

2018 年 11 月 9 日下午 ,由七牛云主办的第 31 期架构师实践日——大数据技术实践与分享,在南京举行。有货架构师兼运维总监张春华为我们带来了题为《有货大数据系统的演进之路》的分享。
本文是对分享内容的整理。
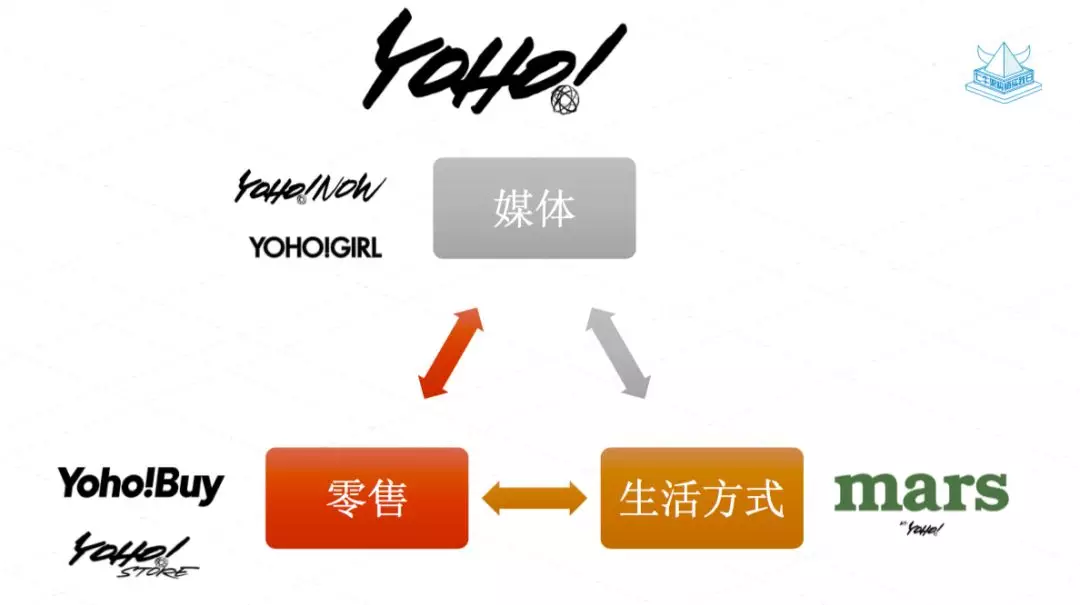
有些同学可能不是特别了解有货, 我先为大家介绍一下有货。有货总部位于南京。我们公司主要有三块业务,一块是媒体,包括线上 APP YOHO!NOW 和潮流杂志 YOHO!BOYS & YOHO!GIRL ; 另一块是零售,包括电商 APP YOHO!BUY 和线下店 YOHO!STORE,最后一块就是分享潮流生活方式的 mars。
我担任有货的架构师,同时也负责运维,加入有货之前我是华为的工程师。
有货是七牛很早的早期存储用户。早在 2014 年的时候,我们就是七牛云存储的一个用户,我们全网所有的图片、小文件、视频都存在七牛云上。到 2015 年、2016 年,我们开始变成七牛 CDN 的用户。

我先分享一下有货从 2013 年到 2015 年大数据的一个基本架构,这个是最原始大数据的一个系统。关于基础设施,我们在北京有自己租用的 IDC,在这个 IDC 的机器上我们部署了基于 Hadoop 的系统,主要提供 hive 的计算。我们做一些简单的业务报表,提供给老板看一些日活月活,包括店铺的销售数据、商品的销售数据等等,是一个很简单的系统。
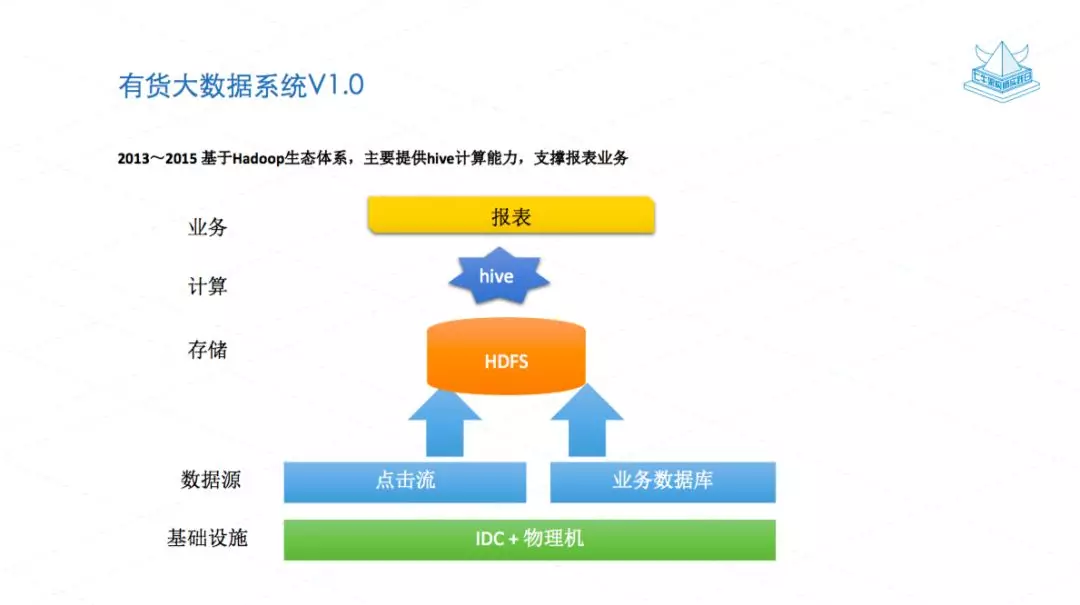
这个系统主要的问题有两点:

一是存储能力不足,因为你需要自己去买磁阵,而且这个费用是非常高的,而且容易坏掉。另外存储分为冷热存储,自己在 IDC 很难做这个冷热分离。
二是计算能力不足,因为 hive,大家都知道它很难去支撑一些实时或者近实时的业务。我相信大部分公司,第一个大数据平台都是类似这样的,基于 hive 的一个简单的东西。
在 2015 年的时候,我们也做了一个最大的变化,就是从 IDC 迁移到公有云上,迁移到公有云上以后,我们的大数据也一并迁移到公有云上。原来的物理计算机变成了云的虚拟机,在这个虚拟机上我们也搭建了自己的 Hadoop 集群。同时为了支撑一些实时或者近实时的业务,我们也搭建了 Spark 的集群。
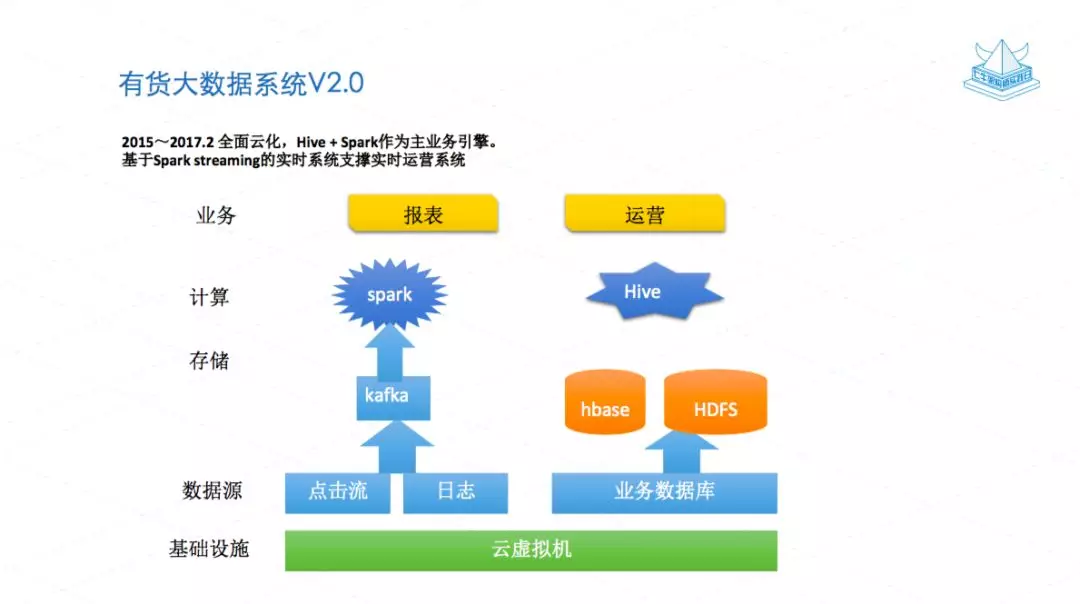
有了这个 Sprak 之后我们就能支撑一些实时的业务,比如说老板看一个小时内哪个商品卖得好或者哪个商品点击率高等等,它可以支持实时的查询。从 2015 年到 2017 年,这个系统运行了将近一年多到两年的时间。
这个系统也有一些问题,第一个问题就是计算和存储是耦合的,因为我们是公有云虚拟机搭建的一个 Hadoop 集群,计算能力不足时,你需要加节点,存储也顺带必须要加上,可能存储是够的,加的存储就是浪费。这是一个问题。同时自己搭建集群维护成本很高。

另一方面,Spark 在毫秒级延迟下的 Streaming 计算能力是不足的。基于 hive 的数据仓库也是比较慢的,一般快的需要二三十秒,慢的可能要几百秒。
现在的架构大概是这个样子,最下面是系统的数据源,还有来自外部广告投放的一些点击数据。我们现在存储都是用的云的对象存储,简称 OSS。计算包括流计算、OLAP 和批处理计算。流处理我们使用 Spark streaming + Flink 的架构;OLAP 主要使用了 Druid 和 Spark ;数据仓库方面,我们在 hive 的基础上添加 GreenPlum 来支撑一些更快的查询。
为什么引入 Greenplum 呢?因为这个数据库是 MPP 界开源里面一个比较好的选择。能够支持 PB 级的数据,而且在性能上、可靠性上经过了很多商业案例的检验。我们国内银行、证券等金融行业客户用这个用得比较多。我们做的一些 CRM 人群画像使用宽表存储在 Greenplum 中,业务系统取这些数据的时候就会非常快,如果用 hive 取这些数据就会很慢。
有了这套系统,我们可以支撑报表、运营、CRM、风控、推荐等等业务。
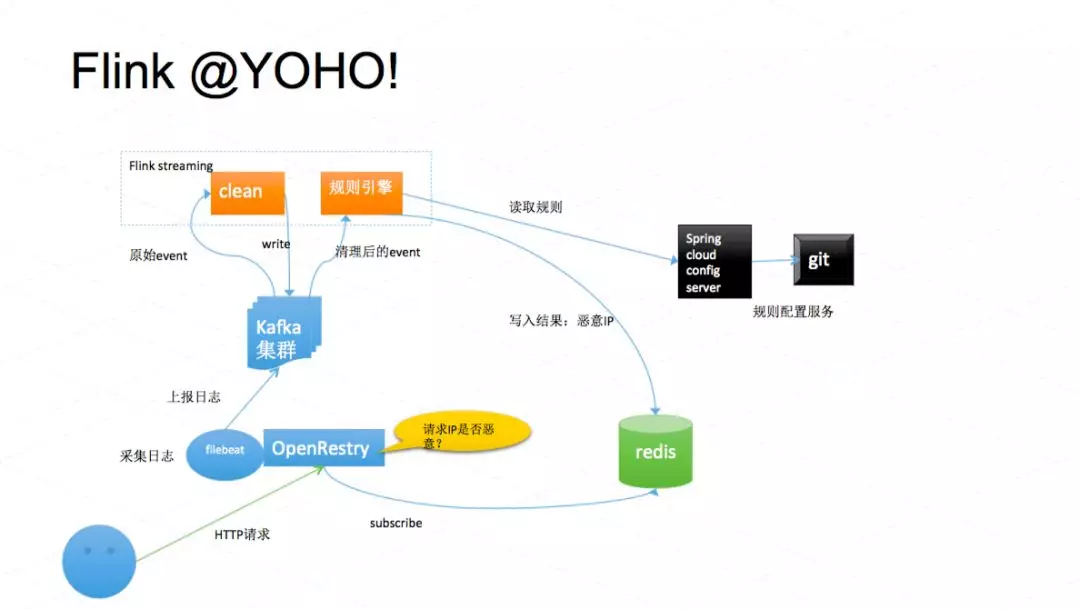
我们重点看一下 Flink 在我们这边的一些应用。以恶意请求检测的场景来介绍,我们电商系统或者其他系统应该都会遇到一些恶意的攻击,比如说羊毛党、撞库等等。系统入口的请求日志通过 Filebeat 收集到管道-即 Kafka 集群中,一个 Flink Straming 任务是对原始日志做清理。清理完之后再把结构化的数据写到 Kafka 集群里面。然后再有另外一个任务读取这些清理过的事件,然后根据规则判断请求是否恶意。 我们通过 spring cloud config server 来提供规则配置服务。如果 IP 是恶意的,就会写入到 Redis 中,Openresty 会 subscribe 到恶意 IP,并且实时拦截请求。
这是一个简单的恶意 IP 识别的系统。这个识别是基于规则。我们也尝试过去做一些所谓的人工智能基于有标签的历史数据集就行训练。经过我们实践之后,发现基于特征和基于规则的结果都是差不多的,所以我们没有上线基于机器学习的恶意检测系统。
这个系统,我们现在能够支撑到 5 万每秒的请求,所以如果你用 Spark Streaming 这个来做,同样的延迟和吞吐量,可能会需要更大的 yarn 集群资源。
接着介绍一下 OLAP。我们做过 POC 后最终选了 Druid 来做 OLAP。
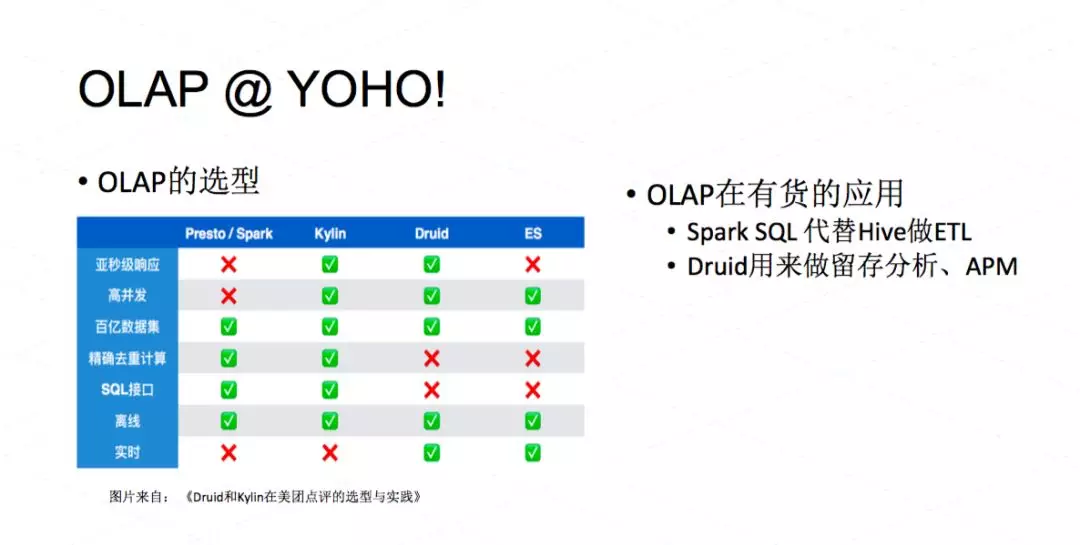
Druid 可以直接对接 Kafka 流数据,可以很方便地做一些数仓的切片、切块等等,可以支持汇聚,能够支持快速的 count-distinct。count-distinct 电商系统里面是非常常见的,你要计算 PV、UV 等等。我们用 Druid 主要做留存分析,包括热门店铺、热门商品、热门品类等等。运营系统里面很多数据、很多计算都是来自于 Druid。我们有一个简单的 APM 系统,我们也用 Druid 来分析 APP 上报的数据,能知道哪个地区可能网络质量不是很好,哪个版本可能崩溃率比较高等等。
下面是 Druid 的一个架构图,简单介绍一下,Druid 可主要包括历史节点、实时节点,Broker 节点和协调节点,它们各司其职。
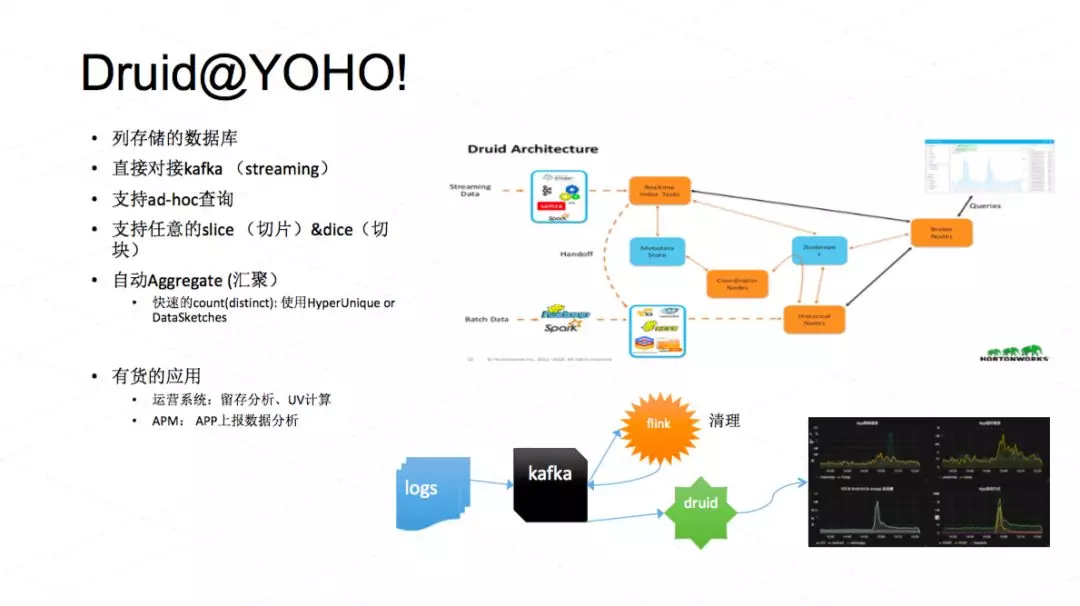
Druid 的历史数据存储有很多选择,例如 Hadoop HDFS、OSS 等。大家知道 Druid 只存储汇聚后的数据,原始数据我们是存储在 Greenplum 中。
接下来分享一下我们在构建大数据一路演进下来的一些经验或者一些教训。
第一个是存储空间的优化,我们最初在公有云上用 EMR 的时候,我们的存储空间是非常非常大的,用了一个月之后我们发现这个存储账单爆掉了,光存储就是十几万的账单。为什么?我们发现我们犯了一个低级错误,没有清理一些 Trash 目录,这个释放掉之后空间就会省出很多。第二个是存储格式,一开始没有做压缩,存储空间就很大。后面我们切换了 orc+snappy 的方式,存储空间就很小。
下图展示了各种存储方式空间大小。切换存储方式应用也要有一些变化,所以这个工作最好在一开始就做好。

第二个是对象存储文件的一个前缀优化,如果大家做过 HDFS 应该都知道,这个会造成所谓的热点。要怎么做呢?可能说你把这个前缀做一些 random 的东西,例如对路径做 HASH,这样的话,这些文件就会分布到不同的节点上。但是做了这个之后也会变得很麻烦。 Hadoop 集群在 IDC 中,你会感受不到热点的问题。当你的数据量变得很大的时候,并且你的数据都是通过网络从 OSS 中获取的,你会发现这个问题很严重。我们当时几乎每天都会出现热点问题,会报超时,但是没有太好的办法,就需要做前缀的这些优化。

当然,各个公有云厂商也在不断对 OSS 产品做改进。我相信其他的公有云厂商,比如说阿里云、华为云或者七牛云,他们都在做优化,我相信再过一年两年这个优化就会成为历史,可能不需要自己做,OSS 厂商就会帮你做。
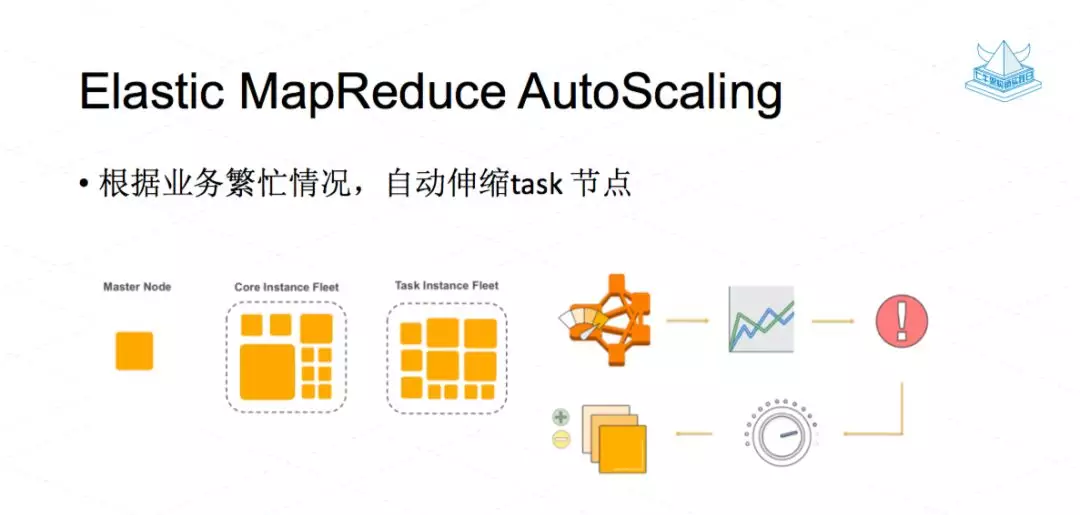
第二个就是 AutoScaling,这个是非常重要。 公有云 EMR 中 task 节点是无状态的,可以方便的伸缩。我们现在每天凌晨扩展一些 task 节点支持大批量的 ETL 计算。计算结束之后,到第二天早上大概到 9 点时,我们会把这些 task 节点全部都缩掉。这个能降低成本,这也是使用公有云的一个好处。
这就是我今天分享的主要内容 :有货大数据系统从基本的 Hadoop 集群进化到现在一个包括 Streaming、OLAP、Batch 的基于公有云的数据平台,也有从 IDC 迁移到公有云的经验。 谢谢大家。
作者介绍:
张春华,有货架构师兼运维总监,负责有货电商中台系统、大数据系统的架构设计。对微服务框架、电商大数据系统、运维系统等有一定的认识和丰富的实践。
本文转载自公众号七牛云(ID:qiniutek)。
原文链接:
https://mp.weixin.qq.com/s/wxEbekoBFN0Nw_J-wZSJdw

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论