

Glue 连接的作用:AWS Glue 中的爬网程序和作业使用连接来访问某些类型的数据存储。
何时使用连接?
如果数据存储需要一个连接,则在网络爬取数据存储以在 AWS Glue 数据目录 中对其元数据进行编目时,将使用该连接。任何使用数据存储作为源或目标的作业也将使用该连接。
AWS Glue 可以使用 JDBC 协议连接到以下数据存储:
Amazon Redshift
Amazon Relational Database Service
Amazon Aurora
MariaDB
Microsoft SQL Server
MySQL
Oracle
PostgreSQL
可公开访问的数据库
Amazon Aurora
MariaDB
Microsoft SQL Server
MySQL
Oracle
PostgreSQL
Demo1 – Glue 如何与 Redshift 连接,将 ETL 后的数据直接写入到 Redshift 里,并自己定义 Distribute Key 和 SortKey
准备条件一 : 创建 Glue 连接 Redshift 的 VPC 安全组 – Glue 在连接 VPC 内的服务时,是通过创建一个新的 ENI,并使用私网地址连接,所以需要有能够访问 VPC 服务的 Security Group
1.进入 VPC 或 EC2 控制页面,选择安全组,点击创建安全组

2.输入安全组名称,描述,选择默认 VPC,这里先不添加规则,直接创建
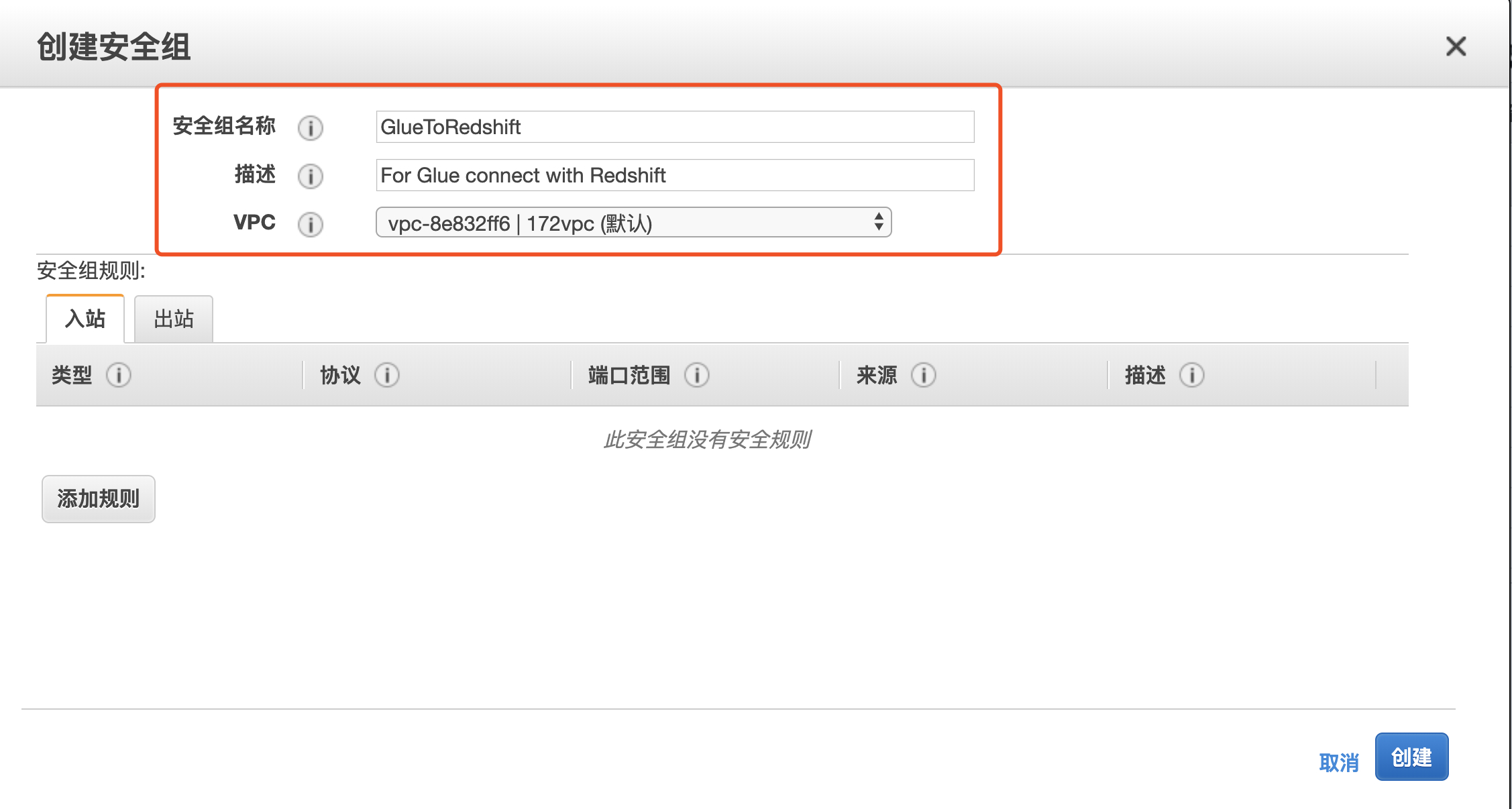
3.安全组创建好之后,选中该安全组,复制安全组 的 ID,点击编辑

4.端口范围选择所有 TCP 端口,来源把安全组 ID 粘贴上,这样写的意思是只要有相同 Security Group 的 AWS 资源就可以访问 5439 端,点击保存

注意:如果不选择所有端口,在测试连接的时候会报如下错误

准备条件二: 创建 VPC 的 S3 Endpoint – Glue 在创建连接的时候,需要有访问 S3 的 IAM 权限和网络条件,详情参看。
1.进入到 VPC 控制页面,选择终端节点,点击创建终端节点

2.选择 s3 endpoint 服务,选择默认 VPC。

3.请注意警告部分,出于安全目的,通常建议使用私有子网+S3 Endpoint 来打通 VPC 和 S3 或其他托管服务,如果您正在使用公有子网连接 S3 或其他托管服务,请注意对自己程序的影响
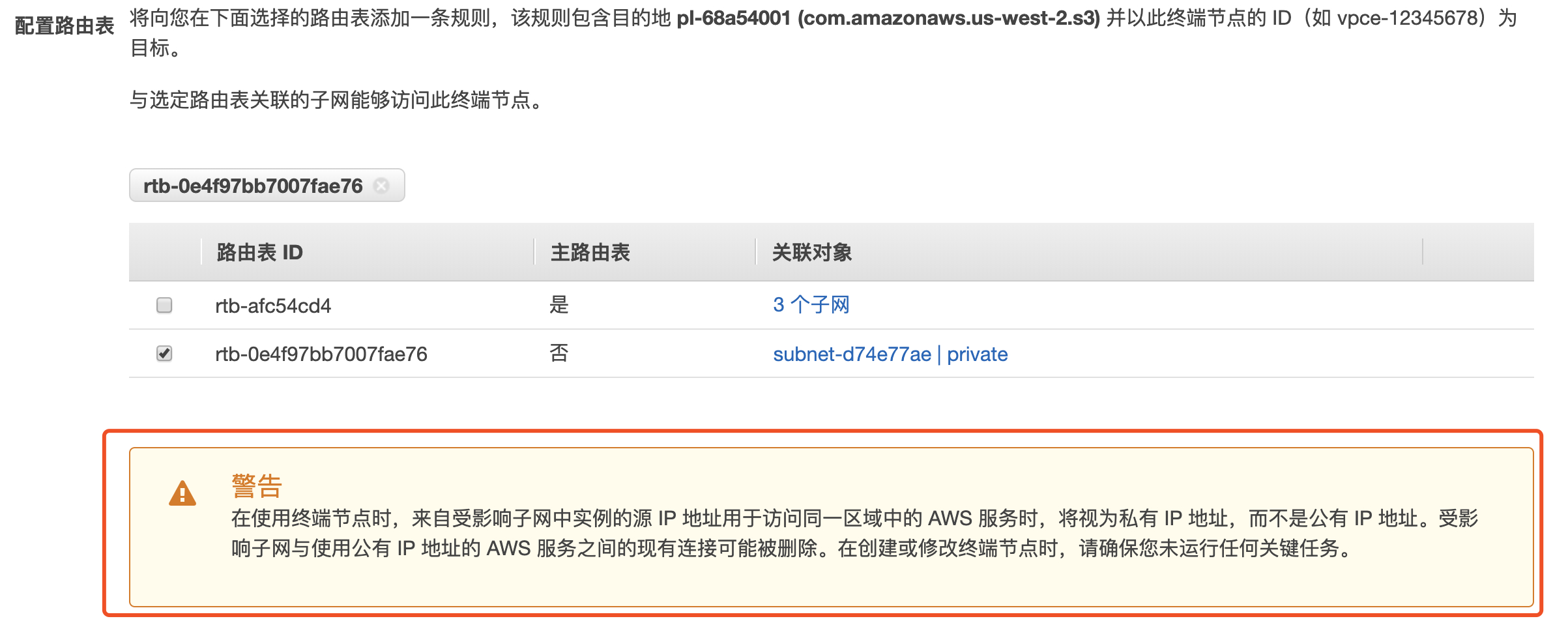
4.点击创建终端节点
准备条件三: 准备一份 sample 数据
在 sample 数据生成中,添加一行日期

3.点击 Download Data,并上传到 s3,这里我们上传到创建好的 s3://myglue-sample-data/rawdata/gluetoredshift/ 下

准备条件四: 创建测试用的 Redshift
1.进入 Redshift 控制页面,点击启动集群

2.输入集群标识,数据库名称,用户名密码,端口默认 5439,点击继续

3.由于是测试所以我们选择最小机型和单节点,在生产环境中则需要选择多节点,点击继续

4.依次选择,默认 VPC,子网(选择设置好的私有子网),选择之前创建好的安全组,IAM 角色暂时不选,在生产环境中需要设置相应的 IAM 策略,具体参考。
点击继续

5.检查一下参数没问题后,点击启动集群
6.集群创建好之后,确认集群是可用状态,数据库也运行正常

准备条件五: 创建一个用于测试连接的 Role – 该 Role 必须有访问源数据 s3 的权限和 GlueServiceRole 的权限
1.进入 IAM 控制页面,点击创建角色
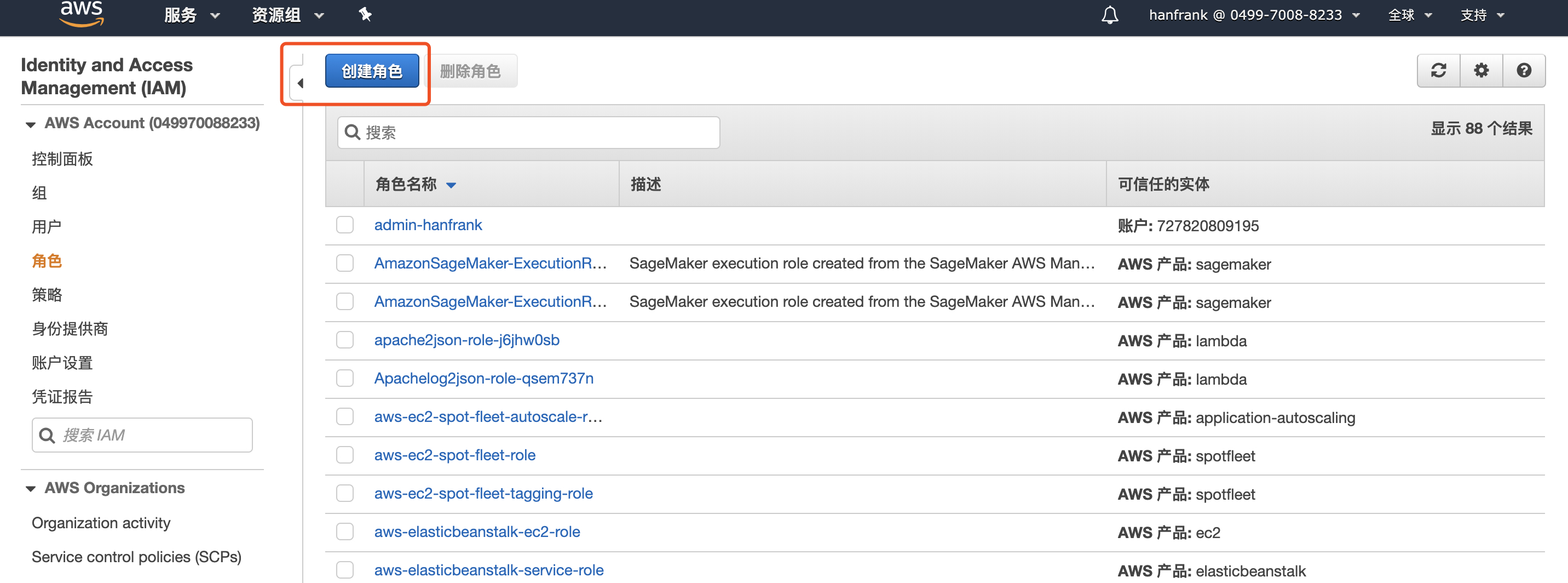
2.选择 Glue 作为使用此角色的服务,点击下一步权限

3.这里需要创建一个新的策略,点击创建策略
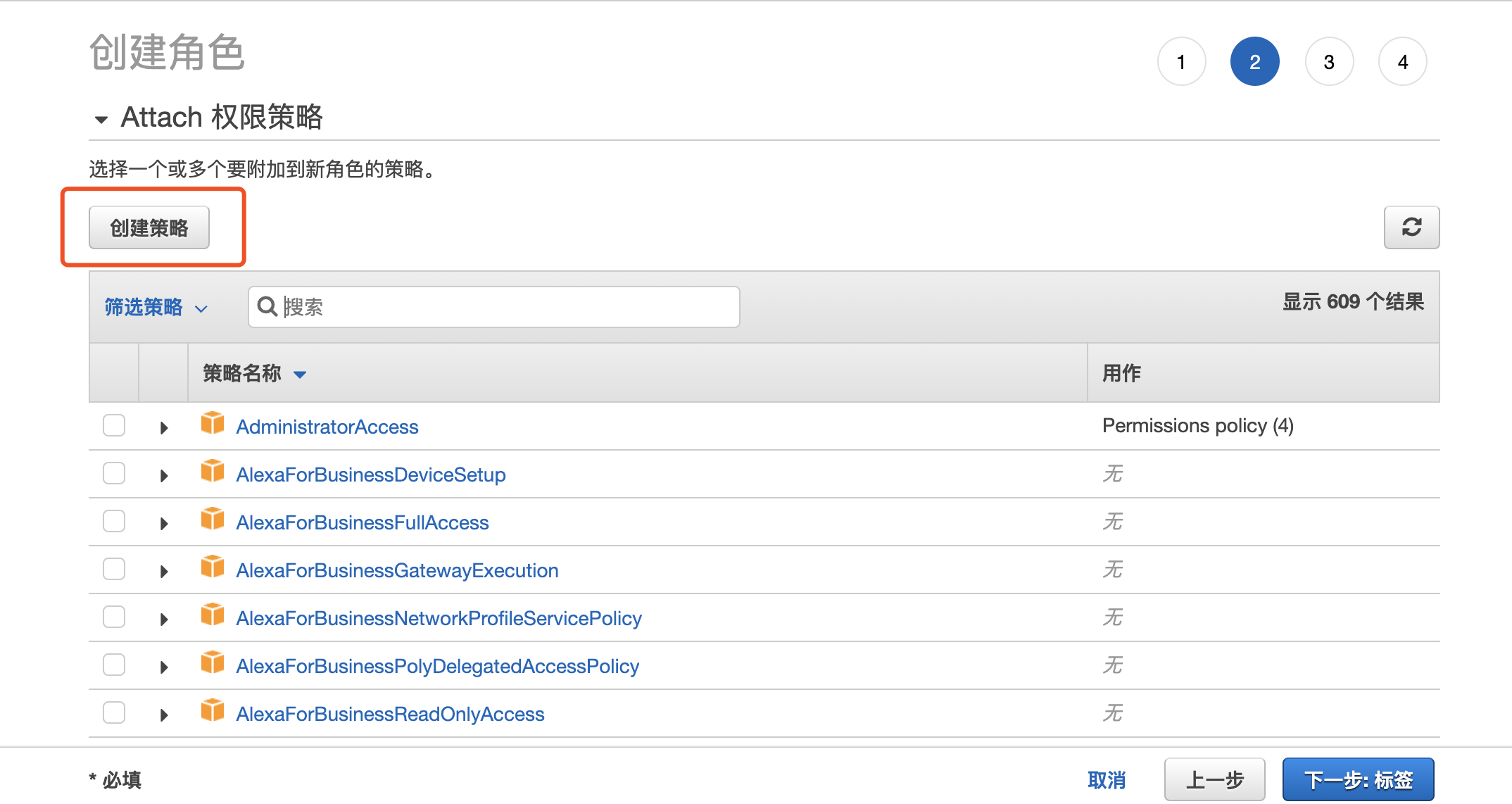
4.进入策略编辑页面,把以下 S3 的权限粘贴进去,这里的 S3 路径是源数据所在的路径,点击查看策略

5.输入策略的名字 AWSGlueServiceRole-gluetoredshift,点击创建策略
注意:这里策略的名字一定要加 AWSGlueServiceRole- 的前缀,否则在添加策略的时候无法识别

6.回到第 3 步的页面,选择两个 Role ,AWSGlueServiceRole 和刚才创建的 AWSGlueServiceRole-gluetoredshift,点击下一步标签

7.输入标签,点击下一步

8.输入角色名称 AWSGlueServiceRole-gluetoredshift,点击创建角色

以上条件都准备好之后,开始进入 Glue 连接的设置
1.进入 Glue 控制页面,点击添加连接

2.输入连接名字,连接类型选择 Amazon Redshift,点击下一步
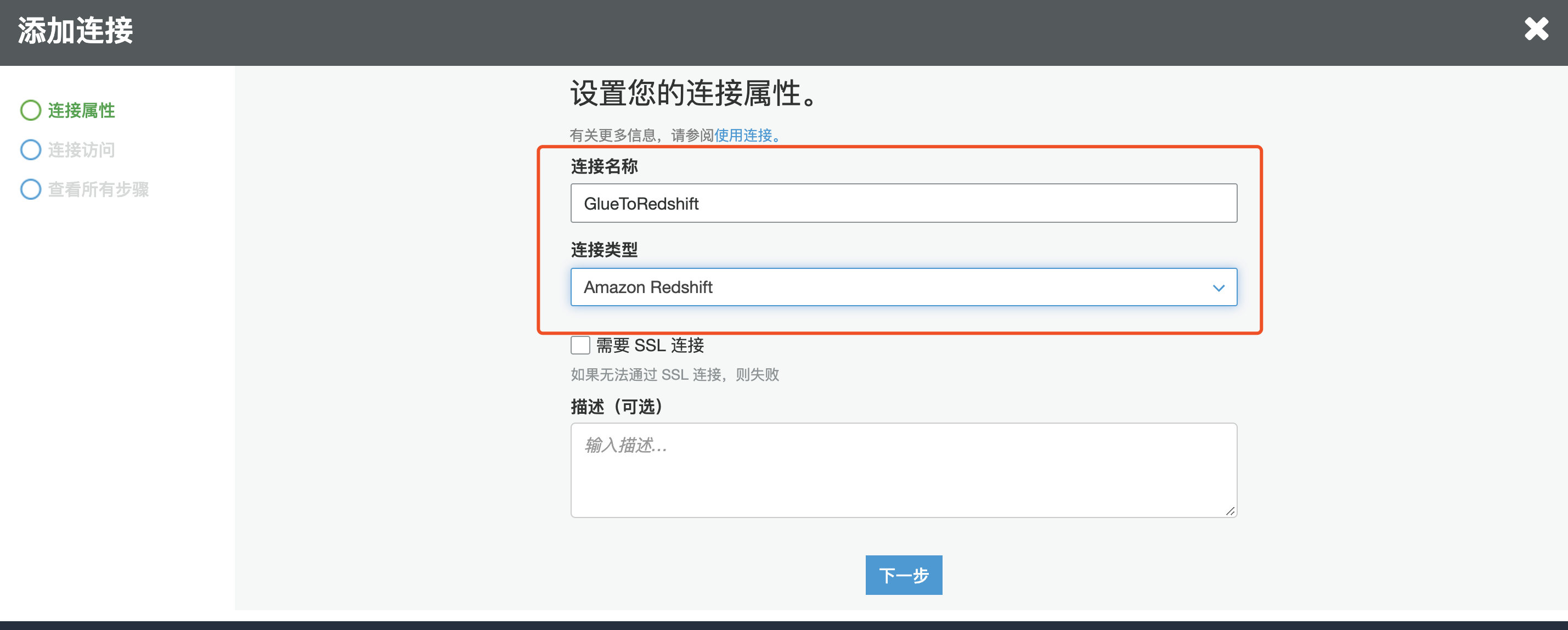
3.选择刚刚创建好的 Redshift 集群,输入创建好的 Database 名字,用户名,密码

4.可以看到系统会默认选择 Redshift 所在子网和安全组,点击完成
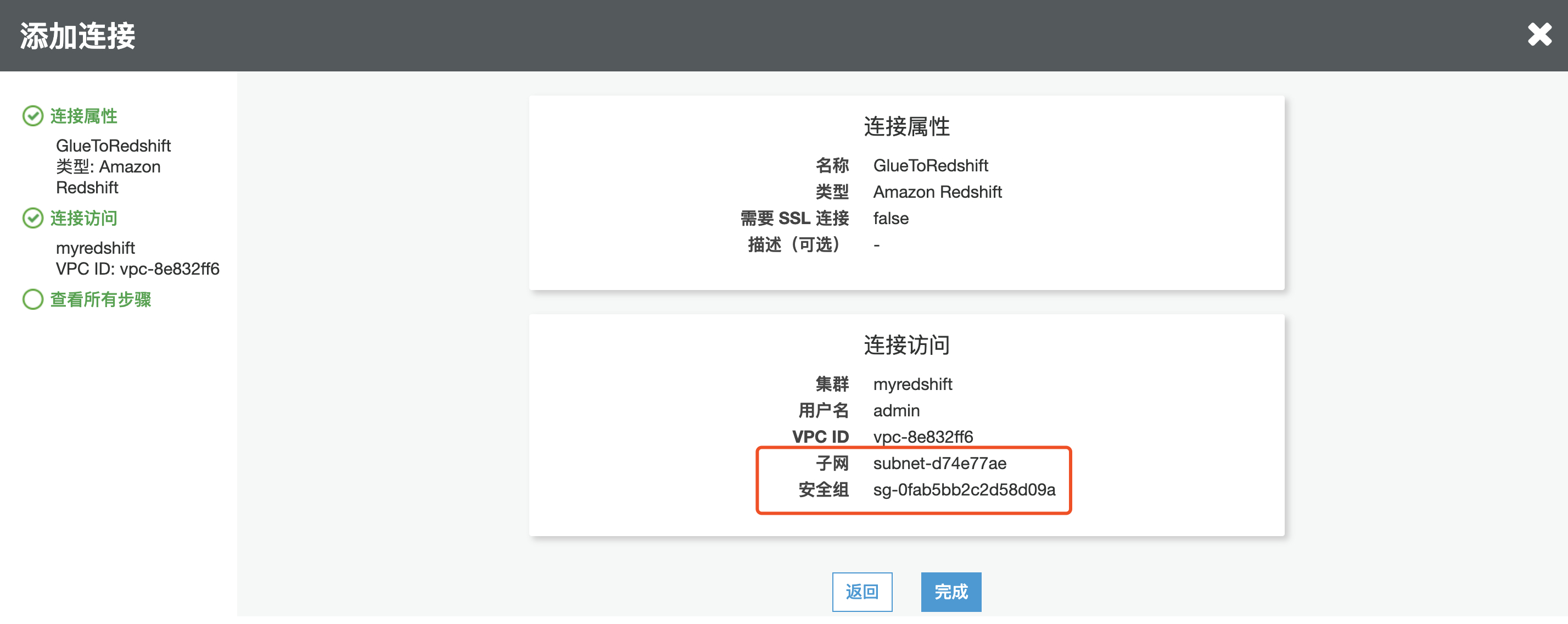
5.选中刚才创建的连接,点击测试连接
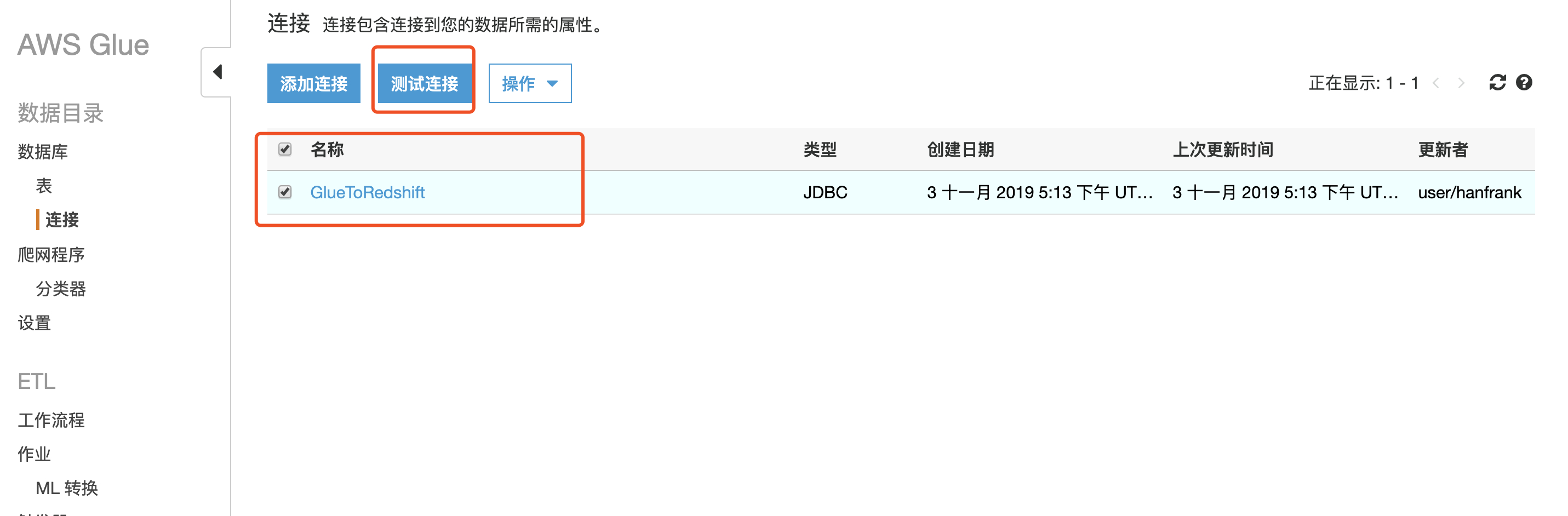
6.选择之前创建好的 Role,点击测试连接

7.连接成功

8.重复第一章的操作先爬取源数据的数据结构,并写入到 mymetastore 里,具体步骤省略,确认爬取后的数据表

9.创建写入到 Redshift 的 ETL 任务,进入到 Glue 控制页面,选择添加作业

10.输入作业名字,选择刚才创建的角色,其他默认,点击下一步

11.选择刚才爬取的数据源

12.选择更改架构,点击下一步
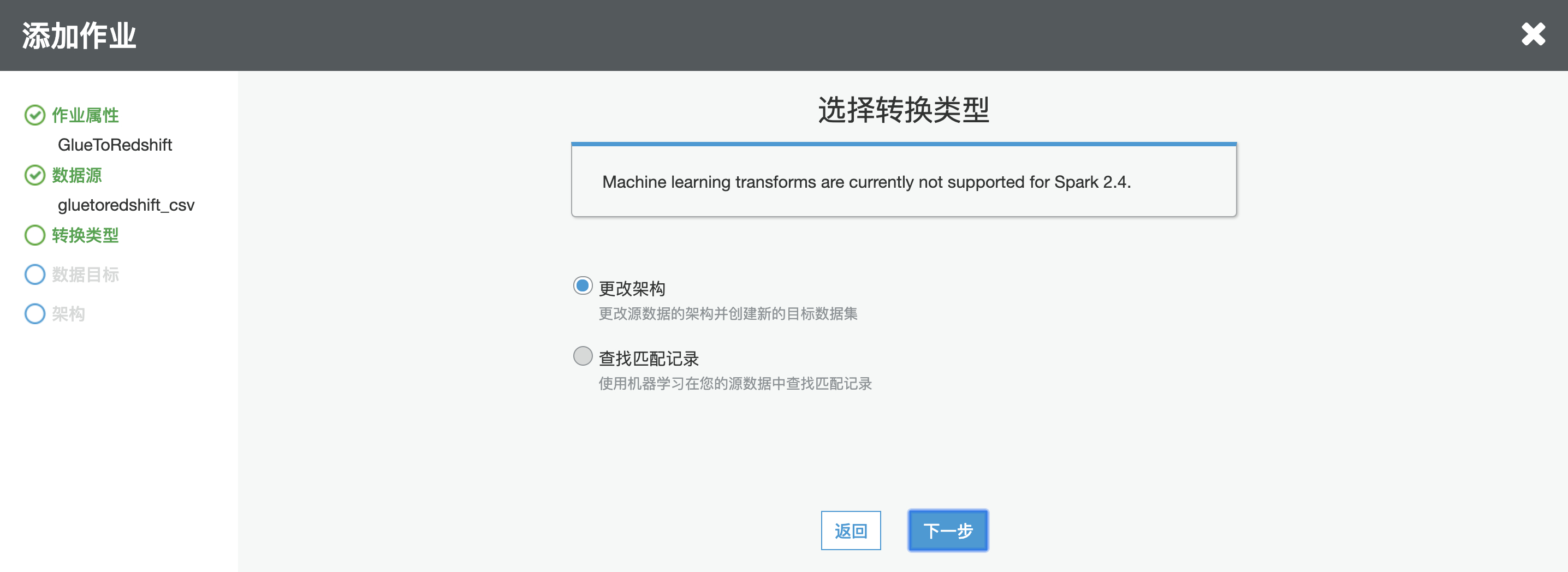
13.选择在数据目标中创建表,选择 JDBC,选择之前创建的 GlueToRedshift 连接,数据数据库的名字,点击下一步

14.对字段进行重命名和对 date 字段类型转换,点击保持作业并编辑脚本

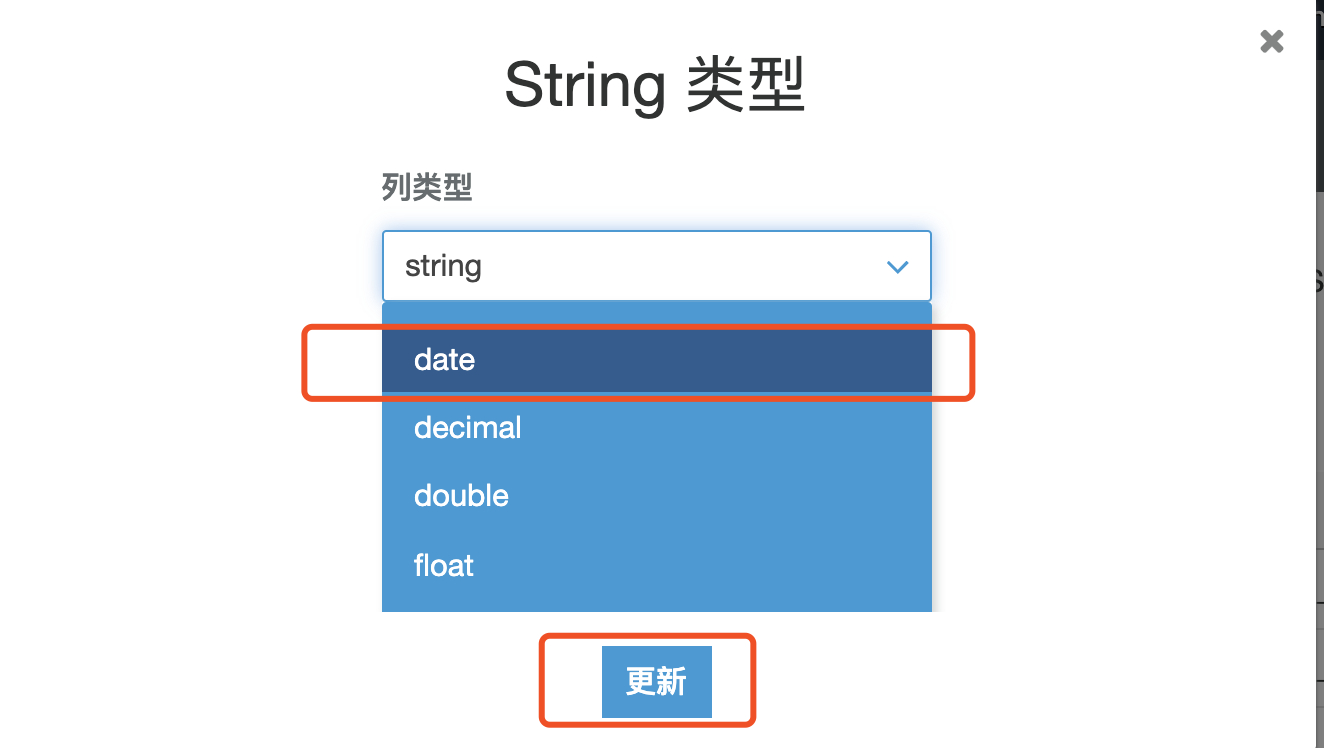
15.进入作业编辑界面,在写入 Redshift 的时候,指定 distkey 和 sortkey,详细参数。
修改如下代码
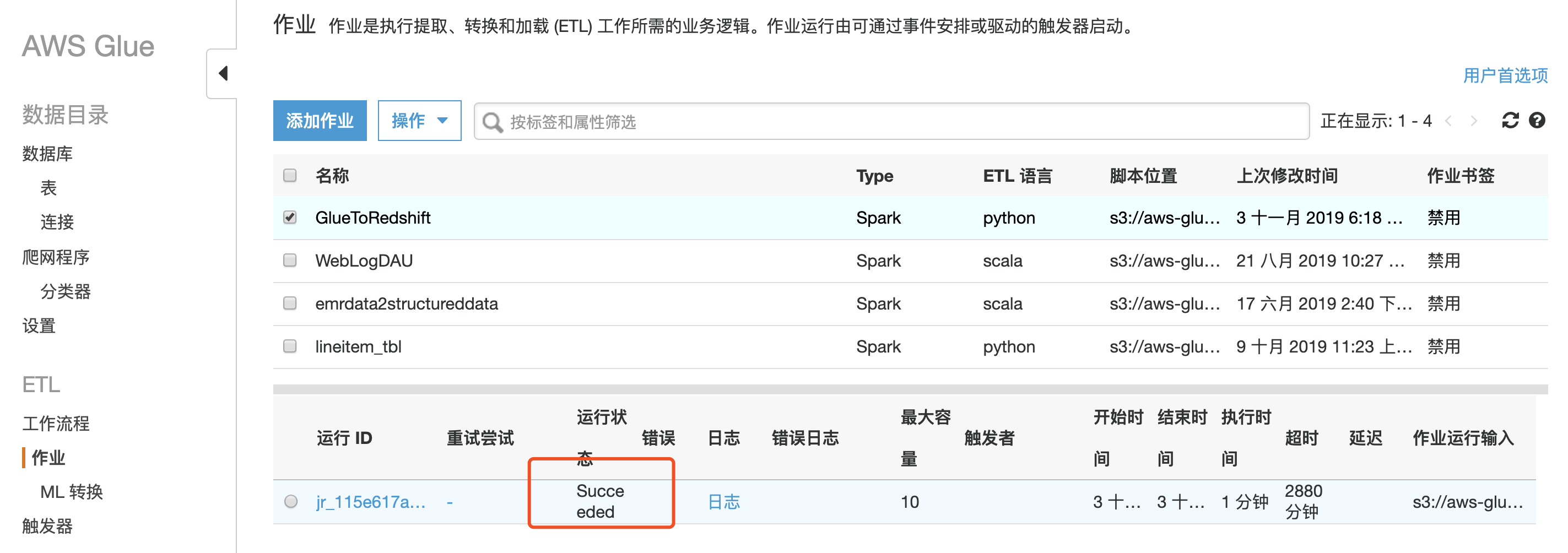
保存,并运行
16.确认任务执行成功后,到 Redshift 里查询表
17.点开 Query Editor 执行以下语句
查询新表字段情况

可以看到,已经按照指定参数,并写入了 Redshift
在下一篇文章中,我们继续展示爬虫使用连接的 Demo2。
作者介绍: 韩宇光,AWS 解决方案架构师,熟悉互联网的大数据业务场景,有丰富的基于 AWS 上大数据解决方案的经验,对开源 hadoop 组件有一定研究。在加入 AWS 之前,在猎豹移动任职大数据高级运维工程师,有 10 多年的运维经验,深入理解云架构设计,对云上的运维,Devops,大数据解决方案有丰富的实践经验。
本文转载自 AWS 技术博客。

Java 避坑指南:Java 高手笔记代码篇
本迷你书包括 86 个业务开发中常见踩坑点。每一个知识点都相当的实用,是程序员业务开发中的必备避坑指南...










评论