
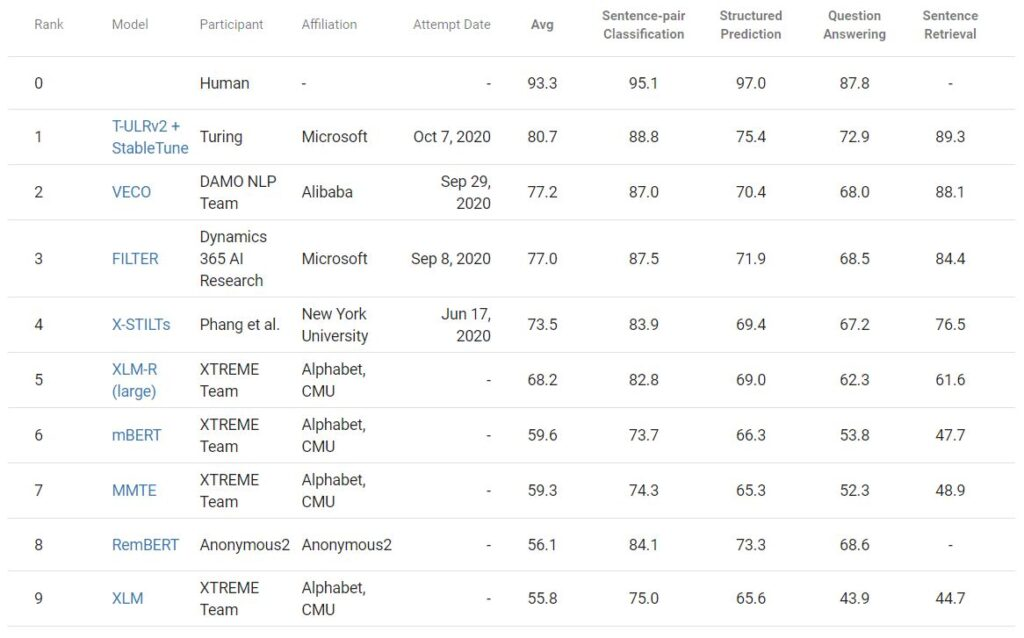
今天,我们很高兴地宣布,图灵多语言模型(Turing multilingual language model,T-ULRv2)目前位居 Google XTREME 公共排行榜榜首。该模型是由 Microsoft 图灵团队与 Microsoft Research 合作开发的,该模型的平均得分高出阿里巴巴(VECO)之前的最好成绩 3.5 分。为了实现这一点,除了预训练模型之外,我们还使用了“StableTune”,这是一种基于稳定性训练的新型多语言微调技术。排行榜上的其他模型包括 XLM-R、 mBERT、XLM 等。以前最好的提交之一也是来自 Microsoft 使用 FILTER 提交的。
通用语言表示
Microsoft 图灵团队长期以来,一直认为语言表示应该是通用的。在这篇发表于 2018 年的论文 中,我们提出了一种以无监督方式训练语言不可知表示的方法。这种方法允许用一种语言对训练过的模型进行微调,并以零样本学习的方式应用于另一种语言。这将克服要求标签数据以每种语言训练模型的挑战。自从这篇论文发表以来,无监督的预训练语言建模已成为所有自然语言处理模型的支柱,而基于 Transformer 的模型是所有这类创新的核心。
作为 Microsoft 大型人工智能的一部分,图灵系列的自然语言模型一直在推动 Microsoft 产品中的下一代人工智能体验。图灵通用语言表示模型(T-ULRv2)是我们最新的跨语言创新,它结合了我们最近的创新 InfoXLM,从而创建了一个通用模型,在同一个向量空间中表示 94 种语言。在最近的一篇博文中,我们讨论了如何使用 T-ULR 对 Microsoft Bing(微软必应)的所有支持语言和地区的智能答案进行扩展。同样的模型也被用于扩展 Microsoft Word 语义搜索功能,使其扩展到英语之外,并为 Microsoft Outlook 和 Microsoft Team 提供回复建议。我们将很快向用户提供这些通用的体验。
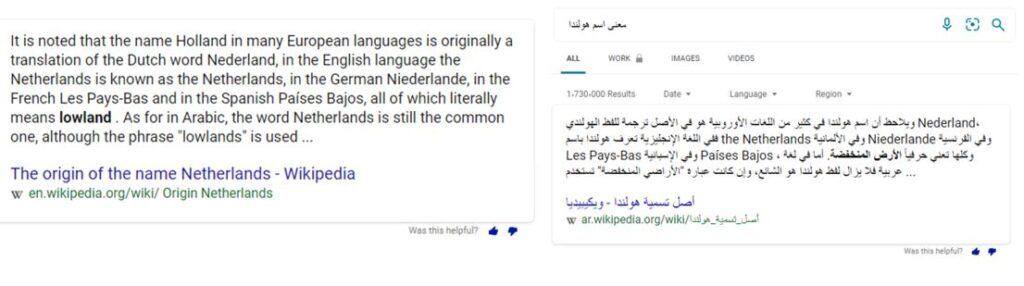
Microsoft Bing 的西班牙语和阿拉伯语智能答案的示例,由 T-ULR 提供支持。
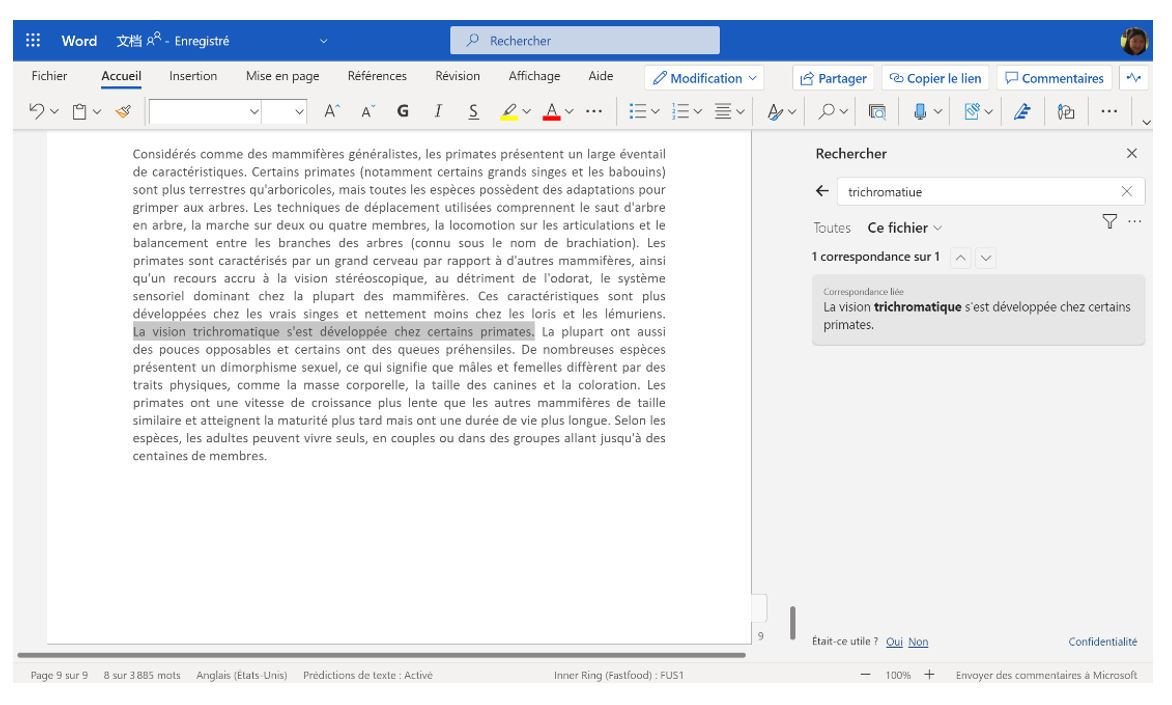
Microsoft Word 语义搜索的法语示例,由 T-ULR 提供支持。
这些真实的产品场景要求极高的质量,因此为我们的人工智能模型提供了完美的测试平台。结果,我们的大多数模型在自然语言处理任务的正确性和性能都接近最新水平。
XTREME 基准
多语言编码器的跨语言迁移评估(The C ross-lingual TR ansfer E valuation of M ultilingual E ncoders,XTREME)基准涵盖了跨越 12 个语系的 40 种不同类型的语言,其中包括 9 项任务,这些任务需要对不同级别的语法或语义进行推理。选择 XTREME 中的语言是为了最大限度地提高语言多样性、现有任务的覆盖率和训练数据的可用性。
XTREME 中包含的任务涵盖了一系列的范式,包括句子文本分类、结构化预测、句子检索和跨语言问答。因此,为了使模型在 XTREME 基准中获得成功,它们必须学习泛化到许多标准跨语言迁移设置的表示。
有关基准测试、语言和任务的完整描述,请参阅《XTREME:用于评估跨语言泛化的大规模多语言多任务基准》(XTREME: A Massively Multilingual Multi-task Benchmark for Evaluating Cross-lingual Generalization.)
T-ULRv2:数据、架构和预训练
图灵通用语言表示(T-ULRv2)是一种具有 24 个层和 1024 个隐状态的 Transformer 架构,共有 5.5 亿个参数。T-ULRv2 预训练有三个不同的任务:多语言屏蔽语言建模(multilingual masked language modeling,MMLM)、翻译语言建模(translation language modeling,TLM)和跨语言对比(cross-lingual contrast,XLCo)。MMLM 任务(又称为 Cloze 任务)的目标是从不同语言的输入预测被屏蔽的标记。T-URLv2 使用一个由 94 种语言组成的网络多语言数据库进行 MMLM 任务训练。与 MMLM 一样,TLM 任务也是预测被屏蔽的标记,但预测是受到以串联的翻译对的限制。例如,给定一对英语和法语的句子,模型可以通过关注周围的英语标记或其法语翻译来预测被屏蔽的英语标记。这有助于模型对齐不同语言中的表示。
XLCo 还使用了并行训练数据。任务的目标是最大化平行句表示之间的互信息。与 MMLM 和 TLM 中的最大化令牌序列互信息不同,XLCo 的目的是跨语言序列级的互信息。在 TLM 和 XLCo 任务中,T-URLv2 都使用 14 个语言对的翻译并行数据。
XLCo 的损失函数如下:
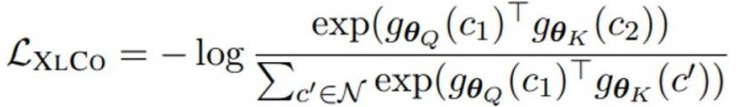
随后将其添加到 MMLM 和 TLM 损失中,以获得跨语言预训练的总体损失:
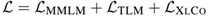
T-ULRv2 发布信息
在 Microsoft Ignite 2020 上,我们宣布图灵模型将可用于构建自定义应用程序,作为私人预览的一部分。T-ULRv2 也将成为该计划的一部分。如果你有兴趣了解更多关于此图灵模型和其他图灵模型的更多信息,可以给我们提交申请。我们正在与 Azure 认知服务(Azure Cognitive Services)密切合作,使用图灵模型为当前和未来的语言服务提供支持。现有的 Azure 认知服务客户将通过 API 自动从这些改进中受益。
让我们的人工智能体验民主化
在 Microsoft,全球化不仅仅是一个研究问题。这是一个我们必须正视的产品挑战。世界各地都有 Windows。Microsoft Office 和 Microsoft Bing 在 200 个地区有 100 多种语言版本。我们的客户遍布世界的每一个角落,他们以自己的母语来使用我们的产品。为了使我们的产品体验真正民主化,以赋予所有用户权利,并在全球范围内有效地扩展,我们正在推动多语言模型的边界。其结果是像 T-ULRv2 这样的与语言无关的表示形式可以改善所有语言的产品体验。
作者介绍:
Saurabh Tiwary,是 Microsoft 副总裁兼杰出工程师。
周明博士,是微软亚洲研究院副院长、国际计算语言学协会(ACL)主席、中国计算机学会理事、中文信息技术专委会主任、术语工作委员会主任、中国中文信息学会常务理事、哈尔滨工业大学、天津大学、南开大学、山东大学等多所学校博士导师。
原文链接:




