

前面介绍过 BERT,作为一种非常成功的预训练模型,取得了非常不错的成绩,那么,他还有改进的空间吗?
本文介绍 BERT 的改进版,XLnet。看看它用了什么方法,改进了 BERT 的哪些弱点。
为什么要有 XLnet?
要理解 XLnet,我们先回顾一下先于 XLnet 的两种表现最好的预训练模型 BERT 和 GPT:
Generative Pre-Training(GPT),采用 Transfomer 作为特征抽取器,预训练阶段采用单向语言模型的模式。
Pre-training of Deep Bidirectional Transformers for Language Understanding(BERT),同样采用 Transfomer 作为特征抽取器,与 GPT 的主要差异在于,在训练阶段,其采用基于 MLM 的双向语言模型。
XLnet 的提出者们,仔细研究了一下这两个模型,发现他们都有自己的缺点。
对 GPT,它主要的缺点在于,采用的是单向语言模型。模型在预测当前词的时候,只能看到该词前面词的信息。而对于很多语言理解任务而言,例如阅读理解等,常常需要参考该词前后的语境,因此,单向语言模型往往是不够的。XLnet 的研究者称 GPT 这一类结构为 AR(AutoRegressive)语言模型。
对 BERT,采用 MLM,即在训练时遮住训练语料中 15%的词(实际的 MASK 机制还有一些调整),用符号[MASK]代替,然后试图让网络重建该词。这个过程,在训练语料中引入了符号[MASK]。而在实际的 Finetune 及预测过程中,是没有这个符号的,这就在预训练和预测阶段之间产生了 GAP。BERT 在 MLM 中还隐含了一个独立性假设,即重建各个符号[MASK]的过程,是相互独立的。这个假设其实是未必成立的,会造成模型训练时部分信息的损失。XLnet 的研究者称 BERT 这一类结构为 AE(AutoEncoding)语言模型。
由此可见,BERT 和 GPT 都有待改进的地方,XLnet 的研究者们的想法是将两个模型结合起来,并改进一些点。下面我们来看看 XLnet 是如何基于 GPT 和 BERT 来做改进的。
XLnet 的改进
1) 预训练模式的优化:Permutation Language Modeling(PLM)
XLnet 想要实现 BERT 的双向语言模型,但是又不想引入 BERT MLM 中的独立性假设和符号[MASK],进而提出了 PLM。
XLnet 中,沿用 GPT 的语言模型的办法,即基于序列中前面部分的内容,预测该词。但是,为了在预测该词的时候,为了能够看到该词后面部分的内容,对序列进行排列组合。这样的话,该词的前面也包含该词后面词的信息,用另外一种方式,实现了双向语言模型。
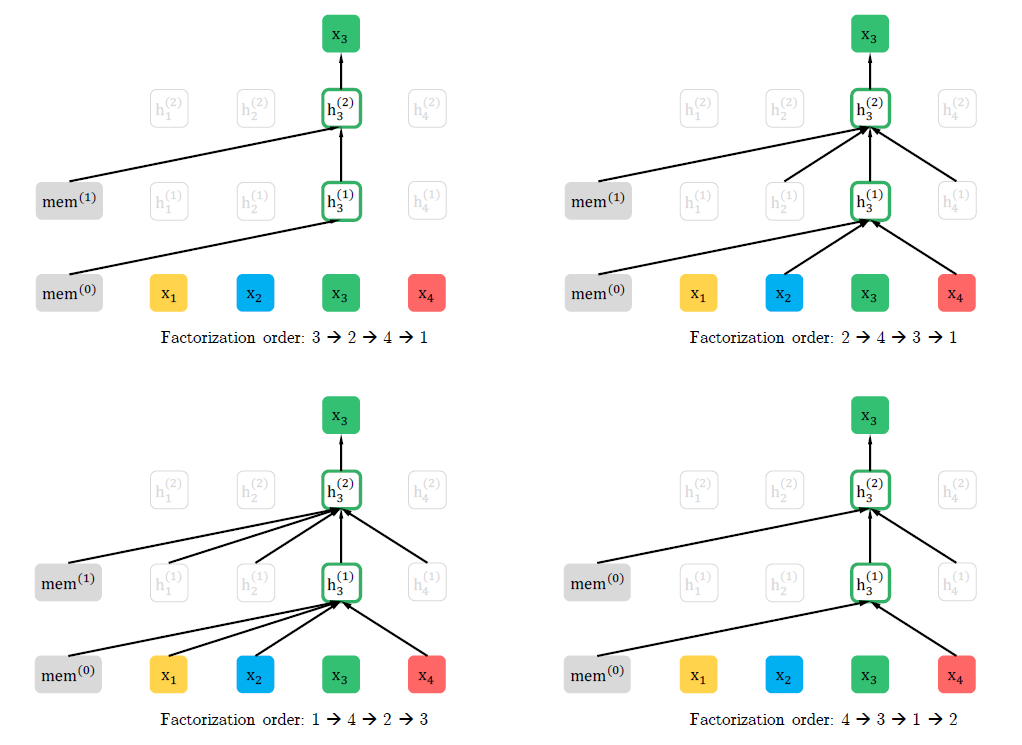
如上图所示,假定输入序列的长度为 4,则除了原语序,这 4 个词总共有 24 种排列方式,上图中用各词在原序列中的位置来表示各词,列出了其中 4 种,[3,2,4,1],[2,4,3,1],[1,4,2,3],[4,3,1,2]。
有同学会疑问,对于 Transformer 这种特征抽取器来说,在不加掩码的情况下,不管输入序列按照哪种顺序输入,效果应该都是一样的才对。
没错,因此 XLnet 还引入了 Two-Stream Self-Attention,双流自注意力模型。
所谓双流就是输入包括了两种,训练句子和相应的位置信息,下面看看具体是怎么组织起来的。
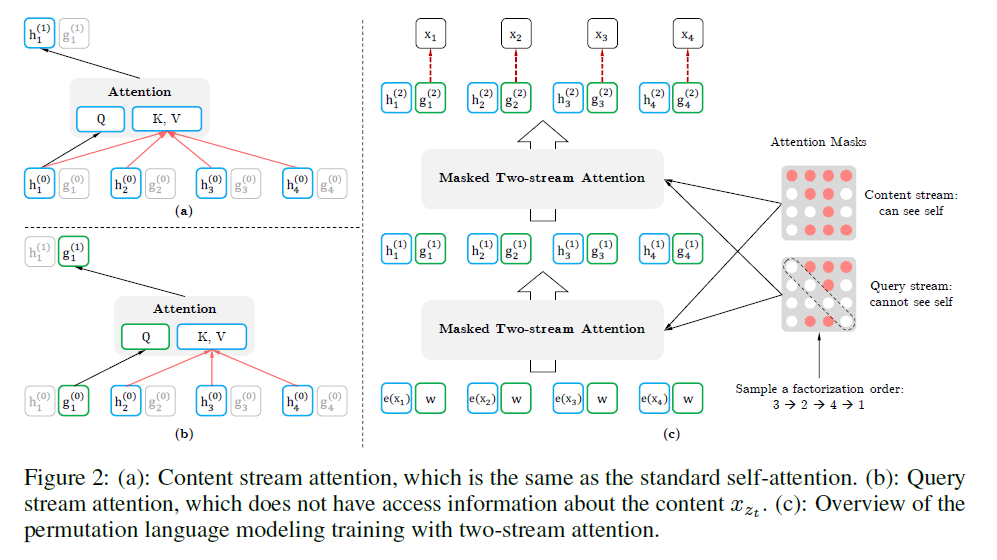
如上图所示,输入包括两种类型,query stream 和 content stream。
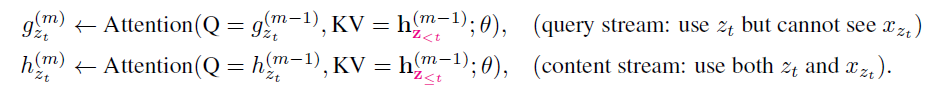
1.query stream 仅仅包含输入序列中预测位置前面的词 x_(z<t),以及该词在原序列(未重新组合前)中的位置 z_t 信息,但是不包括 x_(z_t)。
2.content stream 跟普通的 transformer 输入一致,包括 x_(z_t)及 x_(z<t)。
通过双流注意力机制,可以有效的学习到双向模型的表征。
2)特征抽取器的优化
在结构上,XLnet 采用改进后的 transofmerXL 作为特征抽取器。前面讲过 TransformerXL,他主要有两个优化,一个引入了序列循环机制;一个是引入了相对位置编码。
对于相对位置编码,在 XLnet 中的应用与之前在 transformer 的应用别无二致;对于序列循环机制,这里介绍一下在 XLnet 中是如何应用的。
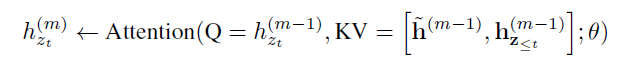
如上面的公式所示,其实在 XLnet 中,attention 计算与 TransformerXL 中类似,也是将前一个序列中上一层的隐藏状态,与本序列中上一层隐藏层状态拼接起来。
总结
XLnet 是一个集合了目前两大预训练模型的优点,其效果自然不会差,目前其在各个任务中的表现都要优于 BERT。
XLnet 接过 BERT 的棒,把预训练模型再往前提升了一步。可以遇见,后续 NLP 预训练还会不断有新的模型出来。

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论