

Original URL: https://aws.amazon.com/cn/blogs/machine-learning/accessing-data-sources-from-amazon-sagemaker-r-kernels/
Amazon SageMaker notebooks 现已开箱即用支持R ,且无需在实例上手动安装R 内核。此外,这些notebooks 还预装了 reticulate 库,由其为 Amazon SageMaker Python SDK 提供 R 接口,并允许您从 R 脚本当中调用 Python 模块。大家可以使用 Amazon SageMaker R 内核轻松访问多个数据源,运行机器学习(ML)模型。目前,所有提供 Amazon SageMaker 服务的区域都已默认提供 R 内核。
R 是一种专为统计分析构建而成的编程语言,目前在数据科学界具有极高人气。在本文中,我们将一同了解如何使用 Java 数据库连接(JDBC) 从 Amazon SageMaker R 内核接入以下数据源:
关于通过 R 使用 Amazon SageMaker 功能的更多详细信息,请参阅 面向 Amazon SageMaker 的 R 用户指南 。
解决方案概述
构建这套解决方案,我们首先需要创建一个包含公共与私有子网的 VPC,借此保证隔离网络内的各不同资源与数据源能够实现安全通信。接下来,我们使用必要配置在自定义 VPC 与 notebook 实例中创建数据源,并使用 R 访问各数据源。
为了确保数据源不暴露在公开互联网之下,我们需要保证各数据源完全驻留在 VPC 的私有子网当中。这里我们需要创建以下资源:
- 在私有子网内创建一套 Amazon EMR 集群,同时安装 Hive 与 Presto。关于具体操作说明,请参阅 即刻开始:使用 Amazon EMR 分析大数据 。
- Athena 资源。关于具体操作说明,请参阅 入门指南 。
- 在私有子网内创建一套 Amazon Redshift 集群。关于具体操作说明,请参阅 创建一套示例 Amazon Redshift 集群 。
- 在私有子网内创建一套 MySQL 兼容型 Amazon Aurora 集群。关于具体操作说明,请参阅 创建一套 Amazon Aurora DB 集群 。
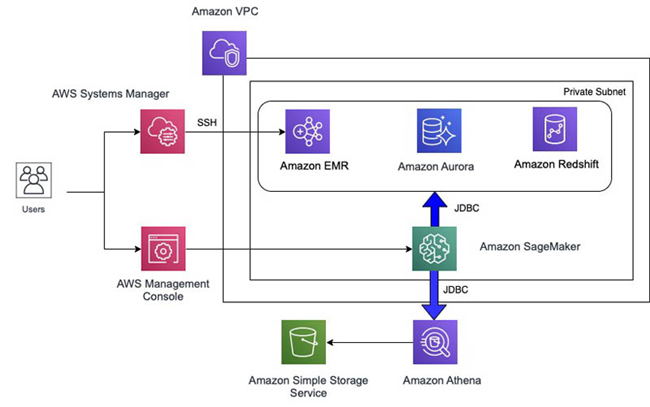
使用 AWS Systems Manager Session Manager 连接私有子网内的 Amazon EMR 集群,而后创建 Hive 表。
要在 Amazon SageMaker 中使用 R 内核运行代码,大家还需要创建一个 Amazon SageMaker notebook。请注意下载用于数据源的 JDBC 驱动程序。为包含 R 软件包安装脚本的 notebook 配置生命周期 ,并在创建及启动时将该生命周期配置附加至notebook 以保证安装顺利完成。
最后,我们可以使用AWS 管理控制台导航至notebook,使用R 内核运行代码并访问来自各个数据源。您可以通过 GitHub repo 获取这套完整的解决方案。
解决方案架构
以下架构图展示了如何与各个数据源建立起连接,使用 Amazon SageMaker 通过 R 内核运行代码。大家也可以使用 Amazon Redshift 查询编辑器或者 Amazon Athena 查询编辑器以创建数据资源。您还需要使用 AWS Systems Manager 中的会话管理器(Session Manager)通过 SSH 接入 Amazo nEMR 集群以创建 Hive 资源。
启动 AWS CloudFormation 模板
要自动创建资源,您可以运行一套 AWS CloudFormation 模板。该模板将帮助您指定需要自动创建的 Amazon EMR 集群、Amazon Redshift 集群或者兼容 MySQL 的 Amazon Aurora 集群,而不必手动执行各个步骤。只需要几分钟,全部资源即可创建完毕。
- 选择以下链接即可启动 CloudFormation 栈。该栈将创建实施本次解决方案的全部必要 AWS 资源:

- 在 Create stack 页面上 , 选择 Next 。
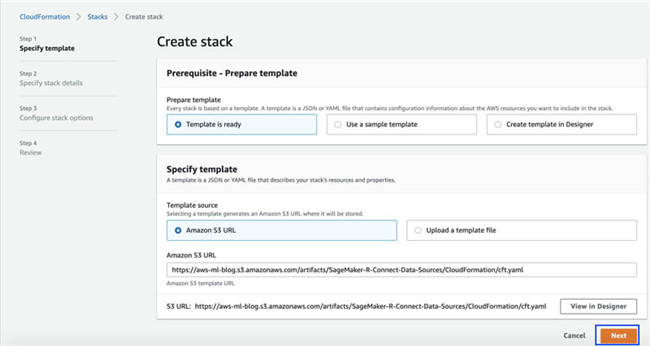
- 输入栈名称。
- 您可以对以下栈细节的默认值做出调整:
| 栈细节 | 默认值 |
|---|---|
| 选择 B 类网络地址作为 VPC IP 地址 (10.xxx.0.0/16) | 0 |
| SageMaker Jupyter Notebook 实例类型 | ml.t2.medium |
| 是否自动创建 EMR 集群? | “Yes” |
| 是否自动创建 Redshift 集群? | “Yes” |
| 是否自动创建 Aurora MySQL DB 集群? | “Yes” |
- 选择 Next 。
- 在 Configure stack options 页面上 , 选择 Next 。
- 选择 I acknowledge that AWS CloudFormation might create IAM resources (我确认 AWS CloudFormation 可以创建 IAM 资源)。
- 选择 Create stack 。
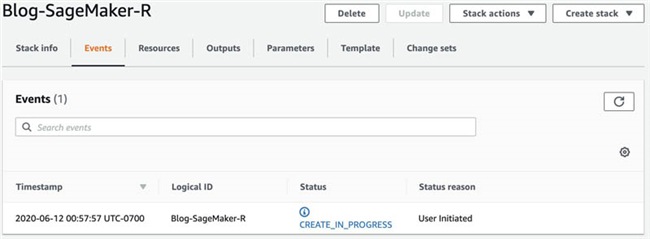
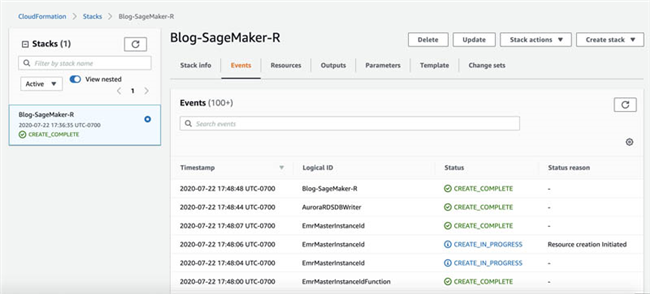
- 现在,您可以看到正在创建的栈,详见以下截屏。
-
在栈创建完毕之后,状态将显示为
CREATE_COMPLETE。
- 在 Outputs 选项卡中,记录各键及其对应的值。
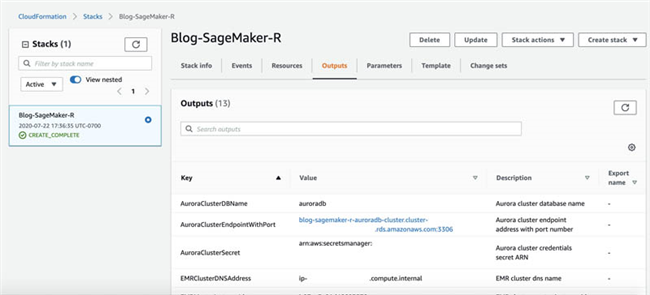
在本文中,我们将陆续使用到以下键:
- AuroraClusterDBName – Aurora 集群数据库名称
- AuroraClusterEndpointWithPort – Aurora 集群端点地址与端口号
- AuroraClusterSecret – Aurora 集群凭证 secret ARN
- EMRClusterDNSAddress – EMR 集群 DNS 名称
- EMRMasterInstanceId – EMR 集群主实例 ID
- PrivateSubnets – 私有子网
- PublicSubnets – 公共子网
- RedshiftClusterDBName – Amazon Redshift 集群数据库名称
- RedshiftClusterEndpointWithPort – Amazon Redshift 集群端点地址与端口号
- RedshiftClusterSecret – Amazon Redshift 集群凭证 secret ARN
- SageMakerNotebookName – Amazon SageMaker notebook 实例名称
- SageMakerRS3BucketName – Amazon SageMaker S3 数据存储桶
- VPCandCIDR – VPC ID 与 CIDR 地址块
使用必要的 R 软件包与 JAR 文件创建 notebook 实例
JDBC 为面向 Java 编程语言的应用程序编程接口 (API),负责定义对数据库的具体访问方式。RJDBC 则是 R 中的一款软件包,可帮助大家使用 JDBC 接口接入各类数据源。CloudFormation 模板创建的 notebook 实例,将保证为 Hive、Presto、Amazon Athena、Amazon Redshift 以及 MySQL 提供必要的 JAR 文件,由此建立起 JDBC 连接。
- 在 Amazon SageMaker 控制台下的 Notebook 部分,选择 Notebook instances 。
-
搜索与您之前记录的
SageMakerNotebookName键相匹配的 notebook。
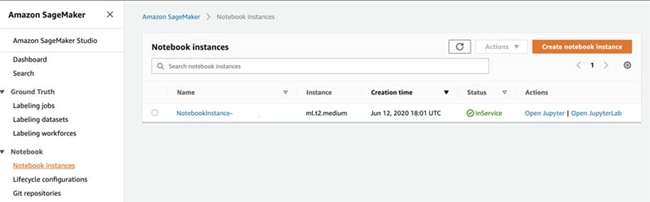
- 选择该 notebook 实例。
- 点击“Actions”之下的“Open Jupyter”,并定位至“jdbc”目录。

CloudFormation 模板将在“jdbc”目录当中下载与 Hive , Presto , Athena , Amazon Redshift 以及 Amazon Aurora MySQL 相兼容的 JAR 文件。
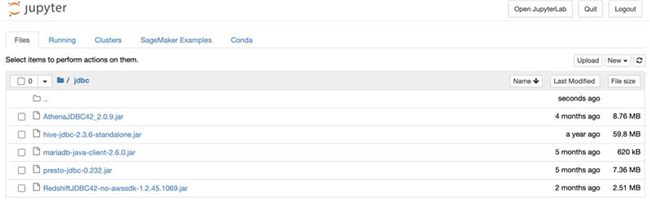
- 找到 Notebook 实例的 生命周期配置 。
通过生命周期配置,我们可以在 notebook 实例上安装软件包或示例 notebook,为其配置网络与安全性,或者使用 Shell 脚本进行自定义其他配置。生命周期配置负责在我们创建 notebook 实例或者启动此 notebook 时,提供需要配套运行的 shell 脚本。
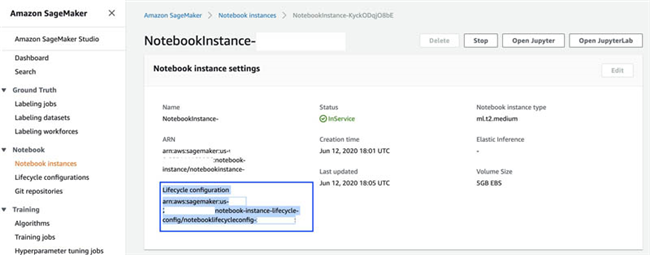
- 在 Lifecycle configuration 部分,选择 View script 以查看负责在 Amazon SageMaker 中设置 R 内核以通过 R 将 JDBC 连接指向数据源的生命周期配置脚本。
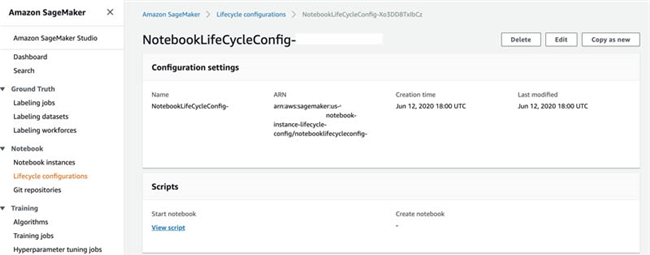
此生命周期配置,将在 Amazon SageMaker notebook 的 Anaconda 环境中安装 RJDBC 软件包与依赖项 。
接入 Hive 与 Presto
Amazon EMR 是一套行业领先的云大数据平台,可使用各类开源工具(例如 Apache Spark , Apache Hive, Apache HBase , Apache Flink , Apache Hudi 以及 Presto)处理大量数据。
大家可以使用 System Manager 中的会话管理器(Session Manager)功能从 AWS 控制台登录至 EMR 主节点,由此在 Hive 当中创建测试表。通过 Systems Manager,您可以查看并控制 AWS 上的基础设施。Systems Manager 还提供统一的用户界面,供您统一查看来自多项 AWS 服务的管理数据,同时跨多种 AWS 资源自动执行管理任务。会话管理器是一项全托管 Systems Manager 功能,可帮助您通过基于浏览器的一键式交互 shell 或 AWS 命令行界面(AWS CLI),对 Amazon Elastic Compute Cloud (Amazon EC2) 实例、本地实例以及虚拟机加以管理。
您可以在此步骤中使用在 AWS CloudFormation Outputs 选项卡当中提供的以下值:
-
EMRClusterDNSAddress – EMR 集群 DNS 名称
-
EMRMasterInstanceId – EMR 集群主实例 ID
-
SageMakerNotebookName – Amazon SageMaker notebook 实例名称
-
在 Systems Manager 控制台 的 Instances & Nodes 之下 , 选择 Session Manager 。

- 选择 Start Session 。

-
使用
EMRMasterInstanceId键的值作为实例 ID,SSH 到 EMR 主节点。
这项操作将启动基于浏览器的 shell。
- 运行以下 SSH 命令:
# change user to hadoop
whoami
sudo su - hadoop
- 登录到 EMR 主节点上,在 Hive 中创建一份测试表:
# Run on the EMR master node to create a table called students in Hive
hive -e
"CREATE TABLE students (name VARCHAR(64), age INT, gpa DECIMAL(3, 2));"
# Run on the EMR master node to insert data to students created above
hive -e
"INSERT INTO TABLE students VALUES ('fred flintstone', 35, 1.28), ('barney
rubble', 32, 2.32);"
# Verify
hive -e
"SELECT * from students;"
exit
exit
以下截屏所示,为基于浏览器的 shell 中的视图示例。
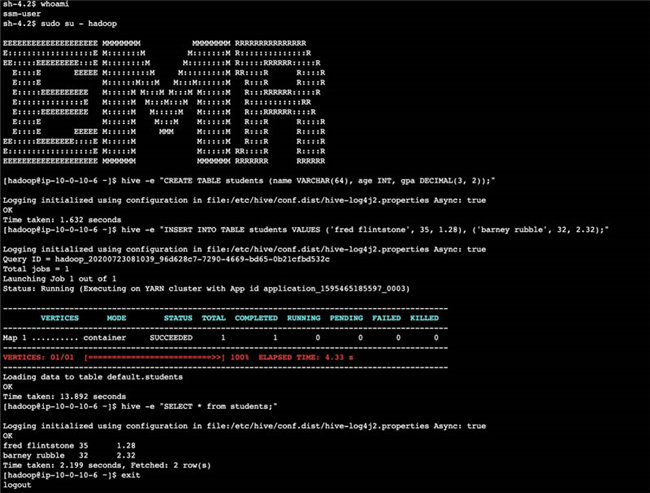
- 退出 shell 之后,关闭浏览器。
要使用 Amazon SageMaker R 内核对 Amazon EMR 中的数据进行查询,请打开之前由 CloudFormation 模板创建完成的 notebook。
-
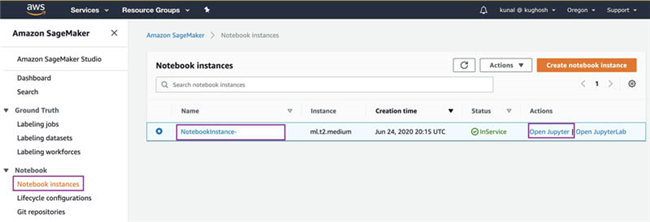
在 Amazon SageMaker 控制台 的 Notebook 之下,选择 Notebook instances 。
-
找到由
SageMakerNotebookName键的值所指定的 notebook。 -
选择 Open Jupyter 。
-
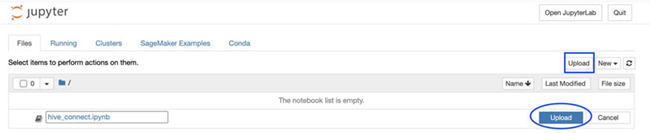
要演示 Amazon SageMaker R 内核中连接 EMR, 选择 Upload 并上传 ipynb notebook。
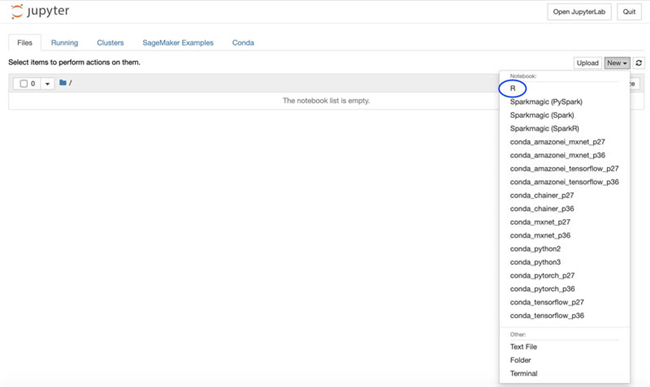
- 或者在 New 下拉菜单中, 选择 R 以打开一个新 notebook。
-
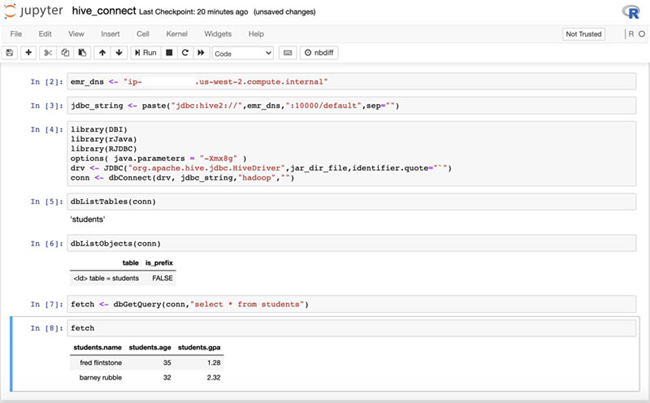
输入“hive_connect.ipynb”中的代码,将
emr_dns值替换为EMRClusterDNSAddress键提供的值:
-
运行该 notebook 中的所有单元,使用 Amazon SageMaker R 控制台接入 Amazon EMR 上的 Hive。
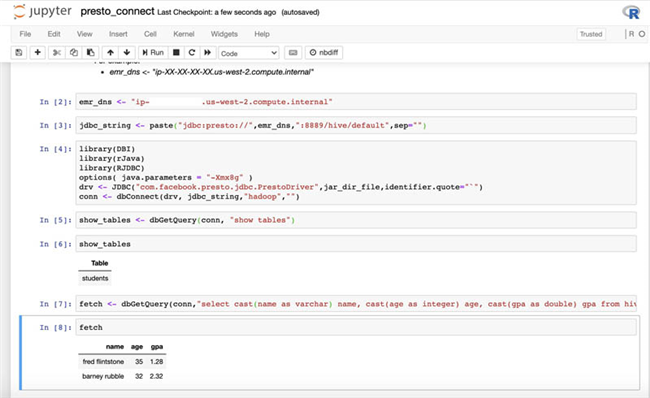
我们可以通过类似的步骤接入 Presto:
- 在 Amazon SageMaker 控制台 上,打开我们之前创建的 notebook。
- 选择 Open Jupyter 。
-
选择
Upload 以上传
ipynb
notebook。
- 或者,可以在 New 下拉菜单中选择 R 以打开一个新 notebook。
-
输入“presto_connect.ipynb”中的代码,将
emr_dns值替换为EMRClusterDNSAddress键提供的值:
- 运行该 notebook 中的所有单元,使用 Amazon SageMaker R 控制台接入 Amazon EMR 上的 PrestoDB。
接入 Amazon Athena
Amazon Athena 是一项交互式查询服务,可使用标准 SQL 轻松分析 Amazon Simple Storage Service (Amazon S3) 中的数据。Amazon Athena 还具备无服务器属性,大家无需管理任何基础设施,只需要为实际运行的查询付费。要使用 RJDBC 从 Amazon SageMaker R 内核接入 Amazon Athena,我们需要使用 Amazon Athena JDBC 驱动程序 。此驱动程序已经通过生命周期配置脚本被下载至 notebook 实例当中。
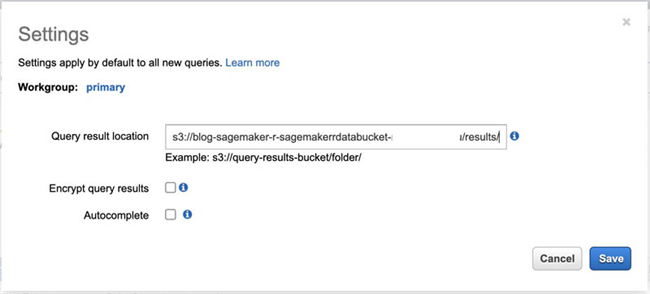
大家还需要在 Amazon S3 中设置查询结果位置。关于更多详细信息,请参阅 如何使用查询结果、输出文件与查询历史 。
- 在 Amazon Athena 控制台 上,选择 Get Started 。
- 选择 Set up a query result location in Amazon S3(在 Amazon S3 中设置查询结果位置) 。
-
在
Query result location
部分,输入由
SageMakerRS3BucketName键的值指定的 Amazon S3 位置。 -
或者,您也可以直接添加前缀,例如
results。 - 选择 Save 。
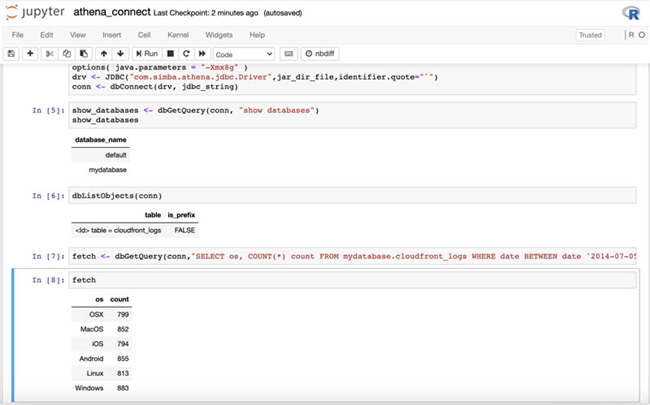
- 使用 Amazon S3 中的示例数据 在 Athena 中创建数据库或 schema 及其对应表 。
-
与接入 Hive 及 Presto 的方式类似,大家可以上传
ipynb
notebook 以通过 R 内核在 Athena 与 Amazon SageMaker 之间建立一条连接。
-
或者,您可以打开一个新的 notebook 并输入“athena_connect.ipynb”中的代码,并将其中
s3_bucket的值替换为SageMakerRS3BucketName键的值:
-
或者,您可以打开一个新的 notebook 并输入“athena_connect.ipynb”中的代码,并将其中
- 运行 notebook 中的所有单元,借此由 Amazon SageMaker R 控制台接入至 Amazon Athena。
接入 Amazon Redshift
Amazon Redshift 是一款速度表现出色的全托管云数据仓库,凭借标准 SQL 与您的现有商务智能(BI)工具实现简单且经济高效的数据分析能力。Redshift 可以对 TB 乃至 PB 级别的大规模结构化数据执行查询,对复杂查询实现优化,可在高性能存储之上实现列式存储,并支持大规模并发查询执行功能。要使用 RJDBC 由 Amazon SageMaker R 内核接入 Amazon Redshift,我们可以使用 Amazon Redshift JDBC 驱动程序 ,此驱动程序已通过生命周期配置脚本被下载至 notebook 实例当中。
您需要从 AWS CloudFormation Outputs 选项卡中获取以下键及其对应值:
- RedshiftClusterDBName – Amazon Redshift 集群数据库名称
- RedshiftClusterEndpointWithPort – Amazon Redshift 集群端点地址与端口号
- RedshiftClusterSecret – Amazon Redshift 集群凭证 secret ARN
CloudFormation 模板会在 AWS Secrets Manager 当中为 Amazon Redshift 集群创建一项 secret,由此保护我们用于访问应用程序、服务以及各项 IT 资源的 secrets。Secrets Manager 还允许用户轻松轮替、管理并检索数据库凭证、API 密钥乃至整个生命周期中的其他 secrets。
- 在 AWS Secrets Manager 控制台 上,选择 Secrets 。
-
选择由
RedshiftClusterSecret键值表示的 secret。
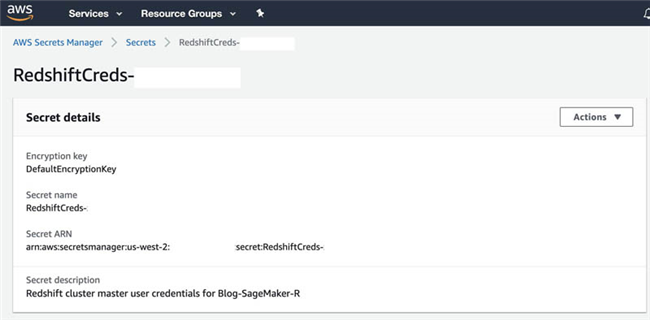
- 在 Secret value 部分 , 选择 Retrieve secret value 以获取 Amazon Redshift 集群的用户名与密码。
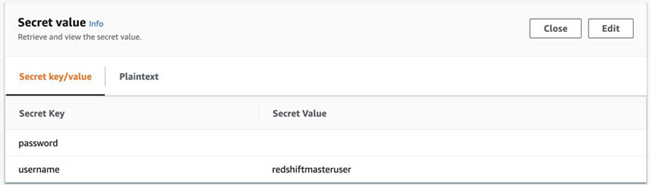
- 在 Amazon Redshift 控制台 上,选择 Editor (在本质上为 Amazon Redshift 查询编辑器 )。
-
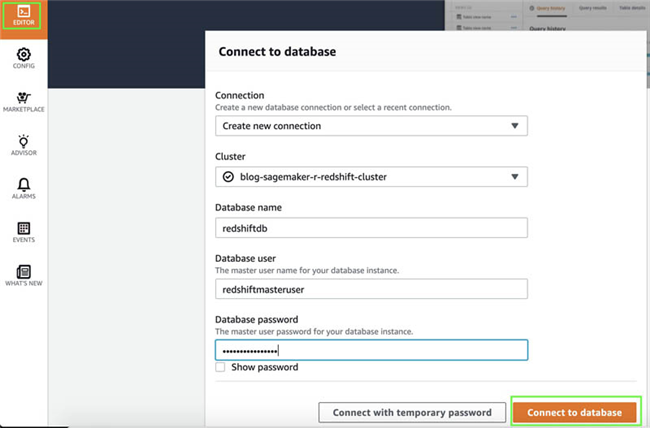
在
Database name 部分,输入
redshiftdb。 - 在 Database password 部分,输入您的密码。
- 选择 Connect to database 。
- 运行以下 SQL 语句,创建一份表并插入几条记录:
CREATE
TABLE
public
.students (
name
VARCHAR
(
64
), age
INT
, gpa
DECIMAL
(
3
,
2
));
INSERT
INTO
public
.students
VALUES
(
'fred flintstone'
,
35
,
1.28
), (
'barney rubble'
,
32
,
2.32
);
- 在 Amazon SageMaker 控制台 上,打开您的 notebook。
- 选择 Open Jupyter 。
-
上传
ipynb
notebook。
-
或者,打一个新的 notebook 并输入“redshift_connect.ipynb”中的代码,注意替换其中
RedshiftClusterEndpointWithPort,RedshiftClusterDBName以及RedshiftClusterSecret的值:
-
或者,打一个新的 notebook 并输入“redshift_connect.ipynb”中的代码,注意替换其中
- 运行 notebook 中的所有单元,由 Amazon SageMaker R 控制台接入 Amazon Redshift。

接入 MySQL 兼容型 Amazon Aurora
Amazon Aurora 是一套专门面向云环境构建的 MySQL 兼容型关系数据库,能够将传统企业级数据库的性能与可用性,同开源数据库的便捷性与成本效益加以结合。要使用 RJDBC 由 Amazon SageMaker R 内核接入 Amazon Aurora,我们需要用到 MariaDB JDBC 驱动程序 ,此驱动程序已通过生命周期配置脚本被下载至 notebook 实例当中。
大家需要使用 AWS CloudFormation Outputs 选项卡中提供的以下键及其对应值:
- AuroraClusterDBName – Aurora 集群数据库名称
- AuroraClusterEndpointWithPort – Aurora 集群端点地址及其端口号
- AuroraClusterSecret – Aurora 集群凭证 secret ARN
CloudFormation 模板将在 Secrets Manager 中为 Aurora 集群创建 secret。
-
在
AWS Secrets Manager 控制台
上,找到由
AuroraClusterSecret键值表示的 secret。
- 在 Secret value 部分 , 选择 Retrieve secret value 以获取 Aurora 集群的用户名与密码。
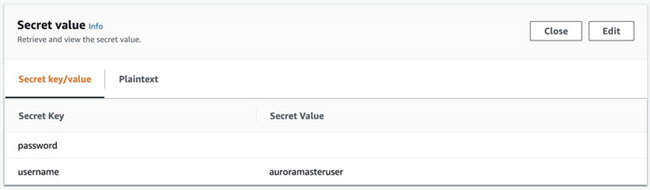
要接入该集群,请遵循与其他服务类似的操作步骤。
- 在 Amazon SageMaker 控制台 上,打开您的 notebook。
- 选择 Open Jupyter 。
-
上传
ipynb
notebook。
-
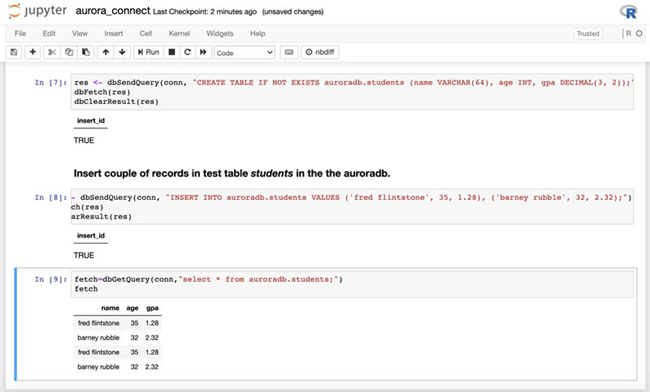
或者,您可以打一个新的 notebook 并输入“aurora_connect.ipynb”中的代码,请注意替换
AuroraClusterEndpointWithPort,AuroraClusterDBName以及AuroraClusterSecret的值:
-
或者,您可以打一个新的 notebook 并输入“aurora_connect.ipynb”中的代码,请注意替换
- 运行 notebook 中的所有单元,以在 Amazon SageMaker R 控制台上接入 Amazon Aurora。
总结
在本文中,我们演示了如何在您的运行环境中接入各类数据源,包括 Amazon EMR 上的 Hive 与 PrestoDB、Amazon Athena、Amazon Redshift 以及 MySQL 兼容型 Amazon Aurora 集群等,并借此经由 Amazon SageMaker 实现分析、剖析并运行统计计算。您也可以通过 JDBC 将同一方法扩展到其他数据源。
作者介绍 :
AWS 公司解决方案架构师。他热衷于立足云端构建高效解决方案,特别是与分析、人工智能、数据科学以及机器学习相关的解决方案。在业余时间,除了陪伴家人之外,他还喜欢读书、游泳、骑自行车、看电影和享受美食。
Amazon Web Services 公司大数据与分析专业解决方案架构师。Gagan 在信息技术领域拥有超过 15 年的从业经历,帮助客户在 AWS 上构建具备高可扩展性、高性能与高安全性的云解决方案。
本文转载自亚马逊 AWS 官方博客。
原文链接 :









