

在《云计算架构下 Cloud TiDB的技术奥秘「上」》中,分析了 TiDB 与传统单机关系型数据库的区别,以及与几种技术整合之后所形成的总体架构。接下来,我们将深度探讨 Cloud TiDB 的关键特性和实现细节。
自动化运维
数据库产品上云的一个先决条件是能实现自动化的运维管理,因为在云上靠手工运维几乎是不现实的。
第一步,用 Kubernetes 将云平台的主机资源管理起来,组成一个大资源池;
第二步,再通过 tidb-opeartor 及 tidb-cloud-manager 等组件,来自动化完成 TiDB 实例的一键部署、扩容缩容、在线滚动升级、自动故障转移等运维操作。
来看集群创建。 在上篇文章里提到过 TiDB 包含 tidb、tikv 和 pd 三大核心组件,每个服务又都是一个多节点的分布式结构,服务和服务之间的启动顺序也存在依赖关系。此外,pd 节点的创建和加入集群方式与 etcd 类似,是需要先创建一个单节点的 initial 集群,后加入的节点需要用特殊的 join 方式,启动命令上也有差别。
有一些操作完成后还需要调用 API 进行通知。Kubernetes 自身提供的 StatefulSet 很难应付这种复杂部署,所以需要 tidb-operator 中实现特定 Controller 来完成这一系列操作。同时,结合 Kubernetese 强大的调度功能,合理规划和分配整个集群资源,尽量让新部署的 TiDB 实例节点在集群中均匀分布,最终通过 LB 暴露给对应的租户使用。
在线升级也类似。 由于 tikv/pd 的 Pod 挂载是本地存储,并不能像云平台提供的块存储或网络文件系统那样可以随意挂载。如果 tikv/pd 迁移到其它节点,相当于数据目录也被清空,所以必须保证 tikv/pd 的 Pod 在升级完成后仍然能够调度在原地,这也是要由 tidb-operator 的 Controller 来保证。
TiDB 的数据副本之间由 Raft 算法来保证一致性,当集群中某一个节点暂时断开,可以不影响整个服务,所以在集群升级过程中,必须严格按照服务的依赖关系,再依次对 Pod 进行升级。
当节点出现故障时。 同样是由于挂载本地数据盘的原因,也不能像 StatefulSet 那样直接把 Pod 迁移走。当 TiDB Operator 检测到节点失效,首先要等一段时间,以确认节点不会再恢复了,再开始迁移恢复的操作。
首先调度选择一个新节点启动一个 Pod, 然后通知 TiDB 将失效节点放弃掉,并将新启的 Pod 加入集群。后面会由 TiDB 的 PD 模块来完成数据副本数恢复以及数据往新节点上迁移,从而重新维持集群内数据平衡。
以上仅列举了 TiDB 几种典型的运维操作流程,实际生产上运维还有很多 case 需要考虑,这些都以程序的方式在 tidb-operator 里实现。借助 Kubernetes 和 tidb-operator 来代替人工,高效地完成 TiDB 数据库在云平台上的复杂运维管理。
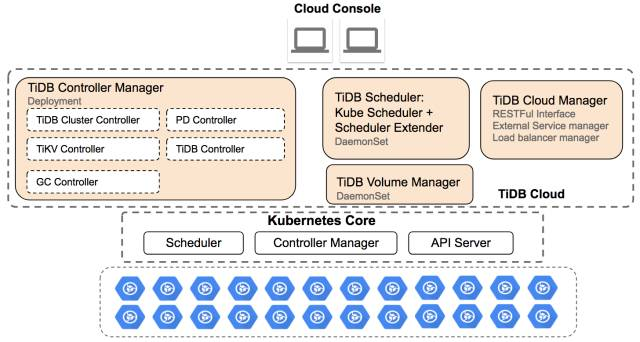
(图:Cloud TiDB 总体架构图)
动态扩缩容
弹性水平伸缩是 TiDB 数据库最主要的特性之一。在大数据时代,人们对数据存储的需求快速膨胀,有时用户很难预估自己业务规模的增长速度,如果采用传统存储方案,可能很快发现存储容量达到了瓶颈,然后不得不停机来做迁移和扩容。如果使用 Cloud TiDB 的方案,这个过程就非常简单,只需在 Cloud 控制台上修改一下 TiDB 的节点数量,就能快速完成扩容操作,期间还不会影响业务的正常服务。
那么,在 Cloud 后台,同样借助 Kubernetes 和 tidb-operator 的能力来完成 TiDB 增减节点操作。Kubernetes 本身的运作是基于一种 Reconcile 机制,简单来说就是当用户提交一个新请求,比如期望集群里跑 5 个 TiKV 节点,而目前正在跑的只有 3 个,那么 Reconcile 机制就会发现这个差异,先由 Kubernetes 调度器根据集群整体资源情况,并结合 TiDB 节点分配的亲和性原则和资源隔离原则来分配节点。另外很重要一点是选择有空闲 Local PV 的机器来创建 Pod 并进行挂载,最终通过 tidb-operator 将 2 个节点加入 TiDB 集群。
缩容的过程也类似。假如数据库存储的总数据量变少,需要减少节点以节省成本,首先用户通过云控制台向后端提交请求,在一个 Reconciling 周期内发现差异,tidb-operator 的 Controller 开始通知 TiDB 集群执行节点下线的操作。安全下线可能是比较长的过程,因为需要由 PD 模块将下线节点的数据搬移到其他节点,期间集群都可以正常服务。当下线完成,这些 TiKV 变成 tombstone 状态,而 tidb-operator 也会通知 Kubernetes 销毁这些 Pod,并且由 tidb-volume-manager 来回收 Local PV。
资源隔离
资源隔离也是云上用户关心的一个问题。尤其是数据库这类应用,不同租户的数据库实例,甚至一个租户的多套数据库实例,都跑在一套大 Kubernetes 管理集群上,相互间会不会有资源争抢问题?某个实例执行高负载计算任务时,CPU、内存、I/O 等会不会对同台机器上部署的其他实例产生影响?
其实,容器本身就是资源隔离的一个解决方案,容器底层是 Linux 内核提供的 cgroups 技术,用于限制容器内的 CPU、内存以及 IO 等资源的使用,并通过 namespace 技术实现隔离。而 Kubernetes 作为容器编排系统,能根据集群中各个节点的资源状况,选择最优策略来调度容器。同时,tidb-operator 会根据 TiDB 自身特性和约束来综合决策 TiDB 节点的调度分配。
举例来说,当一个 Kubernetes 集群横跨多个可用区,用户申请创建一个 TiDB 集群,那么首先根据高可用性原则,将存储节点尽量分配到不同可用区,并给 TiKV 打上 label。那么同一个可用区内也尽量不把多个 TiKV 部署到相同的物理节点上,以保证集群资源最大化利用。
此外,每个 Local PV 也是一块独立磁盘,每个 TiKV 的 Pod 分别挂载不同的盘,所以 I/O 上也是完全隔离。
Kubernetes 还可以配置 Pod 之间的亲和性(affinity)和反亲和性(anti-affinity)。例如:在 TiKV 和 TiDB 之间,可以通过亲和性使其调度到网络延时较小的节点上,提高网络传输效率。TiKV 之间借助反亲和性,使其分散部署到不同主机、机架和可用区上,降低因硬件或机房故障而导致的数据丢失风险。
上面解释了容器层的隔离,也可以看作是物理层的隔离。再来看数据层的隔离,TiDB 的调度体系也有所考虑,比如一个大的 TiDB 集群,节点分布在很多台主机,跨越多个机架、可用区,那么用户可以定义 Namespace,这是一个逻辑概念,不同业务的数据库和表放置在不同的 Namespace,再通过配置 Namespace、TiKV 节点以及区域的对应关系,由 PD 模块来进行调度,从而实现不同业务数据在物理上的隔离。
高可用性
TiDB 作为一个分布式数据库,本身就具有高可用性,每个核心组件都可以独立地扩缩容。任意一个模块在部署多份副本时,如果有一个挂掉,整体仍然可以正常对外提供服务,这是由 Raft 协议保证的。
但是,如果对数据库节点的调度不加任何限制,包含一份数据的多个副本的节点可能会被调度到同一台主机。这时如果主机发生故障,就会同时失去多个副本,一个 Raft 分组内失去多数派节点就会导致整个集群处于不可用状态,因此 tidb-operator 在调度 TiKV 节点时需要避免出现这种情况。
另外,TiDB 支持基于 label 的数据调度,能给不同 TiKV 实例加上描述物理信息的 label,例如地域(Region)、可用区(AZ)、机架(Rack)、主机(Host),当 PD 在对数据进行调度时,就会参考这些信息更加智能地制定调度策略,尽最大可能保证数据的可用性。
例如,PD 会基于 label 信息尽量把相同数据的副本分散调度到不同的主机、机架、可用区、地域上,这样在物理节点挂掉、机架掉电或机房出故障时,其它地方仍然有该数据足够的副本数。借助 tidb-operator 中 controller-manager 组件,可以自动给 TiKV 实例加上物理拓扑位置标签,充分发挥 PD 对数据的智能调度能力,实现数据层面的高可用性。
同时,还可以达到实例级别的高可用性,通过 Kubernetes 强大的调度规则和扩展的调度器,按优先级会尽量选择让 TiKV 部署到不同的主机、机架和可用区上,把因主机、机架、机房出问题造成的影响降到最低,使数据具有最大的高可用性。
另外,运行在 Kubernetes 之上,能实时监测到 TiDB 各组件运行情况,当出现问题时,也能第一时间让 tidb-operator 对集群进行自动修复 (self-healing)。具体表现为 tidb/tikv/pd 实例出现故障时,执行安全的下线操作,同时增加新实例来保证集群的规模和之前一致。
小结
TiDB 作为一款 Cloud Native Database,通过 tidb-operator 方式充分发挥 Kubernetes 平台的强大能力,实现云上自动化管理,极大降低人力运维成本。用户可以根据业务需要进行动态扩容缩容,多租户隔离特性让不同租户的实例可以共享计算和存储资源,互不干扰,同时最大程度充分使用云上资源。Raft 算法和 tidb-operator 自动修复能力以及两层调度机制保证了 Cloud TiDB 的高可用性。
本文转载自公众号 UCloud 技术(ID:ucloud_tech)。
原文链接:
https://mp.weixin.qq.com/s/EKUimeulhGc-hXR8Sto2rQ

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论