写点什么
创作场景
- 记录自己日常工作的实践、心得
- 发表对生活和职场的感悟
- 针对感兴趣的事件发表随笔或者杂谈
- 从 0 到 1 详细介绍你掌握的一门语言、一个技术,或者一个兴趣、爱好
- 或者,就直接把你的个人博客、公众号直接搬到这里
登录/注册
收录了 数据分析图 频道下的 50 篇内容
这是“用Apache Spark进行大数据处理”系列文章的第六篇。在这最后一部分,我们将聚焦于如何处理图数据和学习Spark中的图数据分析库GraphX。

Amazon Neptune 图数据库自从 2018 年 5 月 30 日正式推出以来,已经一年有余,现已经扩展到全球12个区域,同时具有高可用性,并提供只读副本、时间点恢复、到 Amazon S3 的持续备份以及跨可用区的复制。

每一位卓越的 AI 专家,骨子里都是一流的数据分析师。

随着客户的需求越来越“百变”,最近在做大屏设计的葡萄陷入了困境。近期客户提出的需求是想在BI工具中增加 “路线地图”展示功能并进行数据分析。不仅如此,这个“路线地图”还要兼具实用的功能与美观的动效,典型的“既要又要”系列。但是这对于我们的设计
多模态数据分析不应该是少数 ML 工程师的专属能力。Hologres 将其民主化为每一位懂 SQL 的数据从业者都能使用的工具——无需额外基础设施、无需新技能栈、无需数据搬迁。

本文简述了大数据处理的技术实践,从高实时性、秒级查询、交互式分析等方面进行详述。同时,介绍了离线任务管理的拓展领域。希望给读者带来一些启发,更希望能引起志同道合者的共鸣和探讨。

GeaFlow(品牌名TuGraph-Analytics) 已正式开源,欢迎大家关注!!! 欢迎给我们 Star 哦! GitHub👉https://github.com/TuGraph-family/tugraph-analytics

如果按照显示数量来讲,是标签的概念。如果是属性,就分实体属性和链接属性,这些A类多个属性是为A实体和A链接的服务的,主要作用于后续对A实体和A链接的深度分析、分类、统计、过滤、对比等等。

随着岚图汽车销量攀升,每日百亿级数据规模持续膨胀,如何从海量数据中快速提炼有价值信息支撑研发、生产、销售等环节,成为迫切需求。

本文介绍了阿里云 Quick BI 如何通过技术架构跃迁、结合大模型的突破实现从传统 BI 到 AI 驱动的智能 BI 的跨越式进化。并重点解析领域大模型与 BI 引擎的协同设计、NL2SQL 算法调优与架构演进、AI + BI 在场景落地实践过程中的技术权衡,为行业提供可复用的技术范式。
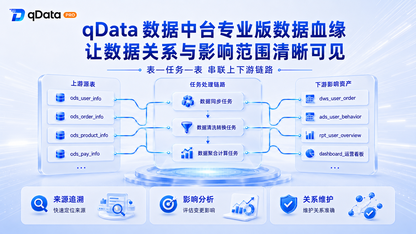
qData 数据中台专业版数据血缘围绕表与任务,通过血缘地图展示“表—任务—表”完整链路,支持来源追溯与影响分析,并提供手动维护能力。帮助研发与治理人员直观查看数据来源、加工路径及变更影响范围,将分散关系沉淀为可查询的数据关系资产。

系统梳理企业级 AI 的端到端落地路径,从战略规划、数据准备到 Agent 构建与业务价值衡量,搭建可规模化的 AI 实施框架。

随着 OpenClaw 等开源 AI Agent 框架的广泛应用,一个清晰的范式正在形成:复杂的任务正被拆解为由自然语言指令驱动的自动化工作流。

原创公众号:bigsai,8张图带你分析Redis与MySQL数据一致性问题

在实际项目中,知识图谱很少是一个“单独的 AI 功能”,它往往承担着关系组织、语义推理、复杂分析的底层能力。但大量失败案例也说明: 图谱不是画出来的,而是“跑”出来的系统工程。

2026 年,AI 落地的故事正在上演一个奇特的悖论:模型能力突飞猛进,企业 AI 投入成本与日俱增,但然后呢?

2026年5月26日,由星环科技自主研发的分布式数据库ArgoDB V6通过中国信息安全测评中心、国家保密科技测评中心联合发布的“安全可靠测评”认证,全面验证其在产品安全与供应链安全领域的端到端防护能力,构建起覆盖研发、产品到生态的全栈自主可控安全体系,能够为各行业核心业务系统提供长期安全、稳定、可靠的数据库支撑。

“把数据库迁到 GPU,就像移民到火星。”

Gartner 在去年 6 月发布的预测中提到,到 2028 年,至少 15% 的日常工作决策将由 Agentic AI 自主完成。
 京公网安备 11010502039052号 | 产品资质
京公网安备 11010502039052号 | 产品资质











