
作者丨 Nick McGreivy
译者丨明知山、华卫
策划丨华卫
编者按:近日,一位专注于物理领域的科学家 Nick McGreivy 分享了其应用 AI 来做研究的真实经历,主题是“我被 AI for Science 的炒作所愚弄”。McGreivy 的研究涵盖机器学习、科学计算、等离子体物理学、核聚变能和核政策等领域,并在 Nature Machine Intelligence、ICLR 等多个知名期刊上发表过成果论文。
曾经,他对 AI 可以加速物理学研究持乐观态度。但是,当他尝试将 AI 技术应用于实际物理问题时,结果令人失望。McGreivy 表示,自己对 AI 即将“加速”甚至“革新”科学的观点产生了怀疑。而在其深入调研后又发现,“即使 AI 在科学中取得了真正令人印象深刻的成果,这也不一定意味着 AI 对科学做出了什么实质性的贡献,更多只是反映出 AI 在未来可能发挥重要作用的潜力…”
2018 年,当我在普林斯顿大学攻读等离子体物理博士二年级时,我做出了一个重要的决定——将我的研究重点转向机器学习。当时我还没有一个具体的科研项目,但我认为,利用 AI 来加速物理研究可能会带来更为深远且重大的影响。(坦白说,AI 领域的高薪也让我很动心。)
我最终将研究方向锁定在后来被 AI 先驱杨立昆(Yann LeCun)形容为“确实是一个热门话题”的领域:利用 AI 解决偏微分方程(PDE)。然而,当我试图在我所认为的那些令人印象深刻的研究成果基础上,继续深入探索时却发现,AI 方法的表现远不如宣传得那么好。

本文作者 Nick McGreivy
一开始,我尝试将一种备受关注的 AI 方法,即物理信息神经网络(PINN) 应用于一些相对简单的偏微分方程,却发现它的效果比预想差得多。尽管有几十篇论文声称 AI 方法能够比标准数值方法更快地解决偏微分方程——在某些情况下甚至快上百万倍,但我发现,这些比较绝大多数都是不公平的。当我将这些 AI 方法与最先进的数值方法放在同等条件下进行比较时,AI 所具有的任何狭义上的优势几乎都消失了。
这段经历让我开始对 AI 即将“加速”甚至“革新”科学的观点产生了怀疑。我们真的即将进入 DeepMind 所说的“AI 助力科学发现的黄金时代”了吗?亦或是,AI 在科学领域的总体潜力被夸大了——就像在我的这个子领域所看到的那样?
类似的问题,有其他人也发现了。例如,2023 年,DeepMind 声称发现了 220 万种晶体结构,这代表着“人类已知稳定材料数量的十倍增长”。但当材料科学家对这些化合物进行分析时,他们发现当中大多数都是“垃圾”,并“恭敬地”指出该论文“没有报告任何真正的新材料”。
另外,普林斯顿大学的计算机科学家 Arvind Narayanan 和 Sayash Kapoor 整理了一份包含 648 篇论文的名单,涵盖 30 个领域,均存在“数据泄露”的方法论错误。在每种情况下,数据泄露都会导致结果过于乐观。他们认为,基于 AI 的科学正面临着“可重复性危机”。
然而,在过去十年间,AI 在科学研究中的应用呈现出急剧增长的态势。计算机科学当然是受影响最大的领域,但其他学科——物理、化学、生物、医学以及社会科学也见证了 AI 应用的快速增长。在所有科学出版物中,AI 的使用率从 2015 年的 2% 增长到 2022 年的近 8%。尽管难以找到最近几年的数据,但有充分的理由认为这种曲棍球杆式的增长仍在继续。
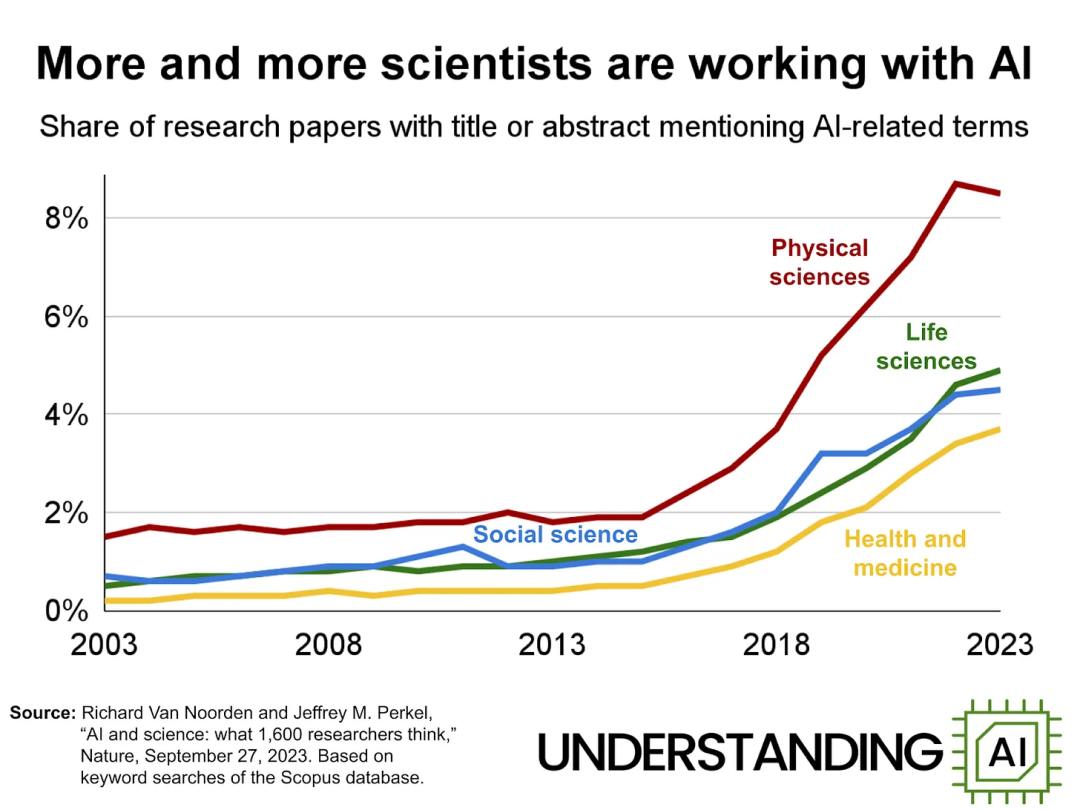
需要明确的是,AI 确实有推动科学突破的潜力。而我担心的是,这些突破的规模和频率是否真的如我们所期望的那样。AI 是否真的展现出了足够的潜力,值得我们如此大规模地将人才、培训、时间和资金从现有的研究方向转移到单一的 AI 范式上?
每个科学领域对 AI 的体验都不尽相同,因此我们应当谨慎地进行概括。不过,我确信,从我的经历中总结的一些经验教训能广泛适用于整个科学界:
AI 在科学家群体中的应用呈爆炸式增长,这更多是因为它对科学家自身有利,而不是因为它对科学有利。
由于 AI 研究人员几乎从不发表负面结果,所以 AI 在科学研究中的应用正经历着幸存者偏差。
那些发表出来的积极的结果往往对 AI 的潜力过于乐观。
因此,我慢慢地开始相信,AI 在科学领域并没有它看起来那么成功和具有革命性。
我不知道 AI 是否会扭转科学生产力长期下降以及科学进步速度停滞(甚至减缓)的趋势。我认为没有人知道。除非在先进 AI 领域取得重大突破(在我看来,这种情况不太可能发生),否则我预计 AI 将成为科学领域的一个普通的工具,它推动科学渐进式、不均衡地进步,而不是一个具有革命性的工具。
经历数周的失败,“我对 AI 失望了”
2019 年夏天,我第一次接触到后来成为我论文主题的内容:用 AI 解决偏微分方程。偏微分方程是用于模拟各种物理系统的数学方程,在计算物理和工程领域,求解(即模拟)它们是一项极其重要的任务。我的实验室利用偏微分方程来模拟等离子体的行为,如聚变反应堆内部和外太空星际介质中的等离子体。
用于求解偏微分方程的 AI 模型是定制的深度学习模型,它与聊天机器人(ChatGPT)的相似度远低于与 AlphaFold 的相似度。
我最初尝试的方法是物理信息神经网络(PINN)。PINN 是在一篇极具影响力的论文中被首次提出,该论文迄今已被引用了数百次。
与标准数值方法相比,PINN 是一种截然不同的求解偏微分方程的方法。标准方法将偏微分方程的解表示为一组像素(如图像或视频),并针对每个像素值推导方程。而 PINN 将偏微分方程的解表示为一个神经网络,并将方程放入损失函数中。
作为一名尚无导师指导的研究生,PINN 对我来说有着极大的吸引力。它们看起来如此简单、优雅且通用。
它们似乎也有一些很好的成果。提出 PINN 的那篇论文指出,其“有效性”已经“通过流体力学、量子力学、反应扩散系统以及非线性浅水波传播等经典问题得到了证明”。如果 PINN 能够解决这些领域的偏微分方程,那么肯定也能解决我实验室所关心的等离子体物理偏微分方程。
然而,当我将那篇具有影响力的论文中的一个示例(1D Burgers)替换为另一个不同但极其简单的偏微分方程(1D Vlasov)时,结果与精确解仍相差甚远。最终,在经过反复调整后,我才得到一个看似正确的结果。然而,当我尝试稍微复杂一些的偏微分方程(例如 1D Vlasov-Poisson)时,无论如何调整,都无法得到像样的解。
在经历了数周的失败后,我联系了另一所大学的一位朋友。他告诉我,他也曾尝试使用 PINN,但同样没能得到好的结果。
只有成功的结果会被发表
最终,我意识到问题出在哪里了。最初 PINN 论文的作者和我一样,“发现在一个方程上取得惊人结果的特定设置,在另一个方程上可能会失败”。 然而,为了让读者相信 PINN 的巨大潜力,他们并未展示任何失败案例。
这段经历让我学到了一些东西。首先,要谨慎对待 AI 研究表面上的结论。大多数科学家并非试图误导任何人,但他们在展示积极成果的巨大压力下,仍然可能无意中误导他人。因此,今后我必须更加审慎,即使面对那些成果惊人、影响力巨大的论文。
其次,人们很少发表关于 AI 方法失败的论文,通常只有在成功时才会发表。PINN 论文的作者没有发表其方法未能解决的偏微分方程的论文。我也没有发表自己那些不成功的实验,只是在一个不知名会议上展示了一张海报。因此,很少有研究人员知晓这些。事实上,尽管 PINN 广受欢迎,但时隔两年才有人发表了一篇关于其失效模式的论文。该论文如今已被引用超过一千次,这表明许多其他科学家尝试过 PINN 并发现了类似问题。
第三,我得出结论,PINN 并不是我想要采用的方法。它们确实简单而优雅,但也极其不可靠、过于挑剔且速度缓慢。
到今天为止,六年过去了,最初的 PINN 论文已经获得了惊人的 1.4 万次引用,成为 21 世纪被引用次数最多的数值方法论文(据我统计,再过一两年,它将成为有史以来被引用次数第二多的数值方法论文)。
尽管如今人们普遍认为,PINN 在解决偏微分方程方面不如标准数值方法有竞争力,但对于一类被称为反问题的特殊问题,PINN 的表现仍然存在争议。支持者声称 PINN 对反问题“特别有效”,但一些研究人员对此提出了强烈质疑。
我不知道这场争论哪一方是对的。我当然希望所有这些关于 PINN 的研究已经产出了一些有用的成果,但如果有一天我们回过头来看 PINN 时,发现它只是一个巨大的引用泡沫,我也不会感到意外。
知名研究多为不公平对比,“导致结果过于积极”
在我的博士论文中,我专注于使用深度学习模型来解决偏微分方程,这些模型像传统求解器一样,将偏微分方程的解视为网格或图形上的一组像素。
与 PINN 不同,这种方法在我的实验室所关心的复杂、时变偏微分方程上展现出了很大的潜力。最令人印象深刻的是,一篇又一篇的论文展示了其求解偏微分方程的速度——通常比标准数值方法快几个数量级。
最让我和我的导师感到兴奋的例子是来自流体力学的偏微分方程,如 Navier-Stokes 方程。我们认为,我们所关注的偏微分方程——如描述聚变反应堆中等离子体的方程具有类似的数学结构,我们或许能看到类似的加速效果。从理论上讲,这将使像我们这样的科学家和工程师能够模拟更庞大的系统,更快速地优化现有设计,并最终加快研究进程。
到这个时候,我已经足够有经验了,知道在 AI 研究中,事情并不总是像看起来的那么美好。我知道可靠性和稳健性可能是一个棘手的问题。如果 AI 模型提供了更快的模拟,但这些模拟的可靠性较低,那么这种权衡是否值得呢?我不知道答案,于是开始寻找答案。
然而,当我努力尝试,却大多以失败告终——让这些模型变得更加可靠时,我开始对 AI 模型在加速偏微分方程求解方面所展现出的潜力产生了怀疑。
一些备受瞩目的论文称,AI 解决 Navier-Stokes 方程的速度比标准数值方法快几个数量级。但我发现这些论文中使用的基准方法并非当前最快的数值方法。当我将 AI 同更先进的数值方法进行比较时,发现 AI 并不比它们更快(或者最多只是略快一些)(至多只快了一点点)。
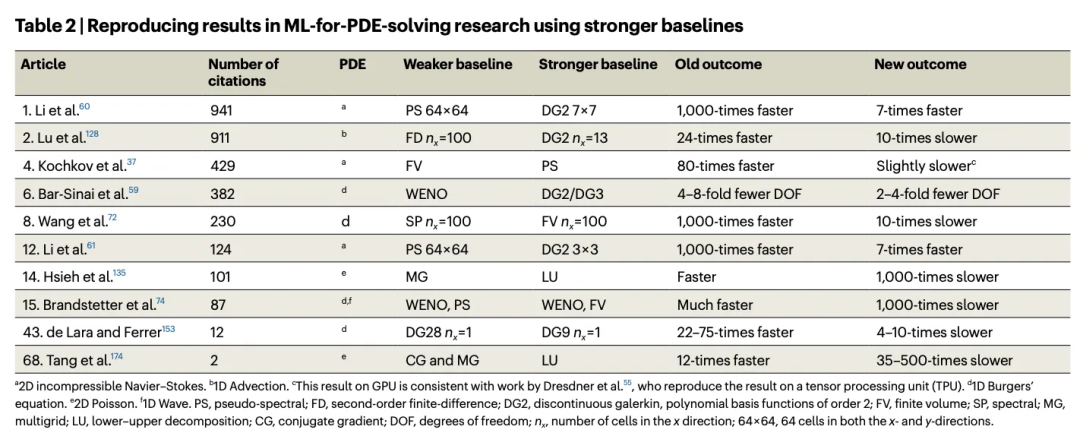
当将求解偏微分方程的 AI 方法与先进基线方法进行比较时,AI 所具有的任何狭义上的优势通常都会消失。
最后,我的导师和我发表了一篇关于使用 AI 解决流体力学偏微分方程研究的系统综述。我们发现,在声称优于标准数值方法的 76 篇论文中,有 60 篇(79%)使用了较弱的基准方法——要么是因为他们没有与更先进的数值方法进行比较,要么是因为他们没有在同等条件下进行比较。所有宣称有大幅提速的论文都选择了弱基准方法进行对比,这表明研究结果越令人印象深刻,其对比可能越不公平。
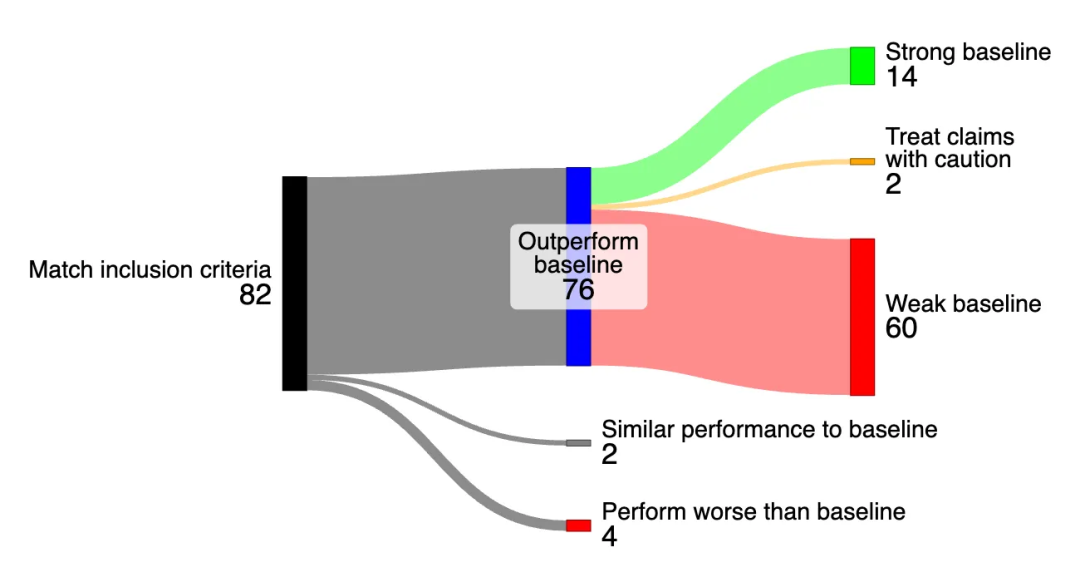
比较了流体力学中求解偏微分方程的 AI 方法与标准数值方法。结果显示,报告负面结果的论文寥寥无几,而报告正面结果的论文大多与较弱的基线进行了比较。
我们还再次发现了研究人员往往不报告负面结果的证据,这种现象被称为报告偏差。基于此,我们得出结论,使用 AI 解决偏微分方程的研究存在过度乐观的情况:“弱基准方法导致结果过于积极,而报告偏差导致负面结果的情况被少报。”
这些发现引发了一场关于计算科学和工程领域中 AI 应用的讨论:
乔治·华盛顿大学(GWU)教授 Lorena Barba 之前在她称之为“愚弄大众的科学机器学习”讨论中指出存在糟糕的研究实践。她认为,我们的研究结果是对“计算科学界对 AI 过度炒作以及缺乏科学依据的乐观情绪”的有力批判。
谷歌研究团队负责人 Stephan Hoyer 也得出了类似的结论,他评价我们的论文是对“为什么我从偏微分方程转向天气预测和气候建模的总结,这些 AI 应用似乎比前者更有前景”。
Johannes Brandstetter 是林茨约翰内斯·开普勒大学的教授,也是一家专注于“AI 驱动物理模拟”的初创公司的联合创始人。他认为 AI 在更复杂的工业应用中有望取得更出色的结果,并且坚信“该领域未来充满希望与潜力”。
在我看来,AI 也许最终会在与求解偏微分方程相关的某些应用中被证明是有用的,但目前我看不到太多乐观的理由。我希望看到更多研究专注于尝试达到标准数值方法的可靠性水平,以及对 AI 方法进行红队测试(Red Teaming)。目前,AI 既缺乏标准数值方法所具有的理论保证,也没有经过实证验证的稳健性。
我还希望看到资助机构激励科学家为偏微分方程创建更具挑战性的问题。一个很好的参考模式是 CASP(蛋白质结构预测竞赛),这是一项每两年举办一次的蛋白质折叠竞赛,在过去 30 年里极大激励了该领域的研究。
AI 真的会加速科学研究吗?
除了蛋白质折叠这个典型的例子外,AI 在科学领域取得进步的其他几个例子还有:
在天气预报方面,AI 预报的准确率比传统的基于物理的预报高出 20%(尽管分辨率仍然较低)。
在药物发现领域,初步数据显示,AI 发现的药物在一期临床试验中的成功率更高(但在二期临床试验中并非如此)。如果这一趋势持续下去,这意味着从头到尾的药物批准率将几乎翻倍。
然而,越来越多的 AI 公司、学术机构、政府部门和媒体不再只是将 AI 视为一种有用的科学工具,而且是一种“将对科学产生变革性影响”的工具。
我认为我们不必完全否定这些说法。据 DeepMind 称,尽管目前的大语言模型“仍在人类科学家所依赖的更深层次的创造力和推理能力上存在困难”,但未来的先进 AI 系统或许有一天能够完全自动化科学过程。我并不认为这会很快发生——即便有可能的话。但如果这样的系统真的被创造出来,毫无疑问,它们将彻底改变并加速科学的发展。
然而,根据我在研究经历中所获得的一些教训,我认为我们应对那些声称“更传统的人工智能技术正按部就班地显著加速科学进步” 的观点持相当谨慎的态度。
众多科学家转向 AI,因对自身有利?
大多数关于“AI 加速科学”的叙述都来自 AI 公司或从事 AI 研究的科学家,这些人直接或间接地受益于这些叙述。例如,英伟达首席执行官黄仁勋声称“AI 将推动科学突破”以及“将科学进程加速数百万倍”。然而,鉴于英伟达存在财务利益冲突,作为叙述者的可信度大打折扣,该公司经常对 AI 在科学领域的作用发表夸张言论。
你或许会认为,科学家越来越多地采用 AI 是 AI 在科学研究中具有价值的有力证明。毕竟,倘若 AI 在科学研究中的应用呈指数级增长,那一定是科学家们发现它极具效用,对吗?
我对此存疑。实际上,我怀疑科学家转向 AI 更多是因为它对他们自身有利,而不是因为它能推动科学进步。
回顾我在 2018 年转向 AI 的初衷,尽管我真心认为 AI 或许能在等离子体物理领域发挥作用,但我的主要动机其实是更高的薪水、更好的就业前景和学术声望。我还注意到,我所在实验室的高层通常似乎对 AI 的筹资潜力更感兴趣,而非对技术本身的考量。
后来的研究发现,使用 AI 的科学家更有可能发表被高度引用的论文,并且平均获得的引用次数是其他科学家的三倍。鉴于使用 AI 所带来的巨大收益,众多科学家纷纷投身其中,也就不足为奇了。
因此,即使 AI 在科学中取得了真正令人印象深刻的成果,这也不一定意味着 AI 对科学做出了什么实质性的贡献,而更多只是反映出 AI 在未来可能发挥重要作用的潜力。
这是因为从事 AI 研究的科学家(包括我自己在内)通常会采用一种反向研究模式。我们不是先确定问题,然后试图找到解决方案,而是先假设 AI 就是解决方案,然后去寻找要解决的问题。然而,由于很难确定哪些开放性的科学挑战可以用 AI 来解决,这种“拿着锤子找钉子”的研究模式往往导致研究人员去处理那些虽然适合用 AI 解决,但要么已经被攻克,要么无法产生新的科学知识的问题。
为了准确评估 AI 对科学领域的影响,我们需要真正去审视科学本身。遗憾的是,科学文献并不能作为评判 AI 在科学中成功与否的可靠依据。
一个关键问题是幸存者偏差。正如一位研究人员所指出的那样,AI 研究“几乎完全不发表负面结果”,所以我们通常只看到 AI 在科学领域取得的成功,而不是失败。但如果没有负面结果,我们对 AI 在科学中影响的评估往往会被扭曲。
但凡研究过“可重复性危机”的人都知道,幸存者偏差是科学领域的重大问题。通常,其根源在于筛选机制——那些缺乏统计学显著性的结果会被排除在科学文献之外。
例如,下图显示的是医学研究中 z 值的分布情况。介于 -1.96 和 1.96 之间的 z 值表明结果不具有统计学显著性。而围绕这些值出现的明显不连续性则暗示,许多科学家要么没有发表介于这些值之间的结果,要么对数据进行了篡改,直至达到统计显著性的阈值。
问题是,如果研究人员未能发表负面结果,可能会导致医疗从业者和公众高估医疗手段的有效性。
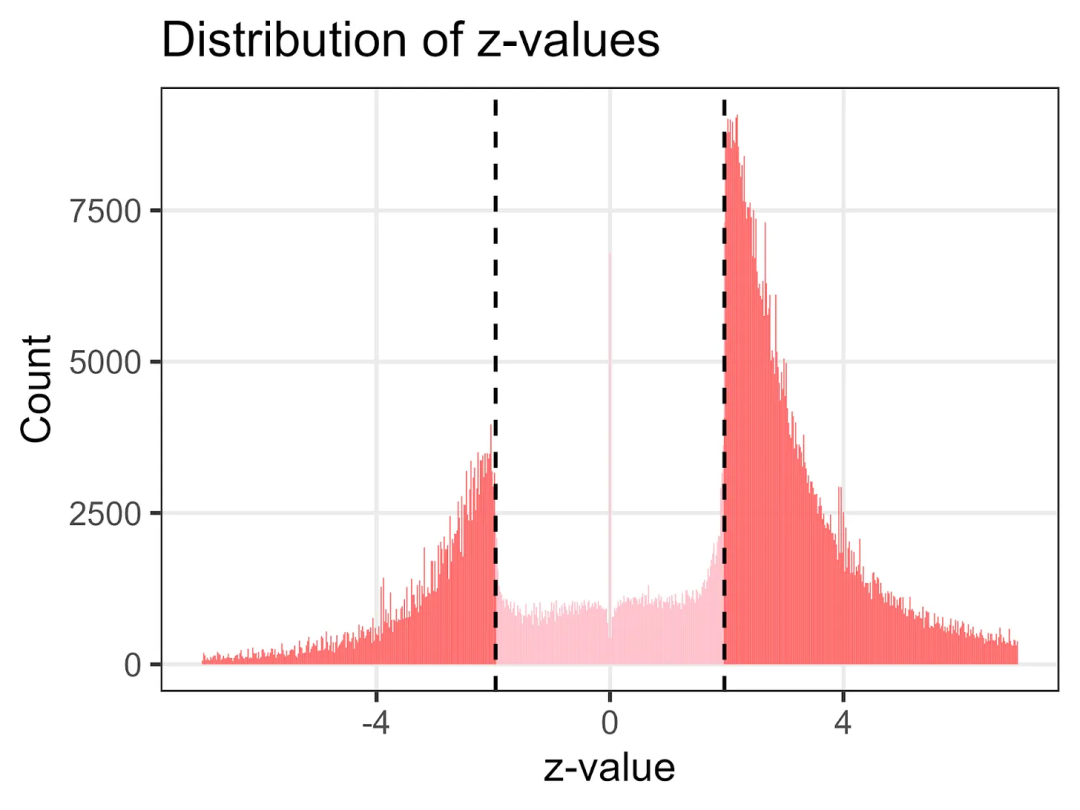
来自医学研究的 100 多万个 z 值的分布情况。负结果(z 值介于 -1.96 和 1.96 之间的结果)大多缺失。
在“AI 促进科学”( AI-for-science)领域中,也出现了类似的现象,尽管选择过程不是基于统计显著性,而是取决于所提出的方法是否优于其他途径或成功执行某些新任务。这意味着,研究人员几乎总是报告 AI 的成功案例,而很少在 AI 未能成功时发表相关结果。
第二个问题是,一些陷阱往往会导致人们根据已发表的成功结果对 AI 在科学领域的潜力得出过于乐观的结论。这些陷阱的细节和严重程度似乎因领域而异,但大多可以可归为以下四类:数据泄露、弱基准方法、挑选有利结果以及错误报告。

评估 AI 模型的人,往往也是从这些评估中受益的人。
尽管导致这种过度乐观倾向的原因颇为复杂,但核心问题似乎在于一种利益冲突:那些负责评估 AI 模型的人,往往也是从这些评估结果中受益的一方。
这些问题似乎相当严重,以至于我不得不建议人们对待 AI-for-science 应用中的那些令人印象深刻的结果,应像对待营养学中的惊人结论一样:本能地保持怀疑态度。
原文链接:
https://www.understandingai.org/p/i-got-fooled-by-ai-for-science-hypeheres




