

一、前言
距笔者上次提出 NFwFM 点击率预估模型,并覆盖美图秀秀、美拍等推荐场景已经过去半年。算法钻研如逆水行舟,不进则退。用户和公司越来越高的期望也要求我们不断进步。
与此同时,美图社区内容推荐业务发展迅猛,有目共睹。社区内容推荐一方面是千人千面,精准连接用户与内容,另一方面是连接用户与用户。因此近半年来,我们的业务目标自然的从点击率预估发展到点击率和关注转化率的多目标预估模型。
本文介绍将多任务学习应用于点击率和关注转化率预估的一些思考和实践经验。这些实践已全量覆盖美图秀秀社区以及美拍热门等推荐场景。
二、算法选型
笔者管中窥豹, 将多目标预估分为两大类, 一类是多模型,一类是多任务学习。
多模型为每一个目标单独构造训练样本和特征,并采用合适的模型各自训练。其优点是可以为每个目标进行深度优化,且预估值融合阶段能够根据业务目标灵活控制各个目标的权重。缺点是需要配备多套人力和机器来存储和优化样本、特征以及调整融合公式。
学术界和业界近年来在多任务学习(Multi-task Learning, MTL)方面的研究和实践进展颇多。MTL 是机器学习的一种范式,属于迁移学习的范畴,但与大家通常理解的迁移学习的区别在于多任务学习是要借助其它的任务来帮助提升所有任务而非某一个任务的学习效果。
当多个任务相关性强时,譬如点击率和关注转化率,多任务学习与迁移学习的本质区别便成为多任务的最大优点。此外,依笔者浅见,DNN 灵活的网络结构,其在一个模型中能够包容多种不同分布的样本并各自优化其目标,更是释放了 MTL 的最大价值。其缺点是参数共享,当存在不那么相关的任务时,任务之间会相互扰乱,影响效果。
多任务学习本身一个很古老的概念[5]。对多任务学习做详细的介绍超出了本文的范围,感兴趣的同学可以参考文末的参考文献。
思虑至此,结合实际预估目标,我们很自然的选择多任务学习作为点击率预估和关注转化率预估的多目标预估模型。
三、Multi-task NFwFM
正如前面所说,多任务学习只是机器学习的一种范式,并不局限于特定的问题或者模型。因为有非常实际的工业需求,所以工业界和学术界的研究和实践成果还在不断增加。
比如 2016 年横空出世的 YouTubeNet[1], KDD’18 的 MMoE[2]等学术研究;工业界如美团"猜你喜欢"引入 Multi-task DNN 后 CTR 提升 1.23%[3], 知乎引入 MMoE 后互动率提升 100%[4]。
在实践过程中为了追求训练效率高,模型可拓展性以及最重要的效果要好,工业界通常选择 Shared-Bottom multi-task DNN[5]的网络结构。
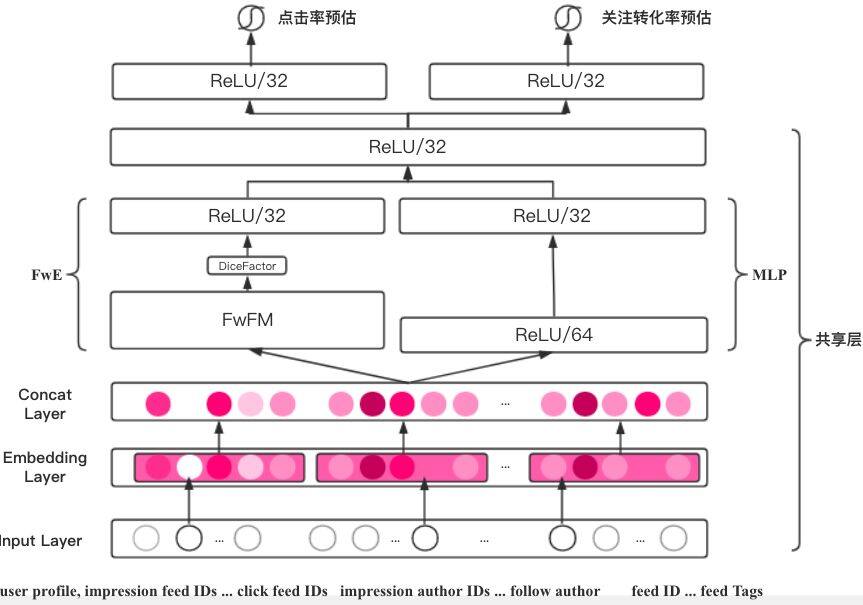
如上图,Multi-task NFwFM 的前 4 个隐含层是共享的,点击率预估任务和关注转化率预估任务共享特征表示。在最后即将预估多个目标时通过全连接层进行拆分,各自学习对应任务的参数,从而专注地拟合各自任务。
多任务学习的不同任务在共享层里的局部极小值位置是不同的,通过多任务之间不相关的部分的相互作用,有助于逃离局部极小值点;而多任务之前相关的部分则有利于底部共享层对通用特征表示的学习,因此通常多任务能够取得比单任务模型更好的效果。
在线上预估时,因为模型尺寸没有变化,推理效率和线上的点击率预估模型一致。考虑到我们是在点击率任务的基础上同时优化关注转化率,融合公式上体现为优先按照点击率排序再按照曝光→关注的转化率排序。
Multi-task NFwFM 已在美图秀秀社区首页 Feeds 推荐、相关推荐下滑流全量上线。首页 Feeds 点击率 +1.93%,关注转化率 +2.90%, 相关推荐下滑流人均浏览时长+10.33%, 关注转化率+9.30%。
四、样本 reweight
上述普适版的 Multi-task NFwFM 带来了点击率和关注率转化率的稳定提升,这驱使我们进一步根据业务数据的特点压榨模型价值。
点击和关注转化样本生而不平等。在秀秀首页 Feeds 推荐场景下,点击样本数:关注样本数≈100:1。虽然 Multi-task NFwFM 包容了点击和关注转化这两种不同分布的样本,并支持各自优化其目标,然而点击样本和关注样本严重不平衡,这无疑会影响关注转化率预估目标的学习。
为了最大化模型的价值,reweight 自然成为我们的选择。样本的研究和模型应用是同等重要的问题,相关研究仍然很活跃,不断有新算法被提出。代表性的工作有近期 Kaiming He 等人提出的 Focus Loss[6], 其通过减少易学习样本的权重,使得模型在训练时更专注于难学习的样本。
Focus Loss 的优点是可以通过超参数来控制两种样本的分布,缺点是在梯度下降类的优化算法中,样本无法随机 shuffle,而这对梯度下降类算法的收敛速度至关重要。
回到实践本身,我们采用样本 reweight 的土办法,一方面,样本 reweight 天然的支持随机 shuffle, 另一方面,从以往实践的经验来看,用更多、更高质量的数据进行训练几乎是总能带来提升的。
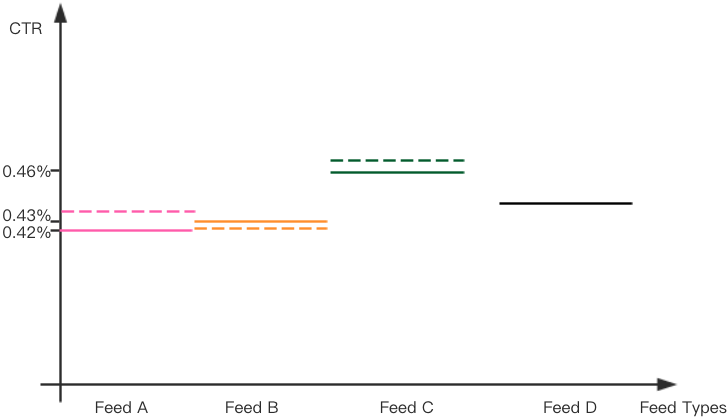
以下图为例,假设有 4 类 feeds, A、B、C、D, 关注转化率的大小关系是 A > C > B > D=0。实线部分表示 4 类 feed 的真实 CTR,则虚线表示各类 feed 被关注样本 reweight 之后的虚拟 CTR。
通过关注转化率 reweight 点击正样本,改变了 CTR 分布之后,模型的 pCTR 将倾向于 C>D>A>B,保证在原始 CTR 接近的情况下,关注转化率较高的 feed 更容易被模型推荐出来,提升整体的关注转化率,并且因为 C、D 等点击率较高的 feed 不受分布改变后影响,因此整体 CTR 应不受太大影响。
基于上述关注样本 reweight 点击正样本的策略,美图秀秀社区首页 Feeds 推荐 CTR -1.09%, 关注转化率 +12.03%。
五、Task-specific weighted Loss
样本 reweight 让我们在关注转化率目标上取得了显著的提升,但是 CTR 下降明显。笔者调整并灰度实验多个 reweight 候选值,尝试降低关注转化率对点击正样本的分布的影响,结果让人失望,CTR 均低于线上。
很大可能的原因是上述图示对我们场景数据的假设太简单理想了。正如前文所述,多任务学习的缺点是参数是共享的,当多个任务存在不相关部分时,任务之间会相互扰乱,影响效果。
学术界将这个现象称为"share conflict",分析并解决这个问题的挑战较大,且业界和学术界可供参考的经验少。
另一种减小 share conflict 的曲线方式是 gradient balancing method,在我们场景下对应的是加大 multi-task NFwFM 中点击率预估任务的重要性,让点击率预估任务来主导底部共享层的参数学习,进而影响整体模型的预估性能。
Yarin Gal 在 CVPR’18 提出一种基于不确定估计的方法, Homoscedastic Uncertainty[7], 来设定多个任务的学习率,学习率越大对整体模型的学习主导性越强。
如下图,在秀秀社区首页 Feed 推荐场景中, Homoscedastic Uncertainty 估计方法表明关注转化率的不确定性确实比点击率预估任务高,因此我们应该让点击率预估任务来主导整体模型的学习。
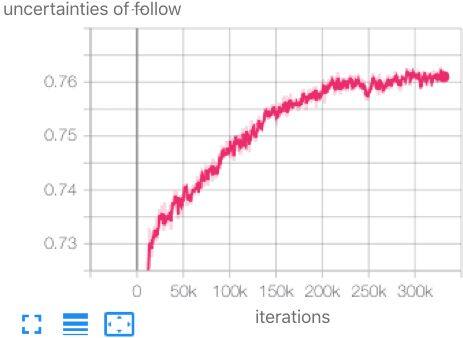
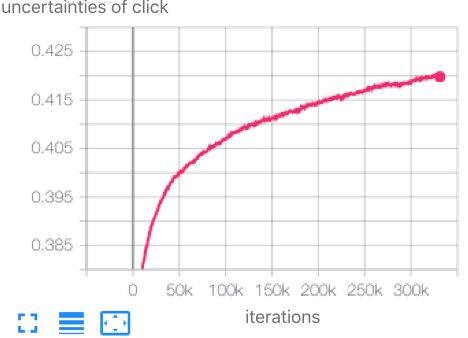
然而灰度实验期间,发现该方法估计出来的不确定性本身不稳定,参数容易学飘,甚至出现相反的结论,导致实验效果波动较大。在实践中,笔者采用效果正向提升的几天的不确定性值作为最终的参数。
上述改进的 Multi-task NFwFM, 在美图秀秀社区首页 Feeds 推荐场景全量上线,点击率 -0.36%, 关注转化率+12.75%。
六、未来展望
对于多目标预估问题,我们已经实现了一套具有良好拓展性的系统,并在生产实践中取得了成功应用。纵观业界,不少公司也在生产中使用了各种多任务模型和算法。
同多任务学习的广阔空间相比,目前我们的实践还很初级,未来我们一方面会继续发挥多任务学习的优势,根据业务形态设计多任务学习目标,另一方面还会尝试更为复杂的模型和算法。
参考文献
Covington P, Adams J, Sargin E. Deep neural networks for youtube recommendations
Ma J, Zhao Z, Yi X, et al. Modeling task relationships in multi-task learning with multi-gate mixture-of-experts
美团"猜你喜欢"深度学习排序模型实践
进击的下一代推荐系统:多目标学习如何让知乎用户互动率提升 100%?
Rich Caruana. 1998. Multitask learning. In Learning to learn
Lin T Y, Goyal P, Girshick R, et al. Focal loss for dense object detection
Kendall A, Gal Y, Cipolla R. Multi-task learning using uncertainty to weigh losses for scene geometry and semantics
作者介绍:
陈文强,美图高级算法技术专家。曾就职阿里巴巴、腾讯。具有多年推荐算法的实际落地经验,长期深耕于最优化算法、推荐算法领域的研究。NFwFM 提出者,在 Neural Computing 等期刊发表数篇论文。

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论 1 条评论