

本文由 dbaplus 社群授权转载。
本文根据 dbaplus 社群第 183 期线上分享整理而成。
面对互联网大数据如火如荼发展、云服务需求的急剧增加,对企业极其重要的数据要如何面对这些新的变革?
作为 Apache 基金会的分布式数据库中间件项目-ShardingSphere 将针对数据水平 &垂直拆分、分布式事务、数据服务治理、数据安全等需求提供一套适用于互联网应用架构、云服务架构的多解决方案生态圈。
本次分享将介绍 Apache ShardingSphere 核心功能、在京东的具体落地实战、产品生态圈发展等内容。
内容提纲:
Apache ShardingSphere 生态圈简介
Apache ShardingSphere 核心功能 &接入端
Apache ShardingSphere 京东落地实战
Apache ShardingSphere 迭代 &规划
一、Apache ShardingSphere 生态圈简介
Apache ShardingSphere 是一款开源的分布式数据库中间件组成的生态圈。自从 2016 年开源以来,不断升级开发新功能、重构稳定微内核,并于 2018 年 11 月进入 Apache 基金会孵化器。
它由京东集团主导,并由多家公司以及整个 ShardingSphere 社区共同运营参与贡献。其主要的功能模块为:数据分片(分库分表)、分布式事务、数据库治理三大块内容。
目前以在 gitHub 上收获 7000+关注度、70+公司落地的成功案例。
参考链接:
https://github.com/apache/incubator-shardingsphere
对新朋友而言,简介部分主要为大家呈现 Apache ShardingSphere 生态圈概览;对老朋友来说,它的迭代和发展是日新月异的,可以看到它最近的发展状态和前进方向。目前,整个 Apache ShardingSphere 生态圈架构如下图所示:
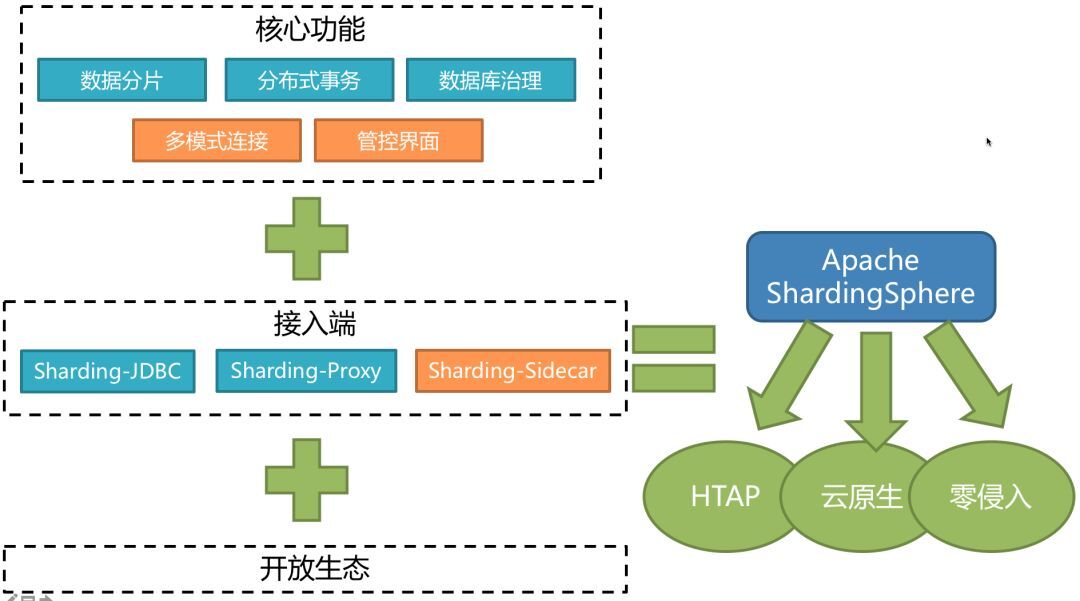
整体核心功能将组成一个闭环,它不仅为大家提供最为基础和核心的数据分片和分布式事务功能,同时针对以 ShardingSphere 为中心的整个分布式数据库系统,提供数据库治理的功能,例如配置信息动态统一管理、调用链与拓扑图、高可用管理、数据脱敏安全、权限控制等强大的管理功能。
此外,我们针对不同的数据库,例如 MySQL、Oracle、PostgreSQL、SQL Server 提供多模式连接的支持,真正屏蔽底层数据库选型的影响,做到无论使用何种数据库都可在用户无感知情况下进行数据分片、分布式事务、数据库治理的功能操作。
管控界面模块旨在为用户提供清晰可见的信息查看、配置更新管理、统计报表等功能。
在接入端部分,为了满足不同用户针对不同场景的需求,ShardingSphere 提供了多款接入端,包括 Sharding-JDBC、Sharding-Proxy 和 Sharding-Sidecar(规划中):
Sharding-JDBC 是一款轻量级的 Java 框架,在 JDBC 层提供上述核心功能,使用方式与正常的 JDBC 方式如出一辙,面向 Java 开发的用户。
Sharding-Proxy 是一款实现了 MySQL 二进制协议的服务器端版本,大家可以把它当成升级版的 MySQL 数据库使用。独立部署后,即可按照正常 MySQL 操作方式来使用上述所有的核心功能。
Sharding-Sidecar 从 Service Mesh 的理念中应用而生,面向于云原生架构。
Apache ShardingSphere 是一个生态,它的开源基因注定它的发展开放自由、社区参与贡献。所以在设计它的架构时,会更加注意营造微内核与开发生态。
我们提供各个方面的开放接口,以方便所有对此感兴趣的朋友能参与其中,贡献代码,成为 Apache 基金会项目的提交者。
二、Apache ShardingSphere 核心功能 &接入端
1、核心功能介绍
数据分片、分布式事务、数据库治理功能已成熟,可提供给用户用于生产;多模式连接和管控界面还在进行中,尚需时日才可与大家见面。
成熟的核心功能具体而言主要由以下内容组成:

可以看到 Apache ShardingSphere 整个生态圈的功能点多且强大。每个功能点展开来讲,即可组成一个系列课程。限于篇幅所限,本次分享主要为大家介绍数据分片的内容,并结合京东落地实战,讲解数据分片在落地过程中遇到的问题以及对应的解决方法。
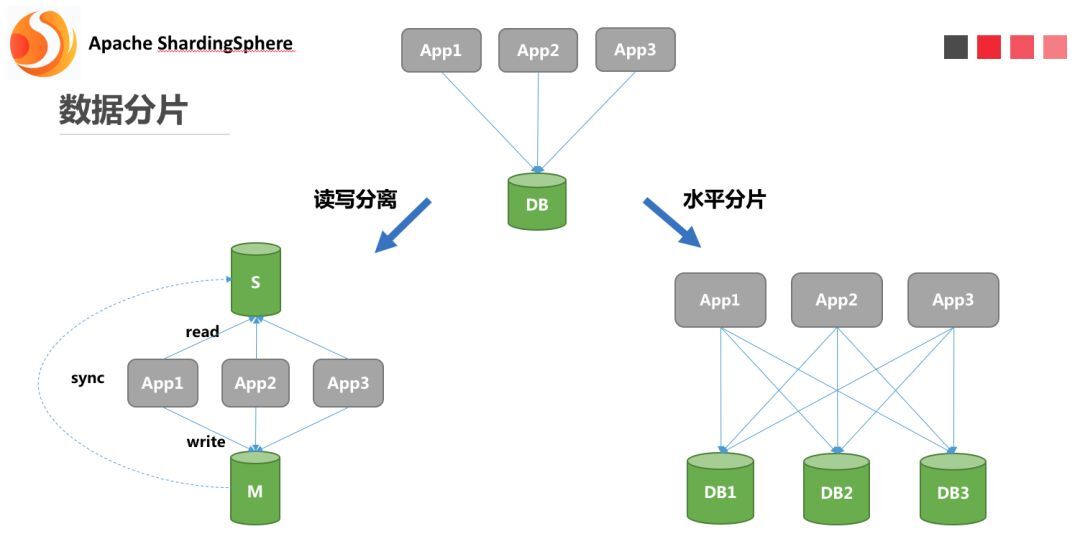
数据分片在 ShardingSphere 中主要被划分为读写分离、数据拆分。读写分离主要是指:为数据库搭建灾备副本,并在访问时将这些生产及灾备库分为主库、从库两种角色。其中主库处理所有的修改、变更操作以及少部分读操作;从库分担主库大部分的读请求。
数据拆分在这里主要指数据水平分片,即真正意义上将一个数据库拆分成多个分库,分别存储及访问。具体架构如下图所示:
在此基础上,很多业务系统出于性能和安全考虑,会选择这两种方式的混合部署架构,即同时使用读写分离和水平分片策略,如下图所示:
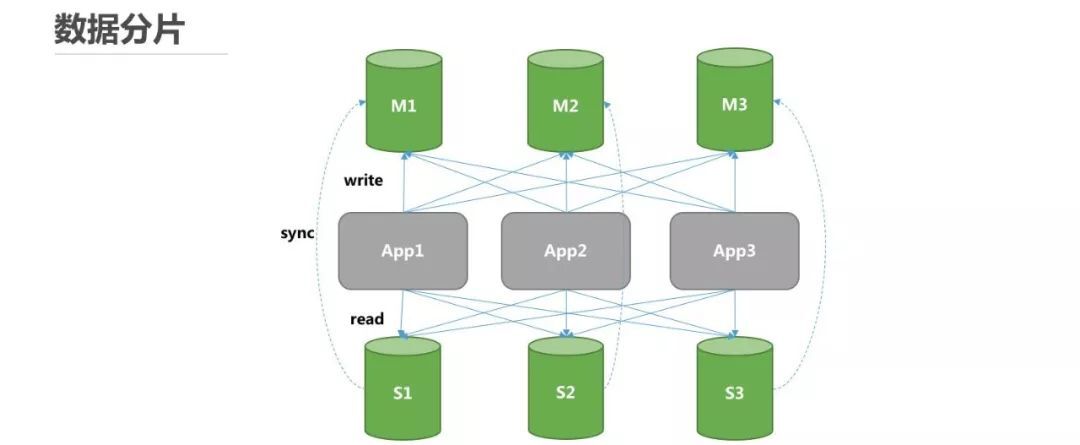
在这种情况下,底层数据的架构网络就会显得异常复杂和繁琐。因为在整个分布式的数据库系统当中会存在:分库 1、分库 2……,还有对应的从库 1、从库 2……
对业务开发的同学来讲,自身的精力和注意力不仅要放到跟 KPI 挂钩的业务代码开发上,还需要考虑如何实现和维护这样一套分布式数据库系统。
如何避免重复造轮子?如何将工作重心只落在自己的业务开发上?
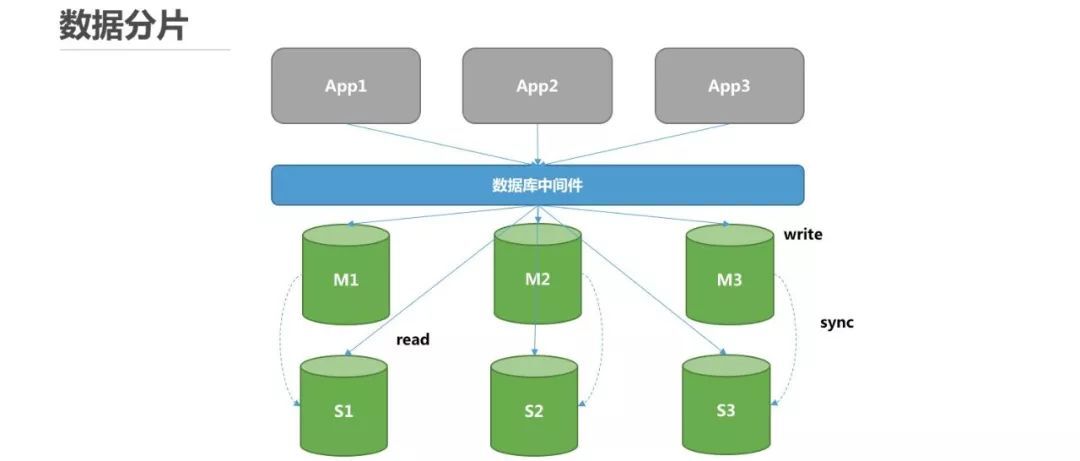
Apache ShardingSphere 便为大家充当这样一个实现并维护分布式数据库系统的管理员。作为一款分布式数据库中间件,它将为大家解决这些场景下的数据库管理维护的工作。
通过引入这层中间件,让业务开发像使用一个数据库一样去使用整个复杂繁琐的分布式数据库系统,而完全无需关心底层所有的分库以及读写库的使用和维护,如下图所示:
那么,Apache ShardingSphere 是如何做到的呢?
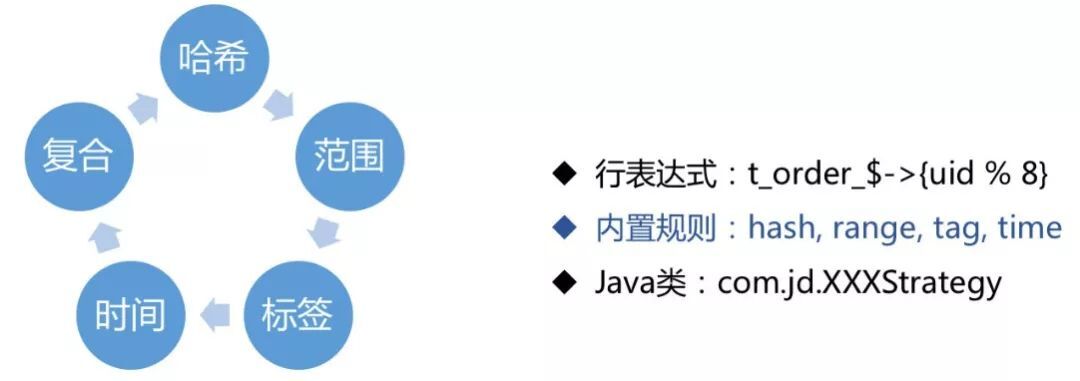
首先,它为用户提供了各种内置的分片策略方式,并开放了自定义分片策略接口,用于帮助用户完成特殊场景下的分片需求。
数据分片的重中之重是:如何去拆分数据库表?
这将关系到今后整个数据库系统的性能、与业务系统的匹配默契程度。ShardingSphere 提供了如哈希取模、范围划分、标签分类、时间范围以及复合分片等多种切分策略。
举例来说,业务方有可能会按照订单号后几十位做哈希取模来切分库表;也有可能将日志文件信息按照日、月、年的维度进行切分数据,并存储到数据库;还可能按照业务类型进行分库分表等。
针对各式各样的业务场景,ShardingSphere 提供了以下多种分片策略。虽然这些分配策略基本可以满足 80%以上业务方需求,但还是会存在一些变态的业务场景。
为此,我们开放了数据分片策略的接口,业务方可以选择按照自己的变态需求实现这些数据分片接口,ShardingSphere 就会通过 SPI 的方式将其加载使用。
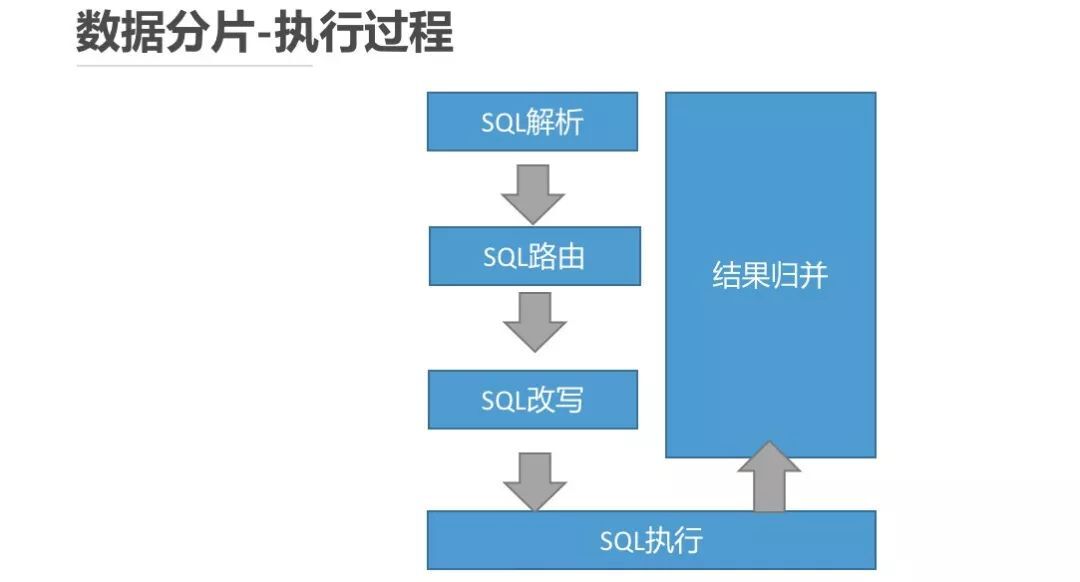
在确定好数据分片策略后,ShardingSphere 将使用该分片策略进行以下操作来完成对某条 SQL 的 DDL&DML&DAL&DQL&TCL 等操作。
但是这个过程对用户来说是透明的,即在用户无感知的情况下,ShardingSphere 将用户输入的 SQL 进行解析,然后依据用户指定的分片策略对这条不含分片信息的 SQL 进行改写,将其改写成为真正在某个或多个数据表上执行的某条或多条真实的 SQL。
此外,还需要找到每一条真实的 SQL 究竟需要在哪个库的哪张分表上执行,最终把改写后的真实 SQL 下发到对应的分表上进行多线程的执行。而用户会将拿到最终汇总后的数据结果集。
2、接入端介绍
Apache ShardingSphere 作为一个生态圈,为用户提供了多款接入端以满足用户不同应用场景的需求。分别为:
Sharding-JDBC,一款轻量级的 JAVA 框架,面向 JAVA 开发更为友好;
Sharding-Proxy,独立部署的实现了 MySQL 二进制协议的服务器端版本,支持异构语言;
Sharding-Sidecar,配合云原生环境使用,面向 Service Mesh 使用。
目前,Sharding-JDBC 和 Sharding-Proxy 可用于生产,Sharding-Sidecar 还在开发中。
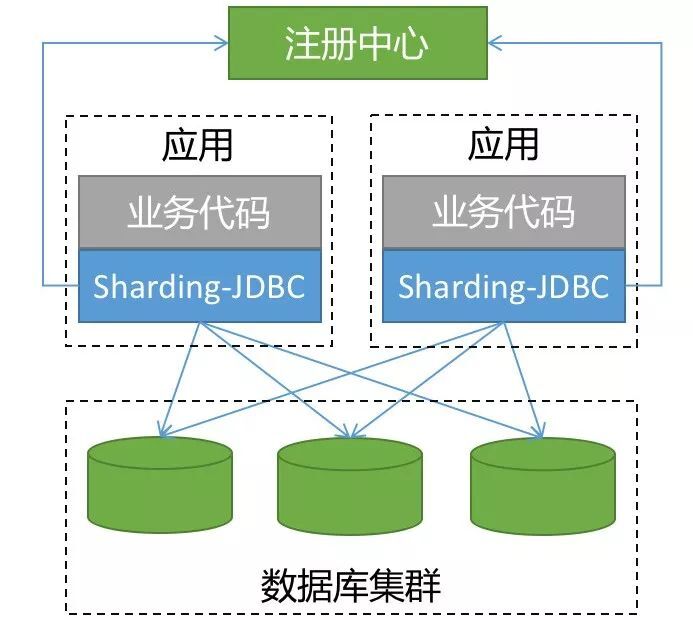
1)Sharding-JDBC
Sharding-JDBC 被定位为轻量级 Java 框架,在 Java 的 JDBC 层提供的额外服务。它使用客户端直连数据库,以 jar 包形式提供服务,无需额外部署和依赖,可理解为增强版的 JDBC 驱动,完全兼容 JDBC 和各种 ORM 框架。
适用于任何基于 Java 的 ORM 框架,如:JPA、Hibernate、Mybatis、Spring JDBC
Template 或直接使用 JDBC。
基于任何第三方的数据库连接池,如:DBCP、C3P0、BoneCP、Druid、HikariCP 等。
支持任意实现 JDBC 规范的数据库。目前支持 MySQL、Oracle、SQLServer 和 PostgreSQL。
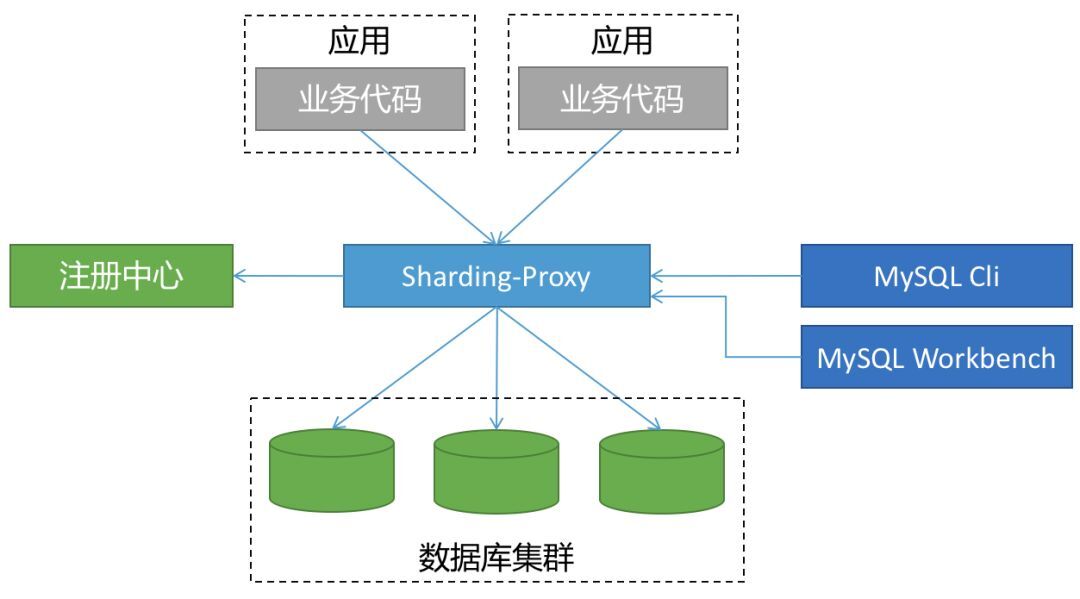
2)Sharding-Proxy
Sharding-Proxy 被定位为透明化的数据库代理端,提供封装了数据库二进制协议的服务端版本,用于完成对异构语言的支持。
目前先提供 MySQL 版本,它可以使用任何兼容 MySQL 协议的访问客户端(如:MySQL Command Client、MySQL Workbench 等)操作数据,对 DBA 更加友好:
向应用程序完全透明,可直接当做 MySQL 使用。
适用于任何兼容 MySQL 协议的客户端。
3)Sharding-Sidecar
Sharding-Sidecar 被定位为 Kubernetes 或 Mesos 的云原生数据库代理,以 DaemonSet 的形式代理所有对数据库的访问。
通过无中心、零侵入的方案提供与数据库交互的的啮合层,即 Database Mesh,又可称数据网格。
Database Mesh 的关注重点在于如何将分布式的数据访问应用与数据库有机串联起来,它更加关注的是交互,是将杂乱无章的应用与数据库之间的交互有效的梳理。
使用 Database Mesh,访问数据库的应用和数据库终将形成一个巨大的网格体系,应用和数据库只需在网格体系中对号入座即可,它们都是被啮合层所治理的对象。
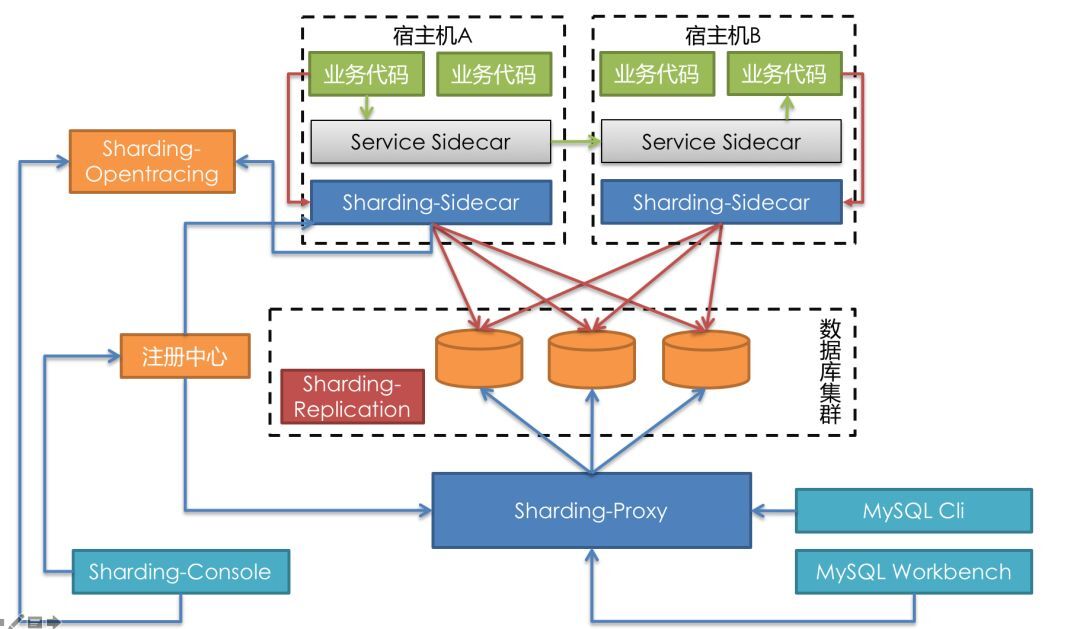
三、Apache ShardingSphere 京东落地实战
当前 ShardingSphere 已在京东落地很多大小业务,这里只是列举较为大型的系统,这些业务系统有的是重要程度较高,有的是业务较为新颖。如下图所示:
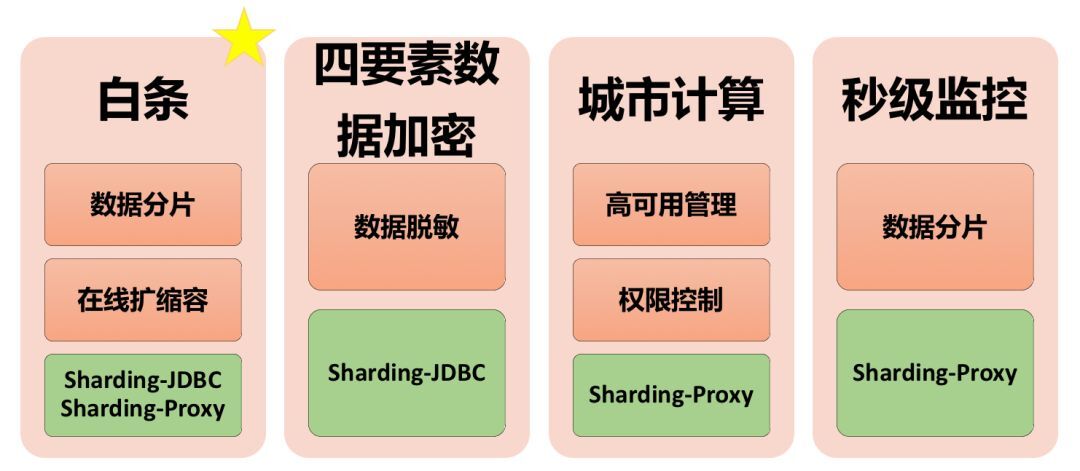
从这个案例中可以看到:
大家熟知的白条业务以及运维部门的监控系统-秒级监控主要使用 ShardingSphere 的数据分片功能及正在开发的弹性伸缩功能,使用到的主要有 Sharding-JDBC 和 Sharding-Proxy;
四要素加密主要是来自数据安全和审计的要求,主要使用到了数据脱敏的功能模块,所采用的产品是 Sharding-JDBC;
而城市计算这一新颖的业务,主要使用到了 ShardingSphere 的数据库治理模块,包括高可用管理和权限控制等。
每一个落地案例都可以成为独立的分享来为大家讲解,本次分享主要为大家介绍落地白条业务的实战情况。
在这个落地过程中,我特意总结了落地实战遇到的问题,已经对应的解决方案。我相信在各位的生产实践中多少都会遇到类似的问题,希望这些解决方案能给予大家相关经验和思考,送人玫瑰,手留余香。
主要遇到的问题以及对应的解决方案可参考下图所示:
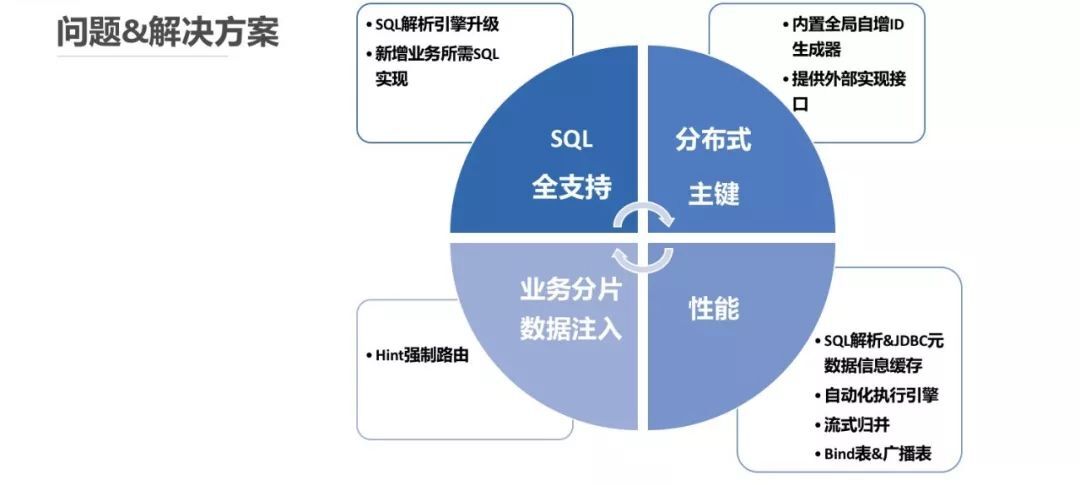
1、SQL 兼容程度
通过上面的讲解,大家可以看到使用上任何一款分布式数据库中间件都会面临一个问题:SQL 是否全支持?
因为一条不含分片信息的 SQL 是需要经过解析、改写、路由、执行、归并这些步骤的,所以对 SQL 的加工处理,有可能会致使中间件对于部分 SQL 是不支持的。
在我们真正落地白条业务时,也出现了这个问题。
白条业务的业务逻辑非常复杂且庞大,同时多样化场景的需求对 SQL 的兼容程度有较高要求。
ShardingSphere 为了能全面支撑白条业务,进行了两方面的优化重构:
一方面是重构了 SQL 解析模块;
另一方面是在除了解析模块之外的模块对更多的 SQL 进行兼容支持,例如 COUNT(DISTINCT *) 等 SQL。
SQL 解析模块是中间件的基石,如果基石不牢靠,上层建筑将岌岌可危。
从第一代的解析引擎使用 Druid 的内置解析引擎到第二代自研了 SQL 解析引擎,再到现在使用 Antlr 解析器作为 SQL 解析器,经历了 2 年之久。
耗时费力如此之多,只为了真正搭建好基石,做到解析引擎自主可控、对 SQL 高效全面支持。当前,SQL 支持情况为:
路由至单节点,SQL100%支持;
路由至多节点,全面支持 DQL、DML、DDL、DCL、TCL 和 MySQL 的部分 DAL。支持分页、去重、排序、分组、聚合、关联查询(不支持跨库关联);
具体支持情况,详见: https://shardingsphere.apache.org/document/current/cn/features/sharding/use-norms/sql/
2、分布式主键
传统数据库软件开发中,主键自动生成技术是基本需求。而各个数据库对于该需求也提供了相应的支持,比如 MySQL 的自增键、Oracle 的自增序列等。
数据分片后,不同数据节点生成全局唯一主键是非常棘手的问题。同一个逻辑表内的不同实际表之间的自增键由于无法互相感知而产生重复主键。
虽然可通过约束自增主键初始值和步长的方式避免碰撞,但需引入额外的运维规则,使解决方案缺乏完整性和可扩展性。
目前有许多第三方解决方案可以完美解决这个问题,如 UUID 等依靠特定算法自生成不重复键,或者通过引入主键生成服务等。
为了方便用户使用、满足不同用户不同使用场景的需求,ShardingSphere 提供了内置的分布式主键生成器,例如 UUID、SNOWFLAKE 等分布式主键生成器,用户仅需简单配置即可使用,生成全局性的唯一自增 ID。
此外,我们还抽离出分布式主键生成器的接口,方便用户自行实现自定义的自增主键生成算法,以满足用户特殊场景的需求。
3、业务分片键值注入
通过解析 SQL 语句提取分片键列与值并进行分片,是 ShardingSphere 对 SQL 零侵入的实现方式。
若 SQL 语句中没有分片条件,则无法进行分片,需要全路由。在一些应用场景中,分片条件并不存在于 SQL,而存在于外部业务逻辑。因此需要提供一种通过外部指定分片结果的方式,在 ShardingSphere 中叫做 Hint。
ShardingSphere 使用 ThreadLocal 管理分片键值。可以通过编程的方式向 HintManager 中添加分片条件,该分片条件仅在当前线程内生效。
除了通过编程的方式使用强制分片路由,ShardingSphere 还计划通过 SQL 中的特殊注释的方式引用 Hint,使开发者可以采用更加透明的方式使用该功能。指定了强制分片路由的 SQL 将会无视原有的分片逻辑,直接路由至指定的真实数据节点。
下面的图片将给出这一场景的具体实施案例:
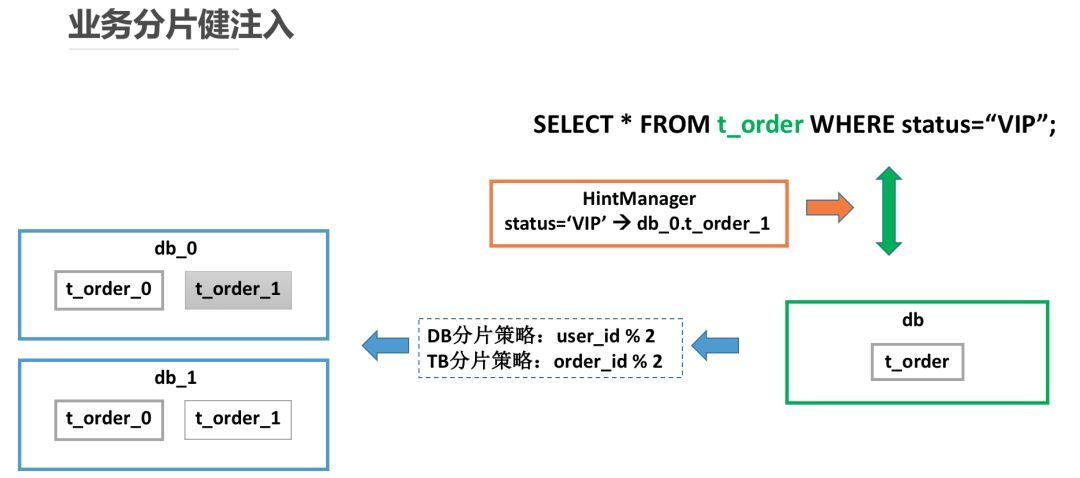
通过向 HintManager 注入 status 和具体路由表的关系,ShardingSphere 将按照用户指定规则,强制到 db_0.t_order_1 执行 SQL,并将结果返回给用户。
4、性能优化
性能问题是任何一个上线系统在面临业务高峰时都必须要考虑的问题。面对京东白条这个量级的应用,ShardingSphere 为了满足白条业务对 TPS/QPS 的强制要求,做了多方面优化,主要为:
SQL 解析结果缓存;
JDBC 元数据信息缓存;
Bind 表 &广播表的使用;
自动化执行引擎 &流式归并。
受篇幅所限,这里主要为大家介绍 Bind 表和广播表使用。这两种表的配置使用,主要是为了优化表关联问题中,切分表与切分表之间笛卡尔积表关联的情况,以及解决跨库表关联不支持的情况。
绑定表是指分片规则一致的主表和子表。例如:t_order 表和 t_order_item 表,均按照 order_id 分片,则此两张表互为绑定表关系。绑定表之间的多表关联查询不会出现笛卡尔积关联,从而关联查询效率将大大提升。
因为主表和子表使用相同的分片策略,数据在主表和子表的分布情况将一模一样,所以表关联查询的时候就能避免笛卡尔积。举例说明,如果 SQL 为:
在不配置绑定表关系时,假设分片键 order_id 将数值 10 路由至第 0 片,将数值 11 路由至第 1 片,那么路由后的 SQL 应该为 4 条,它们呈现为笛卡尔积:
在配置绑定表关系后,路由的 SQL 应该为 2 条:
其中 t_order 在 FROM 的最左侧,ShardingSphere 将会以它作为整个绑定表的主表。
所有路由计算将会只使用主表的策略,那么 t_order_item 表的分片计算将会使用 t_order 的条件。故绑定表之间的分区键要完全相同。
广播表是指所有底层分片数据源中都存在的表,表结构和表中的数据在每个分库中完全一致。
这样在进行关联查询的时候,由于广播表在所有分库均存在,就避免了笛卡尔积关联查询以及跨库关联的情况。比较适用于数据量不大且需要与海量数据的表进行关联查询的场景,例如:字典表。
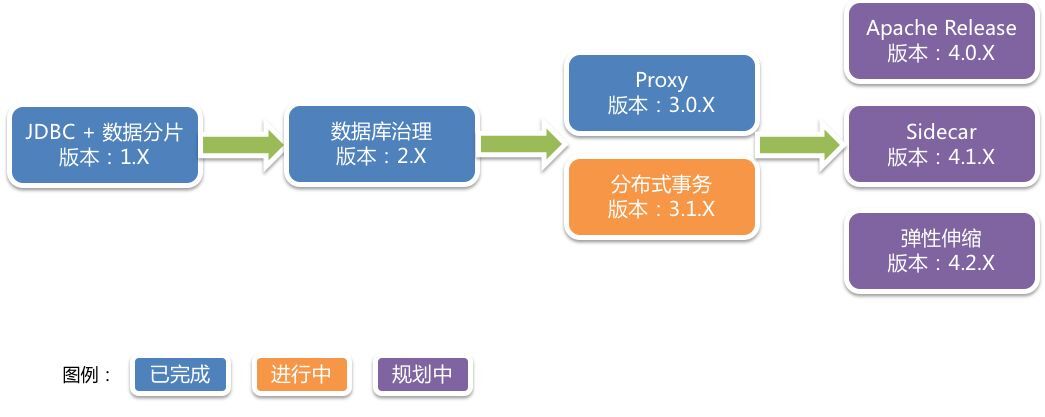
四、Apache ShardingSphere 迭代 &规划
Apache ShardingSphere 的发展及规划如下图所示:
官网及 GitHub 也欢迎大家的访问:

五、写在最后
感谢各位朋友能阅读到文章最后,当然也可能是直接跳到了这里。这篇文章来自于线上的分享,有兴趣的朋友可以回顾线上分享,应该会比文字更生动有趣一些。
从最开始入职做 DBA 到现在转为分布式数据库中间件 JAVA 开发程序猿,也开始在开源领域里去探索寻找自我定位和意义。互联网行业如同大海航行时代,波涛汹涌,变化万千。
愿所有朋友都能做好舵手,直挂云帆济沧海。
直播回放
https://m.qlchat.com/topic/details?topicId=2000003991669127

数据连接未来

中国开发者画像洞察报告 2022
本次报告为你深度解读开发者人群背景,分析开发者群体面临的挑战,洞察开发者人群特征,预测开发者生态发展...









评论