

本文介绍了作者所在团队为了实现语音识别领域的“ImageNet 时刻”所做的努力,以及相关研究成果。这些成果只需要比较少的投入和资源就可以应用在实际生产环境,与传统学术研究相比更接地气。
本文最初由俄语写作,后续被作者改编为英文版本并发表在 thegradient 网站上(Towards an ImageNet Moment for Speech-to-Text),中文译文已经过作者和 thegradient 网站的授权和审核。
语音转文本(STT),也称为自动语音识别(ASR),这项技术由来已久,并在过去十年中取得了惊人的进步。如今在业界,人们一般认为只有像谷歌、Facebook 和百度(在俄罗斯境内则是政府支持的那些本地垄断企业)之类的大公司才能提供可部署的“接地气”的解决方案。这主要是出于以下几个原因:
研究论文中普遍存在的海量计算需求,是在人为地设置较高的入门门槛;
由于词汇、讲话人和压缩技术都是多种多样的,语音数据量非常庞大;
抛弃较为实用的解决方案,转而采用不切实际但技术上更前沿的方案(SOTA)的心态很普遍。
这篇文章介绍了我们为缓解这些矛盾而针对各国语言(包括俄语)所做的各种努力:
引入了 20,000 小时的OpenSTT多样性数据集,基于 CC-NC-BY 许可证分享;
证明了只使用两块在市面上随处可见的消费级 GPU,就可以获得颇具竞争力的成果;
给出了不同的设计模式,帮助广大人工智能研究人员和从业者进入语音识别领域。
简介
随着计算机视觉技术的蓬勃发展和广泛普及(也就是所谓的“ImageNet 时刻”,具体来说就是在硬件需求下降、产品上市时间缩短、数据集规模也尽量缩减之后,可部署产品开始纷纷涌现),一个合理的展望就是机器学习(ML)技术在其他分支领域也很快会大放异彩。唯一的问题是,其他领域中这样的转折点何时会到来,其前提条件都有哪些?
我们认为,一个 ML 分支领域中的 ImageNet 时刻出现时会有以下表现:
能够解决 95%的标准“实用”任务所需的架构和模型构建块,已成为标准化和经过验证的开源框架模块得到了广泛应用;
多数流行的模型都提供了预训练的权重;
成功将预训练模型标准任务上获得的知识应用在多种多样的日常任务中;
与初期在论文中报告的计算需求(在 STT 领域一般是 100-1000 个 GPU 日)相比,训练日常任务模型所需的计算量控制在了很低的水平(例如在 STT 领域中只需 1-10 个 GPU 日);
小型独立公司和研究小组也有能力使用大型预训练模型来处理计算任务。
如果上述条件都能满足,那么从业者就能够以合理的成本来开发新的实用性的应用。行业中的民主化也会随之而来:人们不必再依赖像谷歌这样的大公司作为行业中的唯一真相来源。
这篇文章将介绍我们为了迈向 STT 领域中的 ImageNet 时刻所做的工作。到目前为止这一转折点尚未出现,在俄语范围尤其如此。我们的主要目标是在有限的计算资源预算限制内,尽快构建和部署实用的模型,并共享我们的努力成果,希望其他人可以基于我们的发现,为 STT 领域实现 ImageNet 时刻而携手前进。
为什么我们不以学术论文的形式发表?
这并不是传统的经过同行评审的研究论文,而是对我们结合现有思想和技术,向有用和实用的 STT 迈进的务实努力的总结。
我们决定以这种形式来分享,而不是在会议或 arxiv 上以论文的形式发表,这样我们的发现就能得到更广泛的传播。虽说用来确保技术正确性的同行评审是有意义的,但由于我们使用了很多现有的构想,外加我们得出的经验结果支持,所以我们对自己的主张充满信心。我们将专门讨论,为什么我们认为当前的同行评审和企业支持的研究并不是促进整个社会进步的最快途径。简单来说,尽管这些有缺陷的系统长期来看是能发展起来的,但从短期来看有更快的方法可以取得进展。
简而言之,本文介绍的想法确实可以应用在生产环境中,并且已经在其他领域接受过了验证。更重要的是——它们中的大多数都很接地气,不需要昂贵的硬件或成吨的代码。我们欢迎大家提出反馈和批评意见——aveysov@gmail.com
相关工作和启发
在实验中我们选择了以下技术:
用于声学建模的前馈神经网络(主要是基于squeeze-and-excitation和 transformer 模块的分组 1D 卷积);
连接主义时间分类损失(CTC 损失);
由字素(即字母)组成的复合词,作为建模单位(与音素相对);
使用预训练语言模型(LM)作为解码器进行束搜索。
STT 有很多方法可用,这里就不具体展开了。本文所介绍的是主要使用字素(即字母)和神经网络的端到端方法。
简而言之——要训练一个端到端字素模型,你只需大批带有对应文本的小型音频文件即可,也就是 file.wav 和 transcription.txt。你还可以使用 CTC 损失来降低对同步注释的需求(否则你需要自己提供一个同步表,或在网络中学习同步方式)。一种常见的 CTC 损失替代方法是带有注意力的标准分类交叉熵损失,但它训练起来很慢,而且一般是和 CTC 损失并用的。
选择这个技术栈主要原因如下:
可扩展性。添加 GPU 即可扩展计算能力;
不会过时。如果出现了新的主流神经网络模块,仅需要几天时间就可以进行集成和测试,迁移到另一个框架也很容易;
简单易用。因为用的是 Python 和 PyTorch,所以你可以专心做实验;
灵活性。新特征只需花几天时间用 Python 写好代码就可以测试了;
不在解码器、音素或递归神经网络中使用注意力模型,所以收敛速度更快,模型的维护需求也更少。
开放语音转文本(俄语)
据了解,目前所有公开可用的有监督英语数据集都少于 1,000 小时,并且可变性非常有限。DeepSpeech 2这篇深度 STT 论文建议,至少需要 10,000 小时的注释才能构建一套不错的 STT 系统。1,000 小时也能入门,但是考虑到泛化差距,你需要大约 10,000 小时的分布在不同域中的数据。
典型的学术数据集有以下缺点:
过于理想。与真实场景相比音质太好;
域太窄。STT 的难度遵循以下简单公式:噪音水平词汇量说话者人数;
一般只有英文音频数据。尽管像Common Voice这样的项目一定程度上解决了这个麻烦,但是除德语和英语以外,其他语言很难找到大量可用数据。另外 Common Voice 可能更适合说话者识别任务,因为它们的文本不够多样化;
压缩方式不同。Wav 文件几乎没有压缩,但现实世界中的音频文件可能存在多种压缩算法。
我们决定收集并发布一个前所未有的俄语口语语料数据集。我们一开始的目标是 10,000 小时,这个数据集的大小在英语语料库中也很罕见。
最近我们发布了这套数据集的1.0-beta版本。它包括以下域:
我们的数据收集过程如下:
收集一些数据,然后用启发式方法清理;
训练一些模型,并使用这些模型进一步清理数据;
收集更多数据,并对齐文本与音频;
训练更好的模型,并使用这些模型进一步清理数据;
收集更多数据并手动标注一些数据;
重复所有步骤。
我们的语料库在此,也可以在这里支持我们的数据集。
虽说成果不错,但我们还没有完成。我们的短期计划是:
做一些整理,进一步清理数据,并清理一些旧代码;
迁移到.ogg,以在保持质量的前提下尽量节省空间;
添加几个新域(法庭记录、医学讲座和研讨会、诗歌)。
实现出色的语音转文本模型
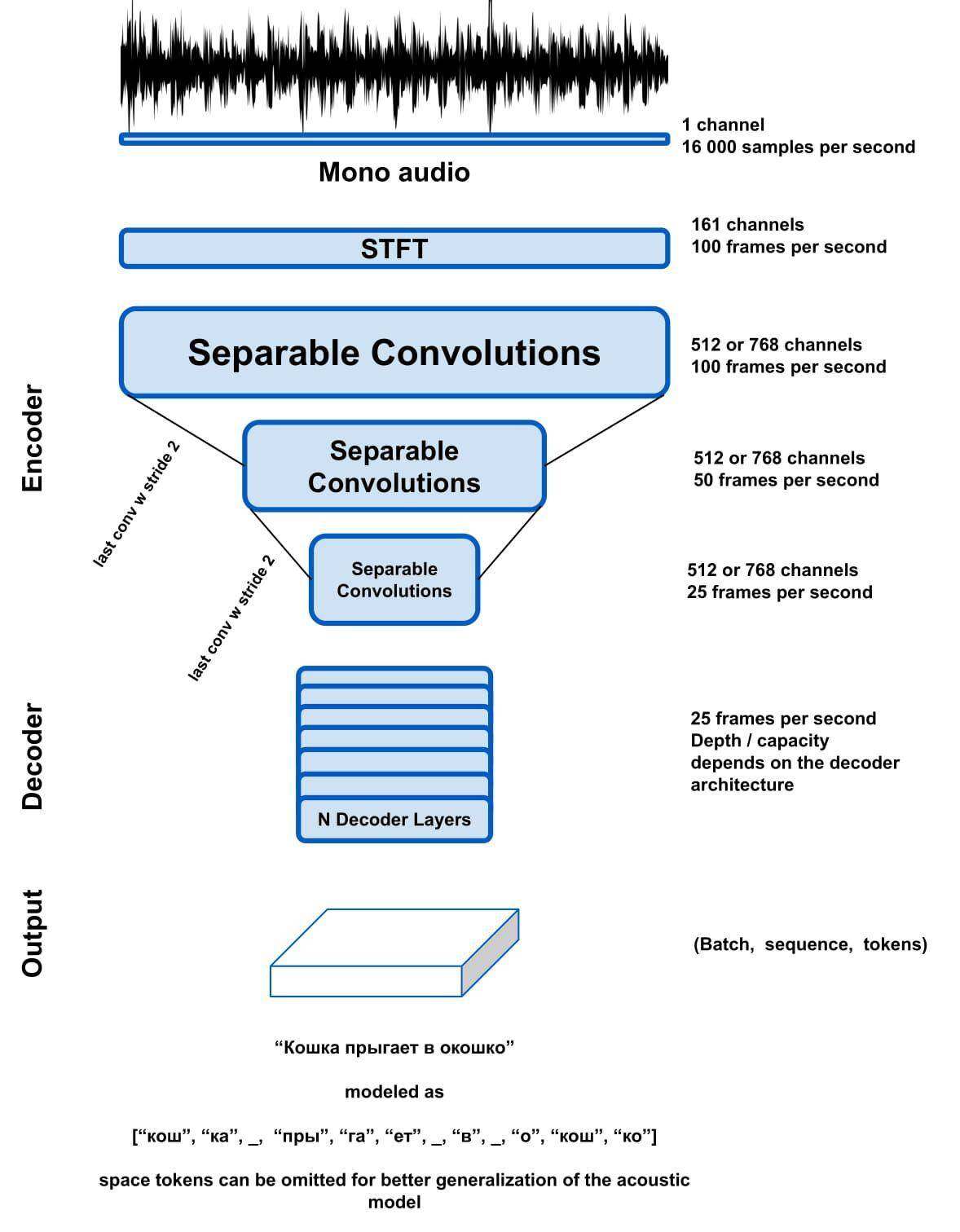
一个出色的 STT 模型需要具备以下特征:
快速推断;
参数高效;
易于维护和改进;
训练时不需要大量计算资源,一台 2x1080 Ti 的机器就足够了;
这些是我们的目标,下面介绍我们如何实现这些目标。
总体进展
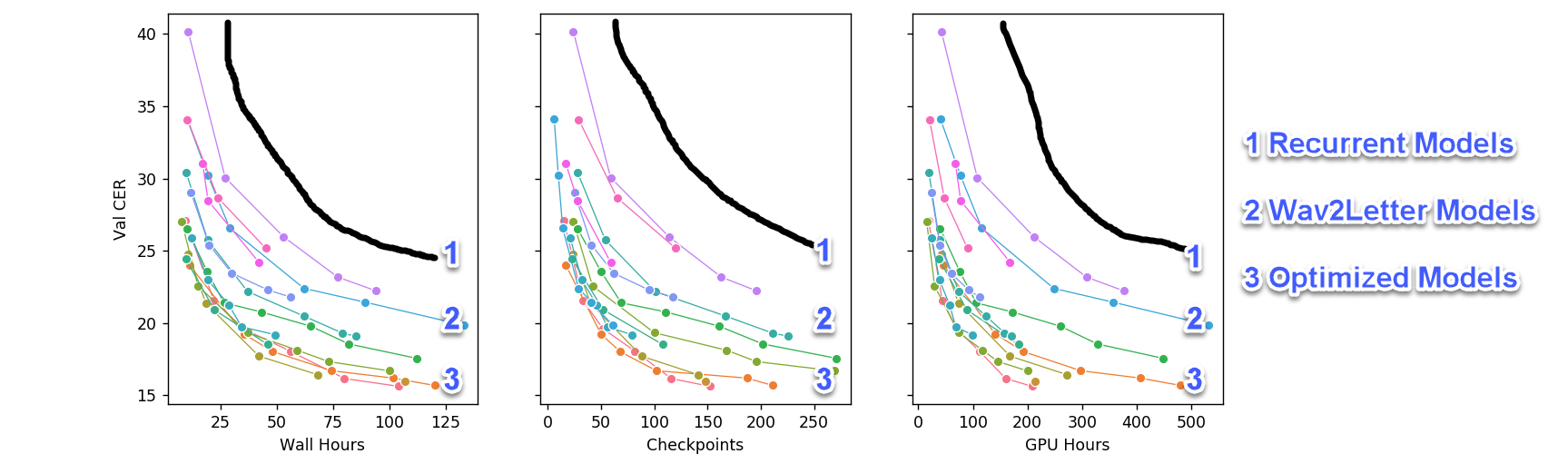
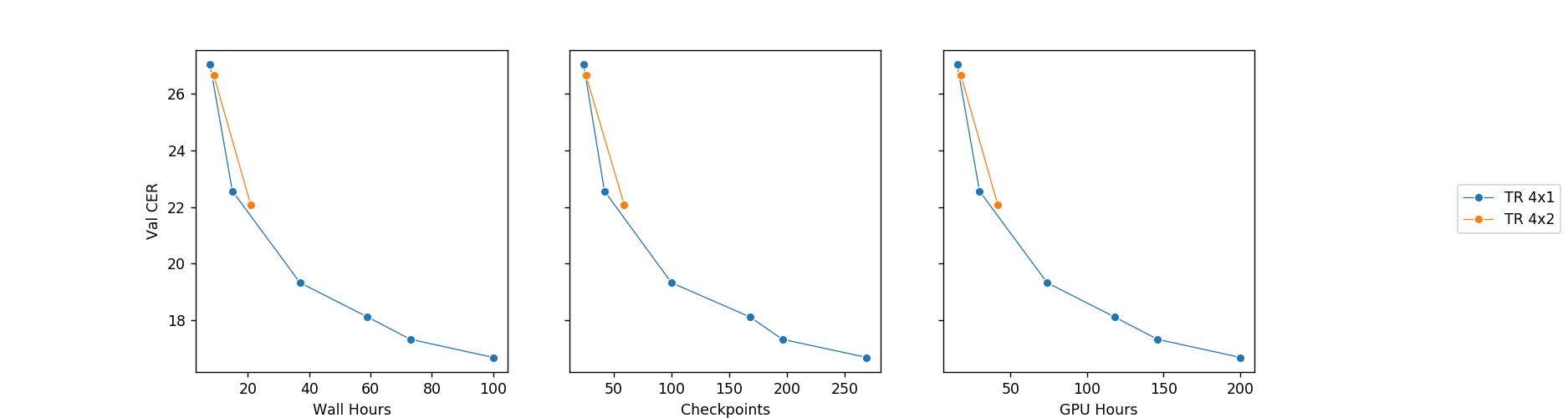
模型收敛曲线展示了语音识别领域从简单的 Wav2Letter 模型到更优化模型的进步。GPU 小时是计算时间乘以所用 GPU 的数量。每次只引入一项架构更改,所有其他设置、超参数和数据集均保持不变。
我们从PyTorch的Deep Speech 2 分支开始。原始的 Deep Speech 2 模型基于深度 LSTM 或 GRU 递归网络,速度较慢。上图展示了我们可以添加到原始管道中的优化。具体来说,我们能够在不损害模型性能的前提下做到以下几点:
将模型大小减小到约 20%;
将收敛速度提高 5-10 倍;
最终模型的小版本(25M-35M 个参数)可以在 2 块 1080 Ti GPU 上训练;
大型模型仍需要 4 块 1080 Ti,但与小版本相比最终 CER 值要低一点(降低 1-1.5 个百分点)。
上面的图中只有卷积模型,我们发现它们比循环模型快得多。我们获取这些结论的过程如下:
使用一个 Deep Speech 2 的现有实现;
在 LibriSpeech 上进行实验,注意到 RNN 模型与卷积模型相比往往很慢;
添加了一个简单的 Wav2Letter 启发模型,但对于俄语语料来说,模型参数不足,因此我们增加了模型大小;
发现模型效果尚可,但是训练起来很慢,于是尝试优化训练时间。
接下来我们尝试了以下想法来做改进:
想法 1:模型步幅
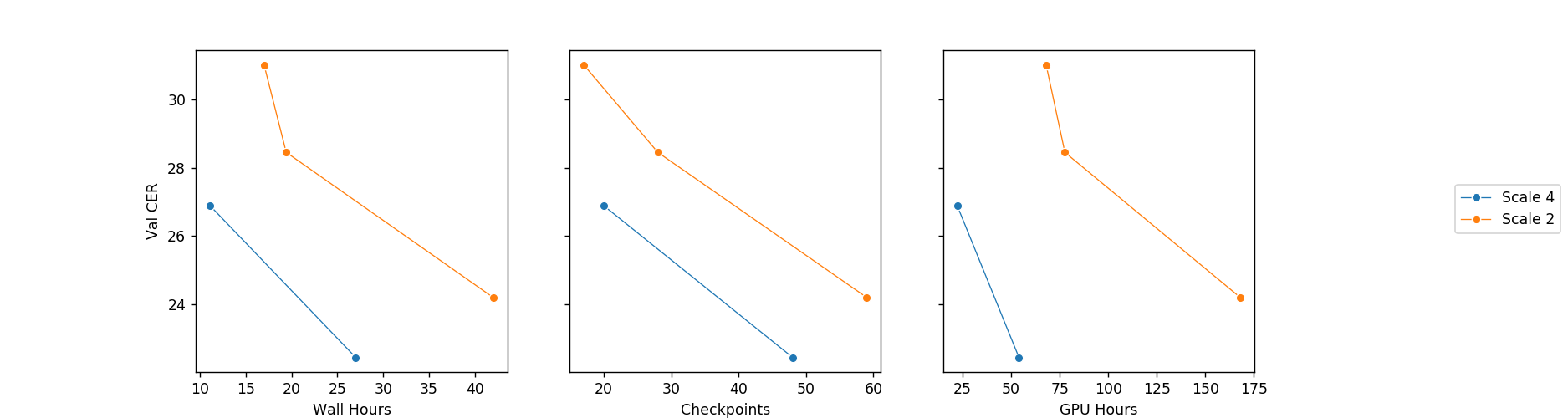
我们的第一步优化是修改模型步幅。这实际上是一个非常简单的想法。在分析 Wav2Letter 模型的扩展版本(步幅为 2)的输出时(在短时傅立叶变换之后),我们注意到有用的输出词与空白词的比率大约在 2 比 1 和 3 比 1 之间。那么何不在卷积编码器中增加步幅呢?
想法 2:紧凑正则网络
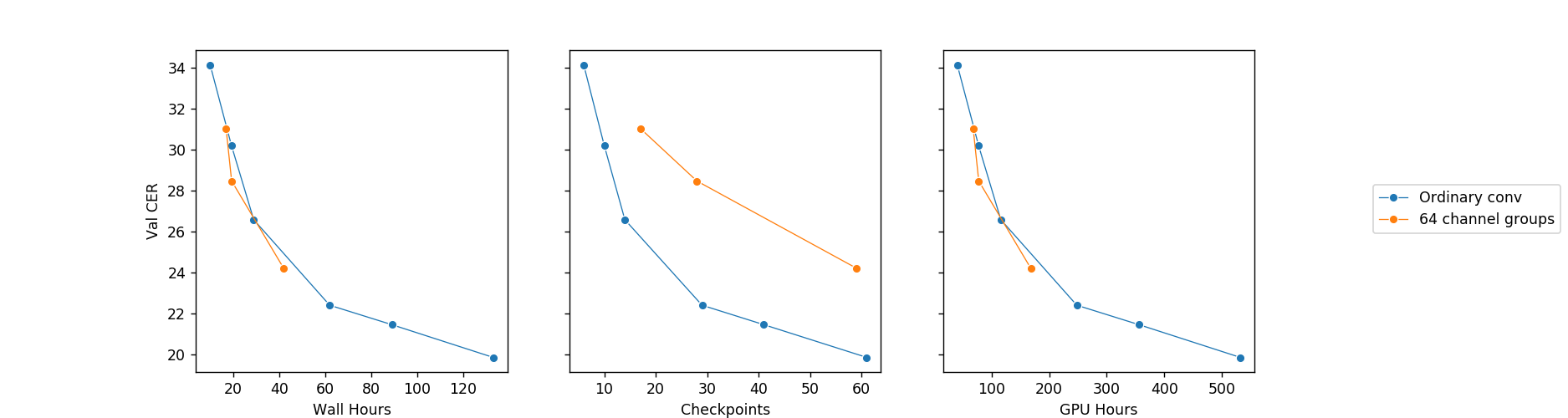
如前所述,针对移动设备高度优化的网络可能无法用作架构决策的理想参考,但是从中可以总结出很好的经验:
使用可分离卷积,因为它们会大大减少模型中的参数数量,而不会牺牲模型性能;
向深度 CNN 添加跳跃连接,可以加快收敛,并能训练更深的模型;
在模型的卷积部分中添加并发空间、通道挤压和激励模块,或基于风格的再校准模块等注意力机制,因为它们往往只需很小的计算开销就能提升模型性能;
此外,小型正则化网络更易训练,因为它们的拟合度较低。不利的一面是较小的网络需要更多的迭代才能收敛(也就是说每个批次更快,但需要的批次更多)。一个简单的经验法则表明(实际情况可能更复杂些),如果网络的大小减少到 1/3 至 1/4,其他所有条件都相同,要训练出和较大网络相同的性能水平则需要 3-4 倍的迭代数。但是较小的网络将快 2-3 倍。
另一个想法也很有价值,如果你使用 IdleBlocks,即在没有任何操作的情况下通过模型传递一些卷积通道,则可以使用一半的参数和更大的感受野来构建更深、更具表现力的网络。
想法 3:使用字节对编码
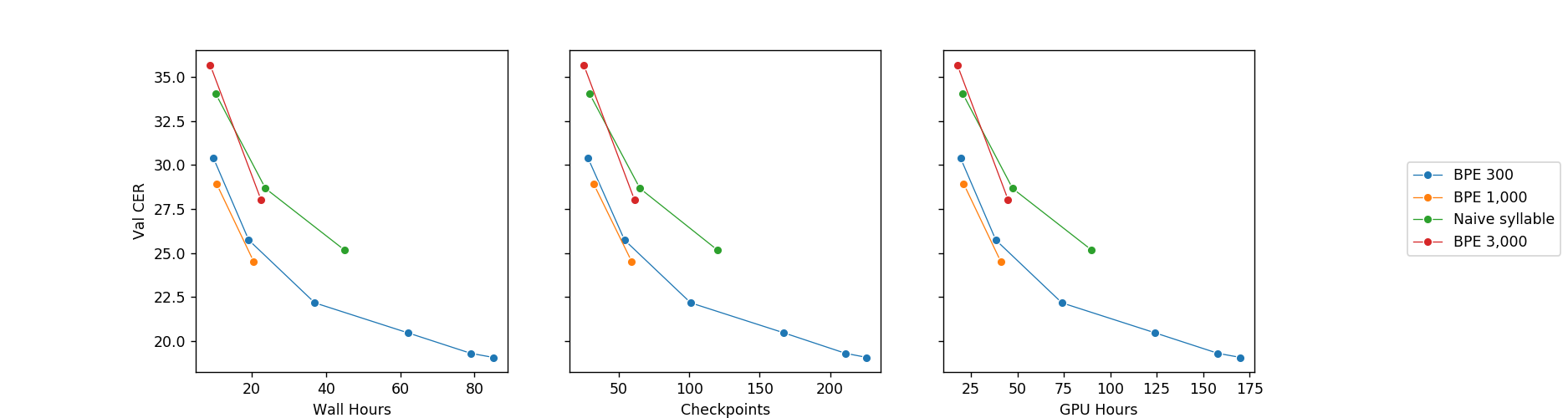
根据这篇文章我们尝试了几种分词方法,结果发现:
字节对编码(BPE)是使用整体步幅大于 4 的模型的必要条件,否则词(token)就不够了。
基于字素的 BPE 优于基于音素的 BPE 模型。
在我们的情况下,即使只有非常简单的解码器的模型也可以充当语言模型,并且与基线模型相比 WER(字错误率)大幅降低。请记住,最好使用在较大文本语料库上单独训练的模型来解码。我们的 BPE 模型与基线模型相比取得了相似甚至更好的 CER(字符错误率)性能;
BPE 词汇量越大,AM 就更像 LM。我们不希望 AM 过拟合已知词汇表,因此需要找到一个平衡点。我们运行了多个模型,其 BPE 词汇量从小到大(300、1,000、3,000 和 10,000),总结出的经验是最多 1,000 的 BPE 词汇量可以在改善声学模型的 WER,而不会损害其 CER。当词汇量大于 1,000 时,我们开始看到 CER 开始下降,这表明模型与口语语料库的词汇表过拟合了;
我们使用了流行的sentencepiece分词器,做了少许调整以适合 ASR 领域。
想法 4:更好的编码器
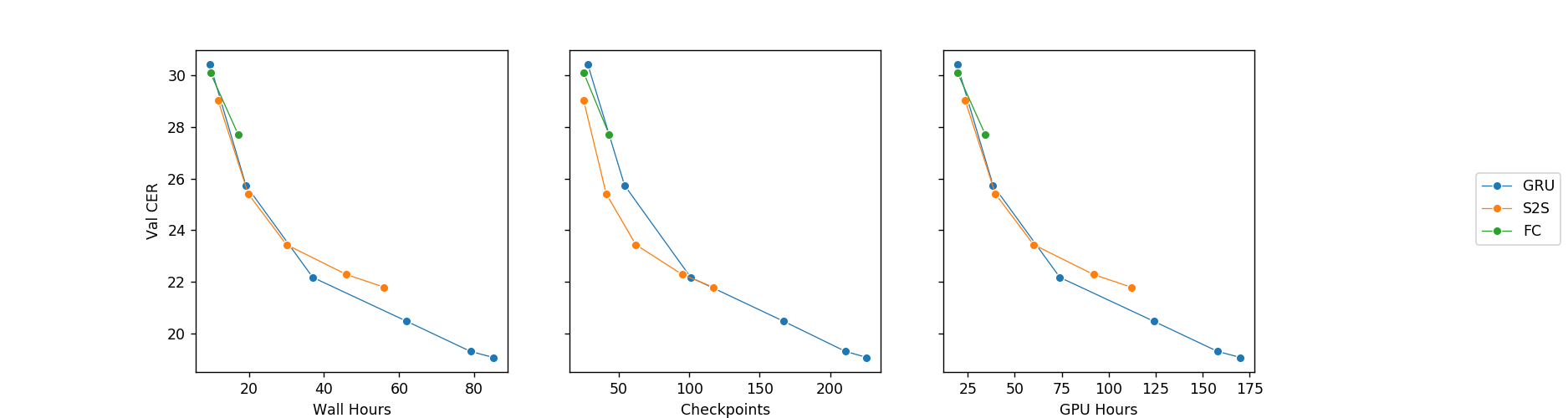
这里的基本思想是使用更具表现力的编码器/解码器架构。缩减到 1/8 比例的卷积编码器非常快,因此你可以使用更复杂的解码器。
现在人们已经普遍认同一点,那就是在 NLP 领域,transformer 模块的建模能力比之前的顶尖模型要强很多。
总体而言,这种设置下的模型所需的计算资源十分少,在生产中部署时甚至都不需要 GPU。声学模型在每 GPU 秒内可以轻松处理 500-1000 秒的音频(实际上的速度很可能受 I/O 限制),而每 CPU 秒则可以处理 2-3 秒的音频(EX51-SSD-GPU服务器上的单 CPU 核心),同时不影响性能。注意这里的估算值仅包含声学模型,并可以通过模型量化和最小化(即修剪、教师蒸馏等)获得进一步改进。
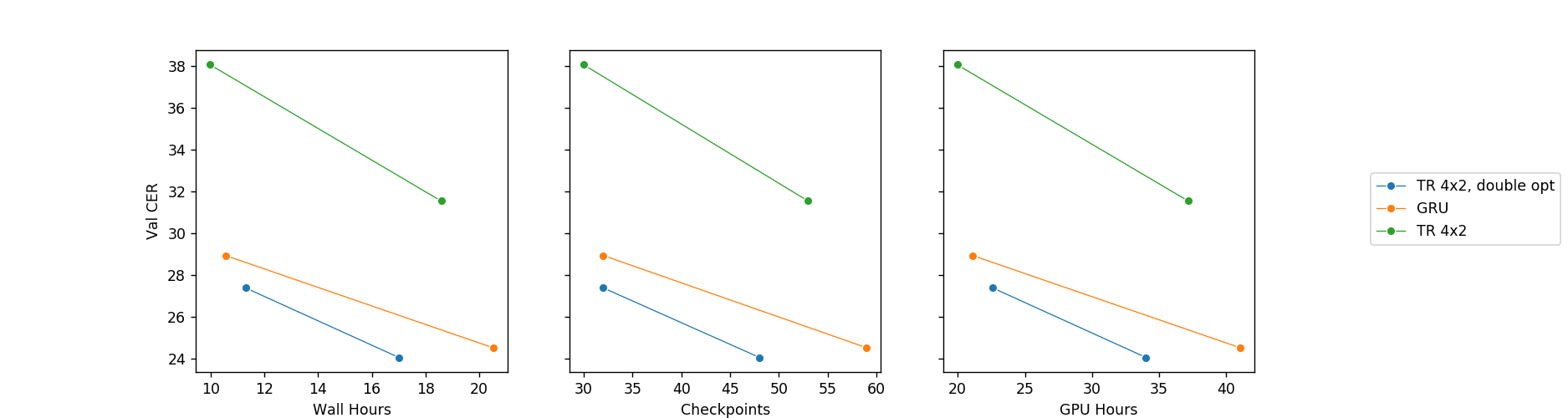
想法 5:平衡容量,不再使用 4 个 GPU
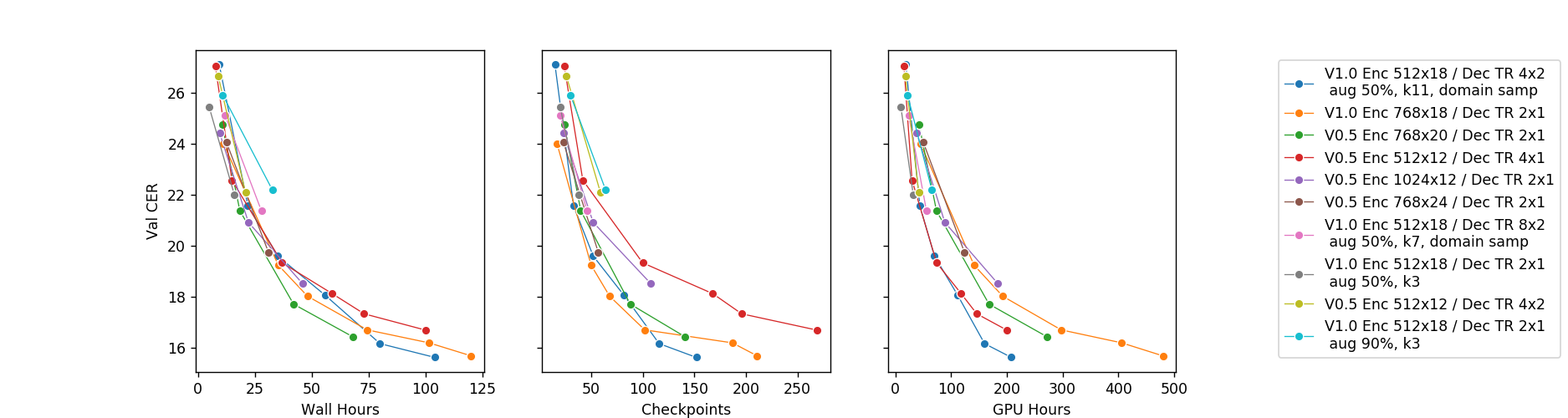
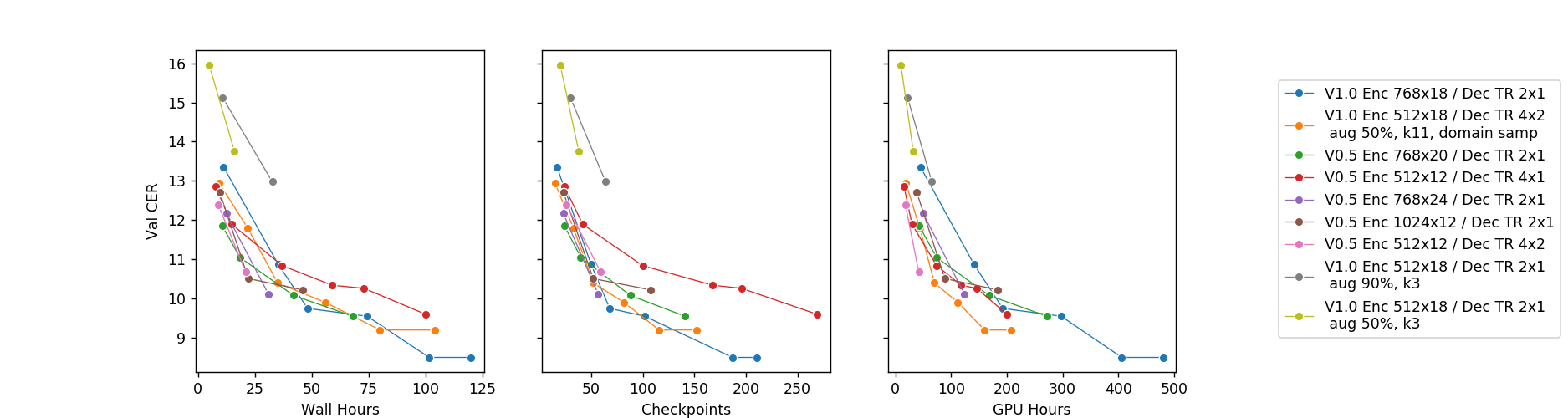
通过在模型的各个部分中平衡容量和计算需求,可以得到一个仅需两块 1080 Ti 即可快速训练的模型!而且比需要 4 个甚至 8 个 GPU 的模型节约很多天的训练时间。
我认为这是迄今为止最令人印象深刻的成就。
想法 6:在各个域中稳定训练成果,平衡泛化
语音识别模型中的一大问题是灾难性遗忘。根本问题在于,就连正则化网络(具有可分离的卷积)在适应大批新数据时也会开始忘记旧的域。这在生产环境中是尤其无法接受的。另一个问题是,ASR 论文往往会在整个 Librispeech 数据集上训练 50 至 500 个 epoch。样本效率非常低,无法扩展到现实数据上。
我们发现可以使用课程学习来减少将模型拟合到新数据上所需的迭代数,并想出了一些办法来应对灾难性遗忘。使用这种方法,我们可以将迭代总数减少到数据集大小的 5-10*以下。
关键思想是:
使用课程学习,也就是根据某种质量指标(我们使用 CER)从数据集中采样样本数据,这样你就可以从较简单的样本开始,随着训练的进行逐渐引入越来越难的样本。一般不宜对太容易的样本进行太长时间的采样(这将导致过拟合并降低鲁棒性),或太早开始采样太困难的样本(这将导致欠拟合)。在实验中我们发现保持 10%的 CER(在训练过程中引入更难或更容易的样本)是最合适的。
学习新的域时,需要从以前训练过的域中采样新增数据,以减少灾难性遗忘;
在现实生活中,来自不同域的数据可能严重失衡。为了解决这个问题,你可以用不同的概率采样不同域的数据,从而为模型提供所需的特征。例如对于最佳模型而言,我们对所有域都分配了相同的概率,但是我们将各个域定义为来自相似的源域(也就是具有相似的噪声、词汇量和主题)。
有些域可能有更高或更低的信噪比,因此对于某些域而言,最佳 CER 可能会降低到 5%;
想法 7:打造快速解码器
这超出了本文的范围,不过简单说一下,有两个用于后期处理的选项:
序列到序列网络;
具有语言模型的束搜索解码器;
在我们的测试中,序列到序列网络不会明显减慢我们的推理速度,而束搜索则慢了 10 倍。让序列到序列模型超越束搜索是下一步研究的一个要点,但我们已经使用了KenLM的束搜索实现,达到了每 CPU 内核秒约 25 秒音频的处理速度,同时没有牺牲精确度。
模型基准测试和泛化差距
在现实生活中,如果模型在一个域上训练,则可以预期它在另一个域上存在巨大的泛化差距。但是泛化差距是先天存在的吗?如果答案是肯定的,那么域之间的主要区别是什么?是否能训练出一种模型,可以在许多实用的域上都以良好的信噪比正常工作吗?
泛化差距是存在的,你甚至可以推断出哪些 ASR 系统在哪些域上训练过。此外,根据之前的想法,你可以训练出一个模型,让它在未见的域上也能表现出色。
根据我们的观察,以下是导致域之间泛化差距的主要因素:
总体噪音水平;
词汇和发音;
用于压缩音频的编解码器或硬件;
说明:
所有速度基准测试都是在 EX51-SSD-GPU 服务器上完成的:4 核 CPU+GTX 1080;
该基准测试包括声学模型和语言模型。声学模型在 GPU 上运行,对结果累加;语言模型后处理在多个 CPU 上运行;
测试成绩是将数据集中音频的总音频时间除以应用声学模型和语言模型后处理所花费的总时间来得出的。对于这些测试,这一指标的范围从 125 到 250,这是非常快的。但这并不代表实际的生产使用速度。
模型测试结果分析
人们在对比不同系统的表现时往往会有很多不良习惯:
将 2019 年新研发的模型与竞争对手 2018 年的模型做对比;
对结果进行精心挑选以符合某些论点;
忽略了实际情况、计算需求或维护方面的问题;
我们自己也没法完全避免这类倾向,所以你至少应该尝试:
进行数据集外(ood)验证;
在干净和嘈杂的数据上验证;
尝试创建适合实际使用的通用模型。显然,有些公司为多个域提供多种模型是有原因的,但是创建一个通用模型比为一个狭窄的域创建模型要困难得多;
将模型与明显不同的其他方法进行比较——至少在黑匣子级别上对比;
根据上一节中的测试成绩对比可以得出一些结论(请注意,这些测试是在 2019 年底/2020 年初进行的):
通过使用 OpenSTT,我们成功地训练了一个通用模型,该模型的性能与业内最优秀的通用模型相当,并且在数据集外测试中不会落后太多。
除了我们的模型外,没有其他模型可以在所有验证集上都表现出色,同时还不会显著牺牲某些域的性能(即 WER>50%);
我们可以清楚地看到,在多数数据集中都能找出几个性能最出色的系统,它们具有明显的普遍性能优势;
出人意料的是,虽然谷歌在现实通话测试中给出了最佳表现,但它在某些领域仍然严重落后。我们无法判断这是不是因为某个内部置信度阈值偏高而造成的,但从数据看来,谷歌的 STT 在自己不确定时直接跳过了输出,这在某些应用中是难以接受的,而对于其他应用场景来说则是默认的行为;
Kaldi 可能接受过有声读物或类似域的训练;
虽然在简单的领域(例如旁白或有声读物)上 Tinkoff 的模型的表现极佳,但它在其他领域的性能甚至比没有 LM 的模型还要差。同样,他们最有可能在有声读物和 Youtube(也可能有旁白或简短命令)上训练自己的模型;
令人惊讶的是,Yandex 并不像人们普遍认为的那样是所有领域中表现最好的;
尽管 Kaldi 在简单域的简单词汇设置中表现良好,但在有噪音的域上却落后了。
生产应用
我们已经证明,在几乎零人工注释和有限的硬件预算(2-4x1080 Ti)条件下,也可以训练出鲁棒且可扩展的声学模型。但一个显而易见的问题是:要部署这个模型还需要多少数据、计算量和工作?模型的实际表现如何?
谈到性能,我们认为显而易见的标准就是在所有验证数据集上击败谷歌。但问题在于谷歌在某些域(比如电话录音)上的性能出色,而在其他域上的平均性能却很差。因此在本节中,我们决定采用俄罗斯企业 SpeechPro 的最佳模型的结果,该模型通常被称为市场上的“最佳”解决方案。
如上表,我们发现除电子商务电话和有声读物之外,我们的模型在所有类别中都优于 SpeechPro Calls(他们有很多模型,但是只有一个模型在所有域上都表现良好)。此外我们发现,为模型增加更多容量和训练更多数据,可以极大地改善我们在大多数域中的结果,并且 SpeechPro 仅在电子商务电话中优于我们改进的模型。
为了获得这些结果,我们额外获取了 100 小时的带有人工标注的电话录音、大约 300 个小时的具有各种自动标注的电话录音、以及 10,000 个小时的类似 OpenSTT 的未公开数据。我们还将模型解码器的容量增加到了约 65M 参数。如果你说俄语,可以在此处测试我们的模型。
其他问题则要复杂一些。显然,你需要一个语言模型和一个后处理管道,这里不再讨论。为了只部署在 CPU 上,最好做一些进一步的缩小或量化,但这不是必需的。每个 CPU 内核每秒可以处理 2-3 秒的音频(在较慢的处理器上是这样,在更快的处理器内核上可以达到 4-5 秒左右)就足够了,但最新的解决方案声称它们的成绩约为 8-10 秒(在更快的处理器上)。
未来展望
下面是我们尝试过的一些想法(其中一些想法甚至是可行的),但我们最后认为它们过于复杂,提供的好处却不见得有那么多:
摆脱梯度裁剪。梯度裁剪占批处理时间的 25%至 40%。我们尝试了各种方法来摆脱它,但是如果不降低收敛速度就无法做到这一点。
ADAM、Novograd 和其他有前途的新兴优化器。根据我们的经验,他们只在较简单的非语音领域或迷你数据集上有效果;
序列到序列解码器和双重监督。这些想法是行之有效的。采用分类交叉熵损失(而非 CTC)的基于注意力的解码器是非常慢的(因为在已经很繁重的对齐任务中还要加入语音解码任务)。混合网络的性能提升并不足以弥补其复杂性的缺陷。这可能只是意味着混合网络需要大量的参数微调。
基于音素和音素增强的方法。尽管这些方法帮助我们规范化了一些过参数化的模型(100-150M 参数),但事实证明它们对较小的模型不是很有用。由谷歌发起的一项分词研究得出了类似的结果;
逐渐增加宽度的网络。这种网络在计算机视觉中是一种常见的设计模式,其收敛速度较慢。
使用IdleBlocks。初看上去这是行不通的,也许需要更多时间才能找出合适的途径。
尝试使用某种类型的可调滤波器代替 STFT。我们尝试了可调 STFT 滤波器和 SincNet 滤波器的各种实现,但是在大多数情况下,使用这类滤波器甚至无法稳定训练过程。
训练具有不同步幅的金字塔形模型。我们在这里没有取得任何进展;
使用模型蒸馏和量化来加快推理速度。当我们在 PyTorch 中尝试进行原生量化时,它仍处于 beta 版本,尚不支持我们的模块;
加入更多优化,例如立体声或降噪。降噪起了点作用,但事实证明它的价值不是很大。
作者介绍
Alexander Veysov 是 Silero(一家开发 NLP/语音/CV 支持产品的小公司)的数据科学家,也是 OpenSTT(可能是俄罗斯最大的公共口语语料库)的作者(我们计划添加更多语言)。Silero 最近已经交付了他们自己的 STT 俄语引擎。在此之前,他曾在一家位于莫斯科的 VC 公司和 Ponominalu.ru(一家由俄罗斯电信巨头 MTS 收购的票务初创公司)工作。他在莫斯科国立国际关系大学(MGIMO)获得经济学学士和硕士学位。你可以在 telegram 上,(@snakers41)关注他的频道。
感谢 Andrey Kurenkov 和 Jacob Anderson 对本文的贡献。
如果你喜欢这篇文章并想了解更多信息,请订阅Gradient 并在Twitter上关注我们。
文章预告
本文作者在 thegradient 网站上发布的另一篇文章《一位语音识别实践者对学术和工业界的批判》(A Speech-To-Text Practitioner’s Criticisms of Industry and Academia)是本文的续作,其中包含的结论也是本文的重要参考。InfoQ China 将继续翻译这篇续作,以飨读者。
原文链接:Towards an ImageNet Moment for Speech-to-Text

InfoQ主编

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论