测概率矩阵分别计算 delta1(“B”)=P(y1=”S”)P(x1=”我”|y1=”S”),delta1(“M”)=P(y1=”B”)P(x1=”我”|y1=”B”),delta1(“E”)=P(y1=”M”)P(x1=”我”|y1=”M”),delta1(“S”)=P(y1=”E”)P(x1=”我”|y1=”E”),
并设 kethe1(“B”)=kethe1(“M”)=kethe1(“E”)=kethe1(“S”)=0;
同理利用公式分别计算:
delta2(“B”),delta2(“M”),delta2(“E”),delta2(“S”)。图中列出了 delta2(“S”)的计算过程,就是计算:
P(y2=”S”|y1=”B”)P(x2=”爱”|y2=”S”)
P(y2=”S”|y1=”M”)P(x2=”爱”|y2=”S”)
P(y2=”S”|y1=”E”)P(x2=”爱”|y2=”S”)
P(y2=”S”|y1=”S”)P(x2=”爱”|y2=”S”)
其中 P(y2=”S”|y1=”S”)P(x2=”爱”|y2=”S”)的值最大,为 0.034,因此 delta2(“S”),kethe2(“S”)=“S”,同理,可以计算出 delta2(“B”),delta2(“M”),delta2(“E”)及 kethe2(“B”),kethe2(“M”),kethe2(“E”)。
同理可以获得第三个和第四个序列标记的 delta 和 kethe。
到最后一个序列,delta4(“B”),delta4(“M”),delta4(“E”),delta4(“S”)中 delta4(“S”)的值最大,因此,最后一个状态为”S”。
最后,回退,
i3 = kethe4(“S”) =“B”
i2 =kethe3(“B”) = “S”
i1 = kethe2(“S”) =“S”
求得序列标记为:“SSBE”。
总结
HMM 的基本原理和其在分词中的应用就讲到这里了,从上述分析可以看出,HMM 时非常适合用于序列标注问题的。但是 HMM 模型引入了马尔科夫假设,即 T 时刻的状态仅仅与前一时刻的状态相关。但是,语言往往是前后文相互照应的,所以 HMM 可能会有它的局限和问题,读者可以思考一下,如何解决这个问题。
原文链接
https://mp.weixin.qq.com/s/RcMtaBdB2zsmZlVfiM11xA
公众号推荐:
跳进 AI 的奇妙世界,一起探索未来工作的新风貌!想要深入了解 AI 如何成为产业创新的新引擎?好奇哪些城市正成为 AI 人才的新磁场?《中国生成式 AI 开发者洞察 2024》由 InfoQ 研究中心精心打造,为你深度解锁生成式 AI 领域的最新开发者动态。无论你是资深研发者,还是对生成式 AI 充满好奇的新手,这份报告都是你不可错过的知识宝典。欢迎大家扫码关注「AI前线」公众号,回复「开发者洞察」领取。


分布式云行业实践指南(2023)
业内首个分布式云行业实践方法论、工具箱。







评论