
导读
第一章机器学习与大数据,主要阐述为何要跨上大数据的战车,会分以下四个课时进行详细讲解:
① 机器学习可能吗?为什么机器能够学习?
② 机器学习如何做?机器通过怎样的步骤把知识从现实世界中学到?
③ 大数据的价值。不同于外面夸夸其谈的大数据的价值,这里会从一线工作者的角度,谈一谈大数据对机器学习和人工智能意味着什么。
④ 跨上大数据战车。最后,我们将从商业和应用的角度阐述,为什么各行各业的企业都想跨上大数据的战车,大数据可以为业务带来哪些好处,以及如何利用这些好处改造业务?
下面,首先来看一看,机器学习可能吗?
人类如何学习?

回答这个问题之前,我们先看看人类是如何学习的。人类有个特点,就是发明创造新事物的时候,往往会从自然界寻找灵感。举个例子:人类发明了飞机,可以让人在天空中飞,这个灵感就来自于人类发现飞鸟可以在空中飞翔。同样,如果想让机器学习知识,可以先想一想人类是如何学习的?人类的学习过程从远古时代就已经开始了,举个例子,在远古荒昧无知的时代,有这样一个原始人,他在经历乌云狂风时,发现每次乌云狂风之后都会下暴雨,当他吃过几次亏之后,就会长一智,知道在乌云和狂风之后会下雨,所以每当乌云密布狂风不止的时候,他会找个山洞避一避,就不会被雨淋到。通过这个例子说明,人类是通过现实世界中发现的一些有规律的具体案例来进行学习的。这个学习过程可以分为两个步骤:第一步是归纳,第二步是演绎。如何解释这个过程?还是刚才的例子,这个原始人归纳的本质性规律是乌云和狂风之后会下雨,当他在遇到乌云密布狂风不止的时候,他就会根据这个规律,知道一会儿可能要下雨,所以这时他会找地方避雨,这就是演绎。刚刚是原始人的例子,对于现代人也一样,我们掌握的大量各种各样的知识,都是通过这样的过程。以人类学习加法为例,大家想一想人类是不是把所有加法的具体案例都记下来了?比如记下来 1+1=2、9+8=17、56+32=88 等等,这样的加法案例是无穷无尽的。其实我们并没有把所有的案例都记下来,才学会加法的,可能随便说两个数字,人类都能知道答案。那么人类是如何进行这种知识学习的呢?我们是通过一些案例,抽象出一个本质的规律:加法法则,并且两个部分,第一部分死记硬背 10 以内的加法,然后对于 10 以上的加法,利用加法法则去计算,加法法则也很简单,大家可以看右侧的 case,两个数字列出来之后,每一位进行对应,那么对应之后,每一列为 10 以内的一个加法,这就跟我们 10 以内的加法是一样的,唯一多了一条规则,就是两个数相加是可以进位的。比如 8+3=11,那除了个位数变成 1,它的十位会再进一位出来。人类就是靠着对这些案例的抽象总结来进行学习的。那我们看一看,我们已经知道了人类是这样学习的,就是归纳和演绎,那这样的步骤真的靠谱吗?
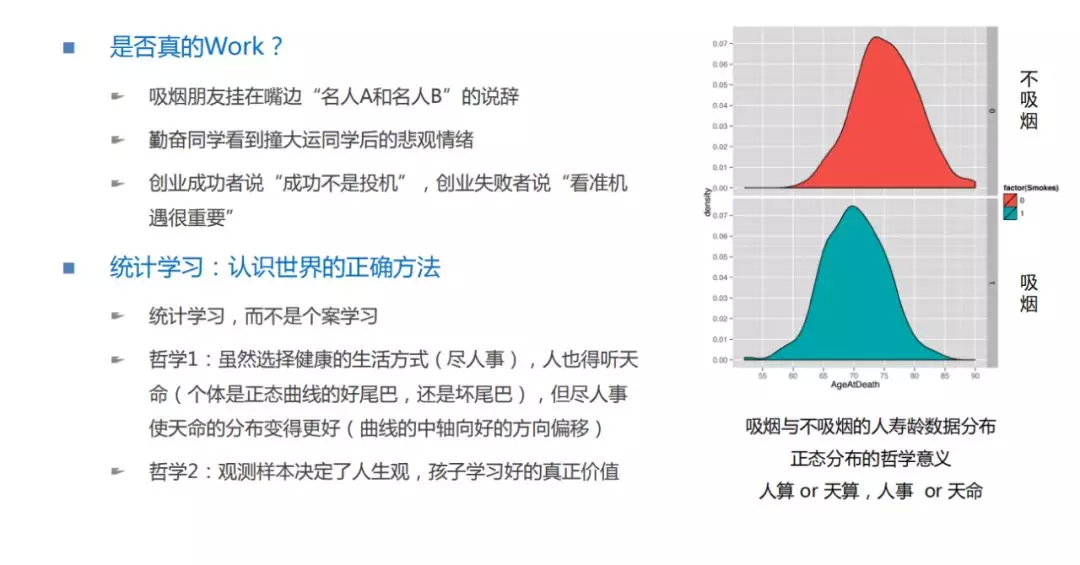
① 在这里,跟大家分享一个我个人的亲身经历。我是来自于东北的,每次回老家的时候都会有碰到一个非常要好的发小。这个发小每次跟他一起吃饭的时候,他都会吸烟,我就劝他不要吸烟,吸烟是有害健康的。但令人崩溃的是,他总会举这样的例子,他说你看名人 A 又吸烟又喝酒,活到了 80 多岁。但你看名人 B 既不吸烟,也不喝酒,然后 50 多岁就没了。所以他说,你劝我吸烟有害健康这个事儿是没有道理的,我每次都会被他用这个例子回绝。直到我发现“统计”之后,才很好的反驳了他。大家想一想,刚刚我举的例子,其实发小的学习,也是正常人归纳和演绎的一个过程,对吧?他是看到一些名人的生存情况,归纳出一个本质规律,爱吸烟是不影响人的寿龄的。
② 这样的 case 还有很多,比如原来有位同学上学期间非常勤奋,但是毕业之后,看到周边的同学有的嫁入豪门,有的进入 BAT 这样的互联网公司有了很好的发展,或者有的同学评运气中了千万大奖。这时,他可能会产生一种悲观情绪,就是他通过这些案例发现周围同学都是时运大于个人努力。
③ 还有一个经常被大家谈论的事情,我经常会跟一些创业者聊各种各样的业务,我发现一个很有意思的事情,当面对成功的创业者时,他往往认为成功不是投机,是努力的结果。而当面对失败的创业者时,他则会认为看准机遇更重要。那么对于创业到底是努力的成分大,还是机遇的成分大呢?
解答上述这些问题,我们需要引入一个正确认识世界的方法,就是统计学习,而不是个案学习。以刚刚吸烟的案例,来说明下。大家可以看右边这张图,一共做了 3000 个样本的统计,其中 1500 个样本是吸烟的人,另外 1500 个样本是不吸烟的人,图中画出来的是吸烟和不吸烟人群的寿龄分布。通过这两张图的比较,我们会发现,即使一个人不吸烟,他可能只活了四五十岁;而一个吸烟的人,他反而可能会活到八九十岁。但是,从统计的分布中线来看,吸烟的人要比不吸烟的人平均寿龄少五岁左右。这说明,虽然我们要通过观察一些案例,用归纳的方式去总结这个世界的规律,但是一定要基于统计,大量的案例观察去学习,而不是从一些个案中去学习。另外,这张图还蕴含了更深刻的哲理,比如我们有句老话叫“尽人事听天命”。那么在分布图中,什么是人事,什么是天命呢?“人事”就是选择哪条正态曲线,“天命”就是正态曲线上的“尾巴”。那么“尽人事听天命”如何理解呢?“尽人事”说明我们需要好好努力的生活,选择正确的生活方式,不去吸烟,就需要选择这上面比较好的分布。“听天命”是什么呢?即使人们选择了很好的分布,但是也不能保证一定会活很久。即使是这样,人们又不能不“尽人事”,否则会掉到一个更差的分布中去。这就是“尽人事听天命”在统计学上的一个理解。
刚刚跟大家分享的哲学含义,可以应用到更多的案例中,比如创业成功者和失败者对事物的不同看法,也可以通过统计分布去理解,我们的努力与否,是否把每件事尽可能的做到极致,这其实就是在选择是否能成功的一个更好的分布。但是,即使在更好的分布中,最后是否成功,还要看机遇,把我们留在“好尾巴”还是“坏尾巴”。现实中,非常成功的这些互联网企业,不仅仅处在非常好的正态分布中,还处在正态分布的“好尾巴”上。所以创业能否成功这件事情,既是努力选择治好的正态分布的过程,也是靠机遇得到正态分布中“好尾巴”的过程。
除了“尽人事听天命”的统计学理解之外,我们还可以看到更多的哲理。刚刚那位勤奋同学通过观察对周围同学毕业后生活情况的案例,产生了悲观情绪,这说明了什么事情呢?就是人类是靠看到了大量的样本案例来学习对这个世界的认知和知识的,也就是说我们对世界观测的样本决定了我们的人生观和世界观。尤其对于小孩来说,让他们观测到一些正确的样本,是对其形成正确世界观的一个非常决策性的事情。所以,对于孩子学习来说,真正重要的不是学习好或不好,而是孩子通过学习好,可以观测到一些正确的样本。当一个孩子每次通过努力学习的方式能够使学习成绩提高,这是一个非常正向的学习样本,这会让孩子体会到“一分耕耘,一分收获”,那么他的人生观就是正向的,这会让他不仅仅在学习上,在处理人生的很多问题上,也会相信经过自己的努力可以改变这个世界的一些事情。但是这个过程,如果孩子学习不好,他就没有观测到亲身经历过的一些正样本,这会对他的人生观产生消极的影响。所以我们对小孩学习好或不好,不止代表学习好就能考上好大学,更重要的一点,是孩子在学习好这个过程中,他观测到了这个世界上更正确的一些样本,以及形成了一个更加积极的人生观。
整个这一篇的内容,其实是在和大家分享一个事情,就是人类的学习是靠归纳和总结出本质的规律,以及进行演绎,预测到现实中没有发生的一些事情,但是这个过程中我们不能通过个案去进行,一定要通过大量的案例观察,以统计学习的方式去进行。
那么接下来我们看一看“统计学习”真的靠谱吗?会不会存在一些问题?
我们能相信统计么?
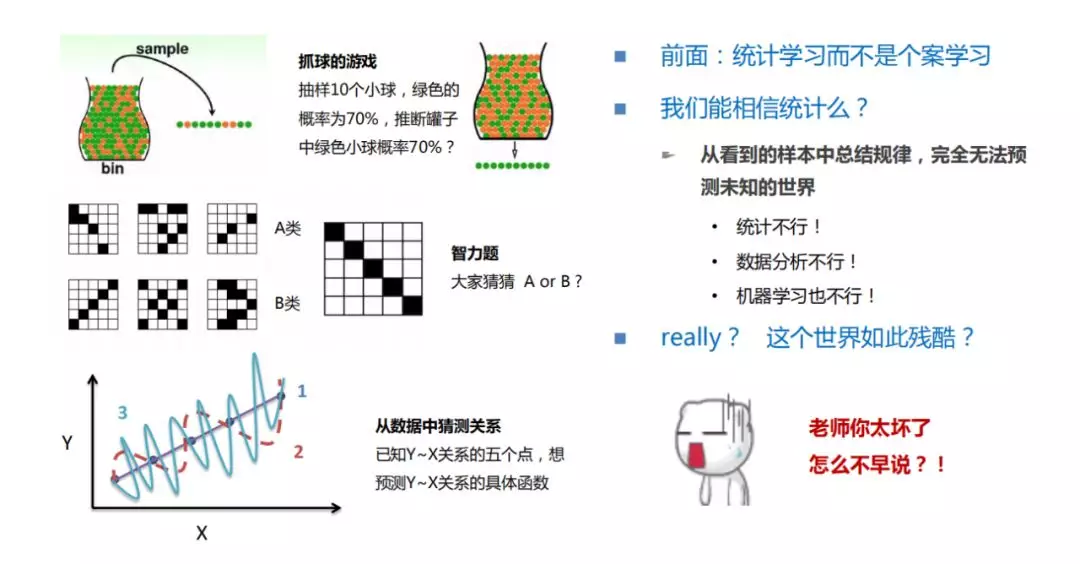
案例 1:有一个罐子,罐子中有两种颜色的小球,分别为绿色和黄色。当从罐中随意抓出来一把,发现有十个小球,其中有七个是绿色的,有三个是黄色的。这里想问大家一个问题,就是大家会不会判断罐子中绿色小球的概率有 70%?这是第一个问题,大家可以稍微思考下。
案例 2:这里有 6 张图,上面 3 张一组,下面 3 张一组,上面一组有一个本质的规律,称为 A 类。下面一组也有一个本质的规律,称为 B 类。问题是,当我拿出这张新图的时候,它是属于 A 类还是 B 类?大家同样可以简单思考下。
案例 3:已知,X 和 Y 之间存在着一定的关系,其上有五个点,分布情况如图所示。大家猜测一下 X 和 Y 之间是什么样的关系?
现在说一下三道题的答案。对于第一道题,相信大部分的同学都能作出这样一个判断:虽然抽出来的 10 个小球中有 7 个是绿色的,有 3 个是黄色的,但是我们不好去判断整个罐子中的一个情况,对吧?因为我们抓出来的 10 个小球不能够代表整个罐子中小球的情况。对于第二道题来说,可能有的同学会说它应该属于 B 类,因为 B 类每个图形都是对称的,然后这个新的图形也是对称的,所以会判断它应该属于 B 类。但我要跟大家说的是第二道题,答案是 A 类。为什么是 A 类?因为大家可以看到 A 类每个图的中心都是黑色的,这个新图的中心也是黑色的,所以它是 A 类。但是如果有同学说他一开始选择的也是 A 类,其实这也是错的,因为 B 类每个图都是对称的,而新图也是对称的。也就是说通过已有经验观测得到的结论,其实是没办法得知真实情况的。再来看第三道题。很多人可能会猜测 X 和 Y 之间的关系应该是一条直线。这其实是错的,因为它是一条曲线,只是这条曲线正好经过这五个点而已。那如果有同学说,一开始就认为是条曲线,那为什么不是一条更曲的曲线或者是一条直线呢?
通过这几个令人崩溃的例子,跟大家说明一件事,就是一定要通过统计去学习,而不是一些个案去学习。但是我们还发现,对这个世界进行一些抽样的观测的案例,再通过这些案例去推测这个世界背后的本质规律,其实是行不通的。对吧?第一道题是拿出了一些小球,通过这些小球的一个分布,去推测罐子中的情况。第二道题,通过观测一些题目的样本规律,来推测其背后的规律也是不行的。第三道题,通过观测 X 和 Y 之间的一些观测点数据,也是没办法推测 X 和 Y 之间的关系?这就比较令人恼火了,统计不行,数据分析也不行,那机器学习是不是也不行?这个世界真的是这么残酷吗?
这里要跟大家说明下,正常情况下,我会在整个系列课程的中间位置来跟大家介绍这方面的内容,但是有的同学跟我说,老师,下次调整一定要把这个案例调整到最开始,因为当你知道这件事的时候,你会说哎呀,老师你真是太坏了,早点说这个事儿,我一开始就不学了,都已经学一半了,没办法,只能继续学下去,所以这次调整我就把这个案例放在一开始。但是大家不要灰心丧气,其实这个世界背后有一些更本质的规律,可以保证通过统计是可以学习到知识的,这个保证就是大数定律。
基于概率的信任

刚才之所以会发生让大家崩溃的一些案例,是因为我在整个事情的背后扮演了上帝的角色。但是这个世界如果有上帝的话,其实是没有这么险恶的。他设定了宇宙所要遵守的一些更本质的规律。其中,有一种本质规律就是抽样统计值和真实事件之间会存在一种数学关系,这个数学关系可以用大数定律来表达。对于大数定律,大家在中学应该都学过,就是当实验或观测的数量足够多的时候,根据观测得到的统计概率会无限接近于该事件发生的真实概率。这里要说的一点是,我们对大数定律的理解,要早于科学家真正的发现这一定律。从远古时代,大数定律的运用就隐藏在每个人对世界的理解中了。举个孔子时代曾参杀人的典故。当时孔子有一个非常贤能的学生叫曾參,有一天,跟曾參同名同姓的人在他的家乡杀人了,然后他的邻居们就不断的传这个事情。这时,有一个人来找曾母,说你儿子杀人了,你怎么不赶紧跑(在古代,犯罪之后是要连坐的)?此时曾母并不相信,他说你看我儿子这么贤能,他怎么会杀人?你们肯定是在胡说,我不相信。然后她继续淡定的织布,过了一会儿,来了第二个人跟曾母说,你儿子杀人了,这时曾母虽然表情非常淡定,但实际上心里已经开始打鼓了,当第三个人对她说,你儿子杀人啦,你怎么还在这?之后呢,曾母立刻扔下织布机,翻墙逃跑了。孔子知道了这件事之后,对曾母进行了非常严重的批判,说三人成虎,一则无心,二则疑,三则信矣。那么今天要做的就是为曾母进行翻案,大家可以看到,其实曾母并不是不相信他的儿子,曾母是在基于自己对大数定律的理解而作出的判断。当一个人说儿子杀人的时候,那么他杀人的概率可能还不是很大,但是当随着观测到的样本不断增多的时候,当周围所有的人都说儿子杀人的时候,那么他没杀人的概率其实就非常低了,这就是大数定律。我们工作中,建模的经验也是这样,一开始往往会对某个问题有些领域的认知,然后把这些认知变成一种人工的规则,但是随着获得的数据样本逐渐增多,往往都会倾向于之后的规律变成一个学习的模型,基于这些数据来进行判断,而不完全是之前历史的人工的经验。
大数定律的数学表达,可以用下面的不等式来表示:
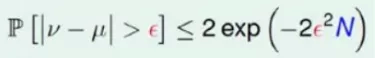
关于这方面的不等式有好几个,这里只以某一不等式来跟大家介绍下大数定律限定的表达。
不等式的左边其实是一个概率,v 代表统计值,μ 代表真实值。μ-v>ϵ 这个概率说明 μ 和 v 存在一定差距的概率。不等式右边,N 是观测样本,随着观测样本的增多,右边式子是趋近于 0 的,代表了左边 μ 和 v 产生一个比较大的差距的概率是趋近于 0 的,也就是说当观测样本足够多,统计值跟真实值是非常接近的。通过对大数定律的理解会发现,我们对这个世界的认知跟普通人不一样的。观测到绿色小球的概率是 70%,这是普通人的一个认知。真正的统计学家的认知是这样的,他会说真实的概率以 90%的可能在 65~75%之间,这样认知世界的方式,我称它为基于概率的信任。就是,我既不是相信,也不是不相信,而是以概率的形式去相信,这又叫做 PAC(Probably Approximately Correct)Learning,可以看到这个词跟之前可以对应上,就是我们相信它是以一定的概率在某个观测值的附近波动。
除了统计学家通过基于概率的信任的方式认知世界外,通过大数定律观测到的样本越多,得到统计的结论就越置信,这会联系到后面对大数据价值的讲解。
最后回顾下案例 3,基于大数定律,X 和 Y 之间的关系,是直线的概率要比曲线只是在抽样的时候正好经过这五个点的概率要大的多。所以如果随机选择一百个点,抽样之后它们之间的关系呈现的就是线性的,那基本可以 100%确定,它们之间就是一个线性关系,而不是一条曲线,正好经过这一百个抽样点。
通过这些案例和逻辑,我希望可以向大家清晰的介绍下,机器学习为什么能够学习。首先,它抄袭了人类学习的方式(归纳+演绎),但是这个过程中个案学习是不行的,必须统计去学习。而统计学习是基于什么原理?是基于大数定律,基于概率的信任来学到知识。
接下来,当机器可以去学习的时候,该怎样一步步地确保机器能够学到这个世界的知识,也就是机器学习如何做?
本文来自 DataFun 社区
原文链接:
https://mp.weixin.qq.com/s/NPS5UqaNVV2cMuht28_8wA

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论