


导读:淘系用户增长算法团队主要定位于业务应用算法,基于对淘系整体用户全方位的理解为各个业务提供高效的用户洞察手段,并通过与运营、产品等团队的配合完成各个业务的用户增长目标。
用户增长平台的目标是希望能构建面向全域运营人员的全维度用户智能洞察分析体系,帮助运营高效触达目标人群。现有运营基于业务经验,将业务需求转化为一系列标签,根据标签筛选出符合条件的目标人群,该方法涉及到的数据链路较长,无法及时支持业务投放。在保证潜在人群与目标人群相似性的前提下,帮助各个垂直业务的运营同学自动化的实现保量提效的投放目标。本文主要介绍在此背景下的相似人群挖掘算法中通用特征体系若干特征处理方法。
1、基本概念和业务难点
种子人群:运营人员在特定业务场景下收集到的,对商品、服务具有相同需求和兴趣的人群称之为种子人群(比如某个场景下的已购买用户、浏览用户等);种子人群通常数量不多,一般在十万以下。
扩展人群/相似人群:与种子人群具有相同特征的人群称之为扩展人群,扩展人群的数量通常为种子人群的数倍。
目标:平衡圈人效率和投放效果,面向不同垂直业务的运营人员达到以人找人的潜客挖掘方式。
难点和问题:由于种子人群来源由运营提供,且不同业务人员的投放目标不同,运营通过各种方式获取到的种子人群成分可能非常复杂,种子人群的特征不明显,如何同时面向各个业务洞察不同种子人群的有效特征成为难点,本文主要介绍基于全域运营的通用特征处理方法。
使用方法:一般进行投放时,先通过种子人群找到扩展人群,其后将扩展人群作为运营触达的目标用户,当有多个种子人群时,可以先找到各个种子人群的扩展人群,然后取各个种子人群的扩展人群的交集作为最终投放的目标用户。
2、特征处理及算法实现
系统的整体框架如下图所示:
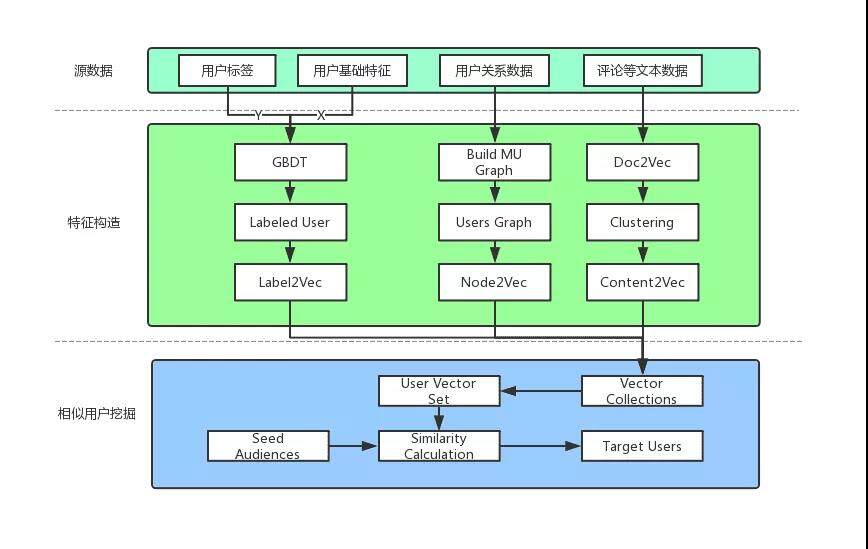
2.1 数据准备
提取用户基础属性数据,如性别、年龄、学历、职业、地域、能力标签等;
抽取平台已积累用户标签(Audience label);
提取用户的评论信息等文本内容,进行观点挖掘和倾向性分析;
提取用户之间的关系,比如亲情号相关,分享、转发关系等;
2.2 特征构造
将原始数据处理为三大类:用户基础特征、互动行为特征、消费行为特征,具体如下图所示:
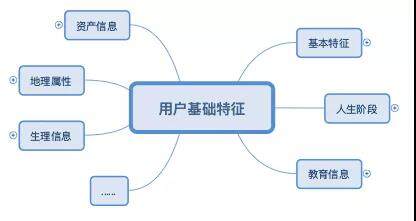
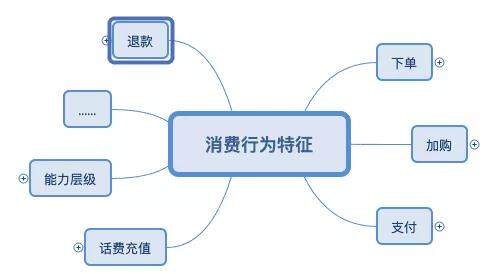
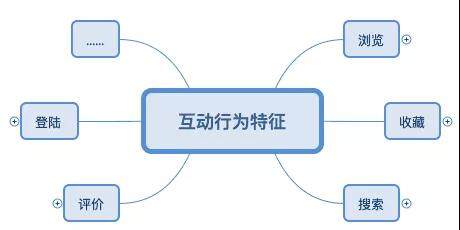
特征的构造方式如下图所示:
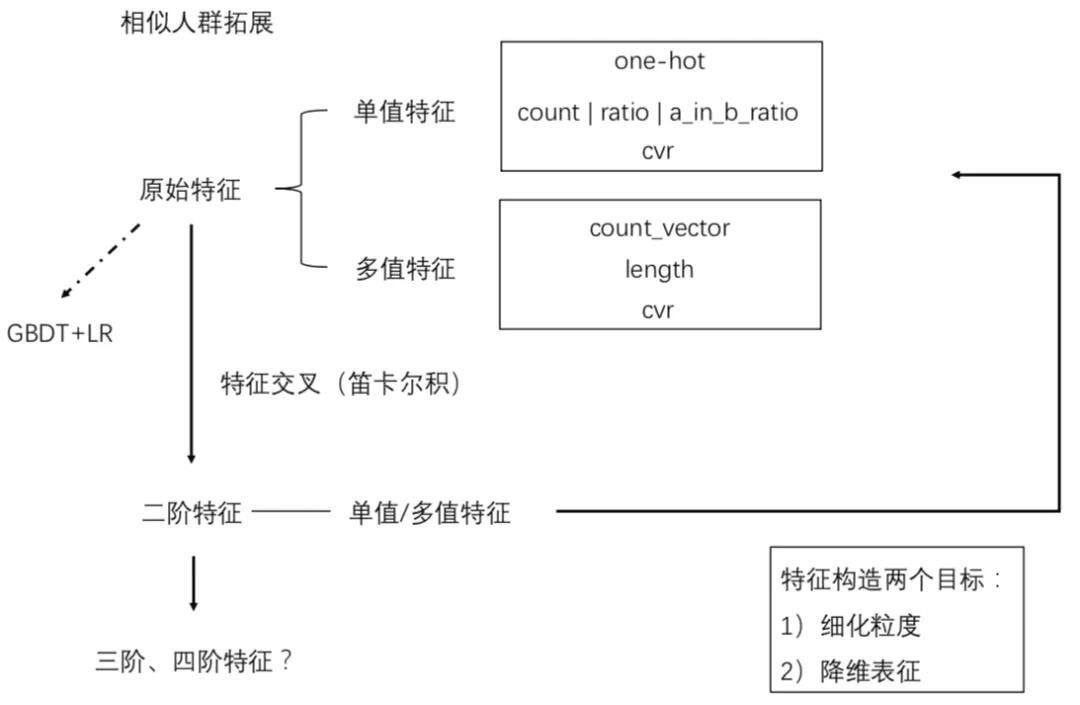
如果仅仅使用用户的属性特征和标签特征进行人群扩散过于粗犷,人与人的兴趣差异不光光是兴趣标签决定的,往往和时间、环境、友人等其他的因素息息相关,通过向量化社交关系和商品评论数据,将原有社交网络中的图结构表达成特征向量矩阵,通过向量与向量之间的矩阵运算来得到相互的关系,针对用户购买商品后的评论数据进行结构化后可以对用户进行观点挖掘和倾向性分析。
2.2.1 用户标签模型化
根据用户基础特征和已有的标签体系。利用 GBDT 算法将没有标签的用户全部打上标签。
将标签进行向量化处理,可以用 Label2Vec(类似 word2vec)方法处理后得到用户标签的向量化信息,在模型效果上有 0.5% 左右的提升。
2.2.2 文本特征处理
清洗整理源数据中提取到的所有文本内容,训练 doc2vec 模型,得到单个文本的向量化表示,对所得的文本作聚类,最后提取每个 cluster 的中心向量,并根据每个用户所占有的 cluster 获得用户所发商品评价的文本信息的向量表示 Content2Vec 。
2.2.3 关系特征
将数据准备中获得的用户之间的分享、转发等关系特征转化成图结构,并提取用户关系 sub-graph ,最后使用 node2vec 算法得到每个用户的关系网络图向量化表示。
2.2.4 特征拼接
将上述步骤中得到的向量做拼接,得到表示每个用户的多特征向量集(User Vector Set,UVS)。最后的特征输出表达了用户的社交关系、用户属性、发出的内容、感兴趣的内容等混合特征向量。
2.2.5 多特征向量用户聚类
将全量用户的多特征向量集进行聚类,然后提取每个类别的中心向量和以用户 ID 作为主键以离线形式存储,当运营人群上传种子人群后,采取同样的方式计算得到种子人群的若干类别中心向量。
2.3 类簇中心 KNN 查找
分别计算种子用户聚类中心和潜在目标用户的聚类中心,并通过相似性度量方法找到与种子人群类簇中心距离最小的 topN 个类簇,其中高纬度数据使用余弦相似度效果较好。将潜在人群和种子人群的类簇中心特征向量集作为输入 x 和 y ,代入下面公式计算相似性。
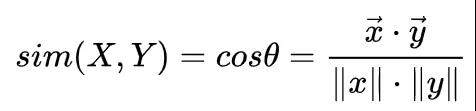
注意:余弦相似度更多是从方向上区分差异,而对绝对的数据不敏感,因此没法衡量每个维度值的差异。这里要在每个维度上减去一个均值或者乘以一个系数,或者在之前做好归一化。
2.4 相似人群挖掘
1.获取种子用户 user_id ,以及期望获取的相似人群数量 N;
2.检查种子用户是否存在于 UVS 中,将存在的用户向量化,并进行在线聚类,输出种子人群类簇中心;
3.计算潜在用户群类簇中心和种子用户类簇中心的相似度,提取最相似的前 topN 个类簇作为召回类簇;
4.通过分类器对步骤 3 中召回的潜在类簇进行精准截断输出。
2.5 离线评估指标
2.5.1 覆盖度
由于相似人群挖掘属于无监督学习,且模型效果无法通过单纯的 AUC、Precision 等指标准确评估,所以需要设计新的评估指标来有效指导模型的优化。覆盖度指标由此而来,对种子人群进行随机采样,切分为 A、B 两个人群, A 人群通过相似人群挖掘算法得到扩散后的人群 C ,覆盖度 =B∩C/B ,覆盖度表示扩人群中人群 B 的占比,考验的是算法通过人群 A 对人群 B 的“恢复”能力,具体实验中通过将种子人群进行 5 倍扩散后根据相似人群的覆盖度是否有提升来对模型进行迭代优化。
2.5.2 相似度
扩展人群相似度概念的提出主要有以下几点原因:
在人群规模探查阶段,运营希望在人群相似度可控的范围内探查潜在人群的规模,使用相似人群查找之前并不会明确给出目标人群的数量;
若将同一种子人群通过随机降采样缩小 10 倍和缩小 5 倍,然后分别通过相似人群挖掘算法得到扩展 5 倍后的人群及其覆盖度,自然缩小 5 倍的人群作为种子人群扩散后的覆盖度较高,但人群覆盖度指标并不能完全表征相似人群与种子人群的的近似程度,需要配合人群相似度一起评估。
人群相似度计算步骤:
1.分别计算扩散人群到种子人群聚类中心的 cosine 距离;
2.按照步骤 1 的结果进行最大最小值归一化,将值域归一化到 [0,1] 之间;
3.根据 sigmoid 函数,将步骤 2 产生的归一化后结果通过 sigmoid 函数移动到 [0.5,1) 之间。
人群相似度基于扩散人群与种子人群间的距离计算,能够表征扩散人群与种子人群的相似程度,运营通过设置固定的人群相似度阈值,能够直接获得潜在人群的规模并进行下一步的分析或者营销活动。
本文转载自淘系技术公众号。
原文链接:https://mp.weixin.qq.com/s/gQ3mb33JTKpNXmS7tswwGQ

中国开发者画像洞察报告 2022
本次报告为你深度解读开发者人群背景,分析开发者群体面临的挑战,洞察开发者人群特征,预测开发者生态发展...









评论