

在之前的文章中,我们了解了 Kubernetes 中的基本概念,其硬件结构,不同的软件组件(例如 Pod、Deployment、StatefulSet、Services、Ingress 和 Persistent Volumes),并了解了如何在服务之间与外部进行通信。
在本文中,我们将了解到:
使用 MongoDB 数据库创建 NodeJS 后端
编写 Dockerfile 来容器化我们的应用程序
创建 Kubernetes Deployment 脚本以启动 Pod
创建 Kubernetes Service 脚本以定义容器与外界之间的通信接口
部署 Ingress Controller 以请求路由
编写 Kubernetes Ingress 脚本来定义与外界的通信。
由于我们的代码可以从一个节点重定向到另一个节点(例如,一个节点没有足够的内存,所以工作将重新调度到另一个具有足够内存的节点上),因此保存在节点上的数据容易丢失 ,意味着 MongoDB 数据不稳定。在下一篇文章中,我们将讨论数据持久性问题以及如何使用 Kubernetes 持久卷安全地存储我们的持久数据。
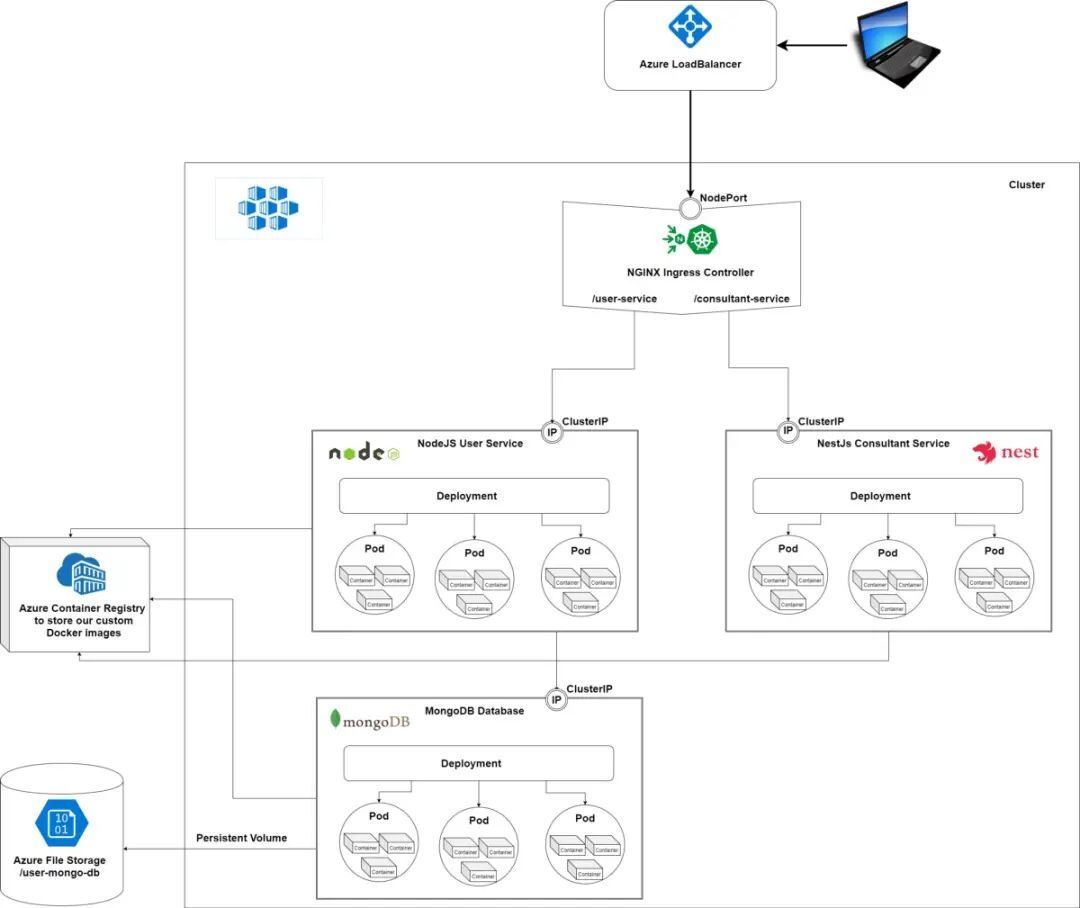
在本文中,我们将使用 NGINX 作为 Ingress Controller 和 Azure 容器镜像仓库来存储我们的自定义 Docker 镜像。文中编写所有脚本都可以在 Stupid Simple Kubernetes git repo 中找到,如有需要可访问链接获取:http://GitHub - CzakoZoltan08/StupidSimpleKubernetes-AKS
请注意:这些脚本不限定于某个平台,因此您可以使用其他类型的云提供程序或带有 K3s 的本地集群来实践本教程。我之所以建议使用 K3s,因为它非常轻量,所有依赖项都被打包在一个小于 100MB 的单个二进制文件中。更重要的是,它是一种高可用的、经过 CNCF 认证的 Kubernetes 发行版,专门用于资源受限的环境中的生产工作负载。有关更多信息,您可以访问官方文档:
前期准备
在开始本教程之前,请确保您已安装 Docker。同时也要安装 kubectl。
Kubectl 安装链接:
https://kubernetes.io/docs/tasks/tools/#install-kubectl-on-windows
在本教程中使用的 Kubectl 命令可以在 Kubectl cheat sheet(https://kubernetes.io/docs/reference/kubectl/cheatsheet/)中找到。
在本教程中,我们将使用 Visual Studio Code,但这不是必要的,你也可以使用其他的编辑器。
创建可用于生产的微服务架构
将应用程序容器化
第一步,创建 NodeJS 后端的 Docker 镜像。创建镜像后,我们会将其推送到容器镜像仓库中,在该镜像仓库中可以访问它,并且可以通过 Kubernetes 服务(在本例中为 Azure Kubernetes Service)拉取。
在第一行中,我们需要根据要创建后端服务的镜像进行定义。在这种情况下,我们将使用 Docker Hub 中 13.10.1 版的官方节点镜像。
在第 3 行中,我们创建一个目录来将应用程序代码保存在镜像中。这将是您的应用程序的工作目录。
该镜像已经安装了 Node.js 和 NPM,因此下一步我们需要使用 npm 命令安装您的应用程序依赖项。
请注意,要安装必需的依赖项,我们不用复制整个目录,而只需复制 package.json,这使我们可以利用缓存的 Docker 层。
有关高效 Dockerfile 的更多信息,请访问以下链接:
http://bitjudo.com/blog/2014/03/13/building-efficient-dockerfiles-node-dot-js/
在第 9 行中,我们将源代码复制到工作目录中,在第 11 行中,将其暴露在端口 3000 上(如果需要,您可以选择另一个端口,但请确保同步更改 Kubernetes Service 脚本。)
最后,在第 13 行,我们定义了运行应用程序的命令(在 Docker 容器内部)。请注意,每个 Dockerfile 中应该只有一个 CMD 指令。如果包含多个,则只有最后一个才会生效。
现在,我们已经定义了 Dockerfile,我们将使用以下 Docker 命令从该 Dockerfile 中构建镜像(使用 Visual Studio Code 的 Terminal 或在 Windows 上使用 CMD):
请注意 Docker 命令末尾的小圆点,这意味着我们正在从当前目录构建镜像,因此请确保您位于 Dockerfile 所在的同一文件夹中(在本例中,是 repo 的根文件夹)。
要在本地运行镜像,我们可以使用以下命令:
若要将此镜像推送到我们的 Azure 容器镜像仓库,我们必须使用以下格式标记它<container-registry-login-service>/<image-name>:<tag>:,在本例中如下所示:
最后一步是使用以下 Docker 命令将其推送到我们的容器镜像仓库中:
使用部署脚本创建 Pod
NodeJs 后端
接下来,定义 Kubernetes Deployment 脚本,该脚本将自动为我们管理 Pod。
Kubernetes API 可以查询和操作 Kubernetes 集群中对象的状态(例如 Pod、命名空间、ConfigMap 等)。如第一行中所指定,这个 API 的当前稳定版本为 1。
在每个 Kubernetes .yml 脚本中,我们必须使用 kind 关键字定义 Kubernetes 资源类型(Pods、Deployments、Service 等)。因此,你可以看到,我们在第 2 行中定义了我们想使用 Deployment 资源。
Kubernetes 允许您向资源中添加一些元数据。这样一来,您就可以更轻松地识别、过滤和参考资源。
在第 5 行中,我们定义了该资源的规范。在第 8 行中,我们指定此 Deployment 应仅应用于标签为 app:node-user-service-pod 的资源中,在第 9 行中可以看出我们想要创建同一 Pod 的 3 个副本。
Template(从第 10 行开始)定义了 Pod。在这里,我们将标签 app:node-user-service-pod 添加到每个 Pod。这样,Deployment 将识别它们。在第 16 和 17 行中,我们定义了应在 pod 内部运行哪种 Docker 容器。如您在第 17 行中看到的那样,我们将使用 Azure 容器镜像仓库中的 Docker 镜像,该镜像是在上一节中构建并推送的。
我们还可以为 Pod 定义资源限制,避免 Pod 资源不足(当其中一个 Pod 使用所有资源而其他 Pod 无法使用它们时)。此外,当您为 Pod 中的容器指定资源请求时,调度程序将使用此信息来决定将 Pod 放置在哪个节点上。当您为容器指定资源限制时,kubelet 会强制执行这些限制,从而不允许运行中的容器使用超出您设置的资源限制。kubelet 还至少保留该系统资源的“请求”量。请注意,如果您没有足够的硬件资源(例如 CPU 或内存),则永远无法调度 pod。
最后一步是定义用于通信的端口。在本例中,我们使用端口 3000。此端口号应与 Dockerfile 中暴露的端口号相同。
MongoDB
MongoDB 数据库的 Deployment 脚本非常相似。唯一的区别是我们必须指定卷挂载(数据会被保存到节点上的文件夹中)。
在本例中,我们直接从 DockerHub 使用了官方 MongoDB 镜像(第 17 行)。在第 24 行中定义了卷安装。在讨论 Kubernetes 持久卷时,我们将在下一篇文章中解释最后四行。
创建用于网络访问的服务
现在我们已经启动了 Pod,并开始定义容器之间以及与外部世界的通信。为此,我们需要定义一个服务。Service 与 Deployment 之间的关系是一对一的,因此对于每个 Deployment,我们都应该有一个 Service。Deployment 还可以管理 Pod 的生命周期,并且负责监控它们,而 Service 负责启用对一组 Pod 的网络访问。
这个.yml 脚本的重要部分是 selector,它定义了如何识别要从此 Service 引用的 Pod(由 Deployment 创建)。在第 8 行中我们可以看到的,Selector 为 app:node-user-service-pod,因为先前定义的 Deployment 中的 Pod 被标记为这样。另一个重要的事情是定义容器端口和服务端口之间的映射。在这种情况下,传入请求将使用第 10 行中定义的 3000 端口,并将它们路由到第 11 行中定义的端口。
MongoDB pod 的 Kubernetes Service 脚本非常相似。我们只需要更新 Selector 和端口。
配置外部流量
为了与外界通信,我们需要定义一个 Ingress Controller 并使用 Ingress Kubernetes 资源指定路由规则。
要配置 NGINX ingress controller,我们将使用可以以下链接中的脚本:
这是一个通用脚本,无需修改即可应用(详细解释 NGINX Ingress Controller 不在本文讨论范围之内)。
下一步是定义“负载均衡器”,该负载均衡器将用于使用公共 IP 地址路由外部流量(云提供商提供负载均衡器)。
现在我们已经启动并运行了 Ingress controller 和负载均衡器,于是我们可以定义 Ingress Kubernetes 资源来指定路由规则。
在第 6 行中,我们定义了 Ingress Controller 类型(这是 Kubernetes 的预定义值;Kubernetes 当前支持和维护 GCE 和 nginx controller)。
在第 7 行中,我们定义了重写目标规则,在第 10 行中,我们定义了主机名。
对于应该从外部访问的每个服务,我们应该在路径列表中添加一个条目(从第 13 行开始)。在此示例中,我们仅为 NodeJS 用户服务后端添加了一个条目,可通过端口 3000 对其进行访问。/ user-api 唯一标识我们的服务,因此任何以 stupid-simple-kubernetes.eastus2.cloudapp azure.com/user-api 开头的请求将被路由到此 NodeJS 后端。如果要添加其他服务,则必须更新此脚本(请参见注释掉的代码)。
应用.yml 脚本
要应用这些脚本,我们将使用 kubectl。应用文件的 kubectl 命令如下:
在本例中,如果你在 StupidSimpleKubernetes repo 的根文件夹中,您需要执行以下命令:
应用这些脚本后,一切准备就绪,进而我们可以从外部调用后端(如使用 Postman)。
总结
在本教程中,我们学习了如何在 Kubernetes 中创建各种资源,例如 Pod、Deployment、Services、Ingress 和 Ingress Controller。我们使用 MongoDB 数据库创建了一个 NodeJS 后端,并使用 3 个 pod 的副本容器化并部署了 NodeJS 和 MongoDB 容器。
在下一篇文章中,我们将了解持久保存数据的问题,并将介绍 Kubernetes 中的持久卷。
作者简介
Czako Zoltan,一位经验丰富的全栈开发人员,在前端,后端,DevOps,物联网和人工智能等多个领域都拥有丰富的经验。
本文转载自:RancherLabs(ID:RancherLabs)

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论