

本文授权转载自知乎专栏:高能NLP之路
本文以 QA 形式总结对比了 nlp 中的预训练语言模型,主要包括 3 大方面、涉及到的模型有:
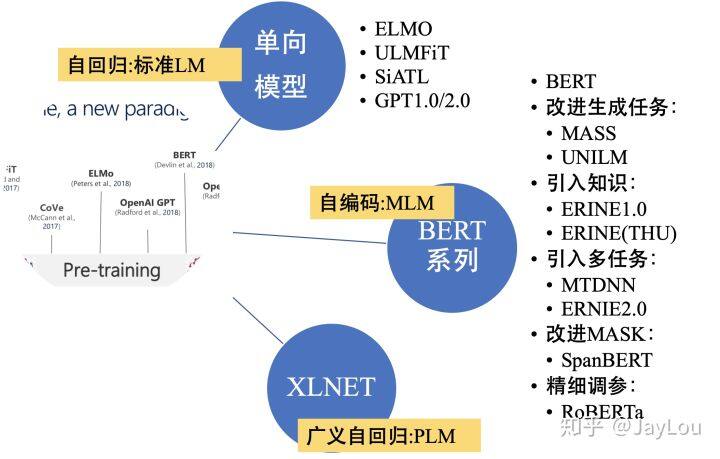
单向特征表示的自回归预训练语言模型,统称为单向模型:
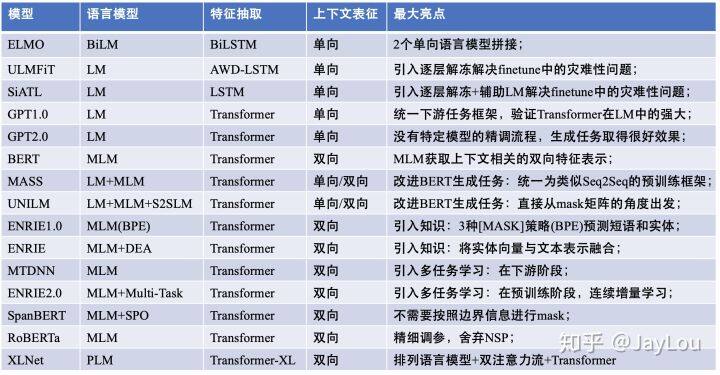
ELMO/ULMFiT/SiATL/GPT1.0/GPT2.0;
双向特征表示的自编码预训练语言模型,统称为 BERT 系列模型:
BERT/MASS/UNILM/ERNIE1.0/ERNIE(THU)/MTDNN/ERNIE2.0/SpanBERT/RoBERTa
双向特征表示的自回归预训练语言模型:XLNet;
Question List
Q1:从不同维度对比【预训练语言模型】?
Q2:基于深度学习的 NLP 特征抽取机制有哪些?各有哪些优缺点?
Q3:自回归和自编码语言模型各有什么优缺点?
Q4:单向模型的内核机制是怎样的?有哪些缺点?
Q5:Transformer 内部机制的深入理解:
为什么是缩放点积,而不是点积模型?
相较于加性模型,点积模型具备哪些优点?
多头机制为什么有效?
Q6-Q10:BERT 内核机制探究
BERT 为什么如此有效?
BERT 存在哪些优缺点?
BERT 擅长处理哪些下游 NLP 任务?
BERT 基于“字输入”还是“词输入”好?(对于中文任务)
BERT 为什么不适用于自然语言生成任务(NLG)?
Q11-Q15:针对 BERT 原生模型的缺点,后续的 BERT 系列模型是:
如何改进【生成任务】的?
如何引入【知识】的?
如何引入【多任务学习机制】的?
如何改进【mask 策略】的?
如何进行【精细调参】的?
Q16:XLNet 提出的背景是怎样的?
Q17:XLNet 为何如此有效:
为什么 PLM 可以实现双向上下文的建模?
怎么解决没有目标(target)位置信息的问题?
Q18:Transformer-XL 怎么实现对长文本建模?
Summary Table
写在前面
微软亚洲研究院成立 20 周年时表示:NLP 将迎来黄金十年。回顾基于深度学习的 NLP 技术的重大进展,从时间轴来看主要包括:NNLM(2003)、Word Embeddings(2013)、Seq2Seq(2014)、Attention(2015)、Memory-based networks(2015)、Transformer(2017)、BERT(2018)、XLNet(2019):
ACL2019NLP 进展趋势主要包括:预训练语言模型、低资源 NLP 任务(迁移学习/半监督学习/多任务学习/主动学习)、模型可解释性、更多任务 &数据集。本文主要介绍从【预训练语言模型】角度介绍 NLP 领域的进展。【预训练语言模型】已经形成了一种新的 NLP 范式:使用大规模文本语料库进行预训练,对特定任务的小数据集微调,降低单个 NLP 任务的难度。
预训练思想的本质是模型参数不再是随机初始化,而是通过一些任务(如语言模型)进行预训练;预训练属于迁移学习的范畴,本文的【预训练语言模型】主要指无监督预训练任务(有时也称自学习或自监督),迁移的范式主要为特征集成和模型精调(finetune)。
语言模型表示序列文本的联合概率分布,为降低对长文本的概率估算难度,通常使用一个简化的 n-gram 模型。为缓解 n 元语言模型概率估计时遇到的数据稀疏问题,提出了神经网络语言模型 NNLM,第一层参数可用作词向量表示。词向量可看作是 NNLM 的一个副产品,而 word2vec 通过一些优化技巧专注于词向量的产生,后来的 glove 词向量是通过共现语料矩阵进行高效分解产生的,glove 也可看作是更换了目标函数和权重函数的全局 word2vec。由于 word2vec、glove 等静态词向量未考虑一词多义、无法理解复杂语境,可通过预训练语言模型产生上下文相关的特征表示(动态词向量)。
注:本文没有把 word2vec 纳入预训练语言模型的范畴,虽然 word2vec 可看作语言模型,但其更专注于词向量的产生。本文的预训练语言模型主要指能够产生上下文相关的特征表示。
随着 ELMO/GPT/BERT 等预训练语言模型在 NLP 任务取得 SOTA 结果,之后又开发了一系列的新的方法,如 MASS、UNILM、ERNIE1.0、ERNIE(THU)、MTDNN、ERNIE2.0、SpanBERT、RoBERTa、XLNet、XLM 等。预训练语言模型推动了 NLP 技术的进步,引起了各界广泛关注。
本文通过以下几个方面对【预训练语言模型】进行介绍:
一. 不同视角下的预训练语言模型对比
二.预训练语言模型的基础:特征抽取机制+语言模型的分类
三.单向模型回顾+内核机制探究
四.BERT 的内核机制探究
五.BERT 系列模型进展介绍
六.XLNET 的内核机制探究
七.预训练语言模型的未来
一、不同视角下的预训练语言模型对比
Q1:从不同维度对比【预训练语言模型】
从特征抽取、预训练语言模型目标、BERT 系列模型的改进方向、特征表示 4 个视角,对比预训练语言模型:
不同的特征抽取机制:
RNNs:ELMO/ULMFiT/SiATL;
Transformer:GPT1.0/GPT2.0/BERT 系列模型;
Transformer-XL:XLNet;
不同的预训练语言目标:
自编码(AutoEncode):BERT 系列模型;
自回归(AutoRegression):单向模型(ELMO/ULMFiT/SiATL/GPT1.0/GPT2.0)和 XLNet;
BERT 系列模型的改进:
引入常识:ERNIE1.0/ERNIE(THU)/ERNIE2.0(简称为“ERNIE 系列”);
引入多任务学习:MTDNN/ERNIE2.0;
基于生成任务的改进:MASS/UNILM;
不同的 mask 策略:WWM/ERNIE 系列/SpanBERT;
精细调参:RoBERTa;
特征表示(是否能表示上下文):
单向特征表示:单向模型(ELMO/ULMFiT/SiATL/GPT1.0/GPT2.0);
双向特征表示:BERT 系列模型+XLNet;
二、预训练语言模型的基础:特征抽取机制+语言模型的分类
Q2:基于深度学习的 NLP 特征抽取机制有哪些?各有哪些优缺点?
1)能否处理长距离依赖问题
长距离依赖建模能力: Transformer-XL > Transformer > RNNs > CNNs
MLP:不考虑序列(位置)信息,不能处理变长序列,如 NNLM 和 word2vec;
CNNs:考虑序列(位置)信息,不能处理长距离依赖,聚焦于 n-gram 提取,pooling 操作会导致序列(位置)信息丢失;
RNNs:天然适合处理序列(位置)信息,但仍不能处理长距离依赖(由于 BPTT 导致的梯度消失等问题),故又称之为“较长的短期记忆单元(LSTM)”;
Transformer/Transformer-XL:self-attention 解决长距离依赖,无位置偏差;
2)前馈/循环网络 or 串行/并行计算
MLP/CNNs/Transformer:前馈/并行
RNNs/ Transformer-XL:循环/串行:
3)计算时间复杂度(序列长度 n,embedding size 为 d,filter 大小 k)
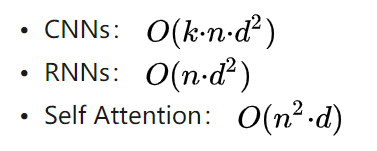
Q3:自回归和自编码语言模型各有什么优缺点?
1.自回归语言模型
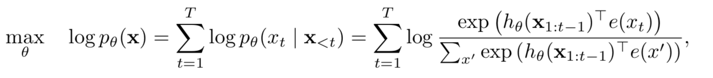
优点:
文本序列联合概率的密度估计,即为传统的语言模型,天然适合处理自然生成任务;
缺点:
联合概率按照文本序列从左至右分解(顺序拆解),无法通过上下文信息进行双向特征表征;
代表模型:ELMO/GPT1.0/GPT2.0;
改进:XLNet 将传统的自回归语言模型进行推广,将顺序拆解变为随机拆解(排列语言模型),产生上下文相关的双向特征表示;
2.自编码语言模型
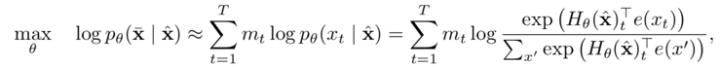
优点:本质为降噪自编码特征表示,通过引入噪声[MASK]构建 MLM,获取上下文相关的双向特征表示;
引入独立性假设,为联合概率的有偏估计,没有考虑预测[MASK]之间的相关性:
不适合直接处理生成任务,MLM 预训练目标的设置造成预训练过程和生成过程不一致;
预训练时的[MASK]噪声在 finetune 阶段不会出现,造成两阶段不匹配问题;
代表模型:BERT 系列模型;
三、单向模型回顾+内核机制探究
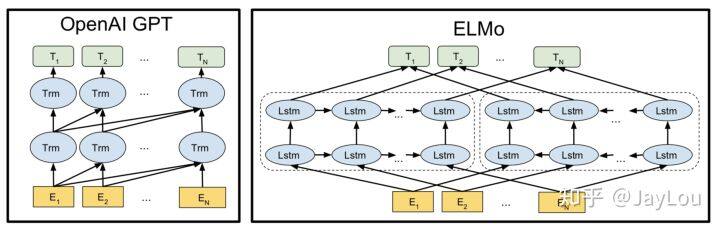
Q4:单向模型的内核机制是怎样的?有哪些缺点?
1、ELMO(华盛顿大学)
优点:
引入双向语言模型,其实是 2 个单向语言模型(前向和后向)的集成;
通过保存预训练好的 2 层 biLSTM,通过特征集成或 finetune 应用于下游任务;
缺点:
本质上为自回归语言模型,只能获取单向的特征表示,不能同时获取上下文表示;
LSTM 不能解决长距离依赖。
为什么不能用 biLSTM 构建双向语言模型?
不能采取 2 层 biLSTM 同时进行特征抽取构建双向语言模型,否则会出现标签泄漏的问题;因此 ELMO 前向和后向的 LSTM 参数独立,共享词向量,独立构建语言模型。
2、ULMFiT/SiATL
ULMFiT 要点:
3 阶段:LM 预训练+精调特定任务 LM+精调特定分类任务;
特征抽取:3 层 AWD-LSTM;
精调特定分类任务:逐层解冻。
SiATL 要点:
2 阶段:LM 预训练+特定任务精调分类任务(引入 LM 作为辅助目标,辅助目标对于小数据有用,与 GPT 相反);
特征抽取:LSTM+self-attention;
精调特定分类任务:逐层解冻;
都通过一些技巧解决 finetune 过程中的灾难性遗忘问题:如果预训练用的无监督数据和任务数据所在领域不同,逐层解冻带来的效果更明显。
3、GPT1.0/GPT2.0(OpenAI)
GPT1.0 要点:
采用 Transformer 进行特征抽取,首次将 Transformer 应用于预训练语言模型;
finetune 阶段引入语言模型辅助目标(辅助目标对于大数据集有用,小数据反而有所下降,与 SiATL 相反),解决 finetune 过程中的灾难性遗忘;
预训练和 finetune 一致,统一 2 阶段框架。
GPT2.0 要点:
没有针对特定模型的精调流程:GPT2.0 认为预训练中已包含很多特定任务所需的信息;
生成任务取得很好效果,使用覆盖更广、质量更高的数据。
缺点:
依然为单向自回归语言模型,无法获取上下文相关的特征表示。
四、BERT 内核机制探究
这一部分对 BERT 的内核机制进行介绍,在回答“BERT 为什么如此有效?”之前,首先介绍 Transformer 的内核机制。
Q5:Transformer[12]内部机制的深入理解(回顾)
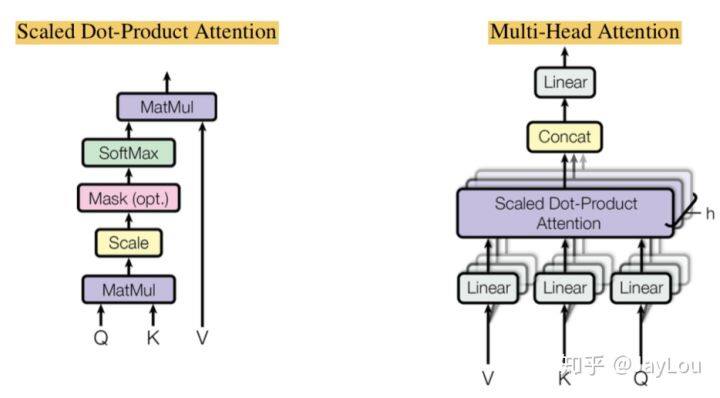
1、Multi-Head Attention 和 Scaled Dot-Product Attention:
本质是 self attention 通过 attention mask 动态编码变长序列,解决长距离依赖、无位置偏差、可并行计算;
为什么是缩放点积,而不是点积模型?
当输入信息的维度 d 比较高,点积模型的值通常有比较大方差,从而导致 softmax 函数的梯度会比较小。因此,缩放点积模型可以较好地解决这一问题。
为什么是双线性点积模型(经过线性变换 Q [公式] K)?
双线性点积模型,引入非对称性,更具健壮性(Attention mask 对角元素值不一定是最大的,也就是说当前位置对自身的注意力得分不一定最高)。
相较于加性模型,点积模型具备哪些优点?
常用的 Attention 机制为加性模型和点积模型,理论上加性模型和点积模型的复杂度差不多,但是点积模型在实现上可以更好地利用矩阵乘积,从而计算效率更高(实际上,随着维度 d 的增大,加性模型会明显好于点积模型)。
多头机制为什么有效?
类似于 CNN 中通过多通道机制进行特征选择;
Transformer 中先通过切头(spilt)再分别进行 Scaled Dot-Product Attention,可以使进行点积计算的维度 d 不大(防止梯度消失),同时缩小 attention mask 矩阵。
2、Position-wise Feed-Forward Networks:
FFN 将每个位置的 Multi-Head Attention 结果映射到一个更大维度的特征空间,然后使用 ReLU 引入非线性进行筛选,最后恢复回原始维度。
Transformer 在抛弃了 LSTM 结构后,FFN 中的 ReLU 成为了一个主要的提供非线性变换的单元。
3、Positional Encoding:
将 Positional Embedding 改为 Positional Encoding,主要的区别在于 Positional Encoding 是用公式表达的、不可学习的,而 Positional Embedding 是可学习的(如 BERT),两种方案的训练速度和模型精度差异不大;但是 Positional Embedding 位置编码范围是固定的,而 Positional Encoding 编码范围是不受限制的。
为什么引入 sin 和 cos 建模 Positional Encoding?
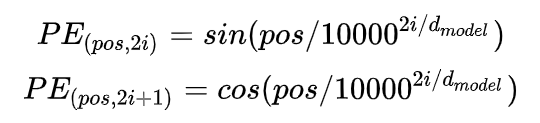
引入 sin 和 cos 是为了使模型实现对相对位置的学习,两个位置 pos 和 pos+k 的位置编码是固定间距 k 的线性变化:
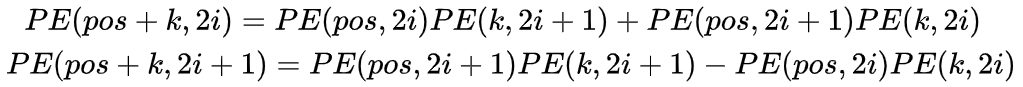
可以证明:间隔为 k 的任意两个位置编码的欧式空间距离是恒等的,只与 k 有关。
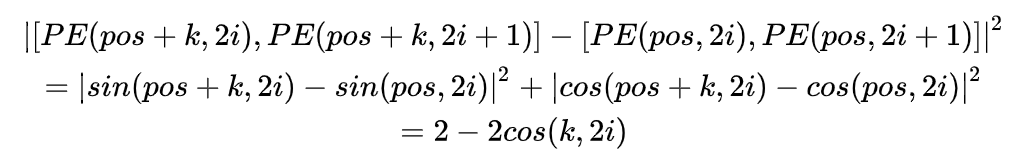
Q6:BERT[13]为什么如此有效?
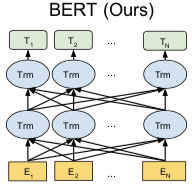
引入 Masked Language Model(MLM)预训练目标,能够获取上下文相关的双向特征表示;
引入 Next Sentence Prediction(NSP)预训练目标,擅长处理句子或段落的匹配任务;
引入强大的特征抽取机制 Transformer(多种机制并存):
Multi-Head self attention:多头机制类似于“多通道”特征抽取,self attention 通过 attention mask 动态编码变长序列,解决长距离依赖(无位置偏差)、可并行计算;
Feed-forward :在位置维度计算非线性层级特征;
Layer Norm & Residuals:加速训练,使“深度”网络更加健壮;
引入大规模、高质量的文本数据;
注意:
BERT 通过不同的迁移学习方式应用于下游任务,特别是 BERT 擅长解决的 NLU 任务;
BERT 通过 MLM 解决了深层 biLSTM 构建双向语言模型中存在的“标签泄漏”问题,也就是“see itself";
Q7:BERT 存在哪些优缺点?
优点:能够获取上下文相关的双向特征表示(BERT 的最大亮点);
缺点:
生成任务表现不佳:预训练过程和生成过程的不一致,导致在生成任务上效果不佳;
采取独立性假设:没有考虑预测[MASK]之间的相关性,是对语言模型联合概率的有偏估计(不是密度估计);
输入噪声[MASK],造成预训练-精调两阶段之间的差异;
无法文档级别的 NLP 任务,只适合于句子和段落级别的任务;
Q8:BERT 擅长处理哪些下游 NLP 任务?
适合句子和段落级别的任务,不适用于文档级别的任务(如长文本分类);
适合处理文本语言本身就能处理好的任务(如 QA/机器阅读理解),不依赖于额外特征(如推荐搜索场景);
适合处理高层语义信息提取的任务,对浅层语义信息提取的任务的提升效果不大(如文本分类/NER,文本分类关注于“关键词”这种浅层语义的提取);
适合处理句子/段落的匹配任务,因为 BERT 在预训练任务中引入 NSP;因此,在一些任务中可以构造辅助句(类似匹配任务)实现效果提升(如关系抽象/情感挖掘等任务);
不适合处理 NLG 任务,因为 BERT 在生成任务上效果不佳;
Q9:BERT 基于“字输入”还是“词输入”好?(对于中文任务)
如果基于“词输入”,会出现 OOV 问题,会增大标签空间,需要利用更多语料去学习标签分布来拟合模型。
随着 Transfomer 特征抽取能力,分词不再成为必要,词级别的特征学习可以纳入为内部特征进行表示学习。
Q10:BERT 为什么不适用于自然语言生成任务(NLG)?
由于 BERT 本身在预训练过程和生成过程的不一致,并没有做生成任务的相应机制,导致在生成任务上效果不佳,不能直接应用于生成任务。
如果将 BERT 或者 GPT 用于 Seq2Seq 的自然语言生成任务,可以分别进行预训练编码器和解码器,但是编码器-注意力-解码器结构没有被联合训练,BERT 和 GPT 在条件生成任务中只是次优效果。
五、BERT 系列模型进展介绍
这一部分介绍一些模型,它们均是对 BERT 原生模型在一些方向的改进。
Q11:针对 BERT 原生模型,后续的 BERT 系列模型是如何改进【生成任务】的?
1、MASS(微软)
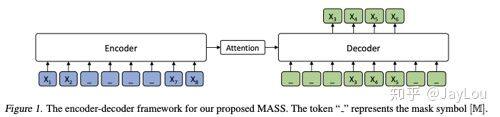
统一预训练框架:通过类似的 Seq2Seq 框架,在预训练阶段统一了 BERT 和 LM 模型;
Encoder 中理解 unmasked tokens;Decoder 中需要预测连续的[mask]tokens,获取更多的语言信息;
Decoder 从 Encoder 中抽取更多信息;
当 k=1 或者 n 时,MASS 的概率形式分别和 BERT 中的 MLM 以及 GPT 中标准的 LM 一致(k 为 mask 的连续片段长度))
2、UNILM (微软):
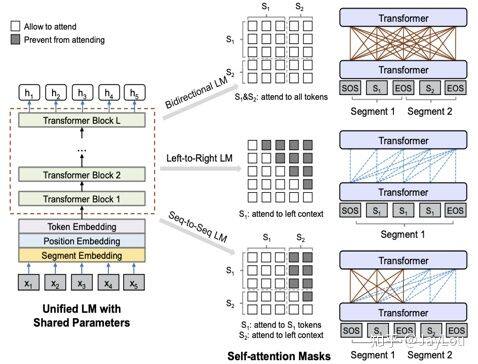
统一预训练框架:和直接从 mask 矩阵的角度统一 BERT 和 LM;
3 个 Attention Mask 矩阵:LM、MLM、Seq2Seq LM;
注意:UNILM 中的 LM 并不是传统的 LM 模型,仍然是通过引入[MASK]实现的;
Q12:针对 BERT 原生模型,后续的 BERT 系列模型是如何引入【知识】的?
1、ERNIE 1.0 (百度):
在预训练阶段引入知识(实际是预先识别出的实体),引入 3 种[MASK]策略预测:
Basic-Level Masking: 跟 BERT 一样,对 subword 进行 mask,无法获取高层次语义;
Phrase-Level Masking: mask 连续短语;
Entity-Level Masking: mask 实体;
2、ERNIE (THU):
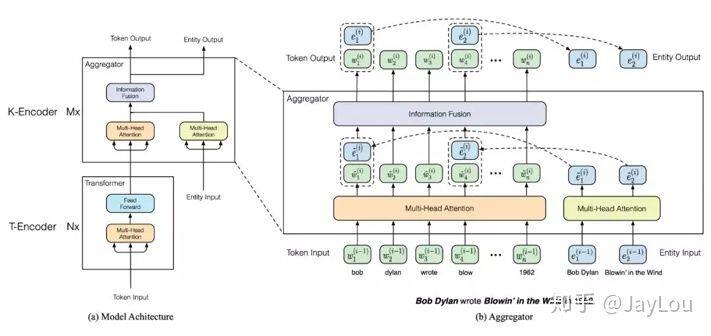
基于 BERT 预训练原生模型,将文本中的实体对齐到外部的知识图谱,并通过知识嵌入得到实体向量作为 ERNIE 的输入;
由于语言表征的预训练过程和知识表征过程有很大的不同,会产生两个独立的向量空间。为解决上述问题,在有实体输入的位置,将实体向量和文本表示通过非线性变换进行融合,以融合词汇、句法和知识信息;
引入改进的预训练目标 Denoising entity auto-encoder (DEA):要求模型能够根据给定的实体序列和文本序列来预测对应的实体;
Q13:针对 BERT 原生模型,后续的 BERT 系列模型是如何引入【多任务学习机制】的?
多任务学习(Multi-task Learning)是指同时学习多个相关任务,让这些任务在学习过程中共享知识,利用多个任务之间的相关性来改进模型在每个任务的性能和泛化能力。多任务学习可以看作是一种归纳迁移学习,即通过利用包含在相关任务中的信息作为归纳偏置(Inductive Bias)来提高泛化能力。多任务学习的训练机制分为同时训练和交替训练。
1、MTDNN(微软):在下游任务中引入多任务学习机制
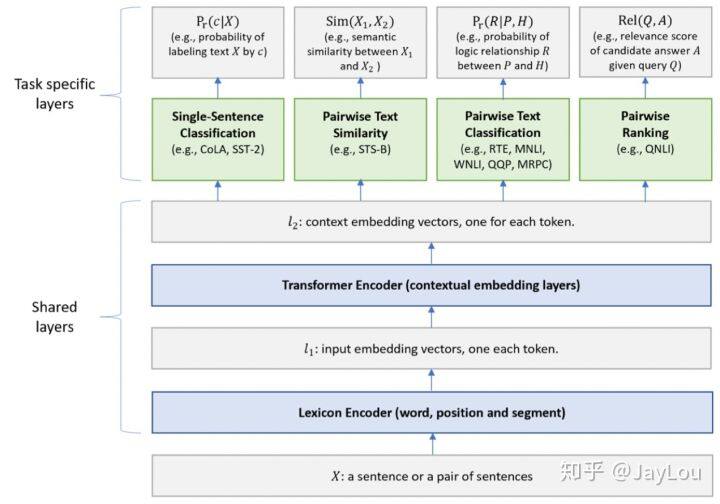
2、ERNIE 2.0 (百度):
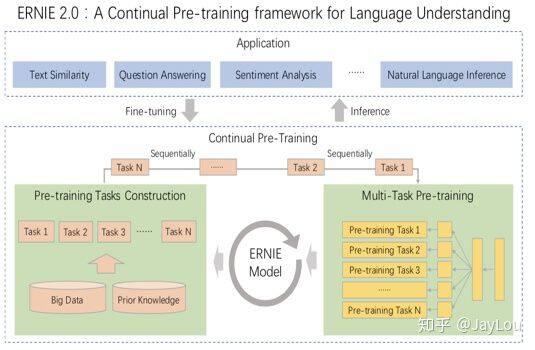
MTDNN 是在下游任务引入多任务机制的,而 ERNIE 2.0 是在预训练引入多任务学习(与先验知识库进行交互),使模型能够从不同的任务中学到更多的语言知识。
主要包含 3 个方面的任务:
word-aware 任务:捕捉词汇层面的信息;
structure-aware 任务:捕捉句法层面的信息;
semantic-aware 任务:捕捉语义方面的信息;
主要的方式是构建增量学习(后续可以不断引入更多的任务)模型,通过多任务学习持续更新预训练模型,这种连续交替的学习范式不会使模型忘记之前学到的语言知识。
将 3 大类任务的若干个子任务一起用于训练,引入新的任务时会将继续引入之前的任务,防止忘记之前已经学到的知识,具体是一个逐渐增加任务数量的过程[22]:
(task1)->(task1,task2)->(task1,task2,task3)->…->(task1,task2,…,taskN),
Q14:针对 BERT 原生模型,后续的 BERT 系列模型是如何改进【mask 策略】的?
原生 BERT 模型:按照 subword 维度进行 mask,然后进行预测;
BERT WWM(Google):按照 whole word 维度进行 mask,然后进行预测;
ERNIE 等系列:引入外部知识,按照 entity 维度进行 mask,然后进行预测;
SpanBert:不需要按照先验的词/实体/短语等边界信息进行 mask,而是采取随机 mask:
采用 Span Masking:根据几何分布,随机选择一段空间长度,之后再根据均匀分布随机选择起始位置,最后按照长度 mask;通过采样,平均被遮盖长度是 3.8 个词的长度;
引入 Span Boundary Objective:新的预训练目标旨在使被 mask 的 Span 边界的词向量能学习到 Span 中被 mask 的部分;新的预训练目标和 MLM 一起使用;
注意:BERT WWM、ERNIE 等系列、SpanBERT 旨在隐式地学习预测词(mask 部分本身的强相关性)之间的关系,而在 XLNet 中,是通过 PLM 加上自回归方式来显式地学习预测词之间关系;
Q15:针对 BERT 原生模型,后续的 BERT 系列模型是如何进行【精细调参】的?
RoBERTa(FaceBook):
丢弃 NSP,效果更好;
动态改变 mask 策略,把数据复制 10 份,然后统一进行随机 mask;
对学习率的峰值和 warm-up 更新步数作出调整;
在更长的序列上训练: 不对序列进行截短,使用全长度序列;
六、XLNet 的内核机制探究
在 BERT 系列模型后,Google 发布的 XLNet 在问答、文本分类、自然语言理解等任务上都大幅超越 BERT;XLNet 的提出是对标准语言模型(自回归)的一个复兴,提出一个框架来连接语言建模方法和预训练方法。
Q16:XLNet 提出的背景是怎样的?
对于 ELMO、GPT 等预训练模型都是基于传统的语言模型(自回归语言模型 AR),自回归语言模型天然适合处理生成任务,但是无法对双向上下文进行表征,因此人们反而转向自编码思想的研究(如 BERT 系列模型);
自编码语言模型(AE)虽然可以实现双向上下文进行表征,但是:
BERT 系列模型引入独立性假设,没有考虑预测[MASK]之间的相关性;
MLM 预训练目标的设置造成预训练过程和生成过程不一致;
预训练时的[MASK]噪声在 finetune 阶段不会出现,造成两阶段不匹配问题;
有什么办法能构建一个模型使得同时具有 AR 和 AE 的优点并且没有它们缺点呢?
Q17:XLNet 为何如此有效:内核机制分析

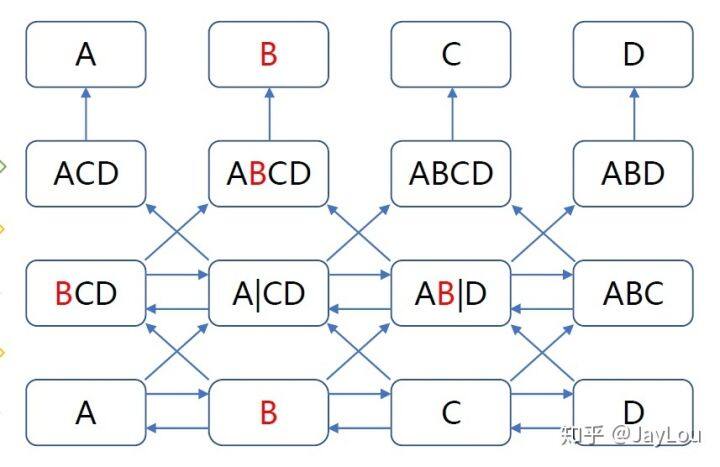
1、排列语言模型(Permutation LM,PLM):
如果衡量序列中被建模的依赖关系的数量,标准的 LM 可以达到上界,不像 MLM 一样,LM 不依赖于任何独立假设。借鉴 NADE 的思想,XLNet 将标准的 LM 推广到 PLM。
为什么 PLM 可以实现双向上下文的建模?
PLM 的本质就是 LM 联合概率的多种分解机制的体现;
将 LM 的顺序拆解推广到随机拆解,但是需要保留每个词的原始位置信息(PLM 只是语言模型建模方式的因式分解/排列,并不是词的位置信息的重新排列!)
如果遍历 𝑇! 种分解方法,并且模型参数是共享的,PLM 就一定可以学习到各种双向上下文;换句话说,当我们把所有可能的𝑇! 排列都考虑到的时候,对于预测词的所有上下文就都可以学习到了!
由于遍历 𝑇! 种路径计算量非常大(对于 10 个词的句子,10!=3628800)。因此实际只能随机的采样𝑇!里的部分排列,并求期望;
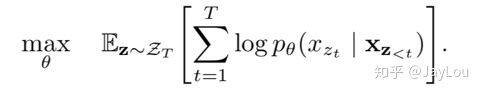
2、Two-Stream Self-Attention
如果采取标准的 Transformer 来建模 PLM,会出现没有目标(target)位置信息的问题。问题的关键是模型并不知道要预测的到底是哪个位置的词,从而导致具有部分排列下的 PLM 在预测不同目标词时的概率是相同的。

怎么解决没有目标(target)位置信息的问题?
对于没有目标位置信息的问题,XLNet 引入了 Two-Stream Self-Attention:
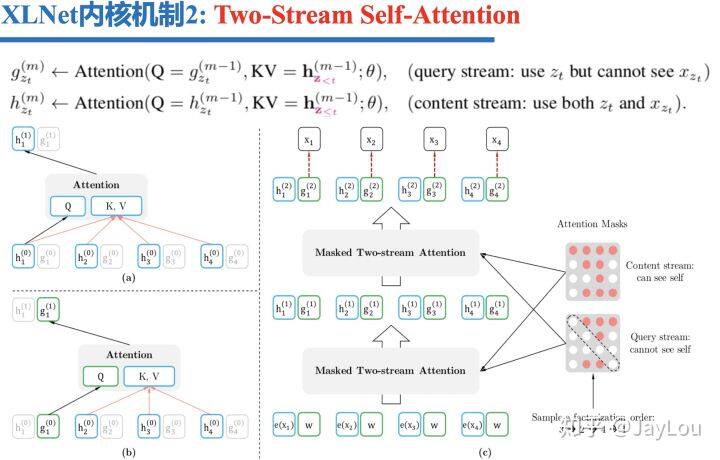
Query 流就为了预测当前词,只包含位置信息,不包含词的内容信息;
Content 流主要为 Query 流提供其它词的内容向量,包含位置信息和内容信息;
3、 融入 Transformer-XL 的优点(具体见 Q18)
Q18:Transformer-XL[28]怎么实现对长文本建模?
BERT(Transformer)的最大输入长度为 512,那么怎么对文档级别的文本建模?
vanilla model 进行 Segment,但是会存在上下文碎片化的问题(无法对连续文档的语义信息进行建模),同时推断时需要重复计算,因此推断速度会很慢;
Transformer-XL 改进:
引入 recurrence mechanism(不采用 BPTT 方式求导):
前一个 segment 计算的 representation 被修复并缓存,以便在模型处理下一个新的 segment 时作为扩展上下文 resume;
最大可能依赖关系长度增加了 N 倍,其中 N 表示网络的深度;
解决了上下文碎片问题,为新段前面的 token 提供了必要的上下文;
由于不需要重复计算,Transformer-XL 在语言建模任务的评估期间比 vanilla Transformer 快 1800+倍;
引入相对位置编码方案:
对于每一个 segment 都应该具有不同的位置编码,因此 Transformer-XL 采取了相对位置编码;
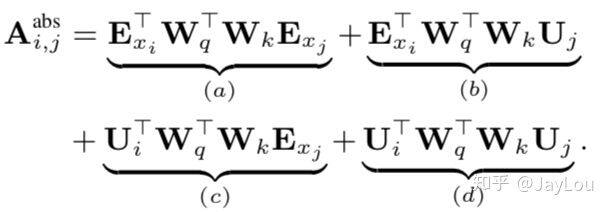
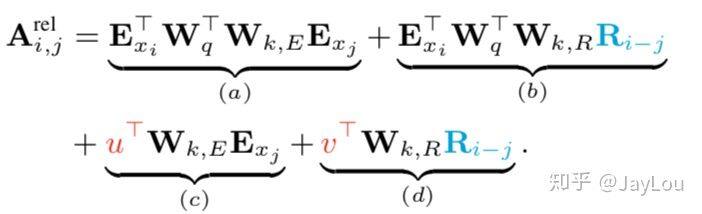
七、预训练语言模型的未来
上述的【预训练语言模型】主要从 2 大方面进行介绍:一是总的对比;二是分别介绍单向语言模型、BERT 系列模型、XLNet 模型。
可以看出,未来【预训练语言模型】更多的探索方向主要为:
复兴语言模型:进一步改进语言模型目标,不断突破模型的上界;
大数据、大算力:将大数据、大算力推到极致;
更快的推断:轻量级模型是否有可能达到 SOTA 效果?
引入更丰富的知识信息,更精细的调参,更有价值的 MASK 策略;
统一条件生成任务框架,如基于 XLNet 统一编码和解码任务,同时可考虑更快的解码方式;

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论