
近日,“李飞飞等斯坦福大学和华盛顿大学的研究人员以不到 50 美元的云计算费用,成功训练出了一个名为 s1 的人工智能推理模型”的消息引起了很多人关注。该模型名为 s1,该模型在数学和编码能力测试中的表现,据传与 OpenAI O1 和 DeepSeek R1 等顶尖推理模型不相上下。
这种零花钱消费水平就能精确复制价值数百万美元大模型给了大家非常广阔的想象空间。但现在我们真的可以达到这种水平吗?
我们先看看该模型都做了些什么。根据论文,s1 能够达到不错效果的核心有两点: s1K 数据集和预算强制法(budget forcing)。
s1 团队构建的 s1K 数据集包含 1,000 个精心挑选的问题,包括数学竞赛问题、博士级别的科学问题、奥林匹克竞赛问题等,配有推理轨迹和答案,并通过三个标准进行验证:难度、多样性和质量。这些数据主要来自 NuminaMATH、OlympicArena、OmniMath 等数据集,作为补充,团队还自己创建了两个原始数据集 s1-prob 和 s1-teasers。团队使用谷歌的 Gemini Flash Thinking 模型生成每个问题的推理轨迹(reasoning traces)和答案。
对于测试时扩展方法,s1 团队分成了两类:并行(后续计算独立运行,如多数投票任务)和顺序(后续计算基于早期计算,如长推理轨迹)。s1 团队更为关注后者并自己研发的预算强制方法,控制模型在测试时的计算量:如果模型生成的思考标记超过预期限制,就强制结束思考过程,添加“end-of-thinking token 分隔符”和“最终答案”,使模型过渡到生成答案步骤;如果希望模型在问题上花费更多的测试时计算量,则抑制“end-of-thinking token 分隔符”,并在模型当前的推理轨迹中追加“等待”,以鼓励更多的探索。
最后,s1 团队对阿里的 Qwen2.5-32B-Instruct 进行 s1K 的监督微调并应用预算强制后,得到模型 s1-32B。微调使用 PyTorch FSDP,在 16 个 NVIDIA H100 GPU 上花费了 26 分钟。
产生了哪些误解?
对于该论文的成果,不少人提炼出了这样几个关键信息:李飞飞团队用不到 50 美元训练出媲美 DeepSeek R1、OpenAI o1 的 AI 推理模型;该模型通过蒸馏法由 Gemini Thinking Experimental 模型提炼出来的 1000 个样本小型数据集;对 Qwen2.5-32B-Instruct 模型进行监督微调;使用 16 个英伟达 H100 GPU 进行了 26 分钟的训练。
有人为此感到惊喜,也有人表示持怀疑。总的来看,这里面的信息有真有假。毕业于西安电子科技大学的知乎大模型优秀答主段小草,针对讨论比较多的几个问题进行了剖析。
问题一:都说是李飞飞团队,跟她有关系吗?
答:有关系,但不好说多不多。论文标 * 的共同一作有 4 位,主要工作也应该是这几位做的。李飞飞应该是指导/挂名(论文致谢中说了 GPU 和经济赞助是斯坦福大学,但全文没有提及李飞飞更多具体论文贡献)。

其中,Niklas Muennighoff 目前在斯坦福大学攻读博士研究大型语言模型,与 Contextual AI & Ai2 有合作,学士学位是在北京大学获得。
Zitong Yang 是斯坦福大学自然语言处理组(Stanford NLP Group)的统计学博士,曾分别在谷歌、苹果任职。此前在伯克利加州分校就读,并在 2020 年获得该校最高学术荣誉。他开发了 Bellman Conformal Inference 方法用于时间序列预测的置信区间校准,提出了 ResMem 提高模型泛化能力。
Xiang Lisa Li 也是斯坦福大学博士,开发了 HALIE 框架,用于评估人类与语言模型的交互。Weijia Shi 则是华盛顿大学博士,开发了检索增强的语言模型框架 REPLUG 、提出了 INSTRUCTOR 模型和旨在减少幻觉的 Context-aware Decoding 方法,目前在 Ai2 工作。
问题二:真的只用花 50 美元吗?
答:如果只考虑最后一轮成功微调训练出 s1 模型所消耗的 GPU 卡时,是的,甚至更少。论文中提到的 s1 模型的训练卡时只需要 7 H100 卡,作者对媒体说的原话是“可以用 20 美元在云平台上租到这些算力”。
关于这里的成本,有三点需要说明:
s1 模型是基于 Qwen2.5-32B-Instruct 模型使用 1000 条数据进行的 SFT 微调,而非从头开始的模型训练(想想也不可能);
正如 DeepSeek V3 的 557.6 万美元训练成本一样,这里的成本只包括训练时的 GPU 算力费用,而不包括人力、数据等一切其他成本;
s1 模型并非只训了一轮,研究人员还做了很多其他的实验和测试。
微调一个模型的目的和成本,与从零开始训练一个模型天差地别,所以如果你真的相信 50 美元可以训练出超过 o1/R1 的模型,那至少也要把 Qwen2.5-32B 的训练成本加上。
问题三:真的能超过 o1/R1 吗?
答:不能。只能通过精心挑选的训练数据,在特定的测试集上超过 o1-preview,而远远没有超过 o1 正式版或者 DeepSeek R1。
看论文中给出的数据,最后一行就是论文的主要成果:
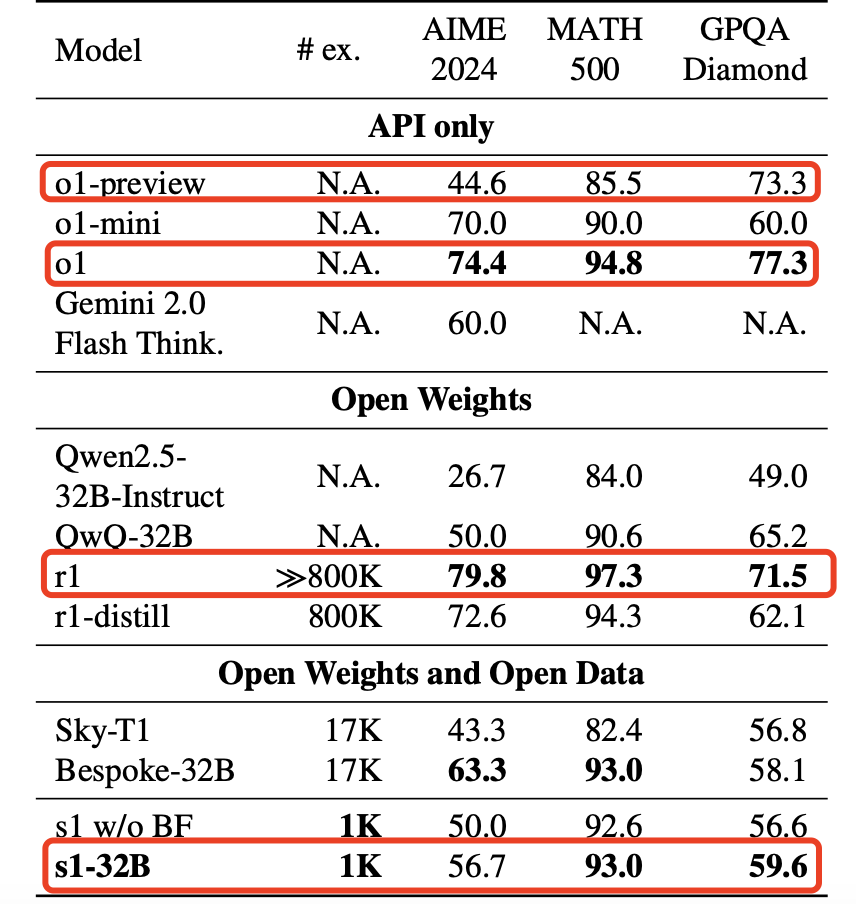
由此看出,在 AIME 2024 和 MATH 500 两个测试集中,s1 可以超过 o1-preview,但无论在哪个测试集,s1 都没有超过 o1 正式版和 R1,而且可以说差距还很大。
为什么说还需要精心挑选数据呢?可以看另一组分数,这是用不同数据集微调的分数差异:
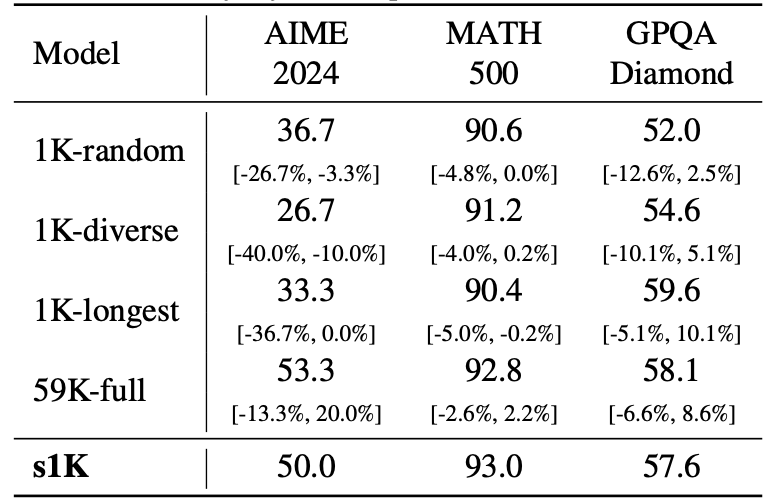
问题四:训练数据真的是“蒸馏”Gemini 吗?
答:s1 团队先收集了 59k 问题,然后从中筛选出了最终的 1k 问题。将这 1k 问题提交到 Gemini 2.0 Flash Thinking 中生成思维链和答案,以此构建数据集去微调开源的 Qwen 模型。
“尽管我认为,这种做法严格来说不叫蒸馏,而是拿 Gemini 生成数据并对 Qwen 做 SFT(有监督微调),但作者们自己在论文里写了这就是‘蒸馏’。那我只能说,现在‘蒸馏’的概念显然已经被扩大化了。这种行为是否属于‘蒸馏’,取决于你对‘蒸馏’的定义,我没办法给出标准答案。”
问题五:虽然没超过 o1/R1,但确实能超过 o1-preview,同时微调后也的确比 Qwen2.5-32B-Instruct 进步显著,怎么做到的?
答:一是微调用的训练数据起到了一定作用;二是强制让模型延长思考时间(test time scaling),具体做法叫做“Budget Forcing”预算强制,也就是强制限制模型使用最大或最小 tokens 进行推理,以此控制模型的思考长度。
为了尽可能延长模型的思考,他们将模型的思考放在
推理时插入的“Wait”,也许会像当初的 Step by Step 一样,成为一个魔法 token。“这或许就是古人‘三思而后行’的哲学吧!”
问题六:我可以体验 s1 模型吗?
答:s1 模型的论文、数据、模型完全开源,但并没有托管线上服务以供直接体验。不过,有人对 s1-32B 模型进行了量化,你可以使用 ollama run hf.co/brittlewis12/s1-32B-GGUF:Q4_0 拉取到本地运行。
开源地址:
https://github.com/simplescaling/s1
最后总结一下就是:李飞飞的学生,精心选了 1000 条高质量的数据,通过让 Gemini 补充完善思维链之后作为数据集,以开源的 Qwen2.5-32B 为基座微调出 s1;然后在 s1 输出时,用“预算强制”方法强行拉长模型的思考时长和输出 token,然后发现其结果在特定测试集上可以媲美 o1-preview,但比不过 o1 和 DeepSeek R1(差距还比较大)。
“该论文的工作确实有一定价值,但远远不必夸大到颠覆 o1/R1 甚至 NVIDIA 算力需求的级别。
顺便一提,近期有另一篇论文《LIMO: Less is More for Reasoning》,同样是基于 Qwen2.5-32B 探讨测试时计算扩展,可以一并学习。”段小草说道。
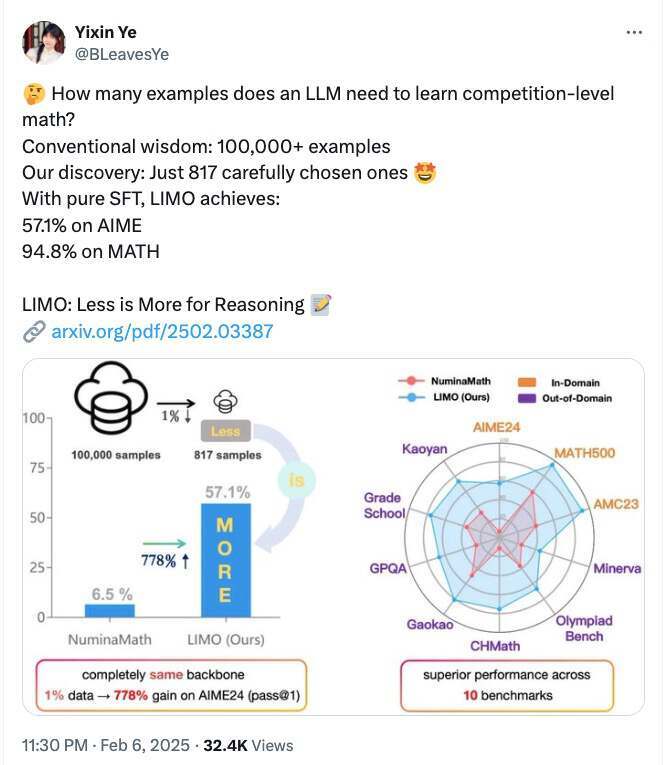
其中,《LIMO: Less is More for Reasoning》发现,通过极少数数据示例即可有效激发模型的复杂数学推理能力。这一发现不仅挑战了模型对大规模数据需求的假设,还挑战了监督微调(SFT)主要导致记忆而非泛化的常见观点。
根据论文,LIMO 团队仅使用了 817 个精选训练样本,通过构建更高质量推理链,结合推理时计算扩展和针对性微调,就在极具挑战性的 AIME 基准测试中达到了 57.1%的准确率,其中 MATH 基准测试中达到了 94.8%的准确率,数据量是之前基于 SFT 大模型的 1%,但 AIME 准确率从 6.5%提升至 57.1%,MATH 从 59.2%提升至 94.8%。
值得注意的是,该论文一作 Yixin Ye 是上海交大的本科生,也是 GAIR 实验室成员,未来计划读博。
如何被曲解了?
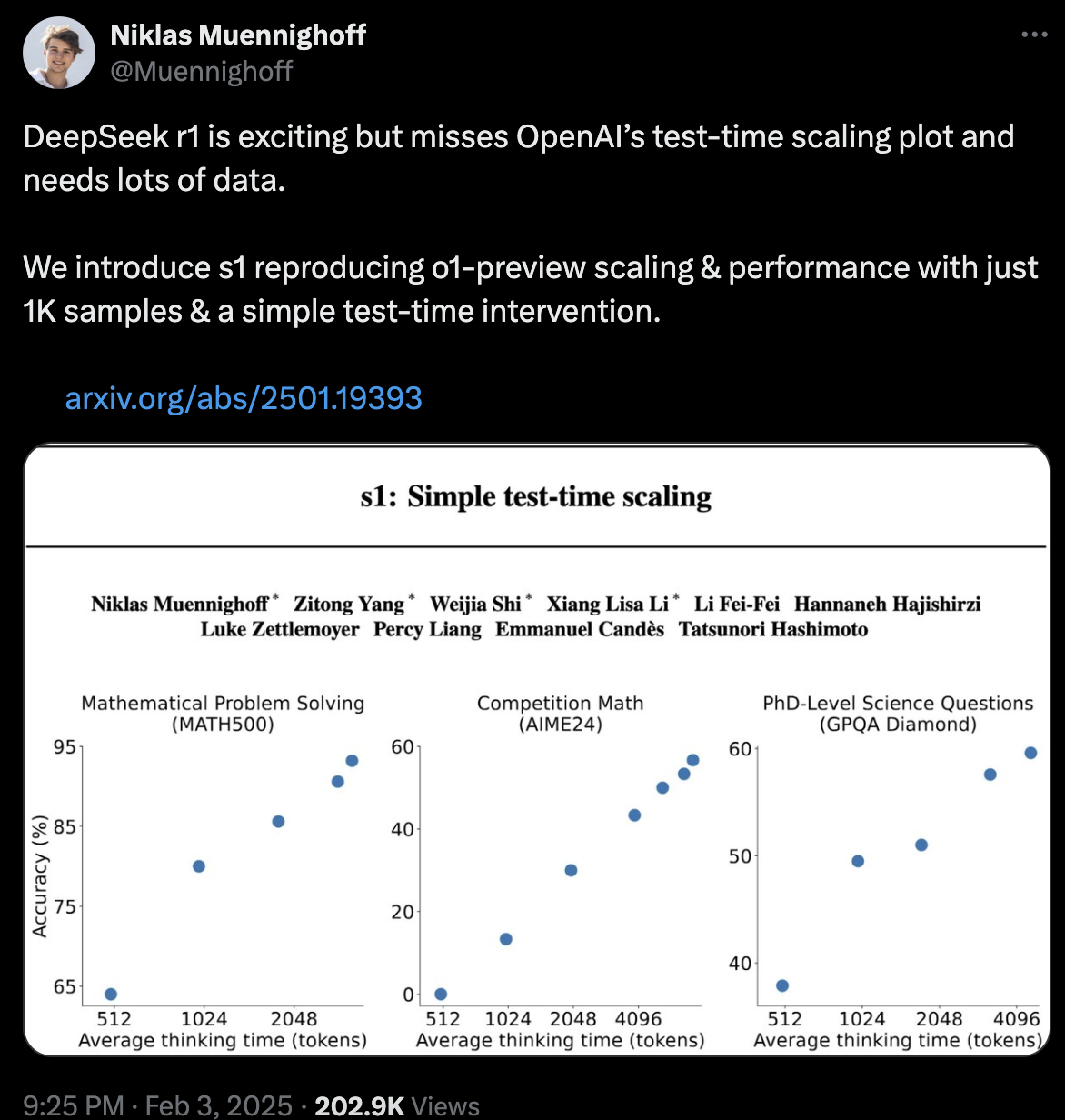
“李飞飞团队”的这篇论文 1 月 31 日提交并于 2 月 3 日修订后,作者 Niklas Muennighoff 发了一篇推文,可以看作是这篇论文宣传的冷启动。值得注意的是,这里论文作者自己说明了复现的是 o1-preview 的成绩,而不是 o1,也不是 R1。
之后 AI 工程师 Tim Kellogg 于 2 月 3 日发了一篇博客,标题简单直接写道“S1:6 美元的 R1 竞争对手”。“这篇文章比较标题党,因为你不可能用 6 美元租到 16 卡的 H100 算力,不知道作者是如何估算出这个价格的。但是不重要,总之这个时候所谓的成本就是 16 x H100 x 26 分钟。”段小草评价道。

北京时间 2 月 6 日上午,外媒 TechCrunch 发了一篇报道《研究人员用不到 50 美元为 OpenAI o1 推理模型制造了一个开源的竞争对手》这篇报道除了用 50 美元作噱头外,关于论文技术部分的内容还是比较靠谱的。而“50 美元”的来源是 Niklas Muennighoff 在采访中告诉 TechCrunch 他可以用大概 20 美元的价格从云平台租到一次训练所需的算力。TechCrunch 还是“保守”了一点,帮他把 20 美元改成了不到 50 美元。

消息到国内,李飞飞、50 美元、R1、o1 等都成了关键词,也被很多人误读。不过也有人对此不是很在意,“真假暂且不说,我个人认为意义还是非凡的,标志着高等级大模型这种王谢堂前燕,开始飞入寻常百姓家。”
相关链接:
https://arxiv.org/pdf/2501.19393
https://www.zhihu.com/question/11467407313/answer/94584520134




