
导读:当前机器翻译模型通常采用自注意力机制进行编码,训练时直接将 Ground Truth 词语用作上文,并行生成所有的目标词语,极大的提升了训练速度。但测试的时候却面临以下难题:
首先,模型得不到 Ground Truth,从而只能用自己生成的词作为上文,使得训练和测试的分布不一致,影响了翻译质量;
其次,由于每个目标词语的生成依赖于其之前生成的词,所以目标词语只能顺序生成,不能并行,从而影响了解码速度。
本次分享将针对以上问题,介绍他们的解决方法。
具体分享内容如下:
改进训练和测试的分布不一致问题:
采用计划采样的方法 (ACL 2019 best paper)
采用可导的序列级损失函数进行贪心搜索解码
解码速度提升:
基于 Cube Pruning 解码算法
融入序列信息的非自回归翻译模型
背景
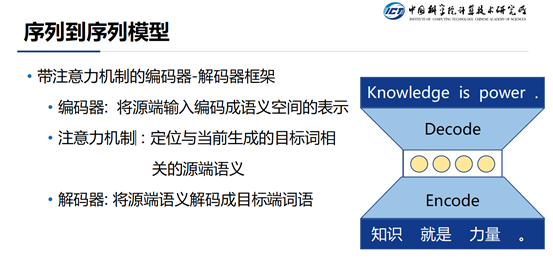
当前,自然语言处理方向的生成任务主要包括:机器翻译,人机对话,文章写作,文章摘要等等。目前这些问题主要是通过序列到序列模型来解决的。序列到序列模型的主要架构是一个带有注意力机制的编码器-解码器架构。这个架构基于一个重要的假设:即“源端的输入和目的端的输出之间是可以找到一个共同的语义空间。编码器的任务就是对输入进行各种变换,映射到共同语义空间上的一个点。解码器的任务是对共同语义空间的这个点进行一些反操作,将其映射到目标端空间,从而生成相应的词语。考虑到在每一步进行翻译的时候不需要关注所有的源端输入,而是仅仅关注一部分,注意力机制主要目的就是将当前步需要关注的部分找出来。
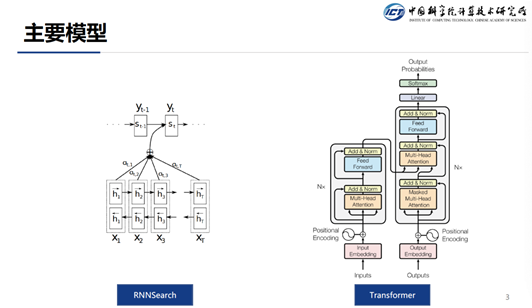
目前主流的序列到序列模型主要包括两种: 一个是 RNNSearch,一个是 Transformer。
RNNSearch 通过 RNN 来将源端的输入编码成一个表示,通常源端采用的是双向 RNN,这样对于每一个源端 Token 的编码表示都能考虑到其上下文信息。在目标端同样是使用一个 RNN,它可以将翻译的历史信息给串起来,这样在当前步翻译的时候就能考虑到上文的信息。
Google 在 2017 年提出了 Transformer 结构,该结构经过无数人的验证,发现非常好用,所以 Transformer 就成为了当前主流的序列到序列模型。Transformer 主要的机制是:在生成源端表示的时候并没有使用 RNN,而是使用自注意力机制来生成每一个 Token 的表示。这样做的好处是,在训练的时候可以并行,因为每个词都可以并行的和其它词计算 attention ( RNN 则只能串行 )。同样在解码端的时候,也是使用的自注意力机制。
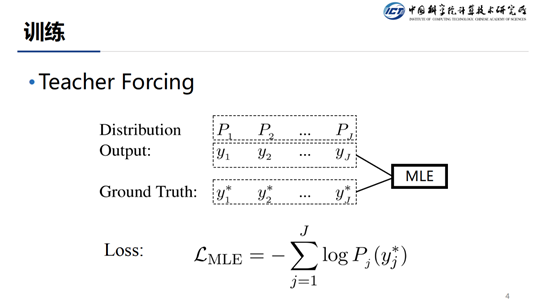
这种模型在训练的时候都是采用的 TeacherForcing 形式。模型在解码当前步的时候,通常会有三个输入:解码器当前的状态,attention 和上一步解码的结果。在训练的过程中,我们通常使用上一步的真实输出而非模型输出作为当前步解码的结果,这就是所谓的 Teacher Forcing。
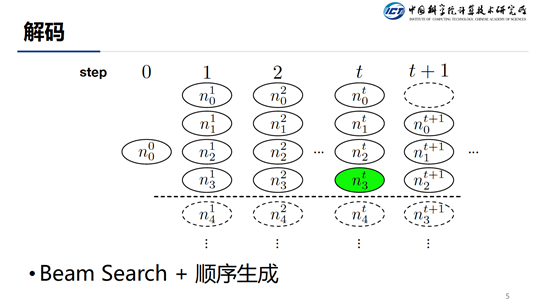
在 Inference 的时候通常采用 Beam-Search +顺序生成的方式,在每一步都保存 Top-K 个最优结果。
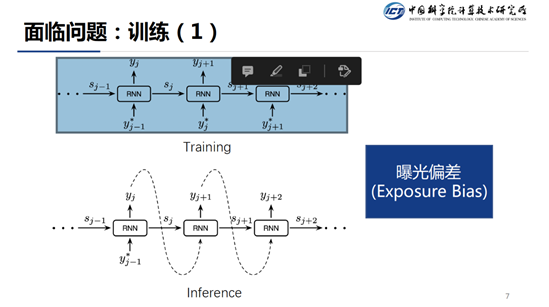
在介绍了训练和推断之后,我们来看一下目前面临的问题,因为在训练的时候我们使用 Teacher Forcing 的方式,但是我们在推断的时候并不知道上一步的 GroundTruth 是什么,所以,我们只能将上一步预测的结果来近似为 Ground Truth。这样,训练和推断在生成分布的条件上就产生了差异(Ground Truth vs Predicted),这个问题被称作为 Exposure Bias。

在训练的时候,我们还存在另一个问题。训练的时候由于我们使用的交叉熵损失函数,该损失函数只对 Ground Truth 友好,对于非 Ground Truth 的结果一视同仁。但是对于翻译任务来说,并不是只有一种翻译方式,从 slides 中可以看到,Output1 和 Ground Truth 表示的是同一个意思,但是 Output2 和 Ground Truth 表示的含义就是不同了,但是在训练的时候,交叉熵损失函数会将 Output1 和 Output2 一视同仁,这样是不合理的。
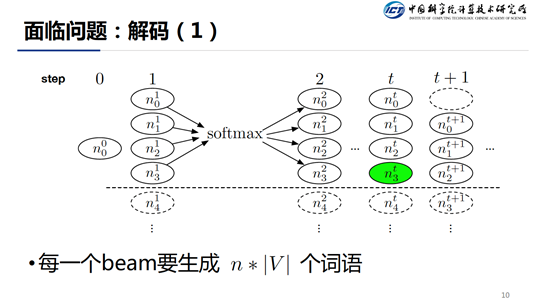
在推断阶段解码的时候同样存在两个问题,在每一个解码 step 我们都要执行 n 各预测,每个预测都要得到整个词表的一个分布,所以在每一个 step 都要生成 n*|V|个词语。而且每个时间步还必须串行,这大大影响了解码速度。
训练
1. 计划采样
对上面提到的问题进行一个小总结:
① 训练
预测过程中 Ground Truth 的未知导致的 Exposure Bias 问题
交叉熵损失函数的逐词匹配所导致对于所有的非 Ground Truth 一视同仁的问题。
② 解码
Beam Search 的 Beam Size 会引入大量的计算成本
自回归解码导致的无法并行问题。

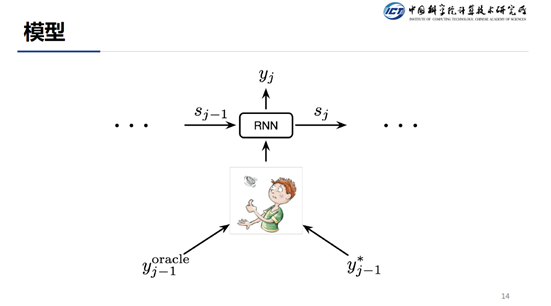
首先,针对于 Exposure Bias 问题,我们采用的是进化采样的方法,这个就是我们 2019ACL Best Paper 的工作。针对与训练和测试时 context 不一致的情况,我们的解决方法的主要思想是,在训练的时候模仿测试时候可能会碰到的情况,这样在测试的时候就会发现,当前碰到的情况在训练的时候都碰到过,这样模型就可以应对了。
具体的做法是我们在每一步,模拟上一步的翻译结果,就是 slides 中的 oracle,其中带*的是就是 Ground Truth,在每一步,我们都会随机的选择是 Oracle 还是 Ground Truth 来作为当前步的上一步词输入。
使用上述方法,我们需要解决的 三个关键问题 是:
如何生成 Oracle 翻译
Oracle 和 Ground Truth 如何对上文进行采样
如何训练模型

对于 Oracle 的生成,我们有两种方法,一个是生成词级别的 Oracle,另一个是生成句级别的 Oracle。词级 Oracle 即每一步都会选择最优,句子级别 Oracle 需要考虑到整个句子的最优。
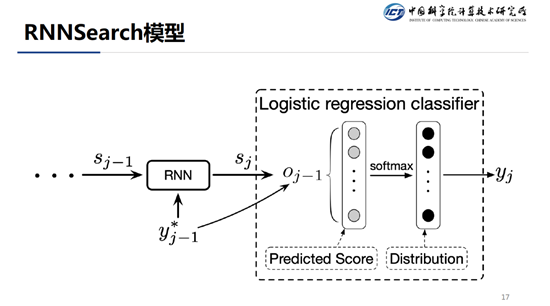
由于 RNN Search 会在生成 oracle 的算法中会用到。在讲生成 oracle 的算法之前,先大体介绍一下 RNN Search 模型。RNN Search 在当前步翻译的时候,会输入历史的隐状态信息,同时也会将上一步翻译的结果输入进去,经过一系列的变换,会得到当前步的一个隐状态 ,该隐状态再经过几层全连接的计算,最终输入到 softmax 层得到词表中每一个词的归一化的分数。
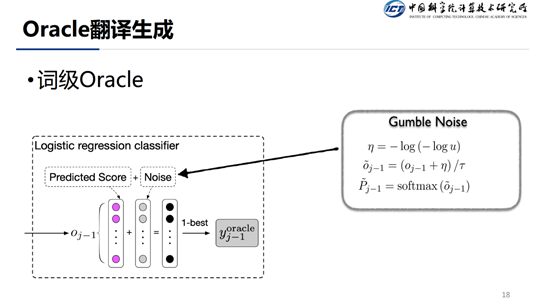
在生成词级 oracle 的时候,我们会在 softmax 归一化分布之前加上一个 Gumble Noise。Gumble Noise 的公式如 slides 中所示,其中 表示一个均匀分布。式子中的 表示温度,当非常大的时候,相当于 argmax,当 比较小的时候,相当于均匀分布。

对于句级 Oracle,我们首先采用 Beam Search 生成前 K 个候选译文,然后对选定的 K 个候选译文进行排序,这里的排序可以根据 K 个候选译文和 Ground Truth 计算一个 BLUE 值,还可以用一些其它的方法进行排序,最终选取得分最高的译文作为句级的 Oracle。词级 Oracle 和句级 Oracle 是一个局部最优和全局最优的一个区别。
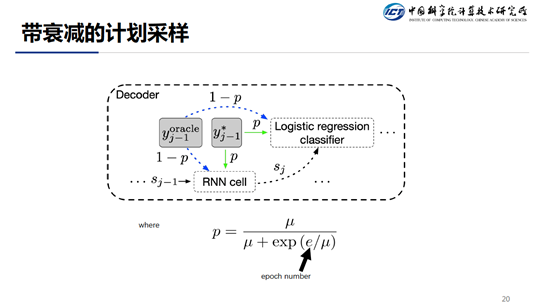
对于采样,具体是怎么操作的呢?首先考虑到一点就是在刚开始训练的时候,模型的效果不怎么好,这样,无论是词级 oracle 的生成还是句级 oracle 的生成效果肯定都不是很理想,如果这时候使用 oracle 来引导模型训练的话, 可能会使得模型收敛的比较慢。一个比较合理的做法是,刚开始我们尽量选用 Ground Truth 的词,当模型快收敛的时候,我们再加大 Oracle 翻译的采样比例。这里的采样概率公式如 slides 所示,其中,随着 epoch 的增长,系统越来越倾向于选择 oracle label。

对于训练的话,同样的采用最大化 log likelihood 的方式。

实验结果:除了对比 Transformer 和 RNN-Search,也对比了另外两个系统,SS-NMT 和 MIXER。其中,SS-NMT 也是通过计划采样的方式。MIXER 的 loss 分为两个部分,一个部分是传统的 Transformer 使用的交叉熵损失函数,另外一部分是将 BLEU 值作为 reward,然后通过 policy gradient 的方法对模型进行训练。
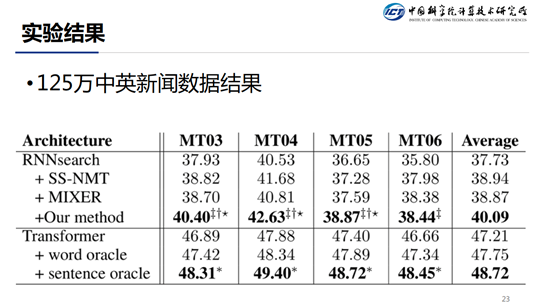
这个是在中英文新闻数据上的结果,可以看到,在 RNN-Search 的系统上, 我们相比于 Baseline 能够提升 2.3 个点。在 Transformer 系统上,相比于 Baseline 能够提升 1.5 个点。
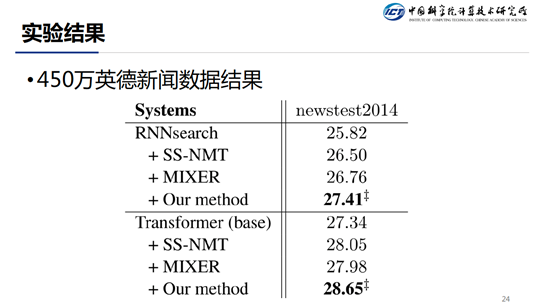
在英德新闻数据结果上,基于 RNN-Search 的系统比 baseline 高了 1.6 个点,基于 Transformer 的系统比 baseline 高了 1.3 个点。
2. 可导的序列级目标
接下来介绍如果解决词级匹配的对于好一点的匹配和差的匹配一视同仁的问题。

这个是我们在 EMNLP 2018 上所做的工作。通过使用可导的序列级目标来解决词级匹配的问题。

首先介绍一下传统的序列级损失函数。传统的序列级损失函数基本上都是基于 N-gram 正确率的损失函数,比如,BLEU,GLEU 等等。计算方法为,命中 n-gram 的个数/总共的 n-gram 的个数(candidate),其中 n-gram 的个数为其每个词语出现频次的乘积。
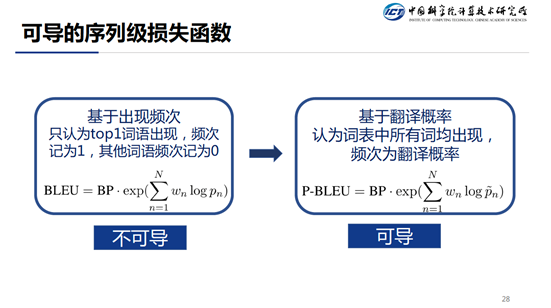
直接使用 BLEU 不可到的原因是因为操作中有 argmax,为了使其可导,我们使用 token 的预测概率,而非使用 argmax。这个方法和直接用 BLEU 作为 Score,然后 reinforce 算法直接训练对比有啥优势?由于 reinforce 算法的方差比较大,所以在训练的时候是很难收敛的。而使用传统的梯度下降的方法,训练过程就会平稳的多。

这里是 3-gram 的例子,其中 output 是概率最高的词,3-gram 概率的是由独立 Token 的输出概率相乘得到结果,然后求和会得到 The total probabilistic count of 3-grams。将匹配上的 3-gram 的概率拿出来求和作为分子,Total probabilistic count 作为分母,计算得到 Precision of 3-grams。这就是我们的 loss。
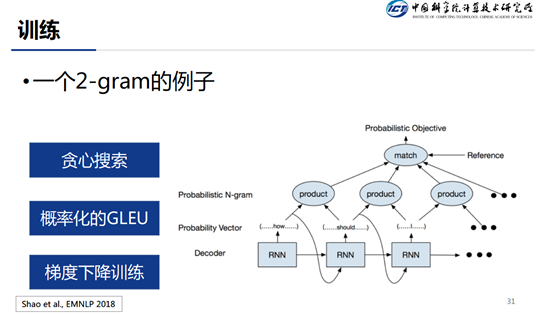
这个例子用来展示整个的训练过程,这里需要注意的一点就是,和传统的 teacher forcing 方式不同,这里当前步输入的为上一步预测的结果(贪心搜索得到的结果),而不是 ground truth 的值。剩下的就是按照上页 slides 介绍的来计算 loss。对于 loss 采用传统的梯度下降算法即可。下面贴的是在数据集上的结果。
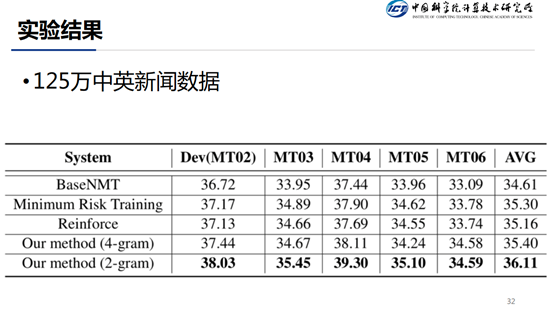
从结果中可以看出,2-gram 比 4-gram 的效果要好,这里我们给出的解释是,过多的使用自己生成的去计算的话,会存在一定程度上的错误累积。
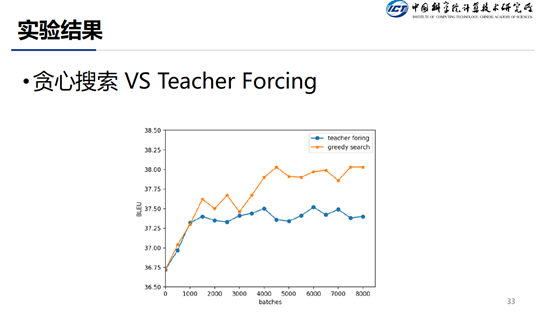
在训练的时候,也是可以通过 teacher forcing 的方式来训练的,但是从图中可以看出,teacherforcing 的方式收敛的比较快,但是效果不如 greedy search 的方式好。
解码
1. CubePruning
下面介绍在解码方面的两个工作,第一个工作要解决的是 beam search 每一步要计算 BeamSize*|V|的问题,这个计算量大大降低了 inference 时候解码的速度。

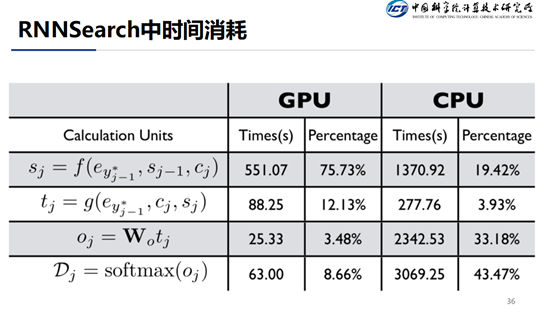
这是解码过程中每个步骤的时间消耗,对于 GPU 来说,大部分的时间消耗在的计算上,其它三个步骤比较节省时间,对于 CPU 来说,最耗费时间的是最后两个步骤,因为|V|比较大。
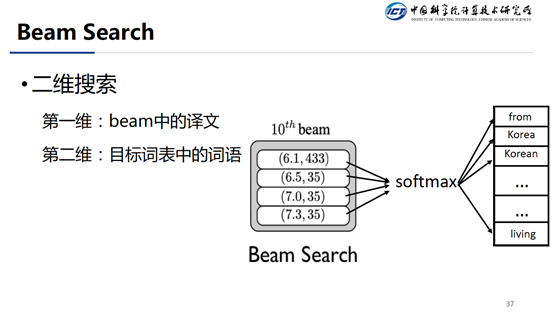
传统的方法使用的是 Beam Search,传统的 Beam Search 其实是一个二维的搜索方法。其中第一维就是已经生成的部分的译文,假设 Beam Size = 4,那么就是四个译文。第二维度是这四个译文都要进行下一步的 Token 预测计算。总共就需要计算 4*|V|的概率。因为|V|的个数通常是几千上万级别的,所以这个部分的计算量就非常大。
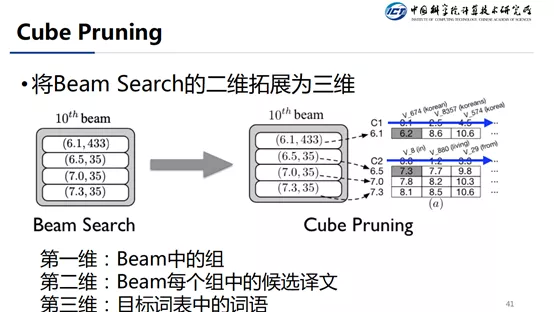
我们的做法是将二维的搜索扩展成三维的搜索,具体的做法分为以下几步:
① Beam 分组:假设我们要解码第 11 步,我们就将第 10 步解码出来相同 Token 的候选序列归为一组。
② 分组预测第 11 步的候选 Token:只用每个组得分最高的哪个候选序列来计算当前的 Token 分布。
③ 近似组员的 Token 分布:由上一步已经知道本组最优的候选序列的下一个 token 的预测分布,对于组员来说,也将共享其老大计算出来的 Token 分布 score,然后和自身的序列 score 相加,得到自身扩展一个 Token 后的 score。这个 score 作为自身的近似分。
④ 查找 Top-K:经过上面的计算之后,这样每个组就是得分其实是一个二维矩阵,我们将矩阵横轴作为每个组员,纵轴表示当前步预测的 token,然后保证右上角 score 最大,往右,往下都是减小。这样便于我们查找 Top-K。具体请看下一张 slides。
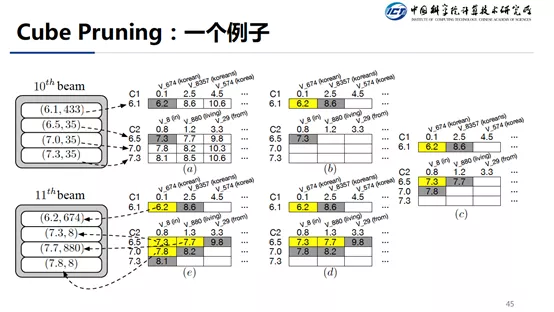
对于近似的 score 这里有两个选择:
如果取到的 candidate 是预测的 score,那么用真实的状态来重新计算一下这个 score,这时候也顺便更新了一下自己的隐状态
直接用预测的 score,不使用更新的方式,这时候和老大哥共享隐状态
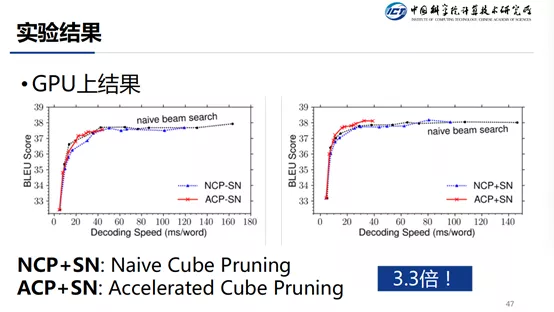
这个是 GPU 上的结果,横轴是速度,纵轴是 BLEU 值,可以看出在取得最优的 BLEU 值的情况下,我们的方法所用的时间是更短的。速度可以提升 3.3 倍。在 CPU 下,提速可以达到 3.5 倍。
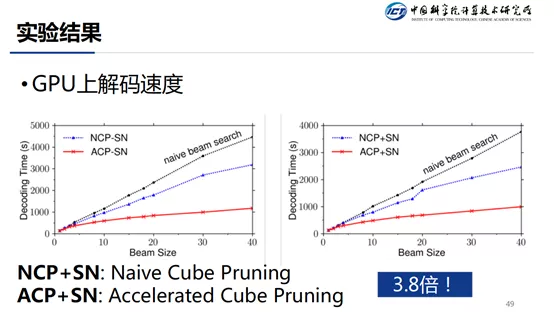
在 Beam Size=40 的情况下,GPU 上速度提升 3.8 倍,CPU 上提升 4.2 倍。
2. 非自回归解码
最后介绍一下基于非自回归的解码方法,传统的解码方法是顺序生成的。如果能够使得解码的时候并行的方式生成,这速度将会大大的提升。

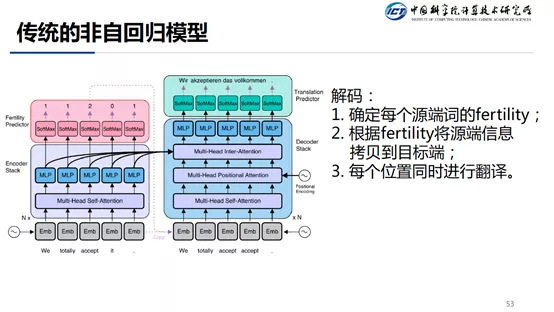
传统的非自回归模型的做法是,在 Transformer Encoder 端头部加一个 Fertility 预测,用来预测每个源端 Token 能翻译成一个目标端的 Token,然后根据预测的结果,将源端的 Token 拷贝到 Decoder 的输入,如果一个源端 Token 能够翻译两个目标 Token,那就拷贝两次,如果源端 Token 不会翻译成目标端 Token,那就不拷贝。由于每一步输出的译文是没有给到下一步的,所以是可以并行的。对于 Fertility 的训练是采用某种对齐模型,通过计算源端和目标端的对齐关系,然后就可以得到源端和目标端的对齐结果,就可以采用监督的方式来训练 Fertility 分支。
该方法有一个问题,就是在翻译当前步的时候没有考虑上一步的翻译信息。这样就可能导致翻译结果的流畅度不够好。我们的方法就是在该方法的基础上添加了序列上的信息。这样模型既能并行执行,又能考虑的到前后的序列关系。

我们的工作分为两个方面,一个是在训练上添加序列信息,一个是在模型上面同样也添加序列信息。序列训练采用的是 Reinforce 的方法,Reinforce 的方法非常难以训练,这是因为其方差非常大,方差大的原因是强化学习 episode(一条轨迹从开始到结束)的搜索空间非常大,我们每次只是采样出一个 episode,然后根据这个 episode 进行计算,通过大数定律,我们可以假设这最终得到的是一个梯度的无偏估计。但是在实际情况下,抖动是非常大的。
将 Reinforce 算法应用到我们这个场景,首先看第一个公式,由于目标端词的概率是独立的,所以就可以写成连乘的形式,第二个公式就是传统的 Reinforce 公式,就是翻译的 reward。是通过前向后向算法计算出来的当前步的 reward。

上面的 slides 介绍的是计算 reward 时候的不同,接下来看 sampling 机制的区别。根据生成前后词的独立性,每一步我们并不是采样出一个词,而是采样出 K+1 个词。这样的话就可以看做我们一次更新的过程中考虑到更多的 episode,而不是仅用一个 episode 就去训练了。具体的做法是,每一步,我们先取 Top-K,计算一下损失函数的值,然后从剩下的 Token 中再采样出来一个。我们将这两部分的 loss 合起来,是为了保证无偏估计。为前 k 个翻译的概率的和。
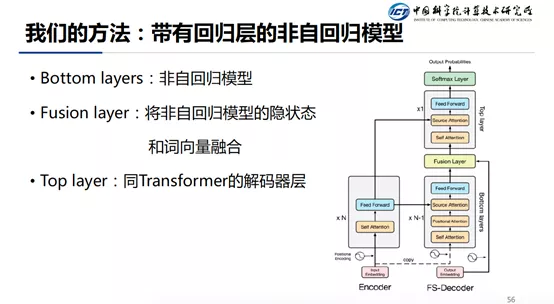
另外一个方法就是模型上的改进,在非自回归层的上面加上自回归层。具体的做法是,模型分为 Bottom Layer,Fusion Layer,Top Layer。Bottom Layer 就是之前介绍的非自回归模型,Fusion Layer 的作用是将非自回归模型的输出和其 Embedding 整合起来,Top-Layer 和 Transformer 的解码器基本一致。
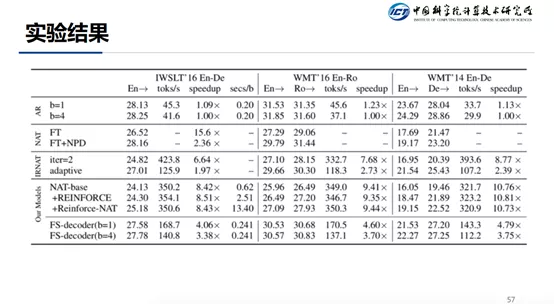
实验结果:AR(Transformer),NAT(非自回归的方法),IRNAT(迭代的非自回归方法),最后是我们提出的方法,第一种是在训练的过程中引入序列信息,第二是在模型上进行改进。作为对比的数据集有三个,前两个数据集比较小。主要关注第三个数据集。可以看出,使用 NAT 来代替 AR 模型的话,效果会降 6 个点左右,迭代的方法会带来 1 到 2 个点的提升。我们提出的 reinforce 方法和传统的 reinforce 方法相比,有 0.6 个点的提升。加上回归层的模型已经接近 Transformer 的效果了。关于速度的提升,如果仅训练的时候采用序列信息,速度可以提升 10 倍。如果是 NAT 加上自回归层的方法,速度也可以提高 4 倍左右。

这里有一些翻译实例,可以看出 NAT-base 的方法流畅性不够好,重复很多“more more …”,因为没有考虑序列信息,所以导致结果的流畅度不行。使用我们提出的 reinforce 方法,能够一定程度上的缓解流畅度的问题,但是问题还是存在。通过使用 NAT+AR 的方法,能够更好的缓解流畅度的问题。
研究组主页:
个人主页:
http://nlp.ict.ac.cn/~fengyang/
今天的分享就到这里,谢谢大家。
本文来自 DataFunTalk
原文链接:

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论