
近日,快手成为业内首家在 PC 客户端实现基于深度学习实时变声直播的公司。这项变声技术可以实现任意用户到目标音色的稳定变声,变声后语音具有自然度高,相似度高,音质清晰等优势,同时整个系统的链路延迟可低至 200 毫秒。
业内首次将基于深度学习的实时变声技术应用于直播场景
在快手、AcFun 等直播平台上,主播往往需要一些趣味性强的功能增强和观众的互动,而变声功能就是其中之一。而现有直播平台支持的变声技术都是基于数字信号处理的变声,主要是对语音信号中的基频和共振峰进行人工干预。这种方法虽然可以实现音色转换,但变声效果因人而异,而且变声后的音色难以控制,甚至会产生混叠噪声,受到不少用户的诟病。
随着人工智能技术的发展,基于深度学习的变声研究也越来越深入。该技术可以很好控制变声后的目标音色,而且变声后语音的自然度也比较高。但是基于深度学习的变声技术对计算资源的需求比较大,通常需要将其部署在服务器上,同时变声实时性也很难保证。
由于直播变声业务的场景特殊性,对变声后语音的自然度与系统运行实时性都要求非常高,而且为了避免网络抖动等带来的干扰,变声系统一般都需要部署在用户客户端(电脑、手机等)上,所以市面已有的变声方案均无法满足高质量的直播变声需求。而快手又是一家直播业务占比很大的公司,主播对在直播间使用高质量的变声有巨大的需求。因此,如何研发一套既能保证变声后音色自然,又能保证运行实时性的变声系统,成为了横亘在快手面前的一道难题。最终,快手音视频技术部和多媒体理解(MMU)部门联手,通过反复的实验和分析,对现有的基于深度学习的变声技术做了进一步优化,在模型尺寸压缩、流式处理以及端上设备多核并行计算等方面做了大量研发工作,最终实现了一套既能保证变声后音色自然稳定,同时又具有高实时性、低复杂度等优势的变声系统,满足了直播变声的要求。
目前,该技术已经完成算法开发,工程质量测试以及用户灰度测试,并在 AcFun 直播业务场景(windows 客户端,i7 4 核以上机器)全量上线。主播可以通过 A 站直播伴侣中的变声功能,选择基于深度学习变声的“憨憨音”或者“软妹音”,实现音色切换。这个两个音色甫一上线,就受到主播的喜爱和广泛好评。
据悉,此次 Acfun 直播业务中上线的变声应用,是业内首个可在 PC 客户端实时运行并采用深度学习框架的变声直播应用,是快手在直播场景的语音交互领域的一个重大技术突破,有望引领直播变声应用的新潮流。此外,快手还准备将直播变声玩出更多花样,比如多种方言与普通话的双向切换,甚至可以进行用户个性化定制变声音色,更好实现人工智能为直播平台赋能。
变声技术的行业现状
变声技术出现良久,业内常用的变声技术是基于数字信号处理的方法,比如虎牙直播、剪映、以及 MorphnVOX Pro 等各类变声软件。而一些提出基于深度学习变声技术的公司,比如科大讯飞、搜狗等,部分没有提供给普通用户的试用接口,或者部署在云端且不支持实时变声。
综合目前的实现方式,大致可以将变声技术分为如下三类:
1. 基于数字信号处理的方法
原理:主要是对语音中的基频和共振峰两个特征进行修改,其中基频是人发浊音时声带的振动频率,而共振峰是指声门波在声道里的共振频率。一般来说,女性的基频高于男性,而男性的共振峰频率比女性要高,这两个特征都与说话人的声道结构和发声特点密切相关,想要修改原始语音中的说话人音色,就需要通过信号处理的相关算法对原始语音中的基频和共振峰进行人工干预。
优点:运算速度比较快,音准比较好;
缺点:跨性别转换效果差,变声后的语音合成感很明显,同时无法完成稳定变声音色输出。
音色自然度:★☆☆☆☆
运行实时性:★★★★★
2. 基于生成对抗网络的方法
原理:完成的是原始说话人到目标说话人之间声学特征的映射建模。包括生成网络和对抗网络两个部分,生成网络输入原始语音的声学特征,预测对应的目标语音声学特征,而对抗网络判断输入样本属于目标语音的生成样本还是真实样本,从而帮助生成网络预测生成更接近目标说话人真实样本的输出。
优点:变声音色自然度较高,真实感非常强,且音色稳定性强;
缺点:生成对抗网络的训练数据是有限的,因此只能建模训练集合内说话人之间的音色映射,而不适用于原属说话人不确定的场景;同时该方法计算量很大,无法支持实时场景。该方案目前尚处于学术研究阶段,不具备工业化应用基础。
音色自然度:★★★★★
运行实时性:★☆☆☆☆
3. 基于音素后验概率的方法
原理:利用语音识别系统首先将语音转换为音素后验概率或音素序列,然后通过变声模型完成上述特征到目标人语音的映射;目前市场上大部分深度学习变声均选用该方案。
优点:可支持训练集外说话人转换为目标说话人,音色自然度较高,真实度较好,且音色稳定性较好。
缺点:使用的语音识别系统和声码器参数量和计算量比较大,只能在云端运行,无法支持实时场景,更无法在端上设备运行。
音色自然度:★★★★☆
运行实时性:★★☆☆☆
综上所述,基于数字信号处理的变声虽然运行速度很快可以实现实时变声,但是变声的自然度较差,用户满意度较差;基于生成对抗网络的变声可以保证输出语音的高自然度,但无法满足训练集外说话人变声需求,同时计算量过大无法保证实时性;基于音素后验概率的变声虽然效果可以支持任意用户到指定音色的变声,但同样因所需计算量很大只能在云端部署,无法满足直播变声实时性的要求。
快手如何实现技术突破
从上一节的分析可见,基于音素后验概率的方法可以满足直播变声功能的变声后音色稳定、自然,音质清晰等需求,但无法实现客户端上部署及实时运行。所以,如何在该方法的基础上,既保证变声后音色自然稳定,同时又可以使其在客户端上实时运行,成为了快手研发团队的重点攻关任务。最终,快手的研发团队在基于音素后验概率的方法基础上,对特征提取模型、网络声码器等重要模块进行了针对性的优化开发,并引入了基于深度学习的低功耗降噪模型,完成了一套基于深度学习的实时变声直播系统。该系统可在 PC 客户端运行,延时低至 200 毫秒,可以满足直播变声功能的需求。
该系统主要由以下四个重要模块构成:
降噪模型:该模型基于深度神经网络对主播输入的语音进行降噪处理,增强系统对环境中平稳噪声的鲁棒性,减少环境噪声对变声系统音准的干扰;
发音单元表征模型:该模型从原始语音中提取出深层语音瓶颈特征,用以描述原始语音中的内容信息,在保证精度的情况下对模型尺寸及计算量进行优化,以满足端上设备运行的要求;
变声模型:该模型完成了说话人无关的深层语音瓶颈特征到特定说话人声学特征的映射,针对实时、端上设备的应用场景,采用了基于 Encoder-Decoder 框架的非自回归的变声模型,并且一个模型可以支持多个音色输出;
声码器:应用高维输入特征的高性能深度学习声码器,可实现高音质、高采样率、低复杂度的语音特征到语音信号的转换;
此外,针对端上设备的特点,快手还开发了多核并行计算的深度学习变声系统架构以及抗抖动的低延迟 jitter buffer 模块,进一步加速端上计算,提升系统稳定性。
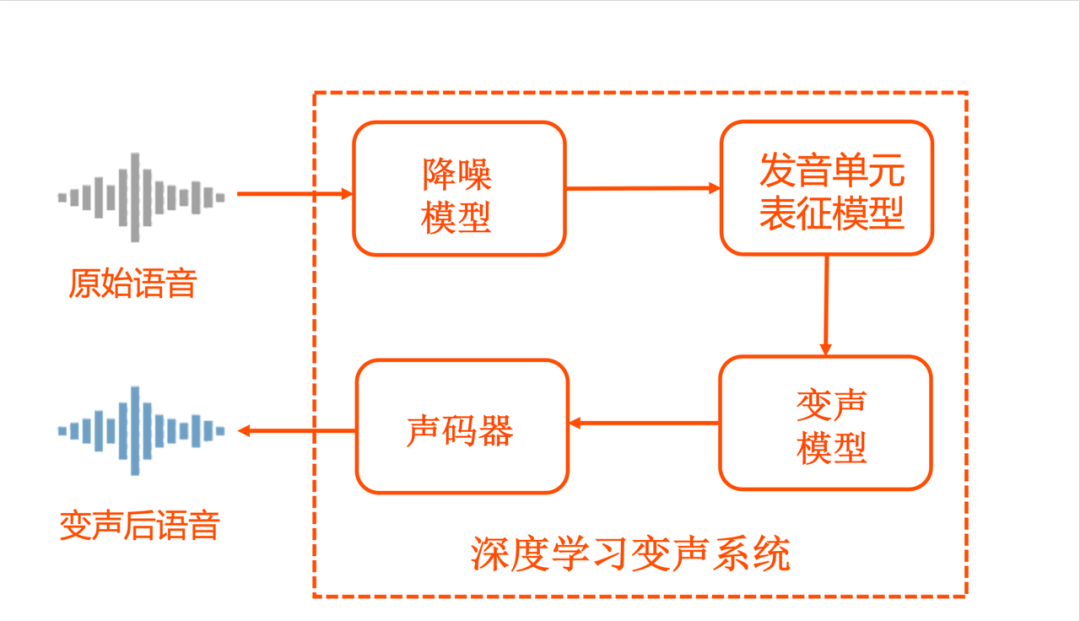
其中,音视频技术部负责了高音质、高采样率、低复杂度的深度学习声码器、基于深度学习的降噪模块、多核并行计算的变声系统架构及抗抖动的低延迟 jitter buffer 模块的开发。MMU 负责了基于深度学习的发音单元特征表征模块、基于 Encoder-Decoder 框架的变声模块和基于多说话人数据的变声预训练平台的开发。
接下来,整个研发团队将会围绕进一步提升音质,降低复杂度,以及用户音色个性化定制等多个方向进行不断的迭代优化,争取在更多的产品、机型和场景落地。
参考资料:
会议论文
[1] Ying Zhang, Hao Che, Chenxing Li, Xiaorui Wang, “One-shot Voice Conversion Based ON Speaker Aware Module”, in ICASSP 2021, 6-11 June 2021, Toronto, Canada
[2] Ying Zhang, Hao Che, Xiaorui Wang, “Non-parallel Sequence-to-Sequence Voice Conversion for Arbitrary Speakers ,”in ISCSLP 2021,24-26 January, HongKong, China
专利
[1] 直播变声, 2021KI0494CN
[2] 基于任意人一句话的语音转换技术, 2020KI1910CN
[3] 语音数据处理方法和装置, 2020KI1304CN
[4] 一种去噪去混响的网络设计和数据增强方法, 2020KI1326CN;
[5] 一种循环神经网络的深度学习降噪状态控制方法, 2020KI0921CN;
[6] 一种基于 SNR 和音频相位的深度学习音频降噪方法, 2020KI0029CN;




