

4.3 动态更新索引
为了保持不变性的前提下实现倒排索引的更新,通过增加新的补充索引来反映最近的修改,而不是直接重写整个倒排索引。每一个倒排索引都会被轮流查询到,从最早的开始,查询完后再对结果进行合并。
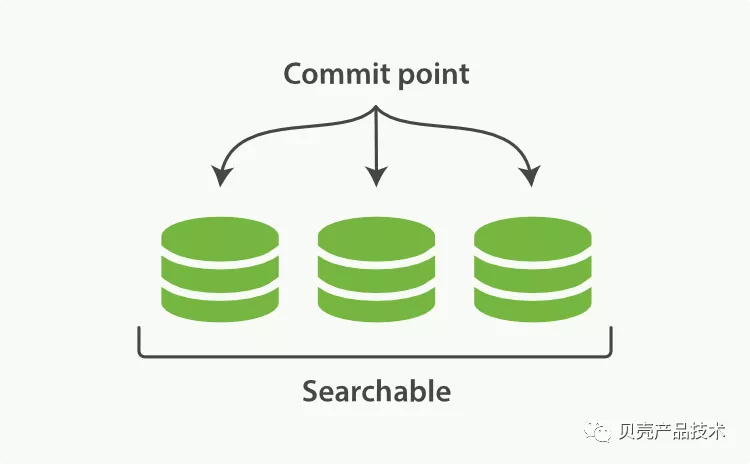
索引在 Lucene 中除表示所有段(segment)的集合外,还增加了提交点的概念,一个列出了所有已知段的文件,从上图中可以看出一个 Lucene 索引包含一个提交点和三个段。
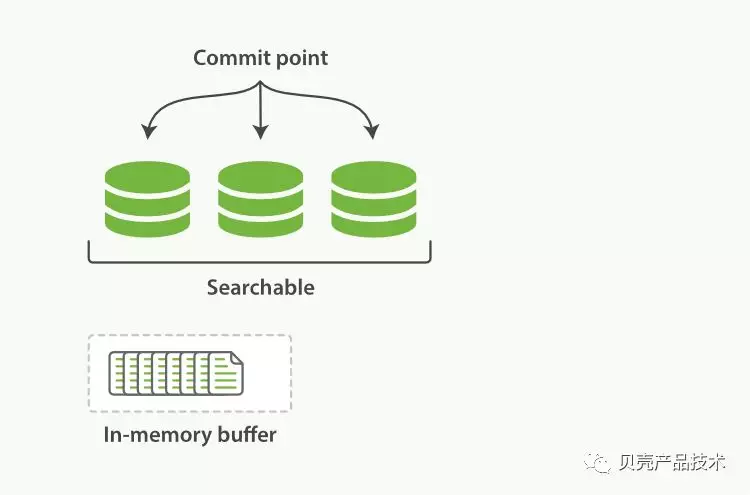
新的文档会被收集到内存索引缓存(In-memory buffer)中。
5 近实时搜索
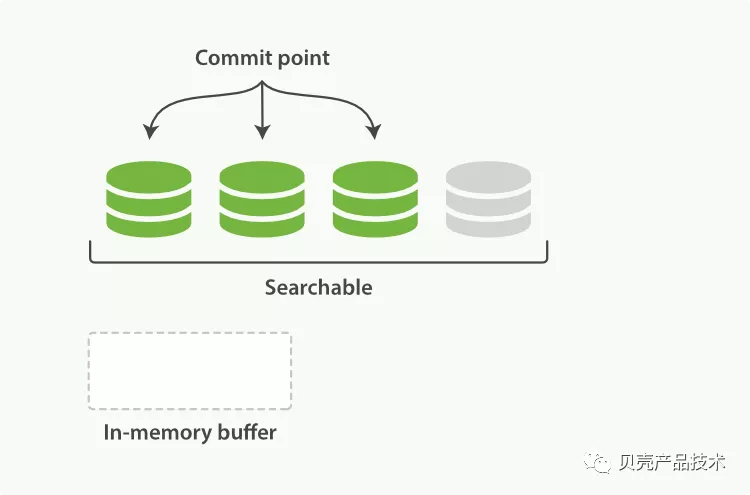
若涉及到磁盘,就有一个不可避免的影响效率问题,对于实时性要求比较高,如果没有这步处理方式,实时性是不够的,所以这步的操作还有个中间状态:
1)内存索引缓存生成一个新的 segment,先是刷到文件系统缓存中,Lucene 这个时候是可以检索这个新的 segment 的;
这一步刷到文件系统缓存的步骤,在 Elasticsearch 中,是默认设置为 1 秒间隔的,对于大多数应用来说,几乎就相当于是实时可搜索了。refresh 接口中,可以通过设置 refresh_interval,调整每个索引的刷新频率。
6Translog 提供的磁盘同步控制
保证这期间发生主机错误、硬件故障等异常情况,数据不会丢失。
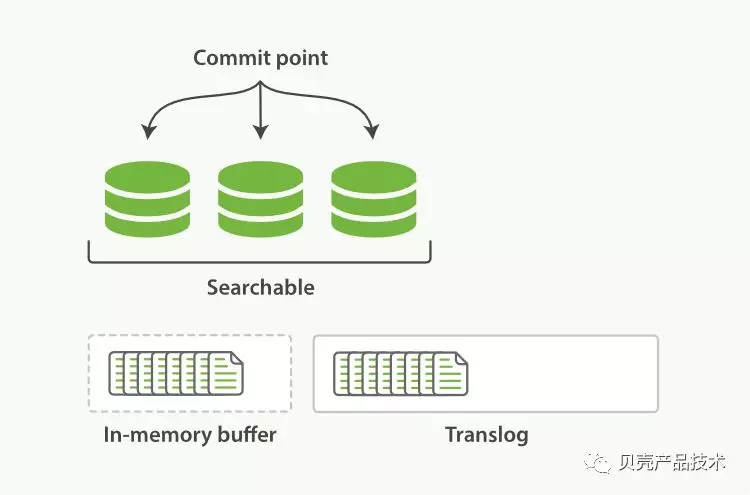
Refresh 只是保证写到文件系统缓存,而写到磁盘这通过这步的操作来控制的。ES 把数据写到内存缓存的同时,其实还同时记录了一个 translog 的日志数据。refresh 发生的时候,translog 日志文件依然保持原样。
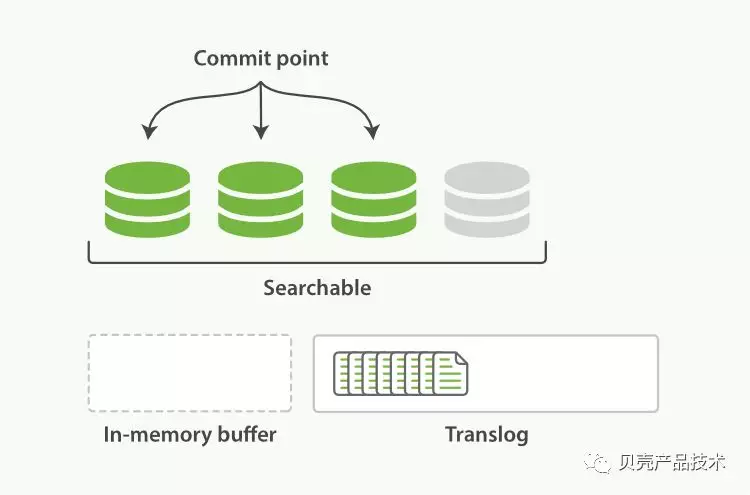
Refresh 完成后, 缓存被清空,但是事务日志不会。在这期间发生异常,ES 会从 commit 位置开始,恢复整个 translog 文件中的记录,保证数据一致性。Translog 文件要等到 segment 刷到磁盘,而且 commit 文件更新的时候,才能清空。
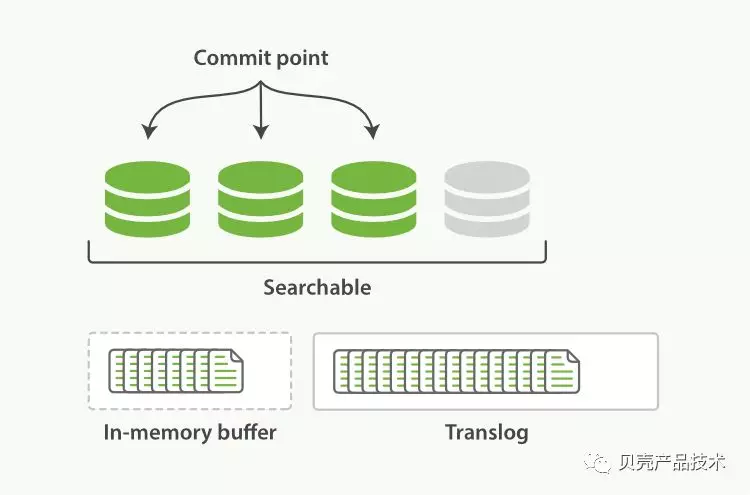
以上的进程会继续工作,更多的文档被添加到内存缓冲区和追加到事务日志,事务日志不断积累文档。
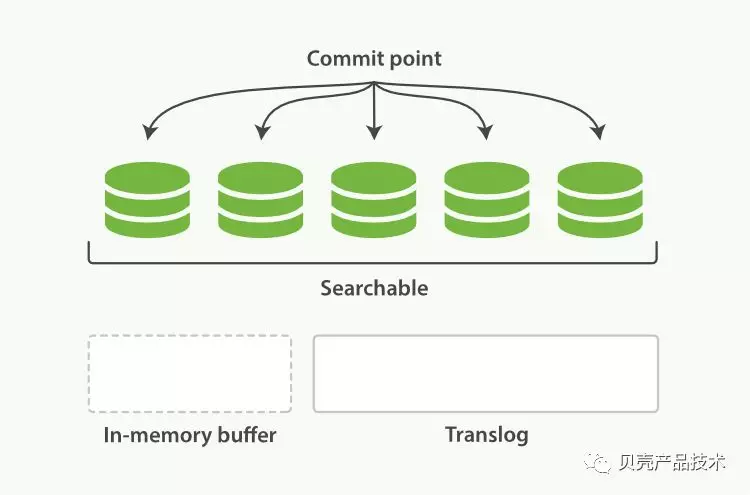
Translog 变得越来越大,索引被执行 flush;一个新的 translog 被创建,并且一个全量提交被执行。在 flush 之后,segment 被全量提交,并且事务日志被清空。执行一个提交并且截断 translog 的行为被称一次 flush,默认参数 30 分钟一次 flush,或者 translog 文件大小超过 500M 的时候,可以调整以下参数:
7Translog 的安全性
文件被 fsync 到磁盘前,被写入的文件在重启之后就会丢失。默认 translog 是每 5 秒被 fsync 刷新到硬盘,或者在每次写请求完成之后执行。在 2.0 版本以后,为了保证不丢数据,每次 index、bulk、delete、update 完成的时候,一定触发刷新 translog 到磁盘上,才给请求返回 200。这个改变在提高数据安全性的同时当然也降低了一点性能。设置如下参数:
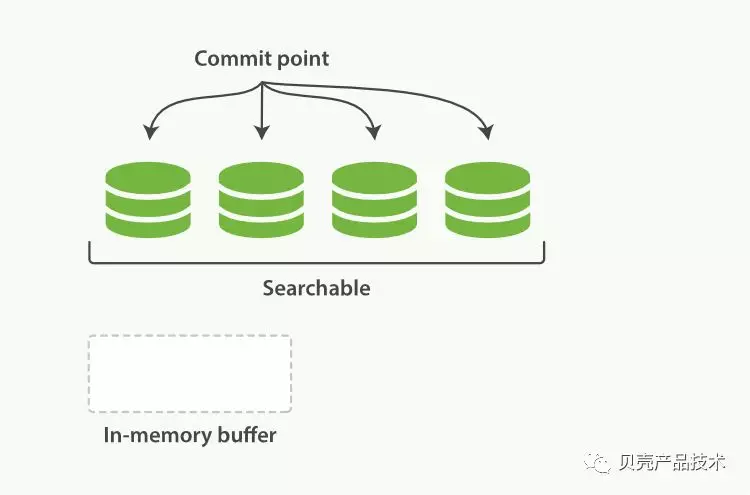
文件系统缓存被提交,新的段被追加到倒排索引序列后面,新的段被开启,而且可以被搜索,此时内存缓存被清空,等待接受的文档。
8 段合并(Segment merging)
自动刷新流程每秒会创建一个新的段,段的数据会暴增,段太多会消耗文件句柄、内存和 CPU 运行周期,这样导致段越多搜索就越慢。
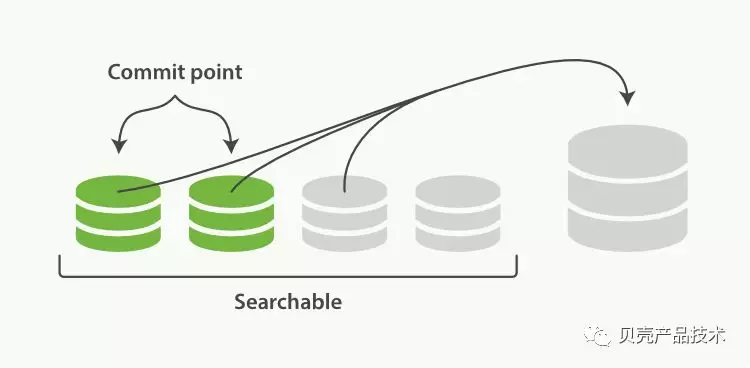
为了解决这个问题,利用小的段合并到大的段,然后继续合并大的段,合并过程中会把已删除的文档从文件系统中清除,这个过程是自动运行的,开发人员无感知。图中可以看出来将两个提交了的段和一个未提交的段正则进行到一个更多的段中。这个阶段如果有索引,刷新操作会创建新的段并将段打开,并提供给搜索使用,在合并过程中不会中断索引。
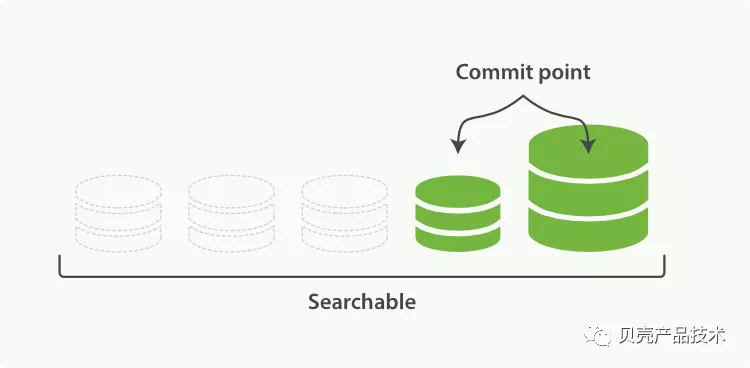
合并结束的时候,老的段将被删除,新的段将被打开用于搜索。合并大的段需要消耗大量的 I/O 和 CPU 资源,如果大的 segment 一直合并会影响搜索性能。默认对合并流程进行资源限制,optimize API 大可看做是强制合并,会指定大小的段的数量,通过检索段的数据来提升搜素性能。
9 存储文件类型和格式
9.1 存储类型
默认文件系统的实现为 fs,以下部分列出了支持的所有不同存储类型:
1)fs
将根据操作环境选择最佳实现,该操作环境目前 mmapfs 在所有受支持的系统上,但可能会发生变化。
2)simplefs
Simple FS 类型是 SimpleFsDirectory 使用随机访问文件直接实现文件系统存储(映射到 Lucene )。此实现具有较差的并发性能(多线程将成为瓶颈)。niofs 当你需要索引持久性时,通常最好使用它。
3)niofs
NIO FS 类型使用 NIO 将分片索引存储在文件系统上(映射到 Lucene NIOFSDirectory)。它允许多个线程同时从同一个文件中读取。由于 SUN Java 实现中存在错误,因此不建议在 Windows 上使用。
4)mmapfs
MMap FS 类型 MMapDirectory 通过将文件映射到内存(mmap)来将分片索引存储在文件系统上(映射到 Lucene )。内存映射使用进程中虚拟内存地址空间的一部分,等于要映射的文件的大小。在使用此类之前,请确保您已经拥有足够的 虚拟地址空间。
默认情况下,Elasticsearch 完全依赖操作系统文件系统缓存来缓存 I/O 操作。可以设置 index.store.preload 以便在打开时告诉操作系统将热索引文件的内容加载到存储器中。但需要注意,这可能会减慢索引的打开速度,因为它们只有在数据加载到物理内存后才可用。
9.2 文件格式
Lucene 负责写和维护 Lucene 索引文件,而 Elasticsearch 在 Lucene 之上写与功能相关的元数据,例如字段映射,索引设置和其他集群元数据。找到 Lucene 索引文件之前,让我们了解下 Elasticsearch 编写的外部级别数据。
10 启动 Elatisearch 时生成的文件
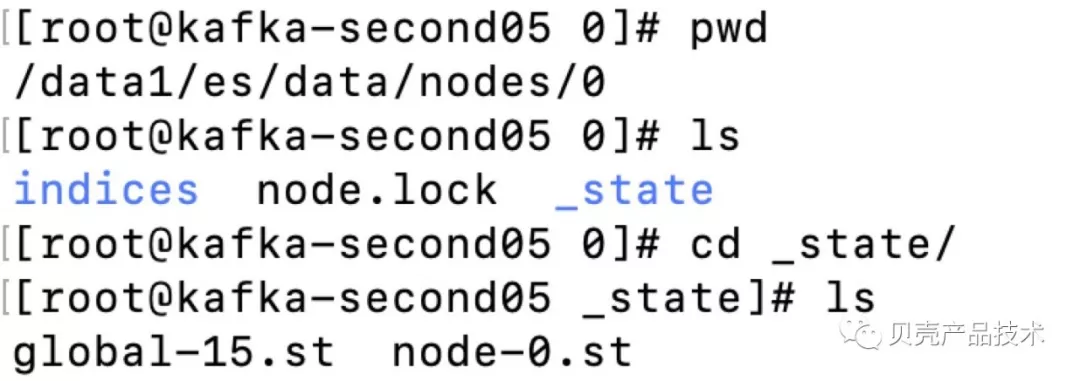
1)图中的路径/data1/es/data/nodes/0,这部分(/data1/es/data)在每个节点可以通过 elasticsearch.yml 配置 path.data 即可,可以多目录,不过多目录没有 rebalance 功能。nodes 是恒定的文件夹名。
2)node.lock 文件用于确保一次只能从一个数据目录读取或写入一个 ES 相关安装信息。
3)global-15.st 文件。global-前缀表示这是一个全局状态文件,
4)而.st 扩展名表示这是一个包含元数据的状态文件。
11Lucene 中文件命名
/data1/es/data/nodes/0/indices 目录的下一级目录是 index 的 uuid,再下一级是分片 id,如图下图所示的 tree 型图中,第一级就是 uuid。

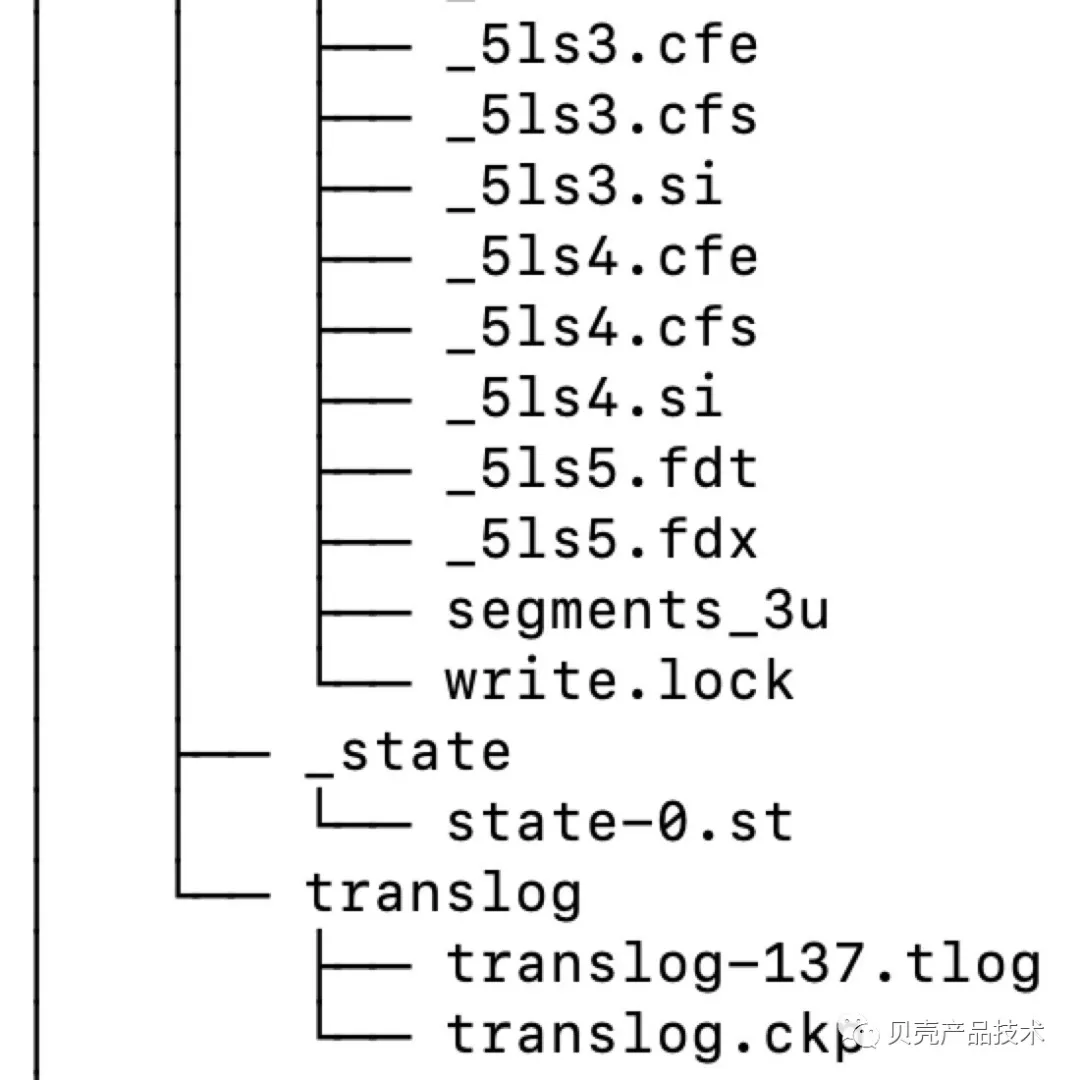
个段的所有文件具有相同的名称,有不同的扩展名。当使用复合索引文件的时候,这些文件将被压缩成单个.cfs 文件。保存磁盘的时候,会创建一个从未使用过的文件名字。下表总结了 Lucene 中文件的名称和扩展名。
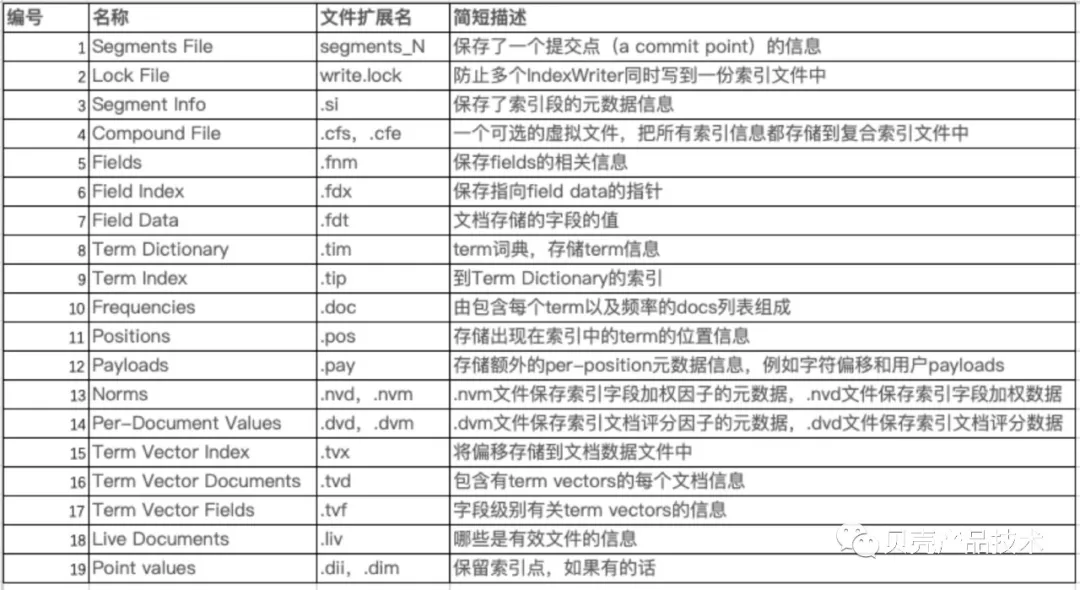
索涉及相关的文件格式的流程,在贝壳智搜发布的《搜索原理和 lucene 简介》中有详细的介绍,这儿就不过多阐述。
12 内容总结
本文对提出的问题进行分析底层原理,以上内容原理属于 ES 核心基础的其中一部分,对实时查询大数据级的需求可以很好的支持,能了解存储和查询的的内部运行原理,对于理解内部原理有很好的帮助。如果对以上内容讲解不是很清楚,可以参考《ES 官网》文档进行分析理解。
作者介绍:
喜羊羊(企业代号名),目前负责贝壳找房实时方向平台建设及大数据应用拓展。
本文转载自公众号贝壳产品技术(ID:gh_9afeb423f390)。
原文链接:
https://mp.weixin.qq.com/s/25BW6ll9m1KA7hhUUE2PLw

Java 避坑指南:Java 高手笔记代码篇
本迷你书包括 86 个业务开发中常见踩坑点。每一个知识点都相当的实用,是程序员业务开发中的必备避坑指南...











评论