

可解释性,已经成为当今机器学习研究与开发领域最紧迫的难题之一。尽管目前的大规模语言模型(LM)已经展现出令人印象深刻的问答能力,但其固有的不透明性却导致人们无法理解模型如何得出最终答案,因此用户难以论证答案合理性、也不易发现答案中的潜在错误。
DeepMind 研究团队在最新论文《使用大型语言模型实现可信推理》(Faithful Reasoning Using Large Language Models)中解决了这个问题。论文提出一套前向链选择推理模型,能够执行忠实推理并提供有效的推理跟踪,用以提高推理质量并帮助用户检查 / 验证最终答案。

论文地址:
https://www.researchhub.com/paper/1272848/faithful-reasoning-using-large-language-models
如何利用因果逻辑原理提高推理质量?
为了突破机器学习可解释性这道难关,DeepMind 研究团队在论文中展示了如何通过因果结构反映问题的潜在逻辑结构,借此过程保证语言模型忠实执行多步推理。研究团队的方法会将多个推理步骤联系起来共同起效,其中各个步骤均会调用两套经过微调的语言模型:其一用于选择,其二用于推理,借此产生有效的推理跟踪。
该方法还会对推理轨迹空间执行定向搜索,借此提高推理质量。
论文中提出的方法基于这一基本思想:如果给定问题的潜在逻辑结构,可以通过因果结构来反映,则语言模型可以忠实执行多步推理。为了实现这个目标,DeepMind 团队开发出选择推理(SI)作为系统主干。作为一种新颖架构,其中包含两套经过微调的语言模型,一套用于选择、一套用于推理。
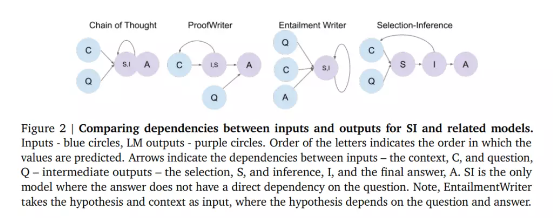
分步前向推理主干会将各个推理步骤拆分为两个:
1)给定一个问题,由选择模型首先从上下文中选择一组语句;
2)推理模型随后从选择中计算一个语句,预测其含义(推理)
在推理步骤结束时,该推理会被添加至上下文内。通过迭代整个选择与推理过程,模型即可产生推理轨迹,而最终推理将用于回答问题。
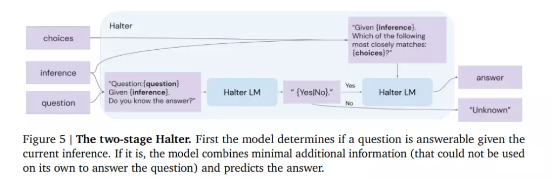
为了让模型能够确定何时停止推理,该团队还引入了一个两段式 halter。它会利用微调的语言模型来预测该模型能否在当前推理之下回答给定问题。如果模型无法以高置信度回答问题,则执行另一次选择推理迭代;如果 halter 的输出就是答案,则终止此过程并返回答案。假设选择推理循环持续到预先指定的迭代次数,但仍未得出答案,则系统不会直接给出最佳猜测、而是返回 “未知”。
研究人员观察到,在删除掉模型认为无法忠实回答的问题之后,模型性能得到显著提高。他们相信,这种方法有助于提高模型在以精确度(而非召回率)为优先的现实世界中的可信度与安全性。
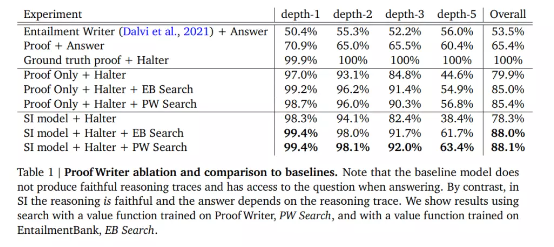

实际效果
在这次实证研究中,该团队将自己的选择推理系统与 Proof Writer(PW)和 EntailmentBankQA(EB)数据集上的基准模型进行了比较。他们提出的模型在 PW 和 EB 上分别实现了 88.1% 和 78.1% 的最终答案准确率,大大优于基准模型。
这项工作表明 DeepMind 提出的新方法确实能在不牺牲模型性能的前提下,通过多步推理对问题做出忠实回答。虽然该研究目前只侧重于给定上下文中的多步骤推理,但该团队已经计划在未来的工作中利用检索进一步充实上下文信息。
从实际性能来看,尽管存在“只能执行可信推理”的限制,该模型的实际表现仍然非常出色。考虑到如果一项技术要想安全普及、为大众所接受,就必须能够通过审计检验,此次研究可能代表语言模型正向着可解释性迈出重要一步。
原文链接:
https://www.researchhub.com/paper/1272848/faithful-reasoning-using-large-language-models
公众号推荐:
AGI 概念引发热议。那么 AGI 究竟是什么?技术架构来看又包括哪些?AI Agent 如何助力人工智能走向 AGI 时代?现阶段营销、金融、教育、零售、企服等行业场景下,AGI应用程度如何?有哪些典型应用案例了吗?以上问题的回答尽在《中国AGI市场发展研究报告 2024》,欢迎大家扫码关注「AI前线」公众号,回复「AGI」领取。


加V:busulishang4668

分布式云行业实践指南(2023)
业内首个分布式云行业实践方法论、工具箱。







评论