

在我们的一生中都会遇到吵闹的邻居,无论是在咖啡馆还是公寓里,吵闹的邻居总是会败坏我们的心情。事实证明,在共享空间中对良好举止的需求不仅对公众很重要,对你的 Docker 容器也一样很重要。
当你在云中运行时,你的容器位于共享空间中,特别是它们共享主机实例的 CPU 存储层次结构。
译注:存储层次是在计算机体系结构下存储系统层次结构的排列顺序。每一层于下一层相比都拥有较高的速度和较低延迟性,以及较小的容量(也有少量例外,如 AMD 早期的 Duron CPU)。大部分现今的 中央处理器的速度都非常的快。大部分程序工作量需要存储器访问。由于高速缓存的效率和存储器传输位于层次结构中的不同等级,所以实际上会限制处理的速度,导致中央处理器花费大量的时间等待存储器 I/O 完成工作。
大部分计算机中的存储层次如下四层:
寄存器–可能是最快的访问。在 32 位处理器,每个寄存器就是 32 位。 x86 处理器共有 16 个寄存器。
高速缓存(L1-L3: SRAM)
第一级高速缓存(L1)–通常访问只需要几个周期,通常是几十个 KB。
第二级高速缓存(L2)–比 L1 约有 2 到 10 倍较高延迟性,通常是几百个 KB 或更多。
第三级高速缓存(L3)(不一定有)–比 L2 更高的延迟性,通常有数 MB 之大。
第四级高速缓存(L4)(不普遍)–CPU 外部的 DRAM,但速度较主存高。
主存( DRAM)–访问需要几百个周期,可以大到数十 GB。
磁盘存储–需要成千上百个周期,容量非常大。
由于微处理器的速度如此之快,计算机架构设计已经发展到需要在计算单元和主存储器之间添加各种级别的高速缓存,以掩盖将 bit 带入“大脑”的延迟。但是,这里有个关键见解是,这些高速缓存在 CPU 之间是部分共享的,这意味着不可能对共同托管的容器实现完美的性能隔离。如果运行在容器旁边的核心上的容器突然决定从内存中获取大量数据,那么,它将不可避免地导致更多的“缓存未命中”(从而可能会导致性能下降)。
要靠 Linux 来拯救吗?
一般认为,操作系统的任务调度器负责减缓这种性能隔离的问题。在 Linux 中,目前的主流解决方案是 CFS(Completely Fair Scheduler,完全公平调度器)。它的目标是以“公平”的方式将正在运行的进程分配给 CPU 的时间片。
译注:完全公平调度器(Completely Fair Scheduler,CFS),是 Linux 内核的一部分,负责行程调度。参考了 Con Kolivas 提出的调度器源代码之后,由匈牙利程序员 Ingo Molnar 所提出。在 Linux kernel 2.6.23 之后采用,取代先前的 O(1) 调度器,成为系统缺省的调度器。它负责将 CPU 资源,分配给正在运行中的行程,目标在于最大化程序交互性能的同时,最小化整体 CPU 的运用。使用红黑树来实作,算法效率为 O(log(n))。
CFS 得到了广泛的使用,因此经过了充分测试,世界各地的 Linux 机器得以运行良好。那为什么还要搞砸它呢?事实证明,对于 Netflix 的绝大多数用例来说,它的性能远非最佳。Titus 是 Netflix 的容器平台。每个月,我们在 Titus 上的数千台机器上运行数百万个容器,为数百个内部应用程序和客户提供服务。这些应用程序包括为面向客户的视频流服务提供支持的关键低延迟服务,以及用于编码或机器学习的批处理作业。在这些不同应用程序之间保持性能隔离对于确保内部和外部客户的良好体验至关重要。
我们能够有意义地提高这些容器的可预测性和性能,方法是将一些 CPU 隔离责任从操作系统中移除,转向包含组合优化和机器学习的数据驱动解决方案。
我们的想法
CFS 通过应用一组启发式方法(每隔几微秒)非常频繁地进行操作,该方法封装了有关 CPU 硬件使用的最佳实践的一般概念。
相反,如果我们减少干预的频率(每隔几秒),但在分配计算资源的过程方面做出更好的数据驱动决策,以最大限度地减少配置噪声,那结果会怎样呢?
缓解 CFS 性能问题的一种传统方法是让应用程序所有者通过使用核心固定或精细值来手动协作。然而,我们可以根据实际的使用信息,通过检测搭配机会,自动做出更好的全局决策。例如,如果我们预测,容器 A 将很快趋向 CPU 密集型,那么我们应该在与容器 B 不同的 NUMA 套接字上运行它,因为容器 B 对延迟非常敏感。这样就避免了对容器 B 进行过多的缓存抖动(thrashing caches),并平衡了机器的 L3 缓存的压力。
译注: MUMA,非统一内存访问架构(Non-uniform memory access),是一种为多处理器的计算机设计的内存架构,内存访问时间取决于内存相对于处理器的位置。在 NUMA 下,处理器访问它自己的本地内存的速度比非本地内存(内存位于另一个处理器,或者是处理器之间共享的内存)快一些。
通过组合优化方法进行放置优化
操作系统任务调度程序所做的主要工作内容,实质上就是解决资源分配的问题:我有 X 个线程要运行,但只有 Y 个 CPU 可用,我该如何将线程分配给这些 CPU,以给人并发的错觉呢?
作为一个例子,让我们考虑一个包含 16 个超线程的玩具实例。它有 8 个物理超线程内核,分为 2 个 NUMB 插槽。每个超线程与其邻居共享其 L1 和 L2 缓存,并与套接字上的其他 7 个超线程共享其 L3 缓存:
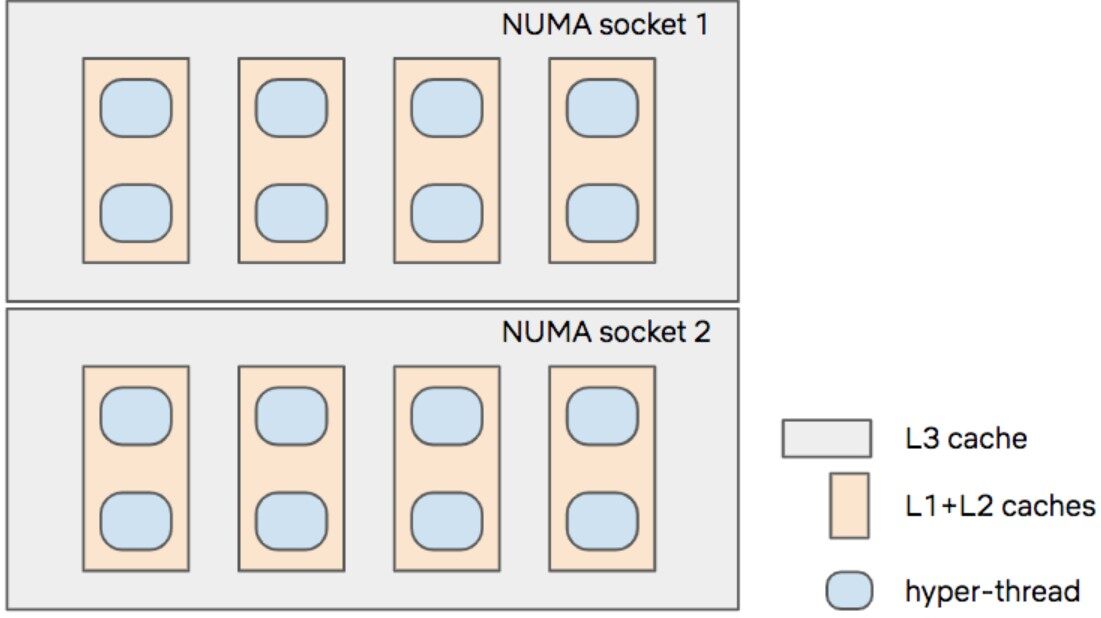
如果我们想在这个实例的 4 个线程上运行容器 A,在 2 个线程上运行容器 B,我们可以看看“拙劣的”和“良好的”放置决策都是什么样子的:
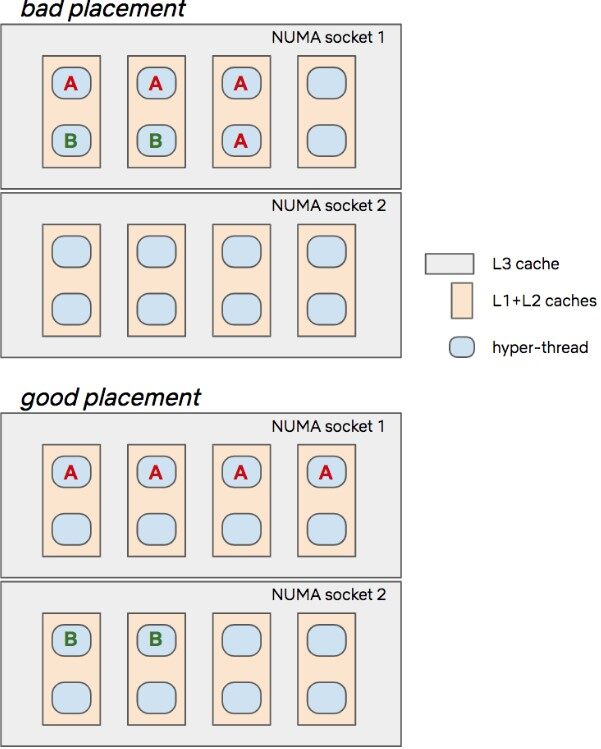
第一个放置从直觉上来看并不是很好,因为我们可能会通过 L1/L2 缓存在前两个内核上制造出 A 和 B 之间的配置噪声,而且通过 L3 缓存访问套接字,同时将套接字留空。第二个放置看起来更好,因为每个 CPU 都有自己的 L1/L2 缓存,并且我们还更好地利用了两个可用的 L3 缓存。
资源分配问题可以通过称为组合优化的数学分支得到有效解决,例如用于航空公司的调度或物流问题。
我们将这个问题表述为混合整数规划(Mixed Integer Program,MIP)。给定一组 K 个容器,每个容器在具有 d 个线程额度实例上请求特定数量的 CPU,目标是找到大小为 (d,k) 的二进制分配矩阵 M,以便没个容器获得它请求的 CPU 数量。损失函数和约束包含了表示先验良好放置决策的各种术语,例如:
避免将容器分散到多个 NUMA 套接字上(以避免潜在的跨套接字内存访问或页面迁移缓慢的情况)
除非需要,否则不要使用超线程(以减少 L1/L2 抖动)
尝试平衡 L3 缓存上的压力(基于容器硬件使用情况的潜在测量)
不要在放置决策之间过多地改变事情
考虑到系统的低延迟和低计算的要求(我们当然不希望耗费太多的 CPU 周期来确定容器应如何使用 CPU 周期!),我们怎样才能够真正在实践中做到这一点呢?
实现
我们决定通过 Linux cgroups 实现这个策略,因为 CFS 完全支持它们,方法是根据容器到超线程所需映射修改每个容器的 cpuset cgroup。通过这种方式,用户空间进程定义了一个“围栏”,CFS 在其中为每个容器进行操作。实际上,我们消除了 CFS 启发式对性能隔离的影响,同时又保留了它的核心调度功能。
译注: cgroups(Control Groups)是 Linux 内核提供的一种机制,这种机制可以根据需求把一系列系统任务及其子任务整合 (或分隔) 到按资源划分等级的不同组内,从而为系统资源管理提供一个统一的框架。简单说,cgroups 可以限制、记录任务组所使用的物理资源。本质上来说,cgroups 是内核附加在程序上的一系列钩子 (hook),通过程序运行时对资源的调度触发相应的钩子以达到资源追踪和限制的目的。
这个用户空间进程是一个名为 titus-isolate 的 Titus 子系统,其工作原理如下。在每个实例上,我们定义了三个触发放置优化的事件:
add:Titus 调度程序为此实例分配了一个新容器,需要运行
remove: 正在运行的容器刚刚完成
rebalance: 容器中的 CPU 使用率可能已发生变化,因此我们应该重新评估放置决策
译注: titus-isolate 的 GitHub 项目:https://github.com/Netflix-Skunkworks/titus-isolate
当最近没有其他事件触发放置决策时,我们会定期将再平衡事件排入队列。
每次触发放置事件时,titus-isolate 会查询远程优化服务(作为 Titus 服务运行,因此也会将自身隔离,就好像是东南亚一带文明中的神话里的世界观,“乌龟循环理论”,认为世界是由乌龟驮着的,而这只乌龟下面又有一只乌龟驮着,以此类推),从而解决了容器到线程的放置问题。
然后,该服务查询本地 GBRT 模型(从整个 Titus 平台收集的数周数据,每隔几个小时就重新训练一次),预测未来 10 分钟内每个容器的 P95 CPU 使用率(条件分量回归)。该模型包含上下文特征(与容器相关联的元数据:由谁启动、镜像、内存和网络配置、应用程序名称……)以及从主机定期从内核 CPU 记账控制器(CPU accounting controller)收集的容器的最后一个小时的 CPU 历史使用情况中提取的时间序列特征。
译注: 梯度提升(Gradient boosting,GBRT),是一种解决回归和分类问题的机器学习技术,它通过对弱预测模型 (比如决策树) 的集成产生预测模型。它像其他提升方法一样以分步的方式构建模型,并且通过允许使用任意可微分的损失函数来推广它们。
CPU 记账控制器(CPU accounting controller)可参阅:https://www.kernel.org/doc/Documentation/cgroup-v1/cpuacct.txt
然后将预测输入到 MIP 中,在运行过程中得到即时解决。我们使用 cvxpy 作为一个很好的通用符号前缀来表示问题,然后可以将其输入各种开源或专有的 MIP 解算器后端。由于 MIP 是 NP 困难问题,因此需要注意一些事项。我们向解算器施加了困难的时间预算,以将分支切割(branch-and-cut)策略推向到低延迟策略,并在 MIP 间隙周围设置围栏,以控制所发现解决方案的整体质量。
译注: NP 困难(NP-hard,non-deterministic polynomial-time hard)问题是计算复杂性理论中最重要的复杂性类之一。某个问题被称作 NP 困难,当所有 NP 问题可以在多项式时间图灵归约到这个问题。
因为 NP 困难问题未必可以在多项式的时间内验证一个解的正确性(即不一定是 NP 问题),因此即使 NP 完全问题有多项式时间内的解,NP 困难问题依然可能没有多项式时间内的解。因此 NP 困难问题“至少与 NPC 问题一样难”。
然后,服务将放置决策返回给主机,主机通过修改容器的 cpuset 来执行该决策。
例如,在任何时刻,具有 64 个逻辑 CPU 的 r4.16xlarge 可能看起来如下图所示那样的(颜色比例表示 CPU 使用率):

结果
该系统的第一个版本就产生了如此好的结果,真令人惊讶。我们将批处理作业的总体运行时间平均减少了百分之几,同时最重要的是减少了作业运行时间差异(合理的隔离代理),如下图所示。在这里,我们看到一个真实的批处理作业运行时分布,其中包含和没有包含改进的隔离。
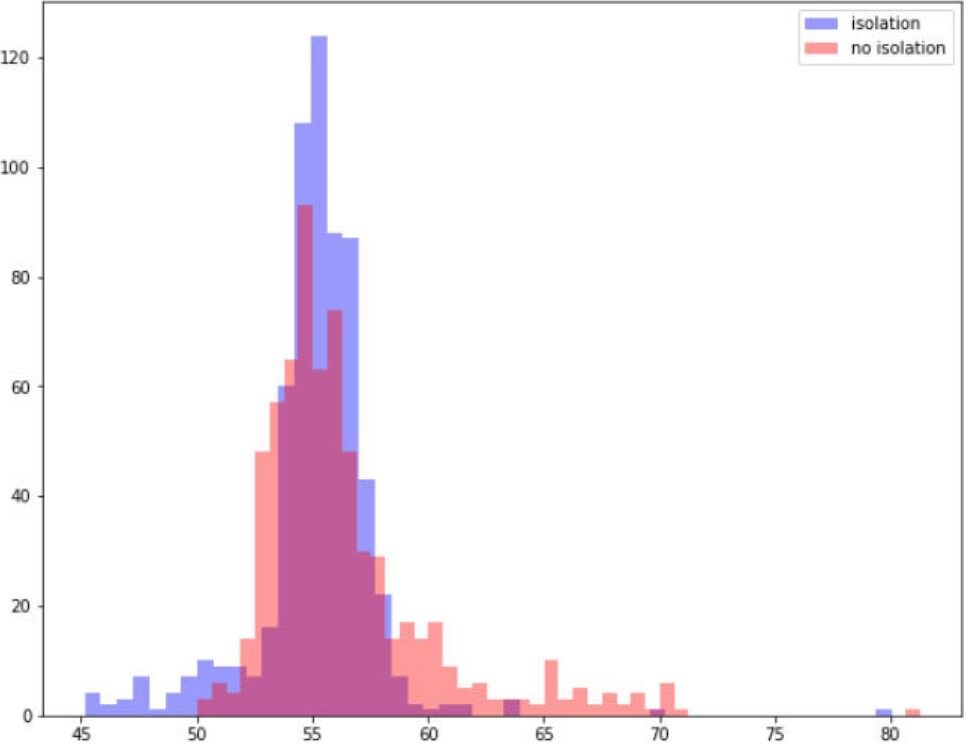
请注意我们是如何最大限度地消除长期异常值的问题的。不幸的吵闹邻居运行的右尾已经消失了。
对于服务而言,收益更让人印象深刻。专门为 Netflix 流媒体服务的 Titus 中间件服务的容量减少了 13%(减少了超过 1000 个容器),这是在峰值流量时使用所需的 P99 延迟 SLA 来服务相同负载所必需的!我们还注意到,由于内核在缓存失效逻辑中花费的时间要少得多,因此计算机上的 CPU 使用率也有了大幅下降。我们的容器现在更容易预测,速度更快,而且机器使用也更少!鱼,我所欲也,熊掌亦我所欲也;二者不可得兼,舍鱼而取熊掌者也。
下一步打算
我们对这一领域迄今取得的进展感到兴奋。我们正在从多个方面开展工作,努力扩大本文中提出的解决方案。
我们希望扩展系统以支持 CPU 超额使用。我们的大多数用户都面临着如何正确调整应用程序所需 CPU 数量的挑战。事实上,这个数字在容器的使用寿命期间会有所不同。由于我们已经预测了容器未来的 CPU 使用率,因此我们希望能够做到自动检测并回收未使用的资源。例如,如果我们可以沿着下图的各个轴检测用户的灵敏度阈值,那么就可以决定自动将特定容器分配给未得到充分利用的 CPU 的共享 cgroup,从而更好地提高整体隔离和机器利用率。

我们还希望利用内核 PMC 事件来更直接地进行优化,以最大限度地减少缓存噪声。一种可能的方法是,使用 Amazon 最近推出的基于 Intel 的裸机实例,这种实例允许深入访问性能分析工具。然后,我们可以将这些信息直接输入到优化引擎中,从而转向更受监督的学习方法。这就需要对放置进行适当的连续随机化来收集无偏的反事实,因此我们可以构建某种干扰模型(“如果我将容器 A 的一个线程与容器 B 放在同一个内核上,并且知道此刻有 C 也在同一个套接字上运行,那么容器 A 在下一分钟的性能表现会怎么样呢?)
原文链接:
https://medium.com/netflix-techblog/predictive-cpu-isolation-of-containers-at-netflix-91f014d856c7

暂无签名

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论