
核心功能
数据查询与可视化: 支持将自然语言精准转化为查询 SQL,并自动选择最优的可视化图表,直观呈现数据洞察。
交互式数据分析: 依托 LLM 的推理能力和算法库,实现异常检测、根因排查等分析任务,并提供优化建议。
内部仪表盘导航: 可根据用户意图,自动推荐合适的仪表盘,满足日常工作需求。
知识问答: 快速回答业务知识、数据模型及指标解释等相关问题。
智能追问与多轮对话: 通过人机协同(HITL)机制澄清用户的模糊意图,支持连贯、深入的数据分析交互
核心技术实践
为了实现以上功能,我们进行了一系列核心技术探索与实践:
让 LLM 理解业务问题 : 将业务概述作为 System Prompt,并构建向量数据库来存储全量的业务术语、指标定义等,再通过 RAG 机制在对话中动态检索,让 LLM 能真正理解业务问题。
意图识别: 准确识别用户意图并将其路由到相应的功能模块,同时提取关键信息,将口语化表达改写为结构化请求。
智能选表: 融合向量检索、TF-IDF、GraphRAG 等多种检索方法召回候选的字段和表,再经过业务约束过滤、LLM 智能决策及规则校验,最终选表准确率达到 95% 以上。
Text2SQL: 基于 LLM 构建的 Text2SQL 系统,已覆盖内部 300 余张业务表,在常见问题上的 SQL 生成全流程准确率超过 90%。
智能数据分析: 我们构建了一套包含时序预测、异常检测、下钻分析、漏斗分析与指标相关性分析等能力的算法服务。通过融合 Workflow(预定义常见问题的分析流程)与 Agent(动态调度工具处理长尾需求)的模式,灵活满足各类分析需求。
系统实现架构: 基于 LangGraph 搭建 Agentic 框架。由 Router 负责识别意图和路由,同时优化上下文管理,支持多轮对话历史追溯,并引入用户反馈闭环,持续提升系统准确率。
在接下来的系列文章中,我们将围绕背景、概述、LLM 业务理解力构建、智能数据查询、智能数据分析、系统实现与最佳实践等几个部分,对 ChatBI 进行更详细的拆解。
主要内容包括以下几个部分:
1. 背景
2. 概述
3. 让 LLM 理解业务问题
4. 智能数据查询
5. 智能数据分析
6. 系统实现与最佳实践
7. 总结与展望
背 景
在数字化时代,数据已成为企业核心资产之一,如何高效提取有价值信息、助力精准决策,正成为企业竞争力的关键。然而,传统的商业智能(BI)工具操作复杂、分析效率低,难以满足日益复杂的业务需求。基于大型语言模型(LLM,下文均简称 LLM)的对话式分析(ChatBI) 突破了传统 BI 的限制,它通过对话实现数据分析,让“人人都是数据分析师“成为可能,从而加速企业的决策效率。
FreeWheel 作为一家全球领先的数字广告管理技术与服务提供商,致力于为高端视频媒体提供广告投放、监测、预测等全链路解决方案,主营业务为高端视频媒体的广告服务,通过销售方直卖、程序化交易、私有 Marketplace、Exchange 等广告销售渠道,助力供给方(通常是流媒体提供商)和需求方(广告代理商或者广告主)更加高效的连接。让流媒体提供商能对他们的流量高效地变现,最大化收益,让广告主能实现广告投放目标,最大化目标人群触达。
这种复杂的业务模式催生了海量的 BI 分析场景,如流量分析、MKPL 订单分析、程序化交易分析、定向数据分析、广告计划检测和优化等等。随着公司业务扩张,数据指标激增、模型逻辑复杂化,传统数据分析模式弊端凸显:业务人员依赖数据团队层层提数,响应迟缓;同时受专业门槛限制,缺乏自主分析能力,数据价值难以释放。ChatGPT 的兴起给我们带来新启发 —— 以自然语言交互替代复杂工具操作,能颠覆传统的数据分析方式,ChatBI 这一概念重新进入了我们的视野。我们开始探索构建公司内部的 ChatBI 系统,服务于广告运营、数据分析与问题排查等关键场景。通过 ChatBI,业务人员可以用对话的方式自主查询数据,系统则自动完成 SQL 生成与结果可视化,甚至进行更深入的洞察分析,从而大幅提升数据获取效率、降低跨团队沟通成本。
本文正是结合我们在 FreeWheel 的实际应用经验,分享构建 ChatBI 系统过程中的核心实践与思考,内容将涵盖智能选表、Text2SQL、数据可视化及分析 Agent 等关键模块,希望能为从事相关领域的同仁带来一些参考与帮助。
概 述
首先介绍下我们的 ChatBI 系统”Insights Chatbot“有哪些功能。
数据查询与可视化:基于自然语言的数据查询是 Chatbot 的核心功能,也是用户最普遍的需求。Chatbot 能理解日常口语、行业术语甚至模糊表达,将自然语言精准转化为查询指令,同时可自动推荐最适合的数据可视化方式,并支持一键切换图表类型,使数据洞察直观清晰。本文第三章将重点介绍数据查询,典型的问题例如:“帮我看看最近的收入趋势” (Show me recent revenue trends),“展示昨天请求量排名前 10 的站点” (Display the top 10 sites ranked by requests from yesterday)。
交互式数据分析:用户经常会问某个指标有没有异常,异常发生的原因(如“为什么 XXX 业务昨天的曝光量下降了?”- Why did the impressions for network XXX decline yesterday?),或者希望下钻到某一个维度(如“是哪个站点导致的问题?” - Which site cause the issue?),又或者仅仅是查询跟某指标变化相关的指标,依托 LLM 的推理能力和外部算法库,快速定位数据,执行统计分析、异常检测、根因排查等任务,并提供优化建议,为决策提供及时有力的数据支持。本文第四章重点介绍数据分析。
内部仪表盘导航:我们在内部监控系统中沉淀了大量的 Dashboard(仪表盘),其中很多已能满足用户日常的工作需求,系统可自动推荐合适的仪表盘给用户
知识问答等:Chatbot 可以回答一些业务知识,尤其是数据模型、指标解释等,以及 Chatbot 擅长的其他问题,如生成摘要等
智能追问与多轮对话:通过引入 HITL(Human-in-the-Loop 人在回环)机制,面对模糊提问时主动追问澄清意图;支持多轮对话,能够准确理解上下文,持续、连贯地推进数据分析。
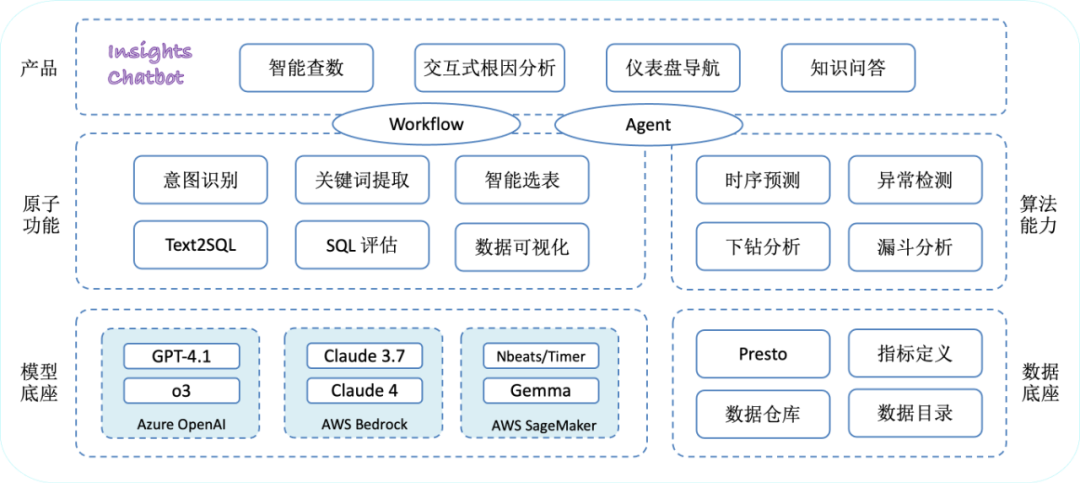
接下来,我们看看 Insights Chatbot 的整体架构。它建立在强大的 模型底座 之上,包括 Azure OpenAI 提供的 GPT 系列模型、AWS Bedrock 提供的 Claude 系列模型,以及我们基于 SageMaker 私有部署的 Gemma 模型和时序预测大模型(如 N-BEATS, Timer 等)。数据底座 依托于分层数据仓库,以及我们统一构建和梳理的数据目录和指标定义,再通过 Presto 进行统一查询。基于此,我们通过 LLM 实现了若干原子功能,包括意图识别、关键词提取、智能选表、Text2SQL、SQL 评估、数据可视化等。在算法能力方面,我们拥有时序预测、异常检测、下钻分析、漏斗分析等多种算法。最终,通过 Workflow(工作流)和 Agent(智能体),将这些原子功能和算法能力有机地结合起来,共同支撑了 Insights Chatbot 的四大核心功能:智能查数、交互式根因分析、仪表盘导航和知识问答。
让 LLM 理解业务问题
由于 LLM 本身对公司具体的业务细节缺乏先验知识,因此我们面临的首要问题是:如何让大模型精准理解我们的业务问题?我们的核心解法是 Prompt + RAG。
我们从以下三个层面入手:
1. 传递核心业务知识
我们提炼了 Freewheel 视频广告业务中的核心概念,包括 Supply vs Demand 模型、广告投放(Ad Serving)核心流程等,整理成千余字的业务概述,作为 System Prompt 的一部分注入模型,为 LLM 提供基本的业务背景。
2. 引入术语体系与知识库
针对业务术语、行业黑话及关键指标,我们分为两部分处理:
高频术语与常用黑话:作为 System Prompt 的一部分,直接提供给 LLM;
全量术语、数据指标等复杂知识资产:构建在向量数据库中,通过 RAG 机制动态检索,辅助模型理解更细节的问题。
3. 用户意图识别与信息提取
进一步让 LLM 理解用户的问题,就要识别用户的意图,我们将业务问题分为四类,对应上文的四大功能:数据查询、根因分析、仪表盘导航和知识问答。我们把常见的业务问题整理到向量数据库中,也是通过 RAG 的方式提高意图识别的准确率。
关键词提取
理解了用户意图之后,对业务问题的进一步理解就是能够对问题进行结构化表达,我们把这一步叫做关键词提取。系统会精准识别用户表达中的关键信息,提取包括维度、查询指标、过滤条件、时间区间、时区等关键词。同时,为了解决指标别名或同义问题,我们将上述业务知识嵌入到提示词中,提升 LLM 对业务语义的感知能力。例如,在我们的业务语境中,“Asset” 和 “Video” 表示相同含义。
关键词提取完成后,系统会结合上下文语义对原始问题进行改写,将用户的口语化表达转化为结构清晰、逻辑严谨的数据查询或者分析请求。
智能数据查询
接下来,让我们看看智能数据查询的落地实践。
Freewheel 的分层数据仓库系统包括了维度数据表、明细事实数据(主要是广告日志明细)、通用聚合数据、领域聚合数据、应用聚合数据,基于聚合数据构建了若干数据产品,如 Analytics, Insights 等。明细层数据都是广告日志明细数据,很多指标的计算需要复杂的逻辑,且查询性能较差,一般仅用于广告工程团队排查问题使用,不适合于 ChatBI。三层聚合数据粒度分别从细到粗,定位不同的产品用途,可以支持不同的查询需求。当前用户在即席查询时面临很多挑战,这也是 ChatBI 需要解决的问题。
对于用户的问题,多个表都可以满足查询需求。但有的表维度多,数据量大,查询性能差,因此我们需要选择满足用户查询需求并且性能最优的表。例如在广告销售表可能存在多个版本,分别记录不同维度的销售信息,如按流量特征、按产品线等,Chatbot 需要理解用户查询意图,判断应从哪个表中查询数据。
在同一张表中或者不同的表中都存在很多非常相似的指标,有的指标名字相似(或者字面上没有关联)代表相同的含义(同一个指标还有很多别名),有的看似相似的指标却表达完全不同的含义
指标因其业务逻辑特点只能对应某些维度,在其他维度上没有意义
我们通过“智能选表”和理解业务语义的 Text2SQL 解决以上问题,下文将会重点阐述。
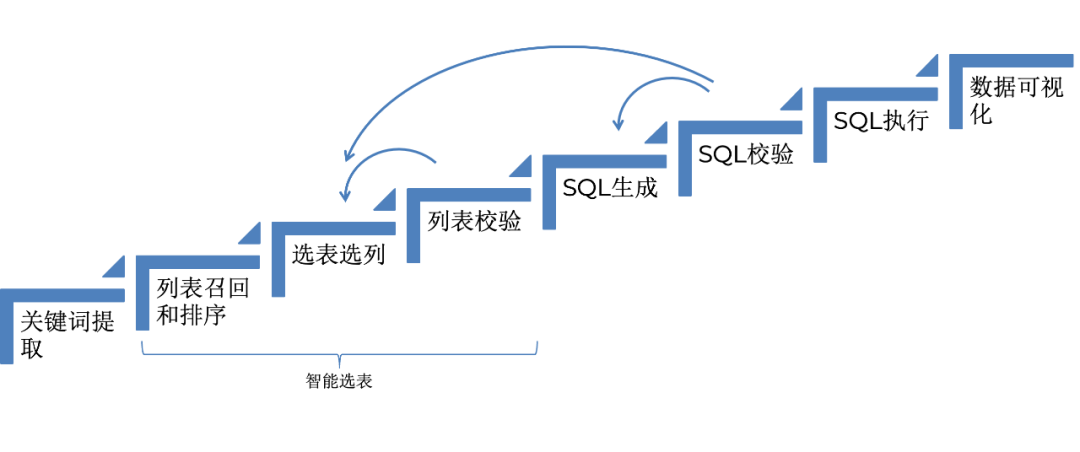
下图是数据查询的整体流程,接下来会详细介绍每一个部分,并花较大篇幅介绍智能选表。整个流程包括关键词提取、智能选表、SQL 生成与优化,最终实现数据可视化。列表召回和排序、选表选列于列表校验这三步组成了智能选表,接下来会重点介绍。列表校验、SQL 校验失败都会退回到上一步重试,SQL 校验时,如果发现这张表无法解决用户的问题,说明选择的表不合适,重新进行选表。
指标与数据目录
在介绍智能选表前,先介绍下数据目录与指标定义,这是选表和 Text2SQL 的基础。我们通过建立数据目录和元数据管理系统,对数据仓库进行统一梳理和标注,涵盖以下多个方面:
数据目录与数据仓库概述:对数据目录和数据仓库进行高层次描述,阐明其分层架构、数据来源、表的种类以及业务场景等。
表的详细说明:清晰阐述每张表的功能,以及其在数据产品中的应用场景,例如某张程序化交易广告销售数据表,可用于生成程序化交易洞察分析、第三方 DSP 竞价仪表盘等数据产品。
表的选择逻辑:明确界定表的适用范围,比如某些表仅适用于特定业务场景,如 Marketplace 订单销售表,仅适应于 Marketplace 业务下的供需分析和销售分析;同时说明哪些场景下该表不适用,避免错误使用导致数据分析偏差。
字段详情:针对每个字段,明确其类型,判断是维度(用于描述业务实体的特征,如网站、地区等)、指标(可量化的业务衡量标准,如请求量、曝光量)还是错误度量(用于记录广告投放过程中的相关问题,如行业限制、竞争失败等);阐述字段含义,列举可能的取值范围;若为维度字段,指出与之关联的维度表,类似数据库中的外键关系,方便数据关联。
衍生指标(Derived Metric):详细解释衍生指标的计算逻辑与业务含义,例如,广告填充率 = 填充广告数 / 视频广告位 。
字段唯一性保障:我们仔细梳理不同数据表中的同名或同义字段,明确其语义一致性,针对字段含义的特殊情况,进行详细说明与标注,确保数据解读的准确性与连贯性。
SQL 限制条件:列出表在 SQL 查询中的限制条件,例如对某些敏感字段的访问限制,或是特定业务逻辑下对数据检索的条件约束,确保数据使用的合规性与准确性。
技术方案的选择
自然语言交互的数据查询通常有 Text2SQL 和 Text2DSL 两大主流方案:Text2SQL 可将自然语言直接转为标准 SQL 查询,便于集成,且通过对多表 JOIN、聚合等操作的支持,它能够灵活应对复杂的业务查询需求,但因 SQL 语法与逻辑复杂,基于 LLM 生成的 SQL 很难保证业务逻辑的绝对准确。Text2DSL 通过预先设计的 DSL(如 LookML,明确规定数据模型、查询维度、指标、时间区间等结构)结构化映射为 SQL 查询,能提升准确性,却面临维护成本高、复杂查询(如多表 JOIN、嵌套聚合)支持不足的问题。
鉴于 Chatbot 用户多具备数据仓库与 SQL 基础,我们最终选择 Text2SQL。系统能够针对用户的问题自动生成 SQL 并可视化呈现,用户可以对生成的 SQL 进行审查,询问 SQL 表达式的含义,通过多轮对话不断优化,直至精确获取所需数据。
如何选表(Schema Linking)
确定 Text2SQL 技术路径之后,我们面临的问题是如何选取合适的表,学术界一般也称作 Schema Linking。因为 Schema 数据特有的结构化特性,我们扩展了传统 RAG 中检索的方式,综合运用多种检索方法。
表和列的初步召回
选表的第一步是在大量的表和字段中召回可能相关的表和字段。我们根据提取的维度和指标等关键词,结合元数据信息,通过融合多种检索方式从数据目录中初步筛选相关表和字段。
在文档检索中,常用的检索方式包括:
Embedding 向量检索,通过预训练模型将文本数据转化为高维向量,在高维空间中快速定位语义相近的数据,通过计算余弦相似度,按相似度排序取 Top-N 结果。擅长处理自然语言变体(如如 “address” 匹配 “country”, “state”, “post_code”)、长文本语义理解(如表描述中的业务逻辑说明)
基于 TF-IDF 的排序检索,基于词频 - 逆文档频率算法评估关键词重要性,BM25 作为改进版引入参数调节,提升短文本匹配精度,可以用于计算问题和所有文档之间的相似度取 Top-N 结果
基于 Edit distance 的检索,Edit distance(编辑距离)用于衡量两个字符串之间的差异程度,可以设置阈值(如≤2)过滤近似匹配结果。
除了传统的检索方式外,GraphRAG 是一种融合知识图谱的检索与生成集成框架,先借助 LLM 将原始数据转换为知识图谱结构,通过社区检测算法划分图谱并生成各社区的语义摘要。对查询预处理后,利用社区摘要检索全局信息,锁定关键社区范围,再利用图嵌入向量检索子图,最后融合社区摘要与子图信息生成回答。
列与表的差异化召回策略
1. 列级检索:传统检索方法和 GraphRAG 的结合
向量检索:最初我们采用列 Embedding 向量检索的方法,也就是最传统的 RAG 方法,根据列名、别名、解释摘要构建向量数据库,它的问题就是准确率不高,在有其他方法之后基本只保留相似度很高的结果;
BM25:可以把列的详细解释以及维度列的枚举值都作为文本进行检索,并强化关键词权重(优先返回包含 “request”“impression” 等高频业务词的列);
编辑距离:我们通过设置很小的阈值,比如 2,可以比较好得处理拼写变异的问题(如 “avail” 匹配 “avails”);
GraphRAG:我们借鉴 Graph RAG 的思路,但不需要社区摘要的步骤。首先借助 LLM 构建 entity-column 知识图谱,实体包括两类,一类是抽象实体,另一类是列实体,抽象实体包括了业务概念、抽象的维度、指标大类等,人工可以 Review 并修改实体和关系的定义。检索时,一方面通过 embedding 向量检索 entity,再召回链接的列,另一方面检索关系,再传播到 entity 和列。
2. 表级检索:区分事实表和维度表
在表召回上,事实表和维度表采用不同的召回策略。由于事实表都是大宽表,很难在表的语义层面召回,因此我们用召回列反向关联的方式得到。对维度表,一个是表描述的 Embedding 向量召,另一个是表名的编辑距离检索。
完成召回之后,我们会先按照业务约束,比如数据过期、权限限制等进行过滤。然后对列进行排序,进一步筛选掉关联性很差的列。对表的初步排序可以协助 LLM 进行最终的选表。
检索结果优化与智能决策
1. 初步过滤与重排序
业务约束:过滤权限不足、数据过期(如用户需最近一年的数据但表的 Retention 为 3 个月)
重排序:按照原始的相似度得分与 LLM ReRanker 排序权重的融合值进行重排序
2.LLM 智能决策
设计如下提示词模板,引导 LLM 输出最优表:
LLM 角色和任务描述
Freewheel 广告业务介绍
术语黑话映射表: 包括了常见的黑话和通过 RAG 方式召回的部分
数据目录与仓库概述
候选表和列:也就是上一步召回的表和列,包括每个表的描述和选表逻辑
通用选表规则:应该遵守的规则,例如什么时候应该选择事实表或者维度表,什么时候应该选择多张表
选表样例:我们收集了多样化的问题并标注了最优选择的表,存储到选表样例向量数据库中,通过 RAG 的方式找到和用户提问相似的例子。
下面举一个例子,有如下候选表:
demand_portfolio_summary(相关字段:sales_channel, revenue;选表逻辑:该表为粗粒度汇总表)
demand_portfolio_details(相关字段:sales_channel, revenue; 选表逻辑:该表包含细粒度数据)
inventory_performance(相关字段:sales_channel)
programmatic_summary(相关字段:sales_channel, revenue;选表逻辑:该表为 Programmatic 渠道汇总表)
programmatic_details(相关字段:sales_channel, revenue;选表逻辑:该表为 Programmatic 渠道细粒度表)
当用户提出 “上个月程序化交易渠道的收入趋势如何” 的问题时,系统会自动解析 “程序化交易”“收入” 等核心关键词。随后,LLM 会参考元数据中对各数据表的详细描述及选表逻辑,并结合与该问题语义相近的过往示例,从数据库中精准筛选出程序化交易事实表中粗粒度表 programmatic_summary(鉴于问题未涉及更多维度),以及渠道维度表。当用户问题为统计 2025 年 Q1 各销售渠道的收入时,同理则需要选择 demand_portfolio_summary。
3. 规则校验与重试
通过与 Schema 校验,确保 LLM 输出的真实存在的表并且包含所需的列,如果校验不通过,就需要重试,避免 LLM 出现“张冠李戴” 的幻觉信息。
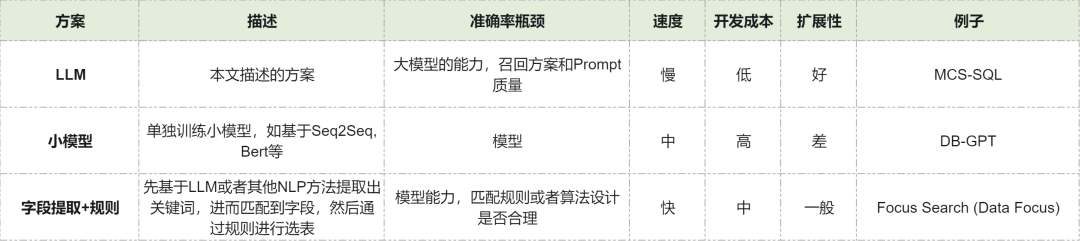
其他方法比较
除了让 LLM 直接参与选表外,我们也对比其他的选表方法,供读者参考
SQL 生成
完成表的选择后,接下来就是生成 Presto SQL,首先根据选表选列结果,从常见问题 SQL 样例数据库中召回与表和列有关的相似的问题和 SQL,然后构建 Text2SQL Prompt,生成 SQL 语句。生成 SQL 后,我们会进行语法检查,一旦发现错误,立即反馈给 LLM 去修正,语法检查之后,会对 SQL 进行业务正确性的评估,同样让 LLM 来完成,如果评估失败,同样把错误原因反馈给 LLM 重新生成 SQL。
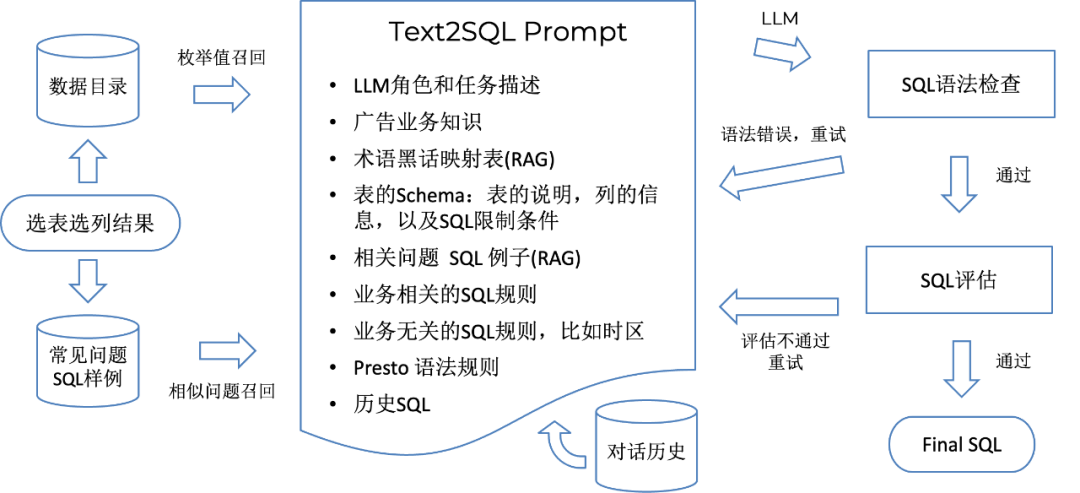
生成 SQL 的 Prompt 分为以下几个部分:
LLM 角色和任务描述
Freewheel 广告业务介绍
术语黑话映射表: 包括了常见的黑话和通过 RAG 方式召回的部分
表的 Schema:包括表的说明,列的信息,包括维度列的枚举值和关联的维度表,指标列的语义,以及 SQL 限制条件
从知识库中召回的跟问题相关的“Question - SQL” 例子
业务相关的 SQL 规则
业务无关的 SQL 规则,比如如何处理时区
Presto 语法规则,比如数组列如何处理
高质量的样例是关键
无论是选表样例还是 SQL 样例,都存在冷启动的问题,提供高质量的样例是解决冷启动问题的关键。在问题收集上,一方面我们通过人工收集常见问题,另一方面利用 LLM 驱动的 SQL2Text 方法将线上系统中采样 的 SQL 转换为问题。有了问题后,我们先用初始版本的 Text2SQL 生成 SQL,并进行人工 Review 和修改,形成了刚上线时的 SQL 样例库。后面会介绍我们上线之后的数据闭环。
数据可视化
数据可视化方面,我们在前端集成了公司自主研发的 Circle UI 组件,能够无缝对接 Grafana Panel 支持的可视化设置和数据格式,包括 Stat、趋势图、表格、柱状图、饼图、热力图等多种可视化效果,确保数据以直观、易懂的方式呈现给用户。
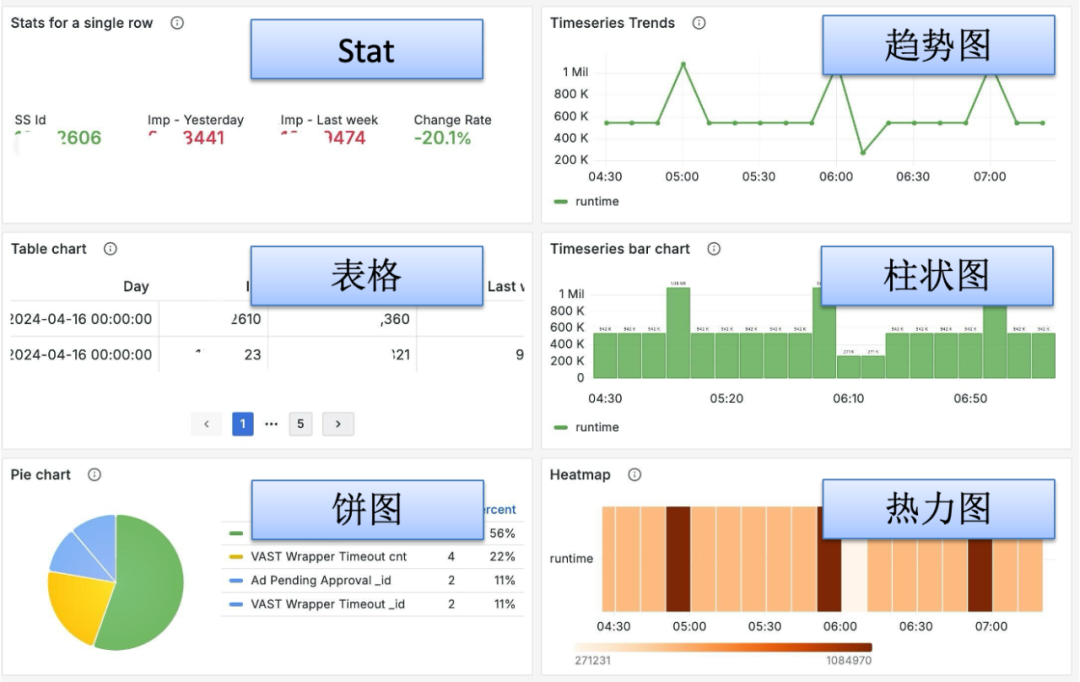
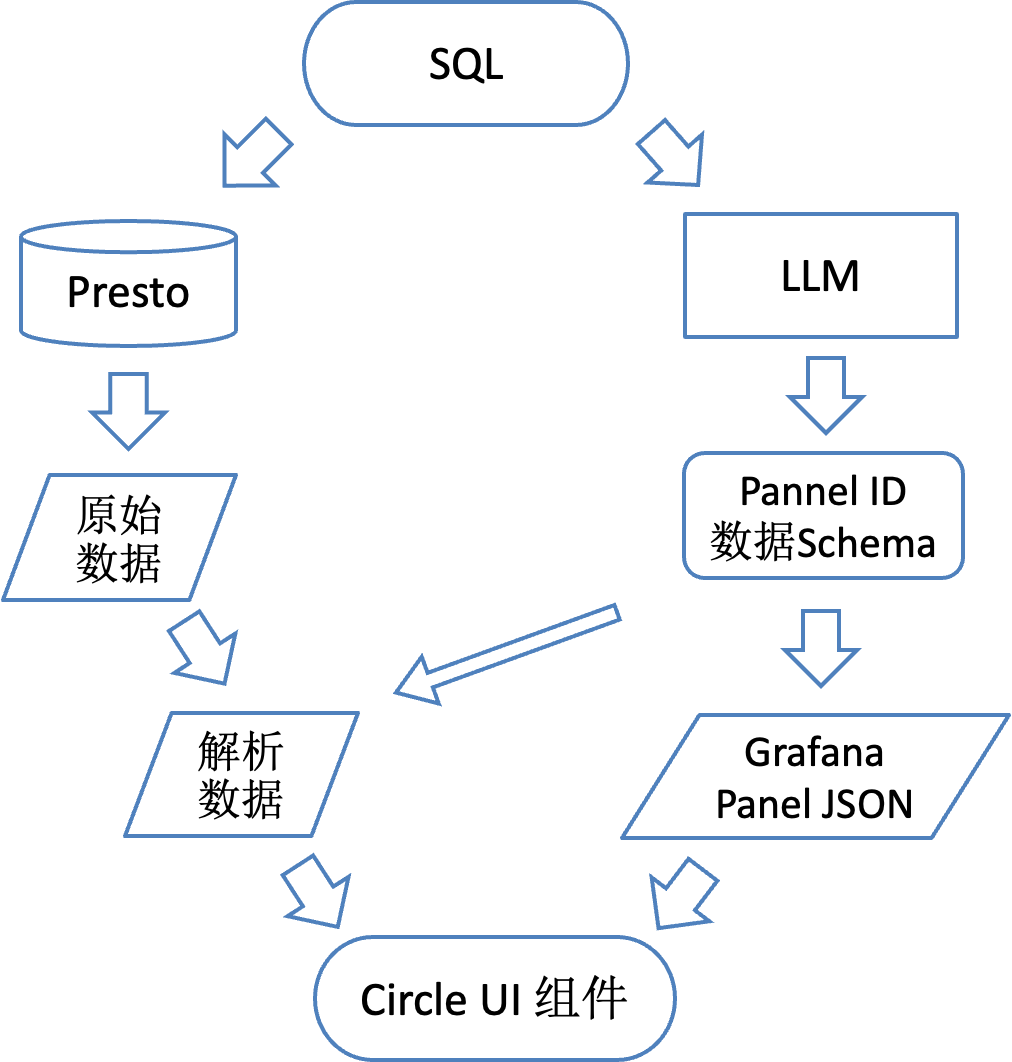
拿到正确的 SQL 之后,一边进行数据查询,另一边进行可视化图表的选择,借助 LLM,结合用户问题的意图和 SQL 选择最为适宜的图表类型,输出 Grafana Panel ID 和数据结果的 Schema,根据这个 Schema 对查询到的数据进行解析,转换为相应的数据格式,传递给前端 Circle UI 组件。
效果总结
我们的数据查询能力涵盖 300 余张表,其中事实表 30 余张,平均字段数超 100 个,唯一字段约 1000 个;维度表 280 余张,平均字段数为十几个。
智能选表:鉴于字段繁多,选表的难点聚焦于事实表,通过标注 400 余个选表示例,系统在事实表选择上的准确率基本达到 95% 以上,在多表中筛选性能最优表的准确率亦达 85% 以上。
SQL 生成:标注了高质量的 SQL 例子 300 余个,常见的问题全流程准确率在 90% 以上。
智能数据分析
如果说智能数据查询是 ChatBI 的基础,解决了“能问”的问题,那智能数据分析则是 ChatBI 的升华,帮助用户从数据中发现业务异常、寻找根因,获取洞察。
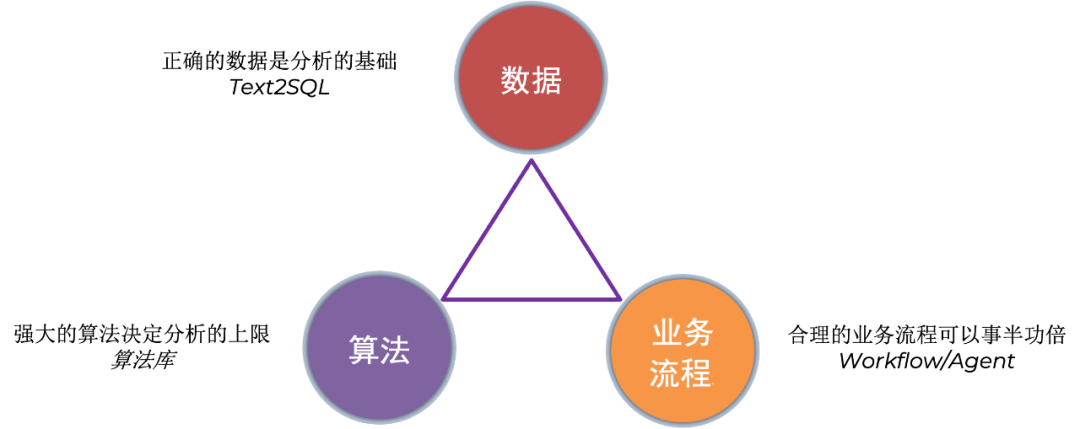
我们首先来看下数据分析的三个关键要素:正确的数据、强大的算法和合理的业务流程。正确的数据是数据分析的基础,我们上面讲的智能选表、Text2SQL,给数据分析提供了所需要的数据;强大的算法决定分析的上限,虽然 LLM 可以直接理解数据,但是效率低、容易出错,这就依赖于我们自建的数据分析算法库;合理的业务流程可以事半功倍,尤其是根因分析,涉及复杂的业务,需要合理的流程进行分析,而不是一股脑得把所有指标都拿出来扔给算法,那样不仅效率低,而且可能得出错误的结论。
算法介绍
为了支持 Chatbot 的异常检测和根因分析能力,我们构建了一套完备的算法服务,核心功能涵盖:
时序预测:该能力不仅能为用户输出指标预测结果,更是异常检测、下钻分析等复杂业务分析的基础。目前线上部署的模型包括针对特定业务指标优化的 NBEATS 模型,以及基于开源 timer 模型微调的定制化模型。
指标时序异常检测:在《从零开始构建业务异常检测系统,Freewheel 面临过的问题和解决方案》一文中,介绍了我们的解决方案和线上系统。我们部署了基于特定业务指标训练的 NBEATS 模型、开源 Timer 模型微调等多个神经网络模型,将核心系统服务化,实现对各类业务指标的动态异常监测,Precision 和 Recall 均超过 90%。
业务实体离群点检测,通过分析同一类广告实体(如 Campaign)的某一个业务指标,精准识别偏离正常分布的异常实体(即那些指标不符合正常分布的 Campaign)。
转化漏斗分析:对业务转化漏斗建模,当漏斗底部指标出现异常下降时,该算法可回溯各环节数据,快速定位影响转化效果的关键节点。
下钻(Drill Down)分析:作为最常用的分析手段,包括单维度下钻和动态维度下钻,支持 Hotspot、Adtributor 等多种下钻算法,帮助用户层层拆解数据维度。
指标相关性分析:通过量化指标间的关联关系,辅助用户定位业务异常的根源。
Workflow or Agent
最后来说最重要的,合理的业务流程。面对丰富的算法体系,如何将其转化为便捷可用的分析服务?我们融合业界主流的 Workflow 与 Agent 两种模式,构建起算法服务与数据分析全流程之间的桥梁,确保算法精准执行,为用户提供可靠的答案。
Workflow
在数据分析场景中,有大量的问题是频繁被问到的,例如 “Why impression drop”(为什么曝光数下降了)、“Why the fill rate is low”(为什么广告填充率低)等,这些问题通常有明确的诊断路径和解决方案。而 Workflow,也就是工作流,具有解决方案成熟、流程相对固定、准确率高的特点。因此,我们基于已有算法能力,构建工作流,将这些常见问题的解决思路进行标准化预定义,将数据查询、算法处理、可视化等流程封装为统一的工作流,供用户直接调用,实现高效准确的分析。
以广告曝光数(impression)下降为例,这是它的 Workflow,通过下钻分析定位问题,依次检查广告填充率、渲染率、广告位数和流量等,最终找到根因是流量下降。
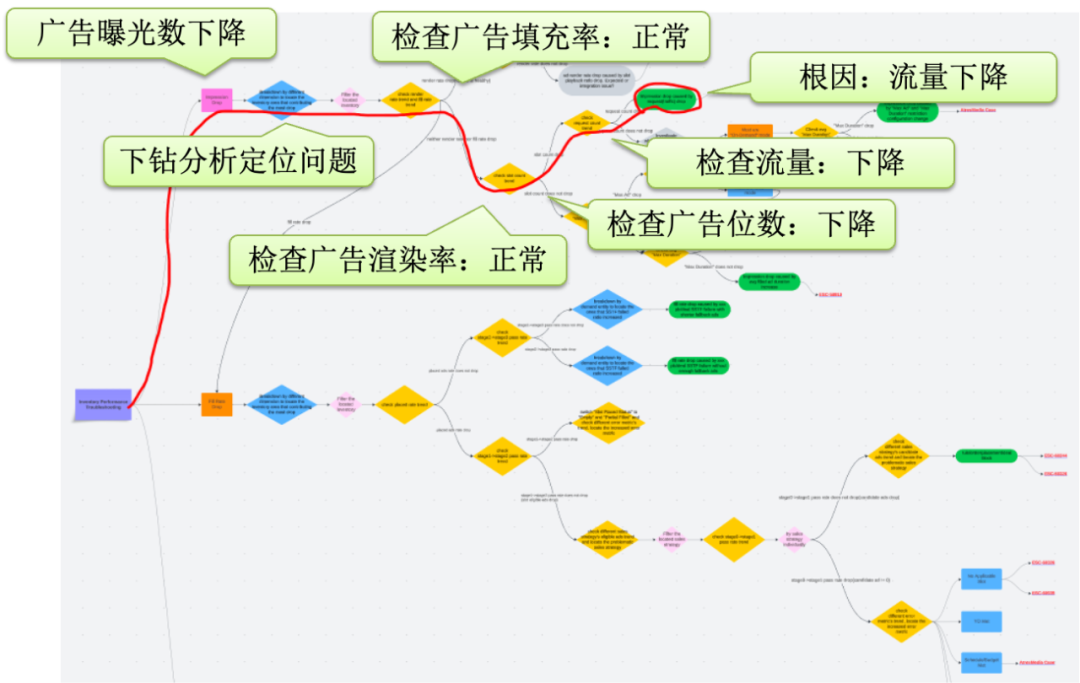
下面看一个更复杂一点的业务问题分析的例子。用户发现他的负责的某一个 Network 的广告曝光量出现了下降,希望知道原因,但他并没有太多分析经验,有了 Chatbot 之后,可以直接提问“Why the impression drop for network XXX yesterday?" 这个问题直接命中了系统内置的工作流,执行路径如下:
定位 impression 异常下降的具体时间段→从可能的维度进行下钻,定位到发生问题的 inventory(流量实体)→确认 fill rate(广告填充率)是否同步下降→是→分析 placed rate(预填充率)是否同步下降→按 sales channel(销售渠道)进行下钻→定位发生问题的(多个)销售渠道→对具体的销售渠道的广告投放进行转换漏斗分析→定位到某销售渠道 candidate ads(候选广告数)出现下降→定位到具体的 demand entity(广告销售实体)
Agent(智能代理)
工作流的局限在于灵活性不足,难以覆盖所有用户的长尾需求。为满足灵活分析场景,我们引入 Agent 机制。通过将 Text2SQL、数据查询与解析、上述算法服务封装为 Tool,交由 LLM 调度与组合执行,生成个性化、动态的数据分析流程,灵活响应复杂多变的用户需求。
我们看下 Agent 的结构,它由 Planner 和 Executor 组成,如下图所示:
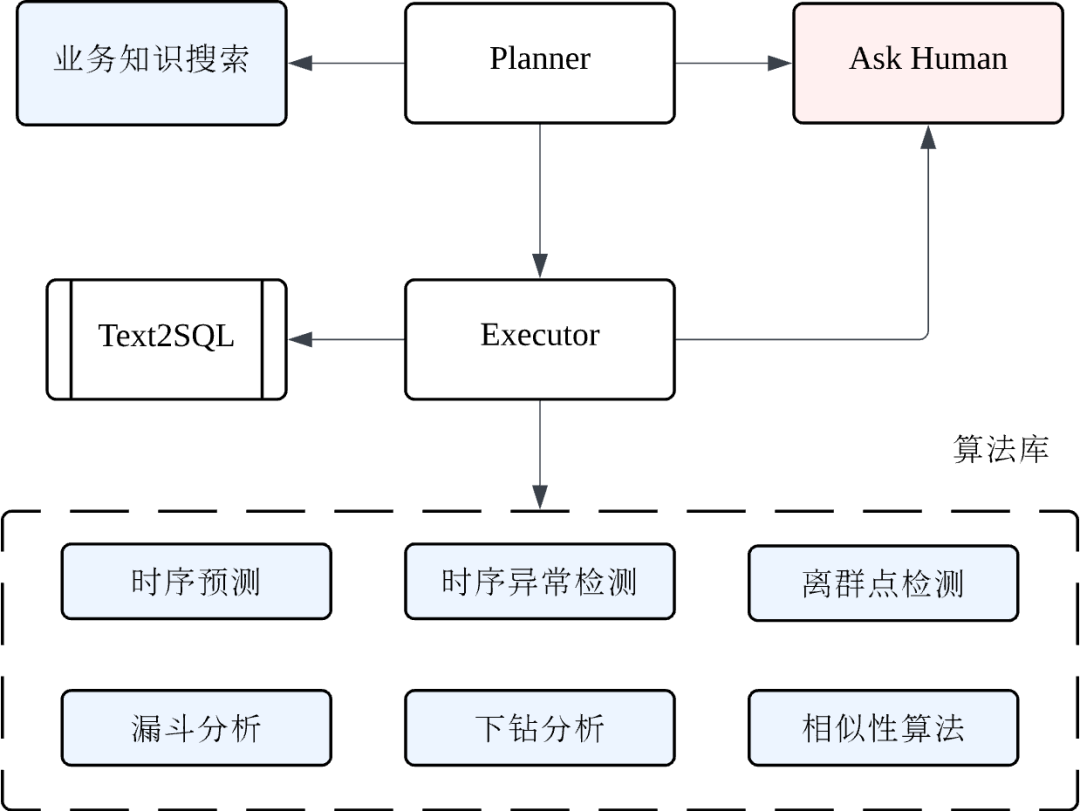
Planner 负责制定计划、汇总当前的状态,给出结论,可以搜索知识库中的解决方案,在不确定时询问用户,让用户给出更多信息或者请求用户审批下一步动作;
Executor 负责调用取数工具和算法工具(包括时序预测、异常检测、下钻分析、漏斗分析等多种算法),诊断错误并自适应调整算法参数,同样在遇到处理不了的错误时询问用户的处理意见。
在处理用户需求时,Agent 会基于数据分析经验与典型工作流示例,让 LLM 通过 CoT 的方式动态规划处理路径。典型流程为:先通过 Text2SQL 完成数据检索,再调用下钻分析等算法进行深度挖掘,如果中间遇到错误,Agent 将诊断错误并自适应调整算法参数进行重试,最终将结构化分析结论反馈给用户。
Agent 的架构设计我们也在持续探索中,包括引入反思,多 Agent 协同等,受限于篇幅,Agent 系统的具体实现将在后续文章中详细展开。
那么,系统如何决定是调用 Workflow 还是 Agent?我们扩展了意图识别模块,通过分析用户提出的问题并识别其属于常见场景还是复杂个性化需求,自动路由至对应的处理方案。后面我们将对该模块进行详细介绍。
系统实现与最佳实践
在 Chatbot 的功能体系中,数据查询、可视化与分析能力固然重要,而准确把握用户意图、智能追问与多轮对话则为其赋予了“思考深度”和“交互温度”。在复杂多变的实际场景中,用户需求往往模糊难辨,单次提问难以完整传达意图。Chatbot 的智能追问与多轮对话功能,通过主动澄清意图、延续分析脉络,实现高效人机协同,显著提升交互体验与分析准确性。
架构
我们通过 Agentic 系统来实现智能追问与多轮对话,以及 Chatbot 的整体架构,我们通过 LangGraph 搭建了 Agentic 的整体框架,如图所示:
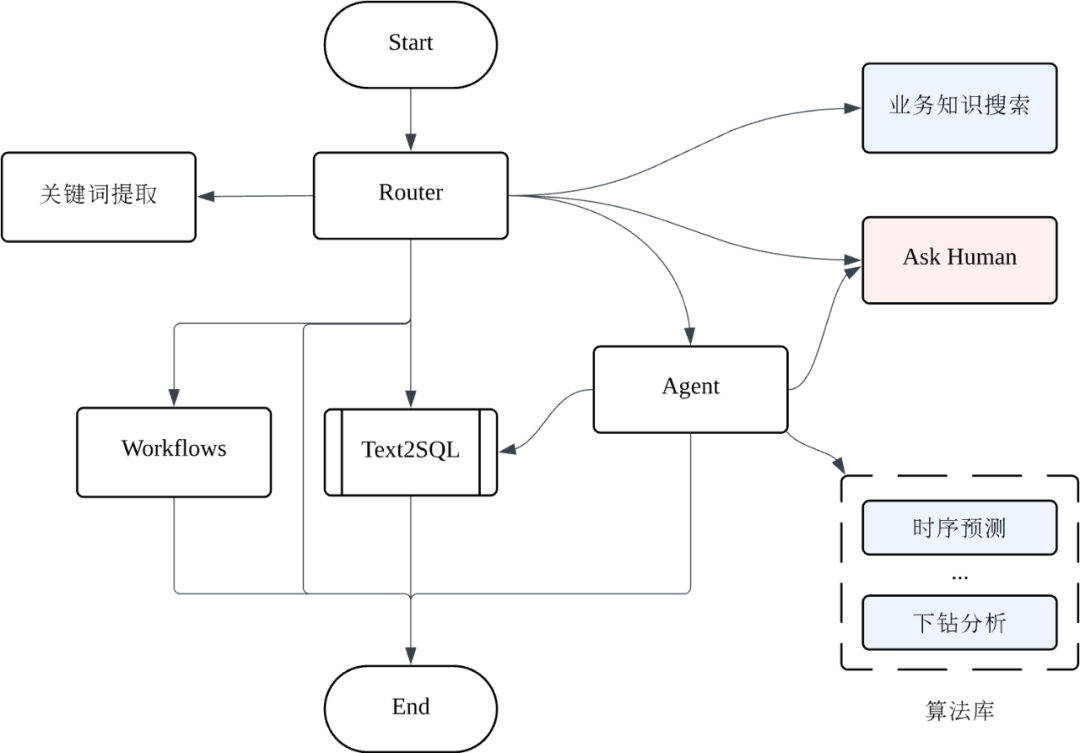
Router
Router 是核心节点,借助 LLM 识别用户的意图,并通过调用多个工具、Workflow 或者 Agent 来回答用户的问题。
LLM 绑定的 Tools 包括:
Ask Human:Ask Human 是实现 HITL 的核心,通过调用 Ask Human 暂停 Graph 的执行,并将 LLM 追问的问题返回给用户,等待用户回答后,将答案返回给 Router
Keywords Extraction:上文提到的,提取问题中的关键词,包括维度、指标、条件、时间等
Search Knowledge:从知识库中检索相关知识,知识库主要包括通用业务知识库、数据目录和元数据,针对不同的数据融合利用上文提到的多种检索方式,确保相关知识被检索到
Router 的 LLM 提示词中包括了通用业务知识、意图分类指导、知识问答指导等。
对于知识问答来说,Router 可以直接生成答案,也可以调用 Search Knowledge 从知识库中检索相关知识后再生成答案。
对于单纯的数据查询,Router 在调用 Keywords Extraction,确保用户提供的信息完整之后,直接调用 Text2SQL 即可,如何用户的问题模棱两可,则会调用 Ask Human 进行追问。
最复杂的是数据分析,如果问题被某 FAQ 工作流覆盖,Router 会直接选择执行该工作流;否则,Router 会将数据分析任务交给 Agent 来处理。
一个例子
以一个实际场景为例:当用户提出问题 “Which site caused the impression drop for ABC during XXXXXX?” 时,Chatbot 会按以下流程完成分析:
意图解析与关键信息提取:Router 模块首先识别该问题属于数据分析范畴,通过调用 Keywords Extraction ,精准提取出分析维度(site)、核心指标(impression)、限定条件(ABC)以及时间区间(XXXXXX),并路由至数据分析 Agent。
SQL 查询构建与数据获取:Agent 调用 Text2SQL 功能,根据提取的条件自动生成 SQL 查询语句。为了更科学地对 “异常下降”进行下钻分析,系统会将时间区间向前拓展,以便获取更多历史数据用于预测异常区间的期望值。生成的查询语句如下:
SELECT event_time, site, SUM(impression) as impressionFROM tableWHERE condition_ABC and time_condition_XYZGROUP BY 1,2执行该查询后,结果将被解析为各个 site 对应的 impression 时间序列数据。
预测与异常定位:Agent 调用 Prediction 模块,对当前时间区间的指标数据进行预测。最后,Agent 调用下钻分析算法,精准定位导致 impression 下降的那些异常的 site。
总结结论,输出支持性数据和图表
上下文优化
对于有十几个与 LLM 交互的节点的这样一个 Agentic 系统来说,为了能保持对全局上下文的敏感,又能确保单轮任务的高效与精准,各模块设计如下。
Router: 作为直接和用户交互的模块,Router 在利用 LLM 识别意图时可以看到 Session 内完整的历史对话,包括用户的问题以及 Chatbot 的回复摘要,摘要主要是对其中的 SQL、数据图表进行抽象,避免冗余信息,节省 token 数;
Text2SQL: 作为相对独立的模型,Text2SQL 仅能看到历次对话的原始问题和 Router 基于上下文扩写之后的问题,以及 SQL 生成结果,控制 token 数目,确保专注于生成 SQL,提高生成效率;
Agent: Agent Planner 与 Router 一样,同样可以看到 Session 内完整的历史对话,以及 Agent 内部的 Plan 与 Execute 日志,从而在制定与执行任务时,结合全局和自身反馈实时调整策略。
用户反馈
鉴于业务场景与数据结构的复杂性,Chatbot 无法始终保证回答绝对准确。为此,我们引入用户反馈学习,构建闭环优化流程,以不断提升系统准确率与用户满意度。具体流程如下:
用户反馈收集: 通过引导用户对结果点踩或点赞,收集用户反馈,点赞的 SQL 可以加入样例库中,用户可对生成的 SQL 提出修改建议,或对分析结论进行质疑。
LLM 驱动预审: 引入 LLM 对用户反馈与现有知识进行自动比对,若模型判断反馈与当前系统输出存在显著偏差,则标记为“高风险反馈”,并提交人工审核,否则可以实时更新知识库。
人工复核与归档: 业务专家对高风险反馈进行审核和修正,经人工确认的更新同步回知识库,完成闭环。
通过上述机制,系统不仅能够快速吸纳用户智慧,还能在自动化与人工复核的协同下,持续提升回答质量和用户体验。
实践经验
下面分享下我们的一些实践经验。
开发框架
在开发框架选择上,一开始我们用了 LangChain 和 LlamaIndex;后来感觉到有俩问题,一个是框架用起来很繁琐,第二个是不够透明,不好 debug,因此我们改成不用框架自己手写;LangGraph 出来以后呢,一是正好解决了我们 HITL 的需求,二是 Graph 的结构清晰,能够表达我们的流程,就逐步切到了 LangGraph 上。
基座大模型
LLM 目前我们同时在用 GPT 4.1 和 Claude 4 Sonnet,互为热备,生成出错或者检测到幻觉可以动态切换。意图识别和语义理解等多数任务默认使用 GPT,GPT 4.1 在成本和速度上都优于 Claude 4 Sonnet。在 SQL 生成 Agent 中优先使用 Claude 4,它的代码生成和问题规划能力要强于 GPT。
数据安全
由于我们对 LLM 的依赖较深,尤其在推理能力与低幻觉表现方面,Chatbot 需接入如 Claude 3.5/4、GPT-4o/4.1 等公有云上强大的模型。这也带来了数据安全的关键问题:如何确保公司和客户数据不被泄露?除了依赖 LLM 服务商自身的安全合规承诺外,我们还引入了 私有化部署小模型的协同方案。我们基于 AWS SageMaker 部署了如 Gemma-4B 等成本可控的小模型,承担数据预处理任务。具体做法包括:由小模型先行进行数据脱敏处理,如识别并提取客户 ID 等敏感字段,将其替换为随机占位符,在与外部 LLM 交互时避免泄露真实数据;最终结果返回后,再将占位符替换为原始信息,确保用户体验完整且数据安全。此外,诸如数据总结等通用性强、对推理能力要求相对较低的任务,也完全可以交由本地小模型独立完成,进一步降低风险和成本。
Prompt Engineer
我们的 Prompt 统一使用 Markdown 格式,使用 Promptfoo 进行 Prompt 测试,使用 Langfuse 作为 Tracing 工具。
总结与展望
Insights Chatbot 上线后收获了用户的广泛好评,尤其是在以下人群中效果显著:花费大量时间手写 SQL 的数据分析师、频繁寻找数据的运营人员、以及需快速定位线上问题根因的 Account 团队。同时,我们也收到了许多宝贵的用户反馈,例如,不知道如何提问、不确定数据是否可信、根因分析流程不够透明等。针对这些问题,我们已着手进行了多项优化:
引入“提问建议”功能引导用户提问;
我们开放 Text2SQL 模块的关键中间结果(如选表依据、生成的 SQL 和相应的解释)以增强可解释性,展示 SQL 自评估结果;告知用户当前查询结果的注意事项,如业务上的默认过滤条件,数据能否去重等;
对于根因分析算法过程不够透明的问题,我们展示算法过程中的决策数据和支持数据,比如,在下钻分析中增加子属性的统计信息与趋势图。
展望未来,我们将持续推动系统能力提升。Text2SQL 方面,通过包括 RAG 精细优化、优化语义表达、借鉴 Alpha-SQL 的思路进一步拆分流程,进一步提升生成准确率,对常见问题缓存可以提高响应速度。Agent 上我们计划支持生成并执行数据分析 Python 代码,以及探索更多 Agent 架构,进一步提升 Agent 的能力。同时,覆盖更多的业务场景,帮助用户解决更多的问题。随着 LLM 能力演进与系统持续优化,我们相信 ChatBI 将真正融入日常业务流程,帮助用户节省 90% 的重复性工作,让数据的价值最大化。
作者简介
钟雨,本科和研究生就读于清华大学,现任 FreeWheel 数据应用部门主任算法工程师,数据智能算法团队负责人,负责业务异常检测、根因分析、ChatBI 等。曾供职于京东广告数据团队,Spark Contributor,具备丰富的大数据开发与调优、数据挖掘和机器学习、大语言模型应用等经验。




