
本文要点
文本到视频模型(Runway、Sora、Veo 3、Pika、Luma)在视频-文本对的大型数据集上进行训练,数据质量直接决定了生成质量(“垃圾入、垃圾出”)。组装和预处理此类数据集是文本到视频生成业务案例的核心工作。
预处理管道由三大阶段组成——场景分割、视频标签和过滤。它们各解决一个具体问题:剪辑太长、缺少字幕以及质量低或损坏的样本。
场景分割通过将视频剪成短的、连贯的片段来为训练准备长视频。使用的工具有 ffmpeg、PySceneDetector 和 OpenCV 等;嵌入(例如 ImageBind)可以帮助合并语义相接的片段。
视频标签为每个剪辑分配一个简洁的文本描述。手动标签可以定义质量标准,而大规模字幕则使用视觉语言模型和 API(Transformers、CogVLM2-Video、OpenAI、Gemini)完成。
过滤会删除损坏的、重复的或低质量的片段和薄弱的字幕。经典的 CV 方法(模糊检测、照明检查、光流)与基于嵌入和基于文本的方法(VJEPA、BERT、TF-IDF)结合使用。
*作者表达的观点是其个人意见,不代表作者雇主的观点,也不是代表作者雇主发表的。
近期文本到视频生成技术的崛起
随着人们对 Runway Gen-2、Pika Labs、Luma AI 等生成式 AI 服务的兴趣日益增长(这些服务根据用户提示创建视觉内容),该技术已经走出了实验项目的范畴,找到了在生产工作流程中的位置。这些基于深度神经模型的解决方案,被提供视频生成服务的公司和生产流程所采用——加速了电视剧和电影的工作,并推动了广告活动创作。
这些模型大多依赖于扩散过程和扩散 transformer,在这个过程中,视频在外部信号——文本、图像或两者的组合的影响下,逐渐从高斯噪声中“显现”出来。这个引导信号的质量直接决定了输出的质量,因为它为模型提供了上下文和清晰的生成目标。
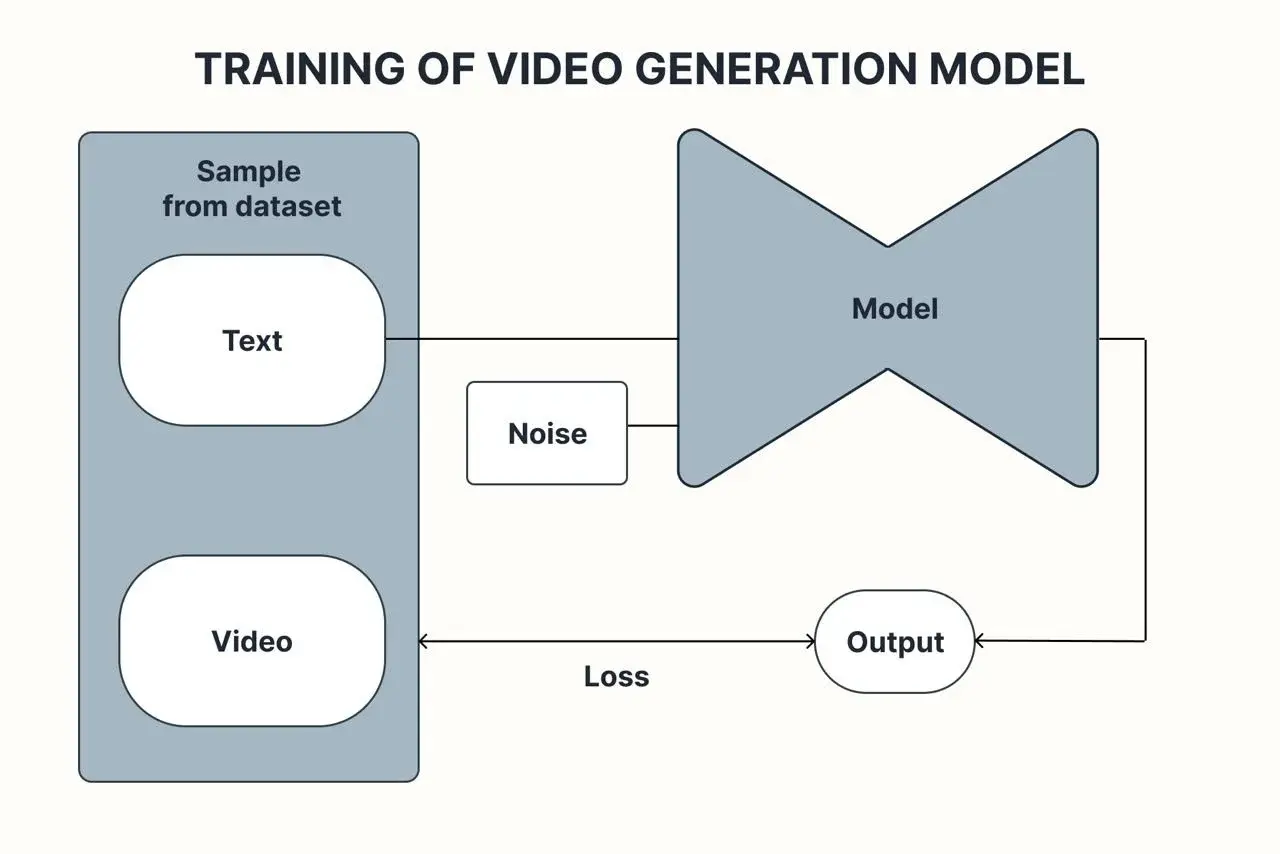
图 1:训练扩散模型过程
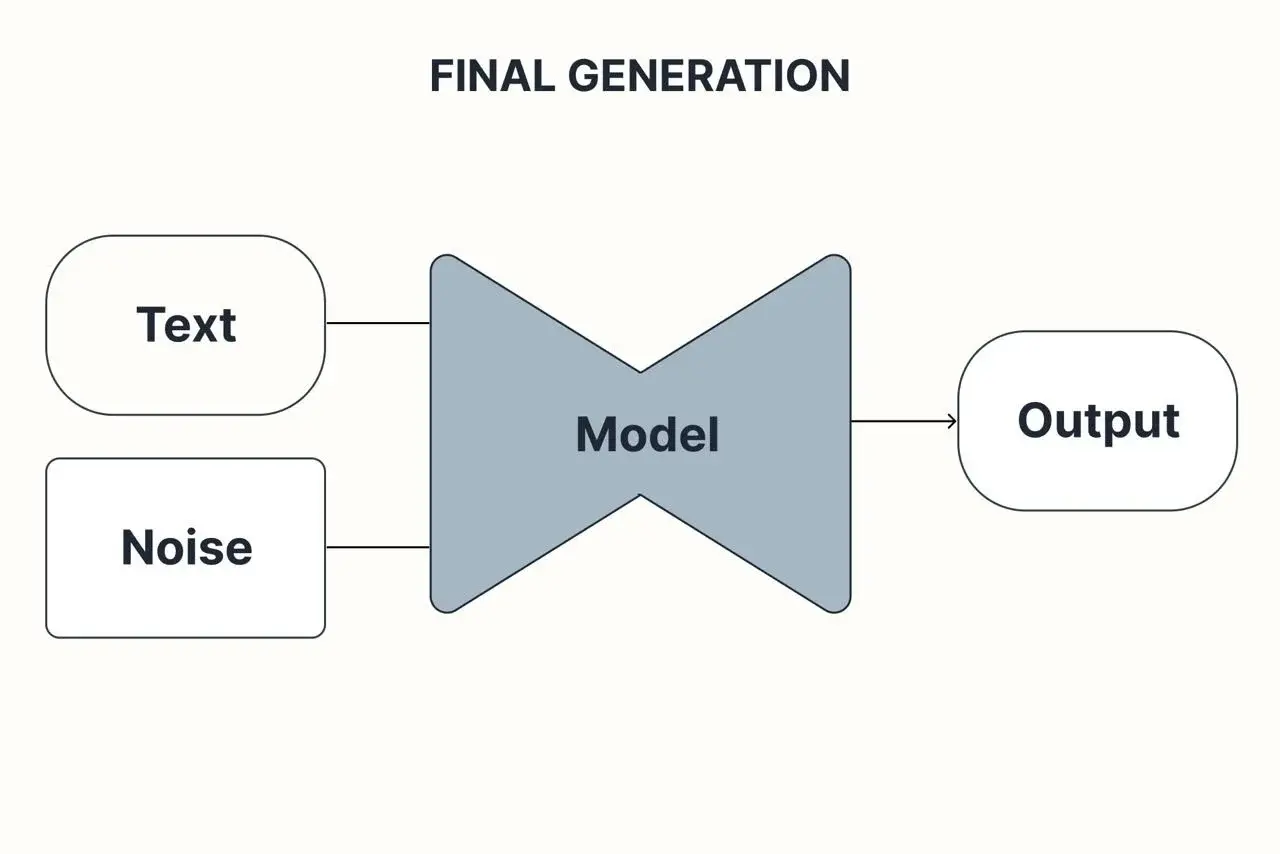
图 2:扩散模型推理
训练是在由视频-描述对组成的数据集上进行的。数据集越大、越多样化,模型就能越好地泛化并提供令人信服的结果。即使是最先进的架构也从更高质量的数据中受益,在这里垃圾进垃圾出的原则完全适用。
本文深入探讨了一个实际的业务案例:为训练生成式文本到图像模型准备数据,这些模型是 Runway、谷歌的 Veo 3、OpenAI 的 Sora 等产品的基础。它解释了数据的准备过程,这一工作可以作为创建自定义数据集以开发专有模型的起点。
鉴于视频制作是一件非常昂贵的事情,企业一直在寻找降低成本的方法。例如,一个拍摄团队和电影明星的一天可能需要花费数十万美元,仅仅为了制作一个五分钟的广告。因此,许多公司开始探索以 AI 驱动的文本到视频生成作为一种更快、更经济的替代方案。近年来,这项技术在广告、电影前期制作和电子学习中越来越多地被采用,帮助团队快速制作概念视频、故事板和营销材料。Runway、谷歌(Veo)和 OpenAI(Sora)等主要参与者已经证明,现在可以直接从文本创建逼真、高质量的画面,大幅降低生产时间和成本,同时开辟了新的创意机会。
数据集创建
评估数据集的质量始于几个关键问题:
它是否涵盖了模型预期生成的视频的全部范围?
视频的质量是否符合目标输出和用户期望?
文本描述是否准确反映了视频内容?
描述应该包含足够的相关细节,关于场景——发生了什么,在哪里以及如何发生——以重建视频的核心元素。
回答第一个问题需要理解模型的业务目标:预期的用例,包括视频的内容和风格。不同的应用需要不同的质量——适合电影的创意资产可能对连续剧制作来说太静态了,而电影和连续剧对广告来说可能节奏太慢。
一旦目标被定义,就可以为数据集中所需的视频类型及其比例设置规范。下一步是尽可能多地获取高质量的示例。这个数据获取阶段对模型的成功至关重要,但超出了本文的范围,因为它取决于数据的性质,通常涉及复杂的法律要素。这个视频列表是我们数据集创建过程的输入。
回到“好数据集”检查表,要对最后两个问题——视频质量和描述对齐——给出积极的答案,很大程度上取决于收集的材料是如何预处理的。这个预处理工作流程将是本文其余部分的主要焦点。
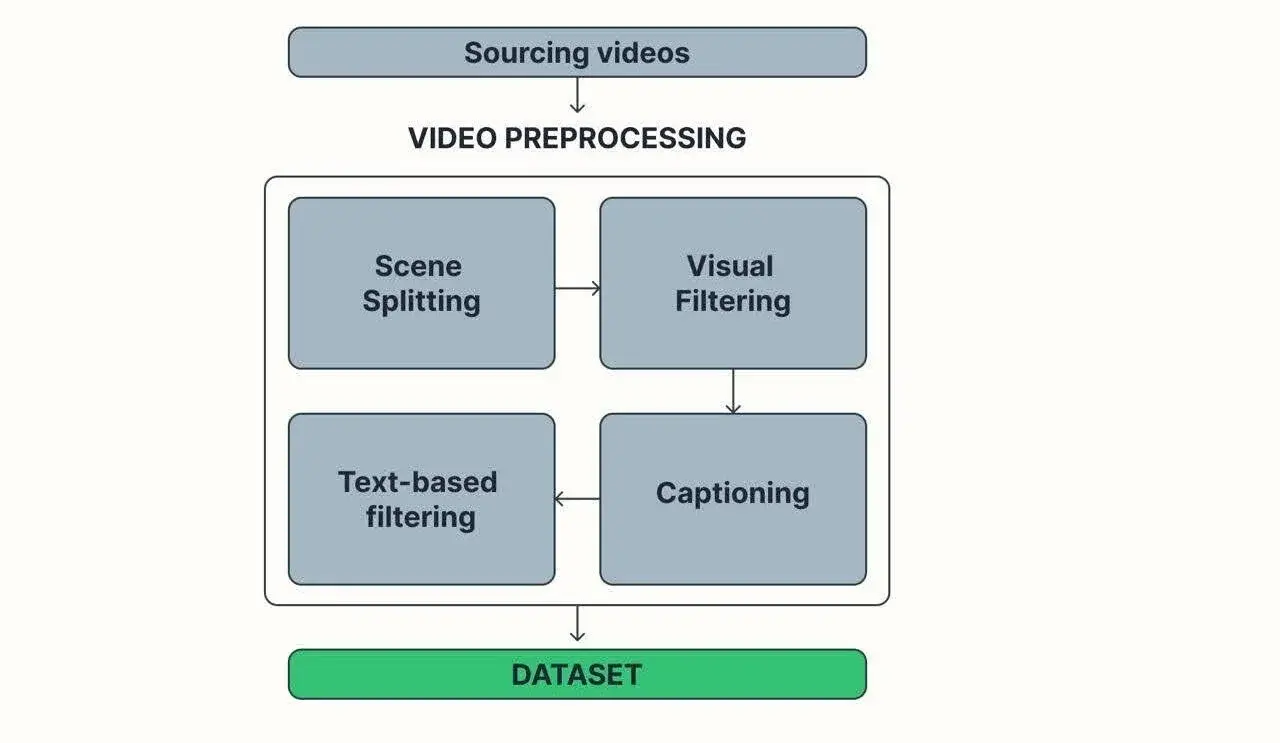
图 3:数据集创建
预处理
为数据集准备视频不仅仅是一个勾选任务——这是一个要求高、耗时的过程,可以决定最终模型的成功或失败。在这个阶段,你通常处理的是大量没有标签、没有描述、最多只有有限元数据(如分辨率或持续时间)的原始素材。如果获取过程有着良好的结构,你可能得到按领域或类别分组的视频,但即便如此,它们也不适合训练。
问题是直接且至关重要的:没有引导信息(字幕或提示)供模型学习,而且片段通常对于大多数生成架构来说太长了,这些架构倾向于使用以秒为单位的上下文窗口(视频的长度,就像大型语言模型的令牌数量)来工作,而不是分钟单位。
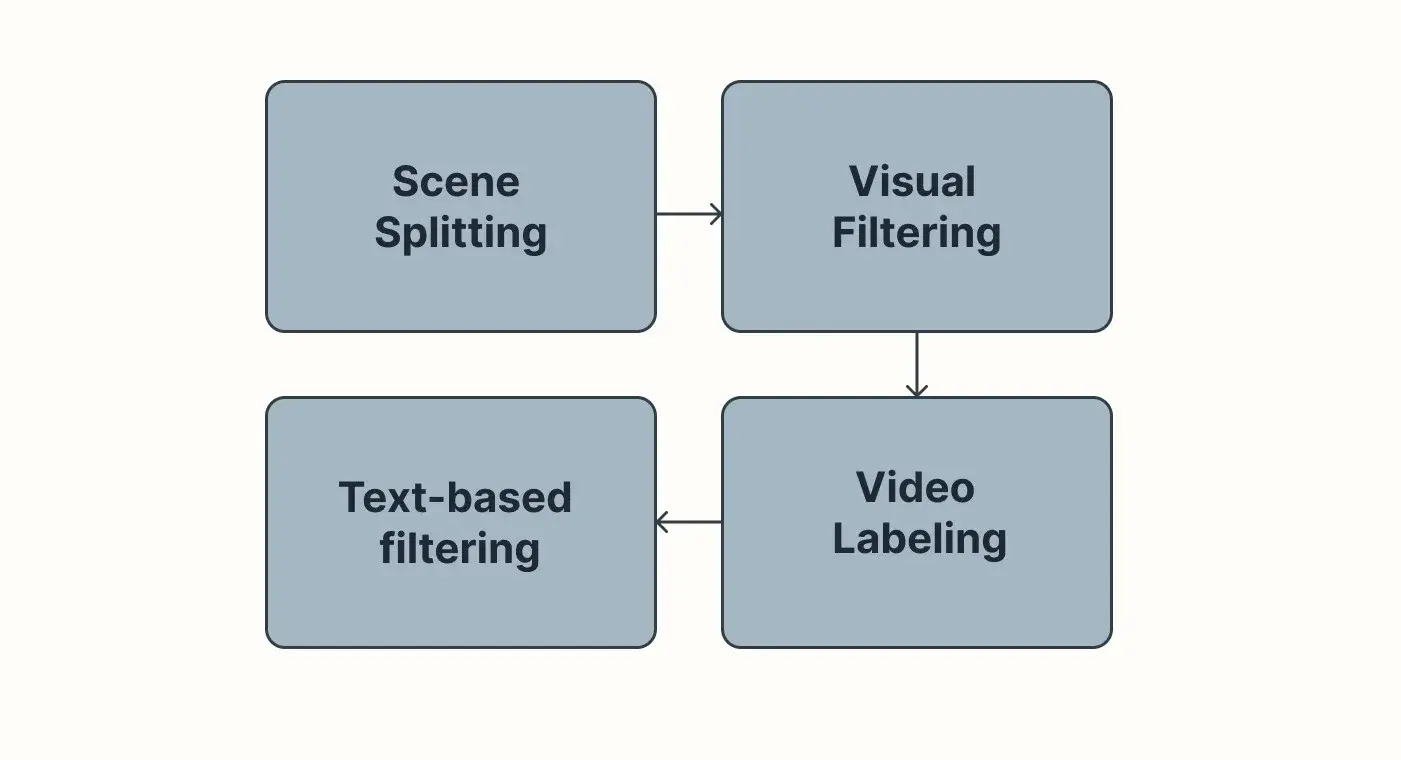
图 4:文本到视频数据预处理
预处理包括三个主要阶段:
将视频分割成有意义的、自包含的场景。
对场景进行视觉过滤
将每个场景与相关的文本提示配对。
根据视频场景的文本描述进行第二次过滤。
基本上,数据集预处理过程的结构如下表所示:
我们来详细看看这些阶段。
第一阶段:场景分割
大多数最先进的视频生成模型对剪辑长度有严格的限制,意味着它们不能在一个轮次中制作长视频。这使得场景分割成为一个关键步骤:将源素材分解成较短的片段,但这些片段仍有连贯感且易于描述。
随机裁剪长视频的方法可能很诱人,但这种方法很快就会崩溃。你最终会得到破损的剪辑、无意义的片段,或者剪辑中发生的事情太少或太多——所有这些都难以标记和训练,导致生成质量差。正如俗话说的,垃圾进垃圾出。
机器学习社区中最流行的解决方案之一是PySceneDetector,这是一个在研究中广泛使用的库。这里有一个最小的例子:
from scenedetect import detect, ContentDetector, split_video_ffmpegpath_to_video = "path/to/your/video"scene_list = detect(path_to_video, ContentDetector(threshold=27, min_scene_len=15), start_in_scene=True) # getting list of tuples (start_time, end_time)split_video_ffmpeg(path_to_video, scene_list, "output_dir") # save cut vidscene_list 返回每个检测到的场景的(开始时间戳,结束时间戳)元组集合。该库提供了几种检测方法。基本的 ContentDetector 在 HSL 颜色空间中将每一帧与前一帧进行比较,当差异超过阈值时进行切割。它很快,但经常将相机移动与实际场景变化混淆。AdaptiveDetector 通过应用滚动平均值来平滑假阳性,结合照明和边缘差异分数以及加权重要性来解决这个问题。
一些团队进一步细化结果。在 Snap 的 Panda-70M 数据集论文中,当一个剪辑的最后一帧和下一个剪辑的第一帧具有相似的嵌入时,Snap 合并了相邻的剪辑——有效地将语义相接的时刻重新缝合在一起。这是这个过程的伪代码示例:
from imagebind.models import imagebind_model # embedding model available from https://github.com/facebookresearch/ImageBindfrom models.imagebind_model import ModalityTypeimport torchdevice = "cuda:0" if torch.cuda.is_available() else "cpu"# Instantiate modelmodel = imagebind_model.imagebind_huge(pretrained=True)model.eval()model.to(device)#Get last frame of first video and first one of the secondfirst_video_last_frame = first_video[-1]second_video_first_fram = second_video[-1]# Calculate embeddings:embedding_1 = model({ModalityType.VISION: first_video_last_frame.to(device)})[ModalityType.VISION]embedding_2 = model({ModalityType.VISION: second_video_first_fram.to(device)})[ModalityType.VISION]# should we stitch?if diff(embedding_1, embedding_2) < threshold: # some distance metric: final_video = first_video + last_video另一个挑战是“错过剪辑”问题——一些长场景没有被正确分割,仍然太长而无法使用。降低差异阈值并再运行一次可以帮助——尽管正确的值通常来自试错。
一旦你得到了你的场景,接下来就是过滤——但我们会把它留到我们讨论字幕之后。
第二阶段:视频标记
一旦视频被分割成许多场景,每个片段都需要一个字幕——一个简洁的文本描述,涵盖动作、角色和其他关键元素。字幕一直是构建文本到图像和文本到视频数据集最具挑战性的部分之一。
这里的目标是找到一个谨慎的平衡:字幕必须足够精确以准确捕捉场景,但又不能过于冗长,以免用不必要的细节压倒模型。在一些工作流中,为同一场景生成具有不同细节水平的多个字幕。这里没有通用公式,所以重点转移到这些字幕是如何创建的。
手动标记是最直接的控制质量的方法,但它不可扩展。尽管如此,手工标记一小部分样本可以是一个有价值的练习——它有助于定义什么是“好”的,并为自动化方法提供参考示例。
将这一过程扩展通常意味着转向具有视觉能力的大规模语言模型,例如 GPT-4 或 Gemini 或一些本地部署的模型。本地和基于 API 的解决方案都是可行的;例如,CogVLM2-Video 可以本地运行以生成字幕。
本地部署的简化伪代码示例:
from transformers import AutoModelForCausalLMmodel = AutoModelForCausalLM("THUDM/cogvIm2-llama3-caption")videoframes = load_frames(path) # load every nth frame of the video to use as the model's inputcaption = model.generate(prompt= "Please describe this video in detail.", images = video_frames)要使用 API 选项,请参见以下示例:
from openai import OpenAIimport cv2 import base64def get_frames(path: str) -> list[str]: video = cv2.VideoCapture(path) base64Frames = [] while video.isOpened(): success, frame = video.read() if not success: break _, buffer = cv2.imencode(".jpg", frame) base64Frames.append(base64.b64encode(buffer).decode("utf-8")) video.release() return base64Framesclient = OpenAI(api_key="your_api_key")frames = get_frames("path/to/your/video")response = client.responses.create( model="use actual openai model", input=[ { "role": "user", "content": [ { "type": "input_text", "text": ( "These are frames from a video that I want to upload. Generate a compelling description that I can upload along with the video." ), }, *[ { "type": "input_image", "image_url": f"data:image/jpeg;base64,{frame}", } for frame in frames[0::25] ], ], } ],)虽然通用模型可能不如专门的字幕系统精确,但它们通常更灵活地处理用户提示,并能以多种风格产生输出。也可以使用手动标记的示例来微调这些模型以提高准确性。
评估字幕质量本身就是一个挑战。最可靠的方法仍然是将不同字幕系统的输出进行并排比较。另一个选择——尽管有些绕圈子——是使用 VLM 来比较字幕。至于改写字幕以增加多样性,这可能有所帮助,但实际上,将这些努力投入到改进核心字幕模型中会获得更大的回报。
第三阶段。过滤
看起来最快的方法是标记你拥有的每一个场景。实际上,这是通往糟糕结果的直接途径。经过前面的所有步骤之后,数据集很少是干净的:它几乎总是包含损坏的剪辑、低质量的帧和几乎相同的片段集群。过滤阶段的存在是为了剥离这些噪音,只留下值得模型学习的内容。这确保了模型不会在不会提高其输出的数据上浪费时间。
第一个目标是视觉上不好看的场景。这从一个小型手动标记的样本开始:将剪辑标记为“好”或“坏”,或标记特定问题,如运动太少、行动不清晰、太暗或曝光过度。一旦你收集了足够的标记示例,你就可以训练一个场景质量分类器。
构建它有几种方法。经典的计算机视觉技术在这里仍然很有效:
使用拉普拉斯算子的方差进行模糊检测——低值表示帧可能是模糊的。
基于照明条件的视觉质量
光流分析,以找到没有运动或混乱、过度运动的剪辑。
以下是根据经典计算机视觉(cv)方法进行过滤的代码:
import cv2import numpy as npfrom skimage.exposure import is_low_contrastdef get_frames(video_path: str): cap = cv2.VideoCapture(video_path) frames = [] while True: grabbed, frame = cap.read() if not grabbed: break frame = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY) frames.append(frame) return frames# 1. Blur detection algorithmdef frame_is_blured(image: np.ndarray, threshold: float) -> bool: # first we need to compute the Laplacian of the image and then return its variance variance = cv2.Laplacian(image, cv2.CV_64F).var() return variance < threshold# 2. Lightning filteringdef frame_has_good_light(image: np.ndarray) -> bool: return not is_low_contrast(image)# 3. Optical flow based filtering:def video_motion_is_good(video_path, low_threshold, high_threshold) -> bool: param = { "pyr_scale": 0.5, "levels": 3, "winsize": 15, "iterations": 3, "poly_n": 5, "poly_sigma": 1.1, "flags": cv2.OPTFLOW_LK_GET_MIN_EIGENVALS, } prev_frame = None magnitudes = [] for frame in get_frames(video_path): gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY) if prev_frame is None: prev_frame = frame continue flow = cv2.calcOpticalFlowFarneback(prev_frame, gray, None, **param) mag, ang = cv2.cartToPolar(flow[:, :, 0], flow[:, :, 1], angleInDegrees=True) magnitudes.append(mag) prev_frame = frame average_difference = sum(magnitudes) / len(magnitudes) return low_threshold < average_difference < high_threshold一个更现代的选择是基于嵌入的过滤。例如,Meta 的VJEPA模型为每个视频生成一个特征向量;这些嵌入可用于训练一个简单的逻辑回归或 MLP 分类器。将嵌入分组可以轻松检测和删除重复项,使用 VJEPA 的视频嵌入时,这应该基于匹配内容,而不是字幕。
在零样本场景中,视觉语言模型(VLLMs)可以用来生成场景描述,并立即决定它是否符合质量标准——无需额外训练。
一旦去除视觉“噪声”,好的片段就会转移到标题生成阶段。第二次过滤轮次将关注文本:手动审查一部分标题,将它们标记为“好”或“坏”,然后训练一个轻量级文本分类器(BERT 或甚至是 TF-IDF)来自动丢弃乏味或过于复杂的场景。
经过这些轮次后,你会得到一个既干净又有用的数据集:结构良好的场景与准确、信息丰富的标题配对。而且,像大多数现代机器学习工作流程一样,场景质量和标题质量都可以使用正确的工具进行测量和改进,例如更好、更专业、更精细调整的大型语言模型,使用少量样本学习技术的复杂提示,以及像 VJEPA-2 这样的专业视频嵌入模型。
小结
构建一个合适的文本到视频数据集是一个非常复杂的任务。然而,没有一个好的数据集就无法构建文本到视频生成模型。鉴于视频生成的需求不断增加,无论是广告、电影还是娱乐等各种用例,我们将继续需要更好、更大的数据集。我希望这篇文章能帮助理解这个过程。
作者介绍
Aleksandr Rezanov 是 Snap Inc.的机器学习工程师。此前,他领导了 Rask AI 的计算机视觉研究团队。Aleksandr 是一名深度学习专家和团队负责人,在机器学习方面拥有五年的经验。他曾在自然语言处理和计算机视觉领域工作。他的专长在于生成式人工智能,特别是在生成式计算机视觉、扩散模型和生成对抗网络(GAN)方面。




