
欢迎阅读新一期数据库内核杂谈。一言难尽的 2020 终于就要过去了。在这里,祝大家新年快乐,希望 2021 年对所有人都充满惊喜。
这一期的内核杂谈来聊一个公司 Datometry,以及它的核心技术 Hyper-Q: Database Virtualization(数据库虚拟化)。契机是最近在 CMU 数据库教授 Andy Pavlo 组织的 Quarantine Tech Talks 上,Datometry 的 principal research scientist Lyublena 做了一次关于 Datometry 的技术分享。笔者于 2014~2017 年在 Datometry 工作,这是笔者第一次初创公司的经历。当时就在一个共享办公的小 cube 里,三个人,埋头写代码。那段时间虽然超级忙,但感觉成长超级快,几乎是完全 build everything from scratch。每每想到,还是充满感激。查了一下 CrunchBase, 截止今年 2 月的 Series B,总共融资了 34M。作为曾经的 Employee No.1,衷心祝愿公司好好发展。
这期的分享主要结合 Datometry 最新的文章Rapid Adoption of Cloud Data Warehouse Technology Using Datometry HyperQ,以及上面的 Youtube 视频。
愿景(Vision)
用一句话来概括 Datometry 的愿景就是,解决数据库迁徙的难题。市场上有各种各样的数据库,特别是这几年,随着云计算的普及,云原生的数据库一路高奏凯歌。技术架构,包括数据库系统向云端迁徙是大势所趋。
但是迁徙数据库系统到另一个数据库系统是一件非常困难且风险极高的任务,首先是要确保原数据库系统和新数据库系统的功能兼容性,无论从数据存储,支持数据类型,事务支持,等等。更加困难的是业务语句的迁徙,不仅要确保 SQL 语义上的兼容性(如果在 SQL 语句中使用了非 ANSI-standard 的原数据库 dialect,迁徙的时候就要特别注意),更头疼的就是接口的兼容性。如果是用 JDBC/ODBC 这类标准接口,难度相对较小。但是,如果接口是数据库原生客户端,比如,很多商业银行会使用 Teradata 作为数据仓库来做报表分析。它们有着大量的,可能很久都没人碰过的 BTEQ(Teradata 原生客户端接口)编写的脚本来处理数据。迁徙这类业务的困难度可想而知(编写脚本的程序员可能早就退休了,很可能都没人能读懂那些语义)。引用 Gartner 的一段声明“Over 60% of database migrations are behind schedule, overrun budgets, and fail utlimately”。
现有的方法无非两种,一是,公司自己组建团队(或者外包给第三方)来进行数据库迁徙,把迁徙当成一个系统问题来对待。建立详细的迁徙计划,包括,数据转移,业务转移,兼容性正确性测试,到最终上线。通常,这个过程可能持续一到几年,而且失败的风险很高。二是,选择接口兼容的新数据库。很多新的数据库包括云端的数据库都会选择兼容开源的数据库系统接口比如 MySQL 和 Postgres,主要的原因之一就是大量的现有系统都使用这两类数据库系列产品,能做到接口兼容,那迁徙的难度就几乎为零了。
当时在 Datometry,目标很明确,就是要做到完全无缝地帮助客户做数据库迁徙:客户端逻辑在不需要做任何改动的前提下,将业务迁徙到新数据库系统。现在想想,还真是一个非常宏大的愿景。首要解决的就是那些商业银行客户的痛点,Teradata 很贵,云端数据库是未来趋势,希望能够将整个数据库系统都迁徙到云端,但是整个业务线都是大量的遗留脚本,迁徙难度太大了。
读到这里,可以暂停一下,如果让你去实现上述的目标,你会怎么去做架构?
数据库虚拟化(Database Virtualization)
Datometry 推出的技术就是数据库虚拟化(Database Virtualization),更确切的说是,Adaptive data virtualization ADV(这个术语出现在最新的 paper 中,暂时还没想到很好的翻译)。要使得现有的业务逻辑(作用于原数据库系统中),可以无缝地,不做任何修改地运行在新的云端数据库系统(或者其他数据库系统上),ADV 的架构关键在于,在业务逻辑层和新数据库系统之间构建一个中间件平台 Hyper-Q,可以实时地捕获业务层发来的各种数据库请求(基于原数据库的),并且,实时地将请求进行解析,转换成语义相同的基于新数据库的语句请求发送给后端的新数据库。在得到请求结果后,再次实时解析,转换成原数据库兼容的结果信息返回给业务逻辑层。Hyper-Q 相当于一个数据库转接头,完全对业务层屏蔽了后端的数据库系统实现,让业务逻辑层依然觉得自己还再和原数据库系统交互。下图给出了架构示例图:
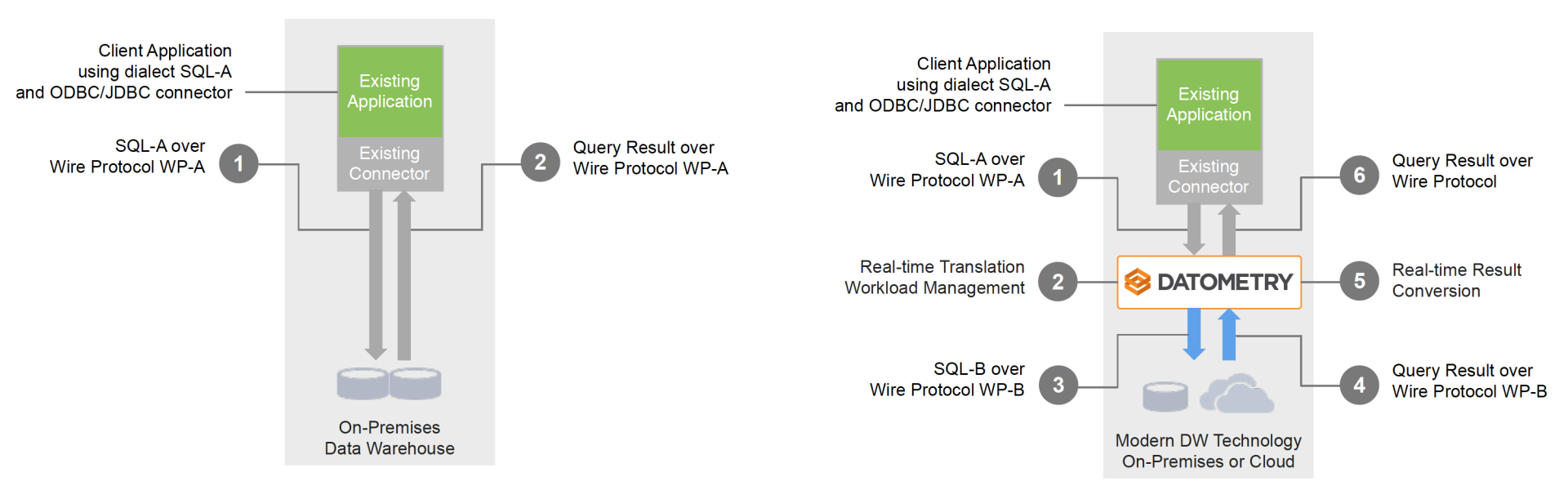
ADV 对于数据库迁徙任务带来了如下的优势:
快速搭建:部署 Hyper-Q 非常容易,对于客户端而言,仅需要更换一下数据库连接的 IP 和端口(端口甚至都不需要改变)。当然,还需要在新的数据库中构建相同的数据库环境。比起传统的迁徙任务(可能需要几个月才能初见成效),更加敏捷。
降低成本:相对于重写或者迁徙整个业务逻辑层,使用 Hyper-Q 的成本会更低(当然我现在也不知道 Hyper-Q 是怎么卖的 :))
降低风险:Hyper-Q 支持 test run,在运行业务端逻辑的时候,记录下哪些语句已经被支持,哪些还暂不支持,最终可以生成一份分析清单来告知用户有百分之多少的逻辑是已经支持的。并对于暂不支持的给出解决方案。
技术细节
聊完了大体架构,来说说技术细节。
数据迁徙
不知大家注意到没,从始至终,我一直强调的是业务迁徙。为什么?因为数据迁徙,我认为,已经是一个解决了的问题。首先,绝大部分的数据库对于常见数据类型,索引类型的支持,特别是那些写在 ANSI 标准里的,支持的都很好,很全面。因此,对于表,库的迁徙是没有太多难度的。其次,由于竞争的关系,很多数据库都支持一键从其他数据库导入数据,对于用户来说,几乎是零难度。
业务迁徙
业务迁徙的难点有二:1)接口以及传输格式的支持,和 2)SQL 语句的支持。
先来说第一点:接口以及传输格式的支持。业务逻辑层可能使用 ODBC/JDBC 这种标准接口,也可能会使用原生数据库客户端(native DB libraries)。读者可能觉得,如果使用 ODBC/JDBC 这类接口,是不是就没有难点了,只要换个实现就行了。但是,魔鬼都在细节中,当你试图去替换接口时,就会发现,不同数据库的接口实现并不是完全兼容的,甚至,同一款产品的不同版本的 ODBC 接口都不兼容。对于业务层使用原生数据库客户端,就更困难了,没有接口可以替换。Hyper-Q 的解决方案是,对于要替换的原数据库系统,直接适配底层的 wire protocol。相当于能够直接解析原生客户端送来的请求。插一句题外话,Hyper-Q 是用 Erlang 语言实现的,对于底层的 binary protocol 的解析很有优势。笔者也是在那个时候第一次写 Erlang 这个小众语言,现在在 WhatsApp,依然使用 Erlang。这样做,虽然从技术难度,工作量来说都更难,更大。但好处也是显而易见的:1)由于 ODBC/JDBC 标准接口在和原数据库连接时,也是走 wire protocol,因此相当于直接适配各种接口。2)做到了对于业务层来说,百分百的虚拟化,完全屏蔽了后端数据库的差异。
对于难点 2),先来看下面这则 SQL 语句:

这是一个完全符合 Teradata SQL 标准的 SQL 语句。虽然,对于很多其他数据库而言,都会不知所云:1)数据方言:SEL -> SELECT; 2)数据类型 1140101 -> DATE 类型,3)Vector subquery:(AMOUNT, AMOUNT * 0.85) > (SEL GROSS, NET FROM SALS_HISTORY),以及 4)QUALIFY RANK(AMOUNT DEC) > 10 是 Teradata 特有的 qualify 语法。这仅仅是冰山一角,当时组里讨论为什么 Teradata 的 SQL 和 ANSI-标准完全不一致,得到的答案是,Teradata 那个时候还没有标准呢,因此,想怎么定义就怎么定义。如果,你是一个对于原数据库系统和新数据库系统都富有经验的 DBA,可能会知道如何重写语句,来实现相同的语义。Hyper-Q 要做的就是自动化这个语句重写的过程,并且,可以适配多个数据库系统之间的语义差异。重写语句,曾经在讲数据库优化器提到过这个技术。没错,Hyper-Q 的语句重写用到的技术和优化器中的语句重写是异曲同工的。因此也不难解释,当时
Orca优化器中一半的作者,包括我在内,都加入了 Datometry,相当于接着做老本行。
具体架构
最后,根据下图的 Hyper-Q 架构细节图一起来看它是怎么工作的。
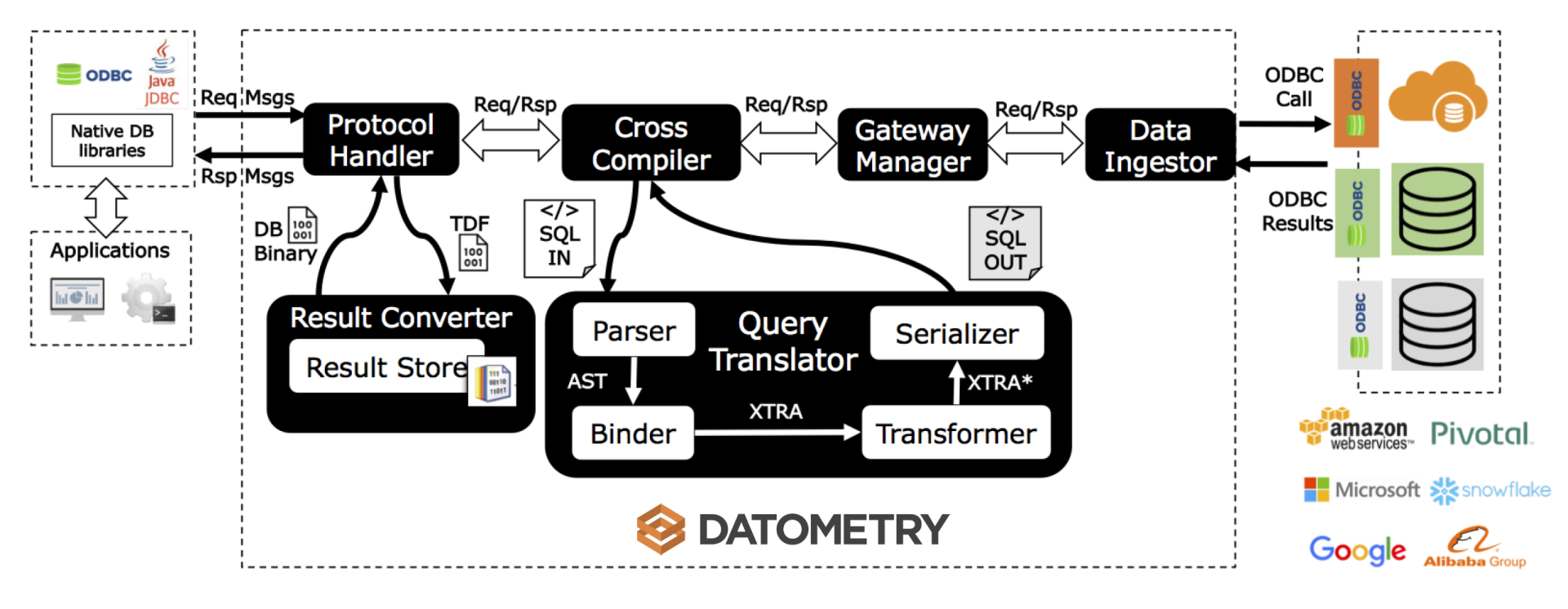
1)首先是上文提及的 Protocol Handler,用来对接业务逻辑层,并且完全理解原数据库的 wire protocol。上文只是提及了数据库请求语句的转换,但同时,Protocol Handler 还需要对结果集进行转换(Rsp Msgs),因此还连接了 Result Converter。由于不同数据库的 wire protocol 格式不同,有时候需要 Hyper-Q 暂存结果集。举个例子,Postgres 对于结果集的 wire protocol 是不需要提前告知客户端一共有多少条结果返回的,但是,Teradata 则不同,wire protocol 需要知道总共有多少条结果返回来提前生成 buffer,因此,如果是适配后端 Postgres 系列数据库,Result Converter 需要缓存所有的结果来得到最终数目。
2)Cross Compiler 解决的是 SQL 语句的重写问题。稍微聊一下细节。试想,Hyper-Q 要适配 M 个原数据库和 N 个后端的新数据库,如果为每个配对都来实现语义重写,相当于是 M*N 的复杂度。因此 Hyper-Q 的实现在于,首先自定义一套语法节点,数据类型(相当于所有系统的合集)Xtra。然后,对于前端原数据库 Alpha,实现 Alpha 到 Xtra 的重写;对于后端新数据库 Beta,实现 Xtra 到 Beta 的重写。这样,实现复杂度就变成了 M+N。具体的流程和优化器流程相当一致,经过 parsing(编译),binding(语义绑定,此步骤需要读取后端数据库的元数据来确保语义正确),transform(重写),最终 serlialize 成后端兼容的 SQL 语句发给后端数据库。
3)Data Ingestor:负责和后端数据库建立连接,发送请求并且得到结果。Protocol Handler 为了能够做到完全和原数据库的任何接口兼容,因此采用了难度更大的 wire protocol 实现。但对于 Data Ingestor,就可以利用标准的 ODBC/JDBC 接口来实现,大大降低了适配新数据库的工作量。
至此,Datometry Hyper-Q 的架构简介就全部讲完了。具体的实现和语句重写的细节就不在这边展开了,有兴趣的同学可以去参阅论文。
Overhead
说了这么多 Hyper-Q 的好处,也来客观地聊一下不足之处。最大的不足就在于,整个语句和结果集的转换是实时发生的,Hyper-Q 作为中间件平台,又要参与类似于优化器这种复杂的工作,对于延时和吞吐量带来的 overhead 是不可避免的。论文中有提及,对于复杂的报表语句,overhead 在 5~8%。
也因此,Datometry 所针对的客户,主要是 OLAP(online analytical processing)这类复杂报表,分析型业务,而非 OLTP(online transactional processing)这类对于延时和吞吐量非常敏感的业务。分析类语句的特点在于,SQL 语义复杂,数据处理量大,本来的处理速度可能就比较慢,那对于 Hyper-Q 引入的 overhead 就不是很敏感,另外,如果后端新的数据库在性能上有所提高,那对于总体性能来说,可能还有提升。
总结
至此,Hyper-Q 的架构就介绍完了。不知道读者对于 Hyper-Q 的架构和 Datometry 的业务模式如何看待?咱们可以在评论区继续聊。我还是挺看好的,如果哪天能上市,或者被收购!那就,哈哈哈哈啦!
给自己打个小广告,2021 年的愿景之一是做更多对于技术和管理的输出,也希望能找到更多志同道合的朋友(粉丝)。这是我的知识星球:Dr.ZZZ 聊技术和管理(由于不知道能输出多少,也不知道有多少粉丝,所以还是先免费吧)。如果你真心觉得数据库内核杂谈对你有收获,愿意听我多扯扯,欢迎加入。




