
现代的前端框架和库可以轻松地创建可重用的 UI 组件。在创建可维护前端应用方面,这是一个很好的方向。但是,在多年来的许多项目中,我发现开发可重复使用的组件常常是不够的。我的项目由于需求的变化或者新需求的出现而变得不可维护。要查找正确的文件或调试多个文件所需的时间越来越长。
必须改变。我可以提高搜索技能,或者更熟练地使用 Visual Studio Code。但我并不是唯一在前端工作的人。所以,我们需要对前端项目进行设置。要让它们变得更易于维护和扩展。那意味着我们可以对当前特性进行修改,但也可以更快地添加新特性。
高级架构
对于后端开发,我们可以遵循很多架构模式。领域驱动开发(domain-driven development,DDD)和关注点分离(separation of concerns,SoC)是目前使用的两个概念。这两个概念给前端开发带来了巨大价值。在 DDD 中,你试着把相似的特性分组合起来,并尽量使它们和其他组(比如模块)解耦。而在 SoC 中,例如,我们可以分离逻辑、试图和数据模型(例如,使用 MVC 或 MVVM 设计模式)。
希望现代的前端应用程序能完成越来越多的繁重工作。当复杂度增加时,Bug 也会变得更加频繁。由于用户和前端的交互,我们需要一个既可维护又可扩展的可靠架构。在这一点上,我的首选架构是模块化和领域驱动的。记住,我的想法也许会改变,但这是我此刻首选的方式。
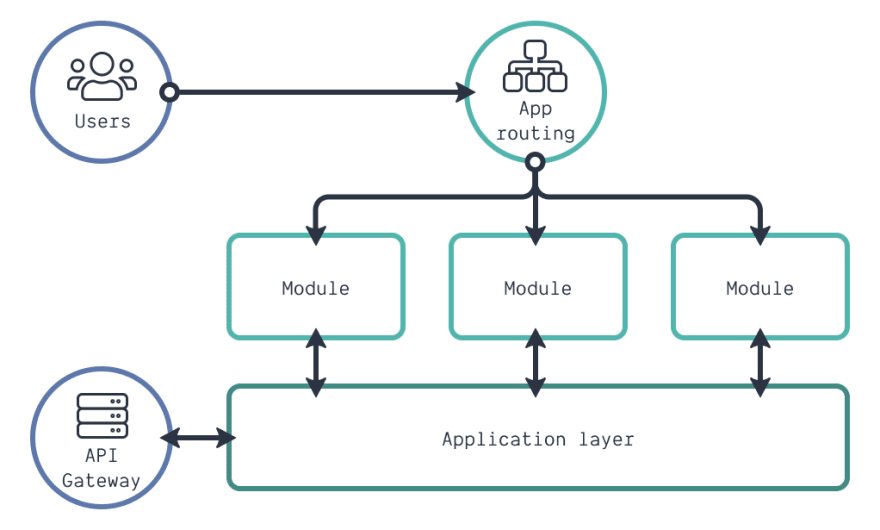
当用户与我们的应用交互时,应用将路由引导用户到正确的模块。每一个模块都被完全包含。然而,如果用户想要使用一个应用,而非几个小应用,就会有一些藕合。该耦合存在于特定的特性或业务逻辑中。有几个特性可以在模块间共享。你可以将该逻辑放在应用层。也就是说,每个模块可以选择与应用层进行交互。例如,需要通过客户端的 API 连接到后端,或者设置 API 网关。
在查看项目的结构时,我们可以遵循如下所示的内容。应用层的所有代码都在 app 目录下。并且所有的模块都有一个目录,位于 modules 目录下。不依赖业务逻辑的可重复使用的 UI 组件(如表格)在 components 目录下。
app/assets/components/lib/modules/styles/其余的目录存放我们的静态 assets(如图片)或者lib 中的辅助函数。辅助函数可以非常简单。它们可以将某些东西转换为某种格式,或者帮助处理对象。但更复杂的代码可以存放于 lib 目录中。处理模式或图的工作(例如检查有向图中的循环的算法)也不例外。
很多人都使用 CSS-in-JS 或样式组件之类的东西,但是我更喜欢普通的 CSS。为什么呢?无需 JavaScript,我们可以使用 CSS 和 HTML 解决很多 UI 问题。当我们应用 SoC 的概念时,这会变得更加容易。此外,在一个地方维护 CSS 使你更容易维护,因为你可以减少重复的工作。它要求一个稳定的 CSS 架构。尽管我会在另一篇博文中讨论这个问题,但是我的 CSS 架构是基于 Harry Roberts 的 ITCSS。
填写应用细节
通过高层和项目结构,我们已经有了一个良好的开端。然而,为了实现这一前端架构,我们还需要更多的细节。我们先来看看更详细的架构图,如下图所示。在这幅图中,我放大了应用层,但同时也放大了一个模块。在我们的前端应用中,应用层是我们的核心,所以我们首先讨论它。
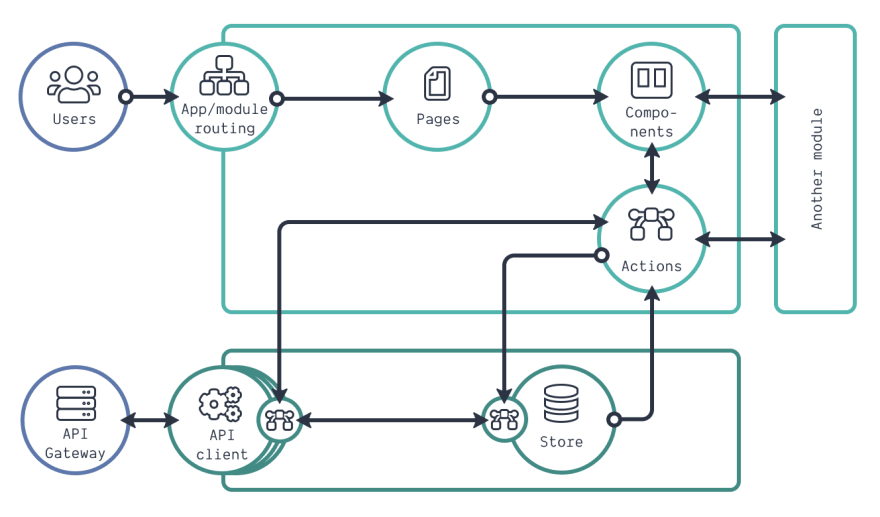
应用层由两部分组成:存储和客户端 API。存储是我们的全局应用状态。这个状态保存着不同模块在同一时间可以存取的数据。即使在屏幕上不需要这些数据,它也会持续存在于存储中。正如你所看到的,每一个发送到存储的更新请求都可以通过一连串的逻辑。这就是我们所说的中间件。这是 Redux 中使用的一种模式。中间件的一个简单例子是记录存储的传入请求。
有时候,需要通过外部服务中的数据对存储的传入请求进行增强。在 Redux 中,我们使用 Promise 处理这个调用。它可能是后端服务,但是它也可能是公共的第三方 API。有些情况下,只需使用浏览器 fetch API 就可以实现单一目的的 REST 调用。如果希望使用同一个 API 来执行不同的调用,那么创建 API 客户端定义是个不错的想法。
基本的 API 客户端处理外部请求、响应和错误。你甚至可以让它为你提供有关请求状态的信息(例如,加载)。不过,更复杂的 API 客户端可以处理更多的事情。有些 API 通过 web-socket 连接甚至是 GraphQL API。在这种情况下,你将拥有更多的配置选项,如下图所示。
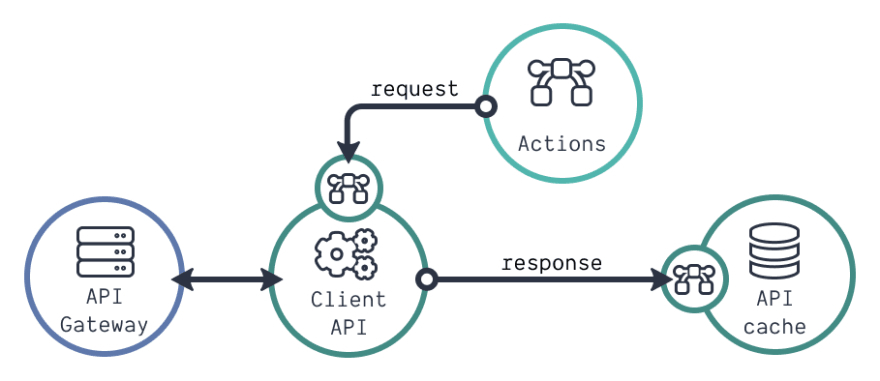
对于更加复杂的 API 客户端,我们可以通过中间件修改所有发出的请求(例如,添加认证头)。响应可以由后件修改(比如更改数据结构)。更改响应之后,我们将其存储在客户端的缓存中,这就像应用存储一样。有什么不同吗?缓存只处理传入的 API 数据,而我们可以把任何数据放入应用存储里。
很多前端应用都会有专门的后端服务来对话。无论是在有许多微服务的 Kubernetes 集群之上的 API 网关,还是一个单一的单体后端。但是有时候我们需要连接到不同的外部服务。使用这种架构,我们可以创建大量的 API 客户端。每个 API 客户端都有缓存、中间件和后件。我们应用的不同部分应该能够与这些 API 客户端中的每一个进行交互。
应用目录的相应项目结构可以如下所示:
app/ api/config/ store/pubsub/ schemas/ index.jsapp 中的两个目录现在听起来应该很熟悉:api 和 store。这两个目录保存了与前面描述的用例有关的所有内容。config 存放静态定义和配置(比如常量),用于整个应用。schemas 描述了 JavaScript 对象的特定数据结构。这在使用 TypeScript 或 JavaScript 时都可以使用。应用的所有通用模式都存储在 schemas 目录中。
pubsub 是一个很好的例子,它可以扩展前端的基本架构。pubsub 可以用于模块通信或管理预定作业。因为它对于应用的核心很重要,所以它位于 app 目录内。最后,我们得到了 index.js 文件。通过这个文件,我们可以添加 app 目录中的所有函数和常量。这就是说,这个文件的功能是进入应用逻辑的入口点。
模块的架构
介绍了应用层之后,就剩下模块了。详细的架构图已经显示了一个模块的内部结构。如果应用的路由指向一个特定的模块时,这个模块就会决定路由应该如何继续。模块的路由决定哪个页面应该显示。一个页面包括许多 UI 组件,也就是用户在屏幕上看到的内容。
在本例中,页面与 UI 组件没有任何区别。它是一个大的 UI 组件。然而,其他模块可以与组件(和动作)交互,但不能与页面交互。只有使用嵌套路由才能使来自不同模块的页面相互作用。这就是说,你将模块的路由放在不同模块的页面中。
组件通过动作与应用层交互。这些动作可能表现为各种形式。它们可以是普通的 JavaScript 函数、Redux 相关函数或者 React Hooks。有时候,你有一些小的实用函数专门用于某些模块。如果是这样,你可以将它们放到 actions 目录下,也可以为模块创建一个专门的 utils 目录。下面显示了项目的模块结构:
users/ actions/ components/config/ constants.js routes.js tables.js forms.js pages/gql/ schemas/ index.js和应用层一样,我们也可以有静态代码(如常量或模式定义),而只涉及到我们的模块。本例中,我们将这些代码放入 config或 schema 目录下。在使用 GraphQL 时,可以有查询和变异的定义。这些应该放在 gql 目录下(或者一个具有相似用途的目录)。添加 interface.js 文件,用于存储该模块的应用。这个文件描述了如何访问存储中的数据。
index.js 作为 app 目录的 index.js。在这里,我们描述了供他人访问的所有的组件、动作和常量。
模块的通信
并不是每个模块都需要拥有上述所有的目录和文件。比如,有些模块不需要页面,因为它们只包括组件和动作。“files”模块就是一个很好的例子。这个模块结合了组建和动作来查看和上传文件。一个例子是一个拖放文件的区域,将结果上传到一个 blob 存储。它可以成为可重复使用的组件。但是,文件的实际上传取决于我们能够使用的服务。我们通过将 UI 组件和上传文件的实际动作结合起来,创建了一个小的包含模块。将组件与业务逻辑结合在一起时,我们将其转换为模块。
但是其他模块是如何使用文件模块中的组件或者动作的?模块的 index.js 文件描述了哪些组件、动作和常量可以被其他组件访问。因此,我们可以在文件模块中使用文件拖放区或上传动作。然而,有时候我们需要选择我们想要公开的内容。这是一个动作,还是我们要将这一动作合并为一个组件?
下面来看看用户下拉列表的示例。通过创建动作,可以为我们提供可以从不同模块选择的所有用户。不过,现在我们需要在其他所有模块中创建一个特定的下拉列表。这可能不需要太多努力,就能得到一个通用的下拉组件。但这个组件可能无法在窗体中工作。也许有必要创建一个可以使用的 UserDropdown 组件。现在我们只在用户周围更改一个组件时更改。因此有时候我们需要选择公开的内容:动作或组件。
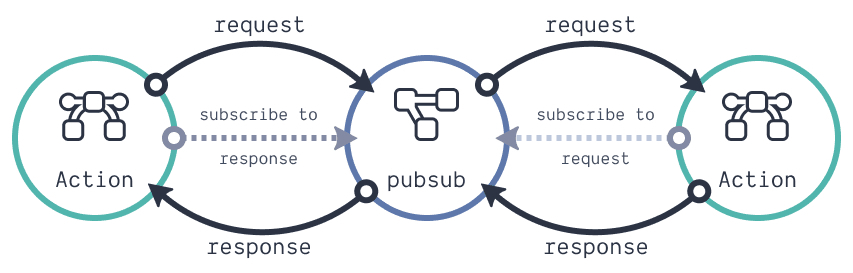
在组件之间使用的一种高级模式是使用 pubsub。在这个模式下,不能共享组件,但是我们可以共享数据。上面的图片说明了它的工作原理。再一次强调一下,这是一种高级模式,仅当你想要走微型前端路线或者需要的时候。
UI 组件剖析
还缺少最后一个细节层面,那就是 UI 组件的架构。我在以前的博文中已经对此进行过描述。你可以从这种解剖图中看到一些我们已经广泛应用的概念。
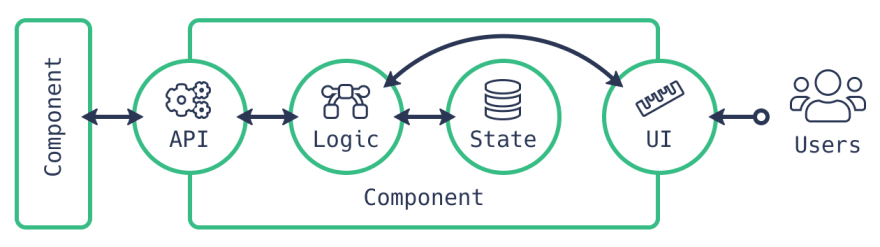
前端是用户的第一个入口点。当前端项目特性增加时,我们也引入了更多的 Bug。但是我们的用户期望没有 Bug,新特性也会更快。那不可能。但是,只要有了一个好的架构,我们就能尽可能达到这个目标。
作者介绍:
Kevin Pennekamp,富有创意的前端工程师。喜欢 CSS,并遵循一些基本的工程原则。
原文链接:
https://dev.to/crinklesio/how-to-create-a-scalable-and-maintainable-front-end-architecture-4f47




