

01
什么是 TensorFlow
TensorFlow 是 Google brain 推出的开源机器学习库,与 Caffe 一样,主要用作深度学习相关的任务。
与 Caffe 相比 TensorFlow 的安装简单很多,一条 pip 命令就可以解决,新手也不会误入各种坑。
TensorFlow = Tensor + Flow
Tensor 就是张量,代表 N 维数组,与 Caffe 中的 blob 是类似的;Flow 即流,代表基于数据流图的计算。神经网络的运算过程,就是数据从一层流动到下一层,在 Caffe 的每一个中间 layer 参数中,都有 bottom 和 top,这就是一个分析和处理的过程。TensorFlow 更直接强调了这个过程。
TensorFlow 最大的特点是计算图,即先定义好图,然后进行运算,所以所有的 TensorFlow 代码,都包含两部分:
(1)创建计算图,表示计算的数据流。它做了什么呢?实际上就是定义好了一些操作,你可以将它看做是 Caffe 中的 prototxt 的定义过程。
(2)运行会话,执行图中的运算,可以看作是 Caffe 中的训练过程。只是 TensorFlow 的会话比 Caffe 灵活很多,由于是 Python 接口,取中间结果分析,Debug 等方便很多。
02
TensorFlow 训练
咱们这是实战速成,没有这么多时间去把所有事情细节都说清楚,而是抓住主要脉络。有了 TensorFlow 这个工具后,我们接下来的任务就是开始训练模型。训练模型,包括数据准备、模型定义、结果保存与分析。
2.1 数据准备
上一节我们说过 Caffe 中的数据准备,只需要准备一个 list 文件,其中每一行存储 image、labelid 就可以了,那是 Caffe 默认的分类网络的 imagedata 层的输入格式。如果想定义自己的输入格式,可以去新建自定义的 Data Layer,而 Caffe 官方的 data layer 和 imagedata layer 都非常稳定,几乎没有变过,这是我更欣赏 Caffe 的一个原因。因为输入数据,简单即可。相比之下,TensorFlow 中的数据输入接口就要复杂很多,更新也非常快,我知乎有一篇文章,说过从《从 Caffe 到 TensorFlow 1,IO 操作》,有兴趣的读者可以了解一下。
这里我们不再说 TensorFlow 中有多少种数据 IO 方法,先确定好我们的数据格式,那就是跟 Caffe 一样,准备好一个 list,它的格式一样是 image、labelid,然后再看如何将数据读入 TensorFlow 进行训练。
我们定义一个类,叫 imagedata,模仿 Caffe 中的使用方式。代码如下,源代码可移步 Git。
import tensorflow as tf
from tensorflow.contrib.data import Dataset
from tensorflow.python.framework import dtypes
from tensorflow.python.framework.ops import convert_to_tensor
import numpy as np
class ImageData:
def read_txt_file(self):
self.img_paths = []
self.labels = []
for line in open(self.txt_file, ‘r’):
items = line.split(’ ')
self.img_paths.append(items[0])
self.labels.append(int(items[1]))
def init(self, txt_file, batch_size, num_classes,
image_size,buffer_scale=100):
self.image_size = image_size
self.batch_size = batch_size
self.txt_file = txt_file ##txt list file,stored as: imagename id
self.num_classes = num_classes
buffer_size = batch_size * buffer_scale
# 读取图片
self.read_txt_file()
self.dataset_size = len(self.labels)
print “num of train datas=”,self.dataset_size
# 转换成 Tensor
self.img_paths = convert_to_tensor(self.img_paths, dtype=dtypes.string)
self.labels = convert_to_tensor(self.labels, dtype=dtypes.int32)
# 创建数据集
data = Dataset.from_tensor_slicesself.img_paths, self.labels
print “data type=”,type(data)
data = data.map(self.parse_function)
data = data.repeat(1000)
data = data.shuffle(buffer_size=buffer_size)
# 设置 self data Batch
self.data = data.batch(batch_size)
print “self.data type=”,type(self.data)
def augment_dataset(self,image,size):
distorted_image = tf.image.random_brightness(image,
max_delta=63)
distorted_image = tf.image.random_contrast(distorted_image,
lower=0.2, upper=1.8)
# Subtract off the mean and divide by the variance of the pixels.
float_image = tf.image.per_image_standardization(distorted_image)
return float_image
def parse_function(self, filename, label):
label_ = tf.one_hot(label, self.num_classes)
img = tf.read_file(filename)
img = tf.image.decode_jpeg(img, channels=3)
img = tf.image.convert_image_dtype(img, dtype = tf.float32)
img = tf.random_crop(img,[self.image_size[0],self.image_size[1],3])
img = tf.image.random_flip_left_right(img)
img = self.augment_dataset(img,self.image_size)
return img, label_
下面来分析上面的代码,类是 ImageData,它包含几个函数,__init__构造函数,read_txt_file 数据读取函数,parse_function 数据预处理函数,augment_dataset 数据增强函数。
我们直接看构造函数吧,分为几个步骤:
(1)读取变量,文本 list 文件 txt_file,批处理大小 batch_size,类别数 num_classes,要处理成的图片大小 image_size,一个内存变量 buffer_scale=100。
(2)在获取完这些值之后,就到了 read_txt_file 函数。代码很简单,就是利用 self.img_paths 和 self.labels 存储输入 txt 中的文件列表和对应的 label,这一点和 Caffe 很像了。
(3)然后,就是分别将 img_paths 和 labels 转换为 Tensor,函数是 convert_to_tensor,这是 Tensor 内部的数据结构。
(4)创建 dataset,Dataset.from_tensor_slices,这一步,是为了将 img 和 label 合并到一个数据格式,此后我们将利用它的接口,来循环读取数据做训练。当然,创建好 dataset 之后,我们需要给它赋值才能真正的有数据。data.map 就是数据的预处理,包括读取图片、转换格式、随机旋转等操作,可以在这里做。
data = data.repeat(1000) 是将数据复制 1000 份,这可以满足我们训练 1000 个 epochs。data = data.shuffle(buffer_size=buffer_size)就是数据 shuffle 了,buffer_size 就是在做 shuffle 操作时的控制变量,内存越大,就可以用越大的值。
(5)给 selft.data 赋值,我们每次训练的时候,是取一个 batchsize 的数据,所以 self.data = data.batch(batch_size),就是从上面创建的 dataset 中,一次取一个 batch 的数据。
到此,数据接口就定义完毕了,接下来在训练代码中看如何使用迭代器进行数据读取就可以了。
关于更多 TensorFlow 的数据读取方法,请移步知乎专栏和公众号。
2.2 模型定义
创建数据接口后,我们开始定义一个网络。

上面就是我们定义的网络,是一个简单的 3 层卷积。在 tf.layers 下,有各种网络层,这里就用到了 tf.layers.conv2d,tf.layers.batch_normalization 和 tf.layers.dense,分别是卷积层,BN 层和全连接层。我们以一个卷积层为例:

x 即输入,name 是网络名字,filters 是卷积核数量,kernel_size 即卷积核大小,strides 是卷积 stride,activation 即激活函数,kernel_initializer 和 bias_initializer 分别是初始化方法。可见已经将激活函数整合进了卷积层,更全面的参数,请自查 API。其实网络的定义,还有其他接口,tf.nn、tf.layers、tf.contrib,各自重复,在我看来有些混乱。这里之所以用 tf.layers,就是因为参数丰富,适合从头训练一个模型。
2.3 模型训练
老规矩,我们直接上代码,其实很简单。
from dataset import *
from net import simpleconv3net
import sys
import os
import cv2
////-------1 定义一些全局变量-------////
txtfile = sys.argv[1]
batch_size = 64
num_classes = 2
image_size = (48,48)
learning_rate = 0.0001
debug=False
if name==“main”:
////-------2 载入网络结构,定义损失函数,创建计算图-------////
dataset = ImageData(txtfile,batch_size,num_classes,image_size)
iterator = dataset.data.make_one_shot_iterator()
dataset_size = dataset.dataset_size
batch_images,batch_labels = iterator.get_next()
Ylogits = simpleconv3net(batch_images)
print “Ylogits size=”,Ylogits.shape
Y = tf.nn.softmax(Ylogits)
cross_entropy = tf.nn.softmax_cross_entropy_with_logits(logits=Ylogits, labels=batch_labels)
cross_entropy = tf.reduce_mean(cross_entropy)
correct_prediction = tf.equal(tf.argmax(Y, 1), tf.argmax(batch_labels, 1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
update_ops = tf.get_collection(tf.GraphKeys.UPDATE_OPS)
with tf.control_dependencies(update_ops):
train_step = tf.train.AdamOptimizer(learning_rate).minimize(cross_entropy)
saver = tf.train.Saver()
in_steps = 100
checkpoint_dir = ‘checkpoints/’
if not os.path.exists(checkpoint_dir):
os.mkdir(checkpoint_dir)
log_dir = ‘logs/’
if not os.path.exists(log_dir):
os.mkdir(log_dir)
summary = tf.summary.FileWriter(logdir=log_dir)
loss_summary = tf.summary.scalar(“loss”, cross_entropy)
acc_summary = tf.summary.scalar(“acc”, accuracy)
image_summary = tf.summary.image(“image”, batch_images)
////-------3 执行会话,保存相关变量,还可以添加一些 debug 函数来查看中间结果-------////
with tf.Session() as sess:
init = tf.global_variables_initializer()
sess.run(init)
steps = 10000
for i in range(steps):
,cross_entropy,accuracy_,batch_images_,batch_labels_,loss_summary_,acc_summary_,image_summary_ = sess.run([train_step,cross_entropy,accuracy,batch_images,batch_labels,loss_summary,acc_summary,image_summary])
if i % in_steps == 0 :
print i,“iterations,loss=”,cross_entropy_,“acc=”,accuracy_
saver.save(sess, checkpoint_dir + ‘model.ckpt’, global_step=i)
summary.add_summary(loss_summary_, i)
summary.add_summary(acc_summary_, i)
summary.add_summary(image_summary_, i)
#print “predict=”,Ylogits," labels=",batch_labels
if debug:
imagedebug = batch_images_[0].copy()
imagedebug = np.squeeze(imagedebug)
print imagedebug,imagedebug.shape
print np.max(imagedebug)
imagelabel = batch_labels_[0].copy()
print np.squeeze(imagelabel)
imagedebug = cv2.cvtColor((imagedebug*255).astype(np.uint8),cv2.COLOR_RGB2BGR)
cv2.namedWindow(“debug image”,0)
cv2.imshow(“debug image”,imagedebug)
k = cv2.waitKey(0)
if k == ord(‘q’):
break
2.4 可视化
TensorFlow 很方便的一点,就是 Tensorboard 可视化。Tensorboard 的具体原理就不细说了,很简单,就是三步。
第一步,创建日志目录。
log_dir = ‘logs/’
if not os.path.exists(log_dir): os.mkdir(log_dir)
第二步,创建 summary 操作并分配标签,如我们要记录 loss、acc 和迭代中的图片,则创建了下面的变量:
loss_summary = tf.summary.scalar(“loss”, cross_entropy)acc_summary = tf.summary.scalar(“acc”, accuracy)image_summary = tf.summary.image(“image”, batch_images)
第三步,session 中记录结果,如下面代码:
,cross_entropy,accuracy_,batch_images_,batch_labels_,loss_summary_,acc_summary_,image_summary_ = sess.run([train_step,cross_entropy,accuracy,batch_images,batch_labels,loss_summary,acc_summary,image_summary])
查看训练过程和最终结果时使用:
tensorboard --logdir=logs
Loss 和 acc 的曲线图如下:
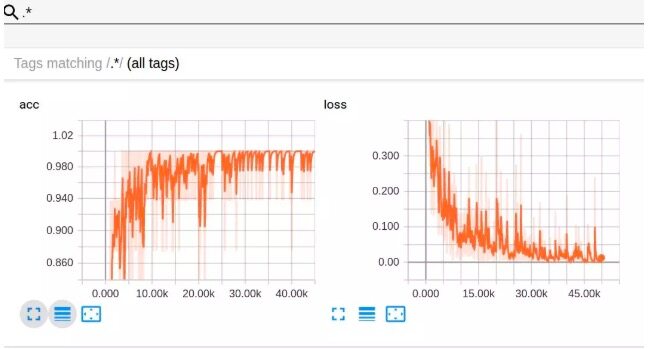
03
TensorFlow 测试
上面已经训练好了模型,我们接下来的目标,就是要用它来做 inference 了。同样给出代码。
import tensorflow as tf
from net import simpleconv3net
import sys
import numpy as np
import cv2
import os
testsize = 48
x = tf.placeholder(tf.float32, [1,testsize,testsize,3])
y = simpleconv3net(x)
y = tf.nn.softmax(y)
lines = open(sys.argv[2]).readlines()
count = 0
acc = 0
posacc = 0
negacc = 0
poscount = 0
negcount = 0
with tf.Session() as sess:
init = tf.global_variables_initializer()
sess.run(init)
saver = tf.train.Saver()
saver.restore(sess,sys.argv[1])
#test one by one, you can change it into batch inputs
for line in lines:
imagename,label = line.strip().split(’ ')
img = tf.read_file(imagename)
img = tf.image.decode_jpeg(img,channels = 3)
img = tf.image.convert_image_dtype(img,dtype = tf.float32)
img = tf.image.resize_images(img,(testsize,testsize),method=tf.image.ResizeMethod.NEAREST_NEIGHBOR)
img = tf.image.per_image_standardization(img)
imgnumpy = img.eval()
imgs = np.zeros([1,testsize,testsize,3],dtype=np.float32)
imgs[0:1,] = imgnumpy
result = sess.run(y, feed_dict={x:imgs})
result = np.squeeze(result)
if result[0] > result[1]:
predict = 0
else:
predict = 1
count = count + 1
if str(predict) == ‘0’:
negcount = negcount + 1
if str(label) == str(predict):
negacc = negacc + 1
acc = acc + 1
else:
poscount = poscount + 1
if str(label) == str(predict):
posacc = posacc + 1
acc = acc + 1
print result
print "acc = ",float(acc) / float(count)
print “poscount=”,poscount
print "posacc = ",float(posacc) / float(poscount)
print “negcount=”,negcount
print "negacc = ",float(negacc) / float(negcount)
从上面的代码可知,与 Train 时同样,需要定义模型,这个跟 Caffe 在测试时使用的 Deploy 是一样的。
然后,用 restore 函数从 saver 中载入参数,读取图像并准备好网络的格式,sess.run 就可以得到最终的结果了。
04
总结
本篇内容讲解了一个最简单的分类例子,相比大部分已封装好的 mnist 或 cifar 为例的代码来说更实用。我们自己准备了数据集,自己设计了网络并进行了结果可视化,学习了如何使用已经训练好的模型做预测。
作者介绍
言有三,真名龙鹏,曾先后就职于奇虎 360AI 研究院、陌陌深度学习实验室,6 年多计算机视觉从业经验,拥有丰富的传统图像算法和深度学习图像项目经验,拥有技术公众号《有三 AI》,著有书籍《深度学习之图像识别:核心技术与案例实战》。
##原文链接

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论