
在 Uber,我们有兴趣调查乘客在平台上完成首次乘坐到第 2 次乘坐之间的时间跨度。我们的很多乘客是通过推荐或促销活动首次与 Uber 进行互动的。他们的第 2 次乘坐是个关键指标,表明乘客在使用平台的过程中发现价值并愿意长期使用我们服务。然而,对第 2 次乘坐时间建模是件棘手的事。例如,一些乘客不经常乘车。在分析这类乘客的第 2 次乘坐之前的时间-事件数据时,我们认为他们的数据就是截尾数据。
在其他公司和行业中都存在类似的情况。例如,假设某个电商网站对客户经常性购买模式感兴趣。但是,由于客户行为模式的多样性,该公司也许无法观察到所有客户的所有经常性购买行为,从而导致截尾数据的产生。
在另一个例子中,假设某个广告公司对其用户的重复点击行为感兴趣。由于每个用户的兴趣不同,该公司无法观察到其用户的所有点击行为。用户也许在研究结束后才点击广告。这样就会产生到下一次点击数据的截尾时间。
在截尾的时间-事件数据建模中,对用 索引的每个感兴趣的个体,我们都可以以下面的形式观察数据:
其中,是截尾标识。如果观察到感兴趣的事件,那么;如果感兴趣的事件截尾,那么。当时, 表示感兴趣的时间-事件。当,那么代表截尾发生之前的时间长度。
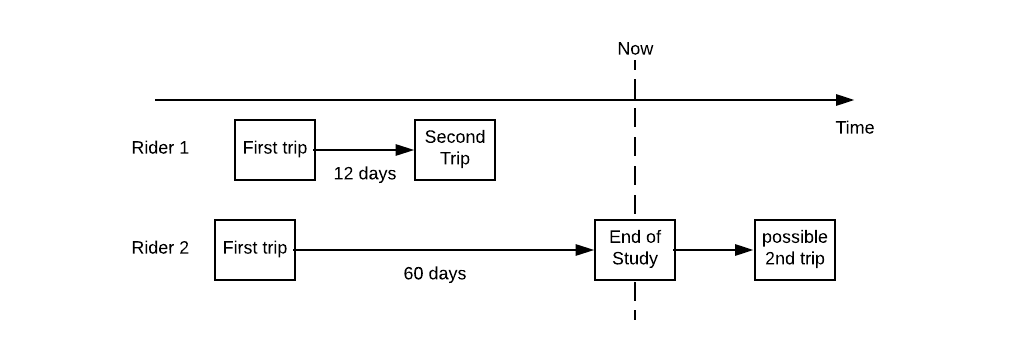
我们继续讲 Uber 的第 2 次乘坐时间的例子:如果某个乘客在其首次乘坐 12 天后才进行第 2 次乘坐,那么该观察就记录为(12,1)。在另一种情况下,如果某个乘客在首次乘坐后过去了 60 天,并且在给定的截止日期前还没返回到应用程序进行第 2 次乘坐,那么该观察就记录为(60,0)。这种情形如下图所示:
在该领域有大量的分析文献,并且研究时间已经有一个多世纪之久;其中大部分可以用统计编程框架进行简化。在本文中,我们将介绍如何使用Pyro概率编程语言来为截尾的时间-事件数据建模。
与流失建模之间的关系
在我们继续之前,值得一提的是,很多行业从业者通过人为设置“流失”标签的方式来规避截尾的时间-事件数据的挑战。例如,如果一家电商的客户在过去 40 天中没有回到网站进行另一次购买,那么该电商可以把该客户定位为“流失”。
流失建模使得从业者把观察转换为经典的二元分类模式。因此,流失建模就会像使用 scikit-learn 和 XGBoost 这样的现成工具那么简单。例如,上述的两位乘客将分别被标注为“未流失”和“流失”。
尽管流失模型在特定情形下是可行的,但其不一定适用于 Uber。例如,某些乘客只在出差时使用 Uber。如果该假设的乘客每 6 个月出一次差,那么我们最终就会把该商务乘客误标注成“流失”。因此,我们从流失模型中提取的结论可能产生误导。
我们也有兴趣从这些模型中进行解释,以阐明不同因素对观察到的用户行为的影响。因此,模型不应该是个黑匣子。我们希望能够开放该模型并用它做出更明智的业务决策。
为了实现这一点,我们可以将 Pyro 这一灵活且富有表现力的开源工具用于概率编程。
用于统计建模的 Pyro
创建于 Uber 的 Pyro 是用 Python 编写的通用概率编程语言,构建于 PyTorch 张量计算库的基础之上。
如果你具有最小贝叶斯建模知识的统计背景,或是你一直在用 TensorFlow 或 PyTorch 这样的深度学习工具,那么你的运气很好。
下表总结了一些最受欢迎的概率编程项目:
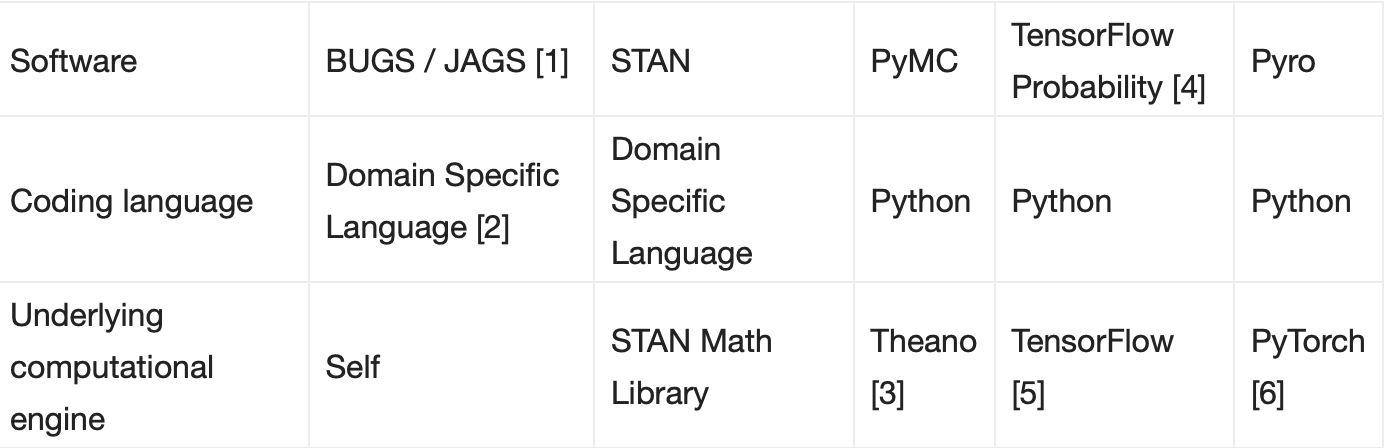
下面,我们将重点介绍这些不同软件项目的一些关键特性:
BUGS/JAGS 是概率编程早期的例子。在统计领域,它们已经被积极开发和使用了 20 多年。
但是,BUGS/JAGS 主要是从头设计和开发的。因此,模型规范是用它们特定于域的语言完成的。此外,概率程序开发人员需要从 R 和 MATLAB 中的包装器中调用 BUGS/JAGS。用户必须在编码语言和文件之间来回切换,不太方便。
PyMC 依赖于 Theano 后端。但是,Theano 项目最近停止了。
TensorFlow Probability(TFP)最初作为一个名为 Edward 的项目启动。该 Edward 项目已纳入 TFP 项目。
TFP 使用 TensorFlow 作为其计算引擎。因此,其仅支持静态计算图。
Pyro 使用 PyTorch 作为计算引擎,因此支持动态计算图。这使得用户能够在数据流方面指定不同的模型,非常灵活。
简而言之,Pyro 基于最强大的深度学习工具链(PyTorch),同时具有数十年统计研究的支持。因而它是一种非常简洁和强大、但又灵活的概率建模语言。
对截尾的时间-事件数据建模
现在,让我们深入研究如何为时间-事件数据建模。感谢谷歌 Colab,用户得以无需安装 Pyro 和 PyTorch 就可以查看大量代码示例并开始为数据建模。我们甚至可以复制工作簿并在其上进行各种尝试。
模型定义
鉴于本文的目的,我们把时间-事件数据定义为,其中表示时间-事件,表示二进制截尾标签。我们把实际的时间-事件定义为,它可以是没有观察到的。为了简单起见,我们把截尾时间定义为, 并假设它是个已知的固定数字。综上所述,我们可以把这关系建模为:
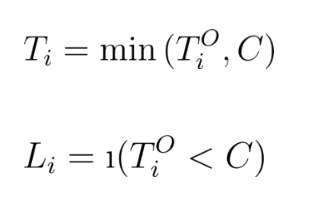
我们假设遵循带有尺度参数的指数分布,变量与感兴趣的预测因子存在以下线性关系:
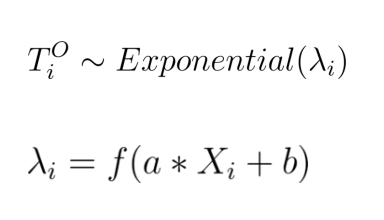
其中,是个 softplus 函数,从而确保保持为正。最后,我们假设和遵循正态分布作为先验分布。鉴于本文的目的,我们感兴趣的是评估和的后验分布。
生成人工数据
首先,我们导入所有必要的 Python 包:
为了生成实验数据,我们运行以下几行脚本:
恭喜你!你刚刚在 Note[1]所在的行运行了你的第一个 Pyro 函数。在这里,我们从正态分布中采了样。细心的用户也许已经注意到,这种直观的操作和我们在 Numpy 中的工作流程非常相似。
在上述代码段的末尾(Note 2),我们分别生成了一个(绿色)和(蓝色)对的回归图。如果我们不考虑数据截尾,那么就低估了模型的斜率。
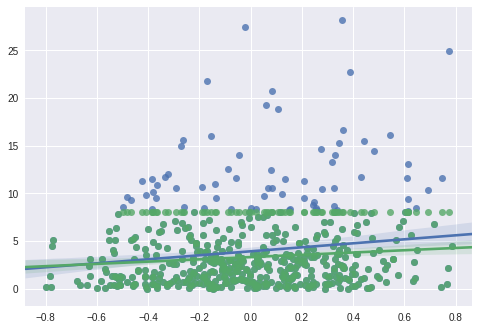
图 1. 这个散点图描述了实际的底层事件时间和相对于预测器的观察到的事件时间。
构建模型
借助这些新鲜但截尾的数据,我们可以开始构建更精确的模型。让我们从下面的模型函数开始:
在上面的代码段中,我们重点解释以下注释,以更好地阐明我们的示例:
Note 1:总的来说,模型函数描述的是数据生成的过程。这个示例模型函数告诉我们如何从输入的矢量 x 生成 y 或 truncation_label。
Note 2:我们指定这里和的先验分布,并利用 pyro.sample 函数对它们采样。Pyro 在 PyTorch 项目和 Pyro 项目中都有大量的随机分布。
Note 3: 在这里,我们把输入,和接入用变量 link 表示的矢量。
Note 4:我们利用带有尺度参数矢量链接的指数分布来指定真实时间-事件的分布。
Note 5:对于观察 i,如果我们观察到时间-事件数据,那么我们把它和实际观察 y[i]进行对比。
Note 6:如果对于观察,数据是截尾的,那么截断标签(这里等于 1)遵循伯努利分布。在点,观察到截断数据的概率是的 CDF。我们从伯努利分布中采样,并将其与 truncation_label[i]的实际观察结果进行对比。
有关贝叶斯建模和使用 Pyro 的更多信息,请参考我们的入门教程。
用哈密顿•蒙特•卡罗方法(Hamiltonian Monte Carlo,简称 HMC)计算推理
在计算贝叶斯推理时,哈密顿•蒙特•卡罗方法是一种常用的方法。我们用 HMC 来估计 a 和 b,如下所示:
上述过程可能需要很长时间来运行。这么慢的主要原因是,我们需要通过依次观察来评估模型。为了加速该模型,我们可以用pyro.plate和pyro.mask进行矢量化,如下所示:
在上面的代码段中,我们首先使用指定的模型来指定 HMC 内核。然后,我们对 x,y 和 truncation_label 执行 MCMC。接着,将 MCMC 采样的结果对象转换为 EmpiricalMarginal 对象,以帮助我们根据 a_model 参数进行推理。最终,我们从后验分布采样,并利用我们的数据绘制出一张图,如下所示:
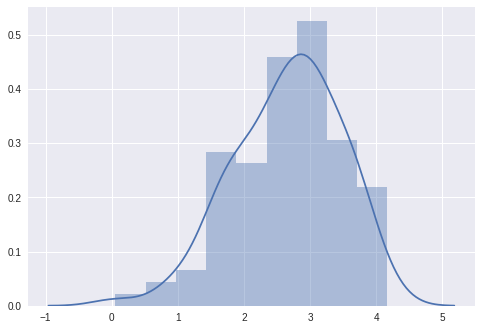
图 2:a 的采样值直方图。
我们可以看到,这些样本集中在实际值 2.0 附近。
利用变分推理加速估计
随机变分推理(Stochastic variational inference,简称SVI)是利用大量数据加速贝叶斯推理的好方法。现在,我们只需要知道导函数是期望后验分布的近似即可。导函数的指定可以大大加快参数的估计。为了实现随机变分推理,我们定义导函数为:
通过使用导函数,我们可以把参数 a 和 b 的后验分布近似为正态分布,其中它们的位置和尺度参数分别由内部参数指定。
训练模型并推断结果
用 Pyro 训练模型的过程和深度学习中的标准迭代优化类似。下面,我们指定 SVI 训练器并通过优化步骤进行迭代:
如果一切如计划所愿,那么我们可以看到上述代码的执行结果。在本例中,我们得到的结果如下,其均值与实际的值及指定的值非常接近:
我们还可以检查模型是否通过下面的代码聚合,并得到图 3,如下所示:
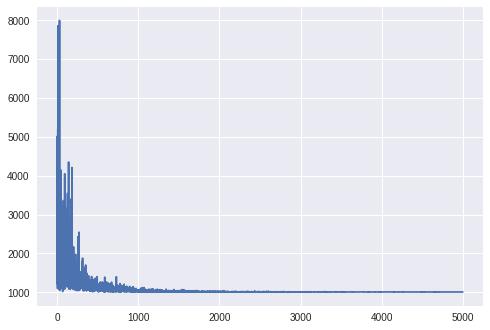
图 3:针对迭代次数绘制的模型损失
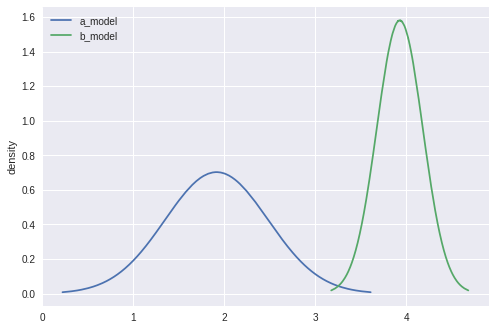
我们可以使用guide.quantiles()函数来绘制近似后验分布:
我们可以看到,导函数分别集中于和的实际值附近,如下所示:
其他
我们希望读者在自己的截尾时间-事件数据建模上试试 Pyro。关于如何开始使用该开源软件,请参考Pyro的官方网站,以获得其它示例,包括入门教程和沙箱库。
阅读英文原文:Modeling Censored Time-to-Event Data Using Pyro, an Open Source Probabilistic Programming Language,
https://eng.uber.com/modeling-censored-time-to-event-data-using-pyro/

暂无签名

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...












评论